以前の「データ駆動型DX基盤を創る」以降・・・・
以前に「データ駆動型DX基盤を創る」と題して、現在のソリューション進化のレベルにおいては、以前の様な「専用設計&個別開発」を前提とし、「そもそもインフラ自体に結構な投資を必要とする」系の大規模プロジェクトベースではなく、必要台数(3−5台)の適切な仕様構成で構築されたIAサーバのクラスター上に、市販のソリューション・ソフトウェアをインストールすればOK!という話をさせて頂いたかと思います。
可視化状況に関しては・・・
(1)データの更新は左側の上から5個のDBテーブルのみに対して状況
(2)他の可視化は、EqualumがCDC起点の高精度ストリーミング技術で物理的・論理的に異なるDB上に散在するテーブルに対して即時同期処理を行なっている状況
になります。またそれぞれの可視化グラフに関しては
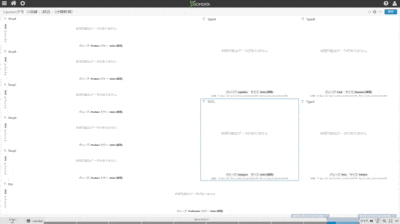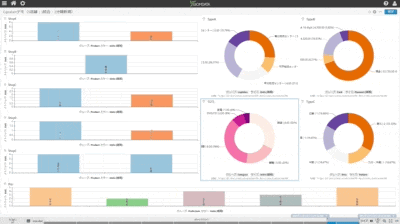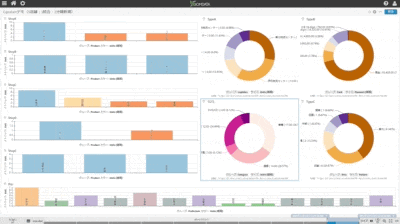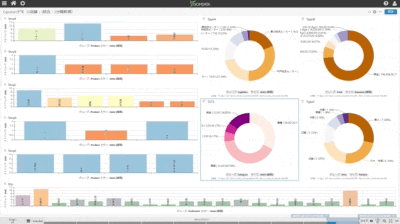
(1)中央の円グラフ:左側で更新中の個別DB5個を即時同期統合している状況
(2)他の3個の円グラフ:中央の統合DBから用途別情報を同期抽出して個別のDBテーブルに同期している状況
(3)一番下の棒グラフ:中央の同期統合しているDBを異なる別のDB上に複製している状況
また、これらに関連する各種の検証作業の報告も過去投稿として公開させて頂いており、最近少しずつですが「少し深掘りした、ケースバイケースの詳しい話を聞きたい!!」というリクエストを頂き始めるようになりました。
今回は、少しその中身を掘り下げた「データ・システムの新しい可能性」について、幾つかの「壮大な思いつき」を書かせて頂ければと思います。
データ駆動型DXという流れの中で・・・
最近データ駆動型DXというキーワードが巷を騒がせている様ですが、そもそもデータ駆動の定義をどの様に行えば良いのでしょうか?
因みに良く相談を頂くケースで見られる状況的には・・・
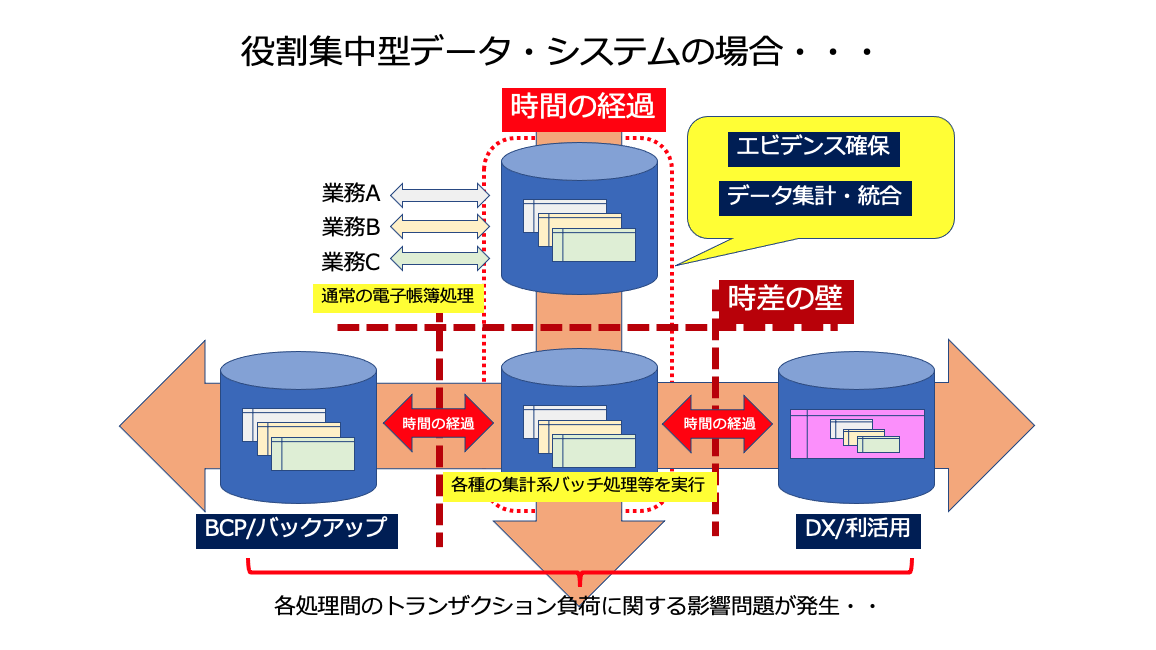
という感じの連携を前提とした構成となっていて、そもそも業務系の電子帳簿システムを適用範囲の拡大という部分だけで巨大化を進めてきた関係上、昨今のDXやデータ利活用といった「後出し系トランザクション(それも結構重量級の・・)」と、「どのように折り合いをつけるか?」という大人の都合に対して、ある意味・・とりあえず対応しました・・的な「暫定解の積み重ね」になってしまっているのでは?と想像しています。
一般的に5W1Hが情報の中に入っていれば、記録としては充分成立する(出来るだけリソースの無駄遣いをしない・・系のデータベースデザインが今も主流だと思いますので)という前提で、データが何時発生したか? という情報としてのタイムスタンプだけを確保して、「具体的な処理は後回しにする前提」で電子帳簿システム上に必要最小限のデータを記録して作業完了!となっているかと思います。
勿論、この仕組みでも充分電子帳簿としては問題無く活用出来ますし、現実的な話をすれば・・「できればその領域を後出し系の処理で掻き混ぜて欲しくない・・・」というのが偽らざる本音なのかもしれません。
これは、「ある意味で既存のシステムとDX/利活用はシステム資源の利用的に見て、利害相反の関係にある」と言っても過言では無い状況なのだと言えるでしょう。
さて、その前提に立った場合に巷を騒がせている「データ駆動型DX・・」をどう実現出来るのか?
単純な思いつきとしては、現在基本的なインフラ技術として熟成期に入っている仮想技術や、最近実用領域に入ってきた!と言われているコンテナ技術を組み合わせて、データ・システム全体の構成を「明確な役割分担に分けて」それぞれに「最適な稼働環境(構成仕様)を与え」、それぞれの間を低遅延のデータ同期技術で連携させれば良い・・・・というコンセプトが考えられるかと思います。
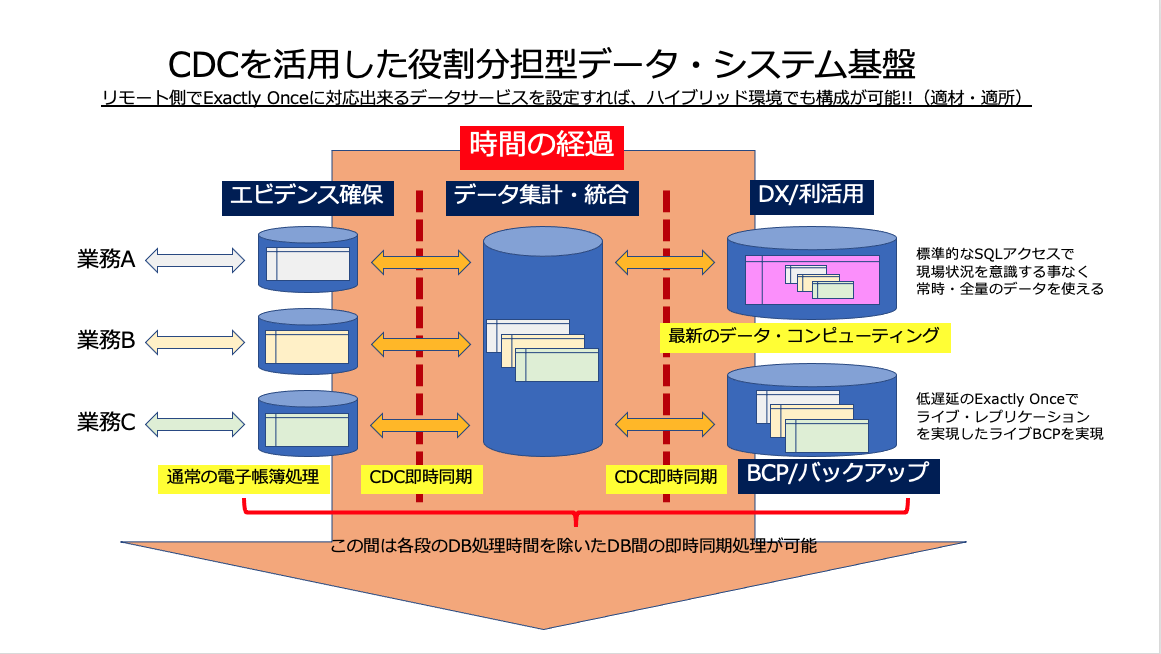
そこで、取り急ぎ、このコンセプト名を
役割分担型データ・システム (Role-Based Data System)
と命名して更に深く中身に突っ込んて行く事にします。
CDC起点のデータ処理・・・
CDCという技術コンセプト自体は、かなり以前よりデータ界隈では良く使われる仕組みでもありますし、また以前の検証で使ったEqualumにも採用されている一般的なコンセプトになります。
勿論、その実装に関しての流儀・流派は多数存在していますので、CDCという外枠だけで一律に括ってしまう事は非常に危険ですが、データ界隈、特にデータベース領域での作業起点を扱うアイディアとしては、非常に便利であると言えると同時に、既に多くの具体的な実装形態が市場で各種の製品に組み込まれて使われていますので、もしかすると既に普通に出会われているかもしれません。
「役割分担型データ・システム]におけるCDCは、データベースに標準機能として搭載されている「ログ系の機能」を遠隔から処理しますので、既存の環境において
(1)CDC対応のログ機能が利用できるか?
(2)ログ参照権限をもつユーザアカウントを1個作成する(クエリを投げたりしないところがポイント)
の2点が可能であれば、基本的に即時の同期ストリーミング処理を実現する事が出来ますので(ログの機能に関しては、かなりのケースで標準的に利用されているかと思いますし・・)、その部分に対する大改造などを行う事なく「同期先以降で各種の処理をオンタイムで実行する」事でできるようになります。
役割分担型データ・システムにおけるCDCの役割
今回の役割分担型データ・システムでは、このCDC技術を「オリジナル側(ソース側)の状況変化取得の起点とする」事で、以前検証したEqualumを基盤内におけるデータ流通の要として活用し、ターゲット側との組み合わせにより「Exactly Once処理対応が可能」な場合は、遠慮会釈なく「そのデータ処理品質を徹底的に使い倒す」事を基本にしています。
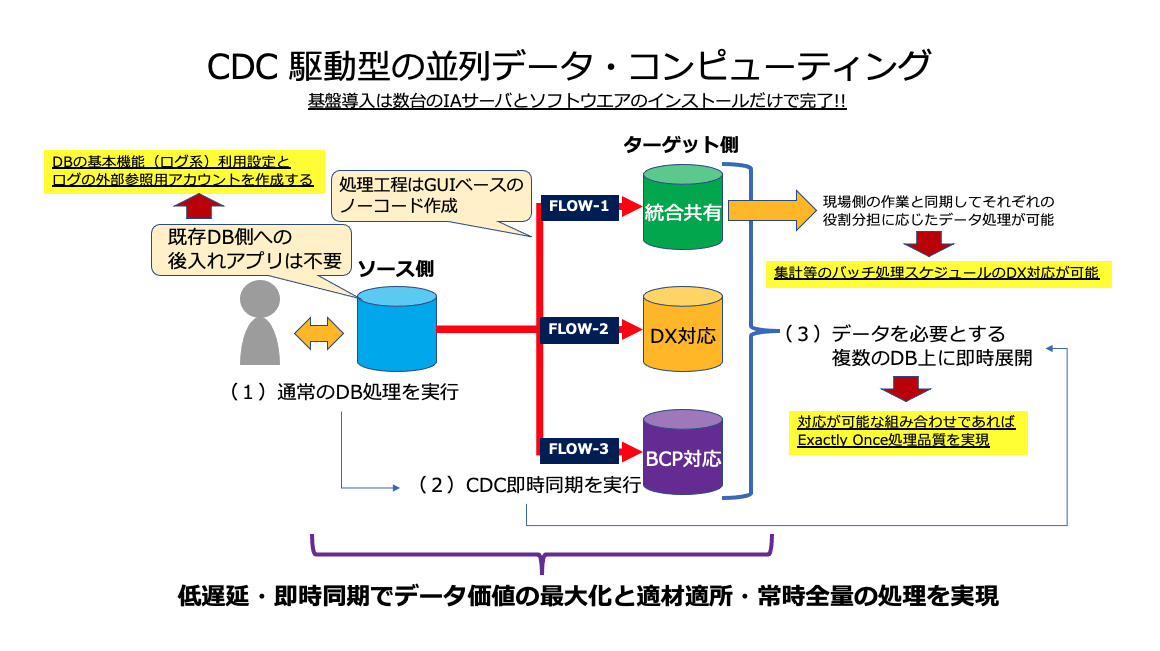
勿論、あくまでもCDCは起点の技術なので、最終的にターゲットDBに処理データを着地させる作業に関する精度・品質を維持しなければなりませんが、前述の「Exactly Once仕様を活用」することで、その辺の問題に対しても「複雑な専用設計と個別開発を行わず」に、シンプルにIAサーバ数台とソフトウエアのインストール(スクリプトを走らせるだけ・・)作業だけで対応・利用が可能になります。
実際の動き的には・・・
役割分担型データ・システム内に展開されるCDC設定されたデータベースでは、何かデータ処理的な変化が発生すれば、極めて低遅延で外部からの参照処理(Equalumの場合は、後出しのサービスやアプリをDBサーバに入れる必要がありません)によるCDCストリーミング処理が起動し、一つのオリジナル側データ処理を「複数の役割分担先DBに対して即時同期する」ことが可能です。
また、その同期先でオリジナル側に影響する事無く「時系列透過な戦略的バッチ処理」等を実行出来るようになりますので、「バッチ処理を本来のバルク系集計処理のために使う」事が出来ますので、処理時間をユーザ都合で設定出来ると同時に、同期先以降での作業変更などに関しても、電子帳簿の現場側を意識することなく作業を実施する事が可能になります。
因みにEqualum環境では、即時同期のストリーミングFLOWの作成も、基本的にGUIベースのエディタを使った「ノーコード」で対応が可能になるので、仕組みの拡張や変更に対してもユーザレベルで柔軟に対応出来るようになります。
因みに・・・・CDCの即時同期はこんな感じで行われます・・
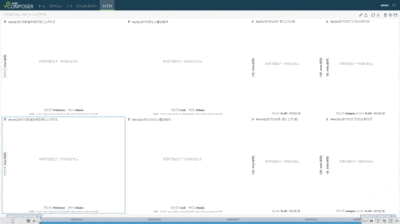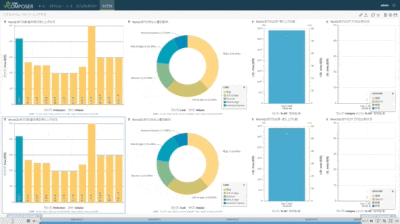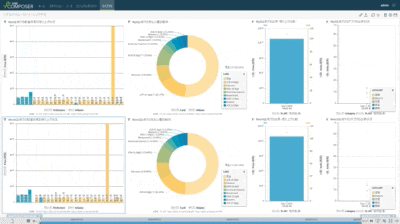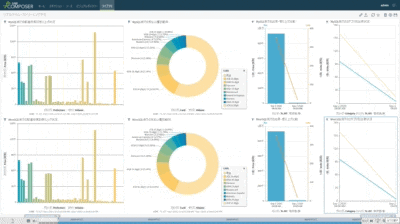
以前に検証報告させて頂いた通り、上半分がオリジナル側のMySQLで、下半分がターゲット側のSingleStoreのテーブル状況になります。
各段での分散データ処理を低遅延で次段へ同期していく・・・
データ処理を一極集中型から、適材適所・常時全量での分散並列的な分担構成処理に変える場合の「最大のポイント」は、多分シンプルに同期速度と処理の精度・確実性になるかと思います。
同期の速度に関しては、既に幾つかの検証報告等で動画共有させて頂いておりますので、Equalum社の担当者に対して「Exactly Onceに対応出来るDB(サービス)は?」という問い合わせをした所・・・
データベース製品群
Oracle
MS SQL Server
MySQL
PostgreSQL
SingleStore
クラウド系DBサービス(順不同)
Amazon SQL Server RDS
Amazon PostgreSQL RDS
Amazon Maria RDS
Amazon Oracle RDS
Amazon MySQL RDS
Amazon Aurora PostgreSQL
Amazon Aurora MySQL
Amazon S3
Azure Database for MariaDB
Azure Database for PostgreSQL
Azure Database for MySQL
Azure Blob Storage
Azure Data Lake Storage
Azure Synapse Analytics
Azure SQL Server
Google Cloud Dataproc
Google Cloud SQL – MySQL
Google Cloud SQL – PostgreSQL
Google Cloud SQL – SQL Server
Google BigQuery
Google Cloud Storage
との事でした。
従って、既存のローカル側環境(オンプレミス)とリモート側環境(マルチクラウドやデータセンター)との連携において、これらの組み合わせを効果・効率的に活用する事で「適材適所・常時全量」の分散処理型データ・システムを構成する事が可能になるということになります。
DXのために、全部を作り直す必要が有る?
最近、データの利活用で新たな可能性を!!的な取り組みが、各企業・団体などで積極的に取り組まれる様になってきており、データをそれぞれの通常活動のプロセスにおける「再生可能エネルギー」と位置付け、データを経営資源や活動改善の源泉として新たな価値を創造しよう!・・という動きが多方面で一気に見られる様になってきました。
またこの動きを・・・ある意味「従来型の電子帳簿型オペレーション」から、「BIやAI系の最新技術を最大限に活用するデータ・コンピューティング」の考え方になってきたのだと捉えれば・・・・
あれ?そもそもデータ駆動型DXなんて既存システムの要件定義にも無かったし、それを振り回せる様な仕様の稼働環境ではない・・・・ という「前向きなジレンマ」に遭遇する事になるのも当然の状況なのではないか・・と思います。
発想の転換で・・・
さてこのジレンマに対して、「DX対応の為に既存の長年掛けて育ててきた、虎の子の電子帳簿型システムを基本部分からガラポン!しなければならないのか?」 という・・極めてシビアな判断・決断を下す状況に遭遇する可能性が出てた場合、モア・ベターな選択肢は何か無いのだろうか?と言う話になるかと思います。
また、ある意味でデータ駆動型DXに取り組もうとした場合に定番的に出くわす、最大かつ深刻な状況 を判断して解決しなければならない状況に追い込まれ、現実的な状況と擦り合わせた段階で・・・多くのケースで二の足を踏むような行き詰まりや問題のネタになっているのではないかと想像しますが・・・実際の現場では如何でしょうか?
DXの為にリスクを取って、程よく枯れた既存のシステムを全部作り直す必要が有るのか?
また、DXとは少し趣が異なりますが、昨今の業務統合や企業の合併・買収に伴う基盤刷新まで含めれば、意外にかなりのケースで「持続発展可能型データ基盤」の問題がクローズアップされてきている気がしています.....
「この一連の作業によって発生するであろう、既存業務系への影響や問題発生リスク・・・」
「基本的に粛々淡々と稼働中の仕組みは、万全の準備と体制で計画的に作業を行いたい・・」
等・・・
ではどうするのか?
そこで今回は、一つのアイディアとして「役割分担型データ・システム」なるコンセプトを妄想したわけですが・・
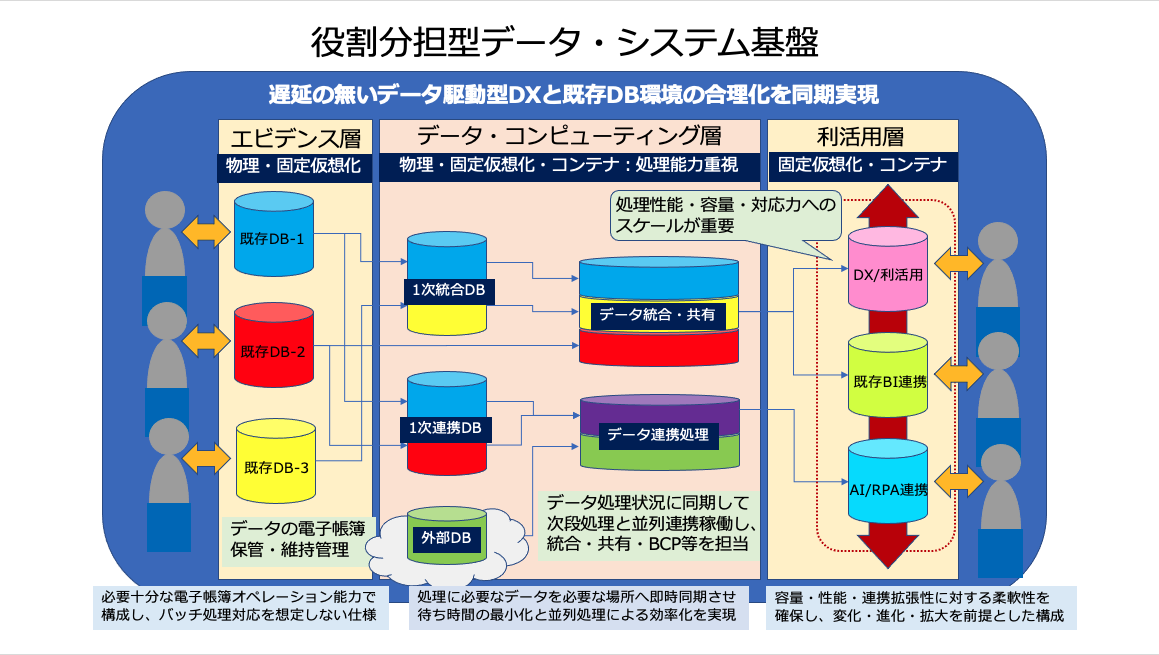
このコンセプトの最大のポイントは、基本的に現在稼働中の現場システムに関しては、データベース側が標準的に持っているログ系機能の適用に関しての状況確認を行い、EqualumのCDCストリーミング関連設定だけを追加して「そのまま次回の更新までは放置!」を行い、既存の現場側システムに関しては「エビデンス確保の電子帳簿」としての役割に徹してもらいます。
勿論、このことにより昨今指摘されている「データのサイロ化問題」は、建設的且つ前向きに無かった事にすると同時に、同期先のデータベースを「適材適所」で構成し(マルチ・リモートとのハイブリッド連携など)、EqualumによるCDC即時同期をそれぞれ異なるデータベース上に実施する事で、データに関する処理的にそれぞれが独立して役割分担に応じた並列データ・データコンピューティング処理を実行していく形にします。(勿論、それぞれの分担先で行われた処理結果も相互に即時同期させて、より高度で最終的なデータ処理に向けた連携稼働を実行させて行く事も可能です)
具体的には、このような感じの仕組みをノーコードで作る事ができます。
視点・発想を少し変えると、最新・実績のクラウド技術を最大限に活用したプライベートデータシステム環境が可能になる状況・・・凄い時代になったかと。
動画の状況は・・・・
(1)全てのチャートが異なるDBテーブルを可視化している
(2)左側の上から5個のDBテーブル個別にランダムな購買情報を作成し連続挿入している(棒グラフで可視化)
(3)5個の個別テーブル状況を即時同期で中央の紫系円グラフが可視化しているDBテーブルに統合
(4)統合テーブルから目的別に3個系統のデータを抽出し3個の異なるDBテーブルに即時同期(青緑系円グラフ)
(5)統合テーブルの状況を即時同期で異なるDBテーブルにレプリケーション(左側の一番下の紫系棒グラフ)
この手の話をすると・・・
因みに、この様な説明・提案を行うと殆どのケースで・・「非常に興味深く可能性を大きく感じますが、費用面で厳しそうなので・・(多分、金融系等の専用環境をイメージされるのかと)」という急ブレーキを踏まれるケースが多いのですが、ここ数年のクラウド技術(当然通信ベースのマルチクラウド・データセンターとオンプレミスを透過的に連携させる系のソリューション群)を上手に組み合わせて、その間を戦略的に維持管理出来るように作り込むことで、数台のIAサーバ・クラスタリングとソフトウエアのインストールだけで、誰でも活用できる環境が手に入る状況になっているという点は、是非!この機会にご理解頂いて記憶の片隅に置いておかれると、この類の問題解決の際の選択肢や発想の展開範囲が非常に大きく柔軟性の高い構想になるかと思います。
基盤はシンプルに持続発展可能形で・・・
さて、CDC技術を起点としてExactly Onceなデータパイプラインをノーコードで作成し、それぞれに明確な役割分担を行った(構成仕様や担当するアプリケーション等)データベース間を連携させる事で、「もしかすると・・マジで役割分担型データ・システムって・・可能かも?!」と爪の先程でも思って頂ければ、今回の話の帰結としては「ほぼ満点のデキ」になるかと思います。
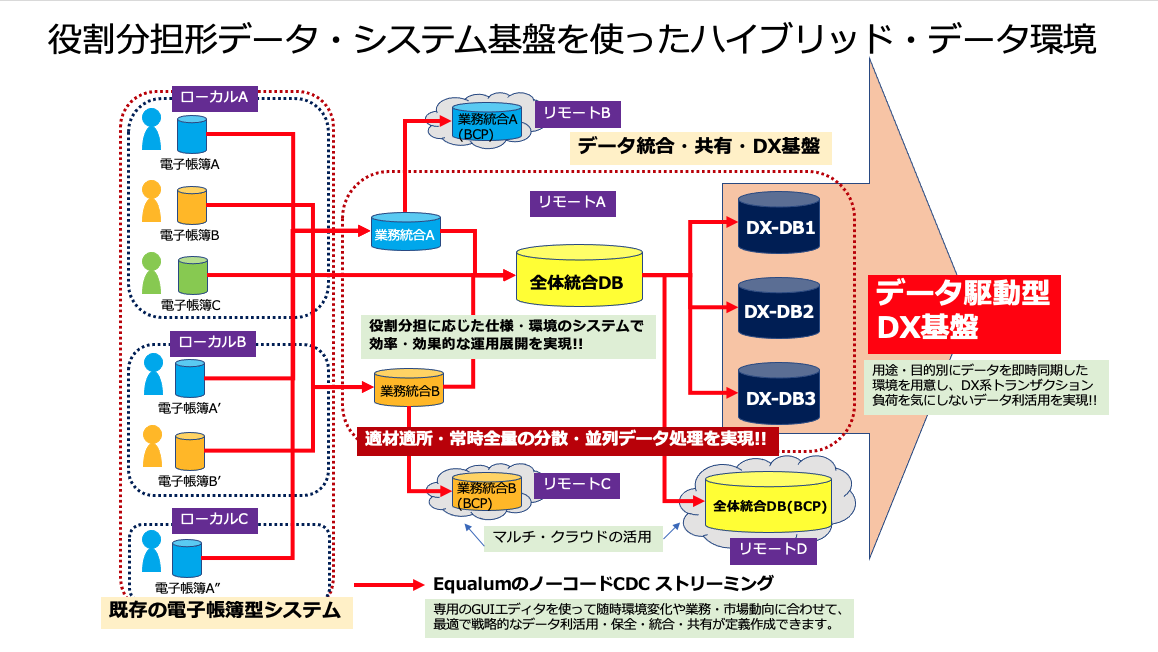
重要な点は、この「役割分担型データ・システム」の場合、XXありき!ではなく「適材適所・常時全量」のデータ処理基盤であれば、ローカルだけでも完結できますし、既存のデータセンター環境と連携させる事で「プライベート型ハイブリッド環境」も可能ですし、複数のマルチクラウド(適材適所で選択)と連携させたハイブリッド環境もシンプルに実現が可能になるという、未来を縛らない選択の自由度と可能性の維持が出来ると言う部分になります。
間に合わないデータは使えない
使えないデータに意味は無い
意味の無いデータに価値は無い
この極めてシンプルであり、今までは「いろいろな意味(特に大人の都合。。)で実現が難しかった」データ界隈での命題について、今回の「処理に最適な構成(仕様)や場所:適材適所」と「CDC&Exactly Onceを活用した即時・低遅延なデータ同期:常時全量」が両立出来る基盤であれば、もしかすると劇的に色々な事が前に進められる・・・かもしれないという可能性を感じて頂ければ幸いです。
役割上の「静」と「動」や割り当てられた処理に最適な構成を与えて、それぞれの作業状況を必要な全ての関連DBに即時連携し、特に「動」側の構成に関してはDX活用や明確な季節繁忙期の存在に合わせて、新設、増設、廃棄が出来るように想定しておくのもポイントかもしれません。
ヌルヌルとした移行の実現・・・
これは、今回の妄想ついでの話になりますが・・・これからのデータ・システムは、一旦カットオーバーすると「基本的に次の更新までは触らない・・」というコンセプトではなく、データの即時同期を上手く活用しながら、DX等で得られたノウハウや技術を活用し、全面刷新・更新型ではない基盤移行(カット・オーバー型ではなく、スイッチ・オーバー型で)という発想も十分実用性が有る話になってきた(技術環境的に・・)という事なのかもしれません。
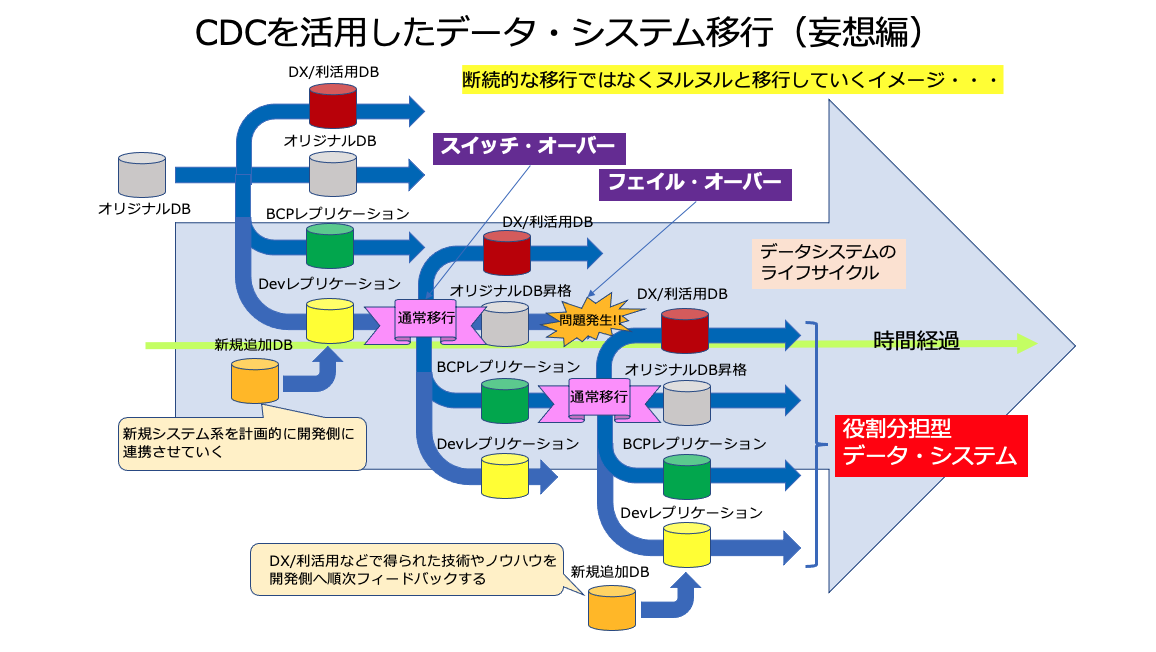
ヌルヌルとした移行・・・もしかすると発想次第では面白い展開が可能になる気が・・・(苦笑)
24時間365日を粛々淡々と支え続ける事が出来る仕組み
役割分担型データ・システムでは、基本的に通常のデータ処理系バッチ(集計系など)は、即時同期先で随時実行出来る様になりますので、一般的なデータ処理界隈で劇的な地殻変動をもたらす可能性と、データ処理自体を正しく保守本流のど真ん中へ戻す大きな変革が実現できる可能性が出てきます。
大きな前進と言えると同時に、「従来のDWHをライブDWHに進化」させる事が可能になります。
また、ウエアハウスではなく「データ・コンピューティングに特化した構成」上に即時展開し続ける事により、「始めに要件定義有り」のウエアハウス型ではなく、「来たものドン!と来い!!」型の「データ・コンピューティング・ラボラトリー:DCL」に進化させられるという点も重要なポイントかもしれません。
要件定義が出来るのであれば、DX云々ではなく最初からシステムに組み込んでおけば良い!
現場発想の突拍子も無いアイディア(ベンダー側から見て)をサポート出来るのがDX基盤!
ノーコード・ローコード環境の進化や、今後は各種学習系を組み込んだAIソリューションの民主化が急速に進んでくると思いますし、既にその兆候は明確に出始めていると思います。また、アジャイル・xxOps界隈もドンドン進化し続けている状況下においては、データ基盤が「未来の選択肢を出来るだけ縛らない」という発想が重要でしょう。
補足を少し・・・
前回の投稿で、オリジナルのDBに対して意図的に改竄を仕掛けて、その改竄後のデータを元に戻すという検証を行いました。
この検証のポイントは「改竄を戻す」という事ではなく、 オンライン上にExactly Onceの処理結果を、時系列シーケンシャルに残すことが設定だけで可能で有る・・ という点と、オリジナルDB以降のデータベース間でCDCストリーミングを使ったFLOW連携を設定した場合、SQLやストアード・プロシージャをプログラム環境にした、多段・並行処理型データ・コンピューティングが実現できる!・・かもしれない、という部分がポイントになります。
前回の場合は、そのデータ・コンピューティングを内向きに使っての「データ・オンライン自動監査」処理を、極めて簡単な仕組みで構築検証し、ターゲット側のモード設定だけで「データベースをログレコーダーとして扱う」事が十分可能で有ることを確かめました。
コンテナ環境とデータ・コンピューティング
オリジナル上で発生する通常のデータ・オペレーション結果を、コンテナ上に展開する複数のDB上で分散並行処理(勿論、その過程をさらにCDCストリーミングを活用して。参画するDB間での途中経過融通を行なっても良いかと)し、最終的にトラディショナルな環境のデータベースに着地させる仕組みを作れば、多くのケースで現状の枯れて安定している現場環境をひっくり返してガラポン!する事なく、コンテナ環境上のデータ・インテグレーション(この環境のメリットとしての柔軟性・即効性をフルに活用)を効果・効率的に設計する事により、懸案のデータ統合問題やデータ駆動型DX対応、さらにはオンライン即時同期型のBCP環境も可能になるかと思います。
「静」と「動」のメリハリを「適材適所」で効果・効率よく展開し、「常時全量」のデータ処理基盤上で各種のデータ活動を進める・・・・
その辺が・・・役割分担型データ・システムが得意とする所であり、お役に立てる領域なのではないでしょうか?
今回のまとめ
今回は、持続発展可能型のデータ基盤を狙った、「役割分担型データ・システム」妄想について徒然なるままに書いてみました。多分、この手のアイディアはデータ界隈の歴史の中で何度も出てきているかと思いますし、専用設計で個別開発型のBIGプロジェクト前提であれば、似た様な仕組みを実現できるかと思いますし、専用システム的に既に稼働しているケースも存在しているかもしれません。
しかし、昨今の技術革新や業界的な経験値の向上に伴い、汎用の仕組みの組み合わせで「結構リアルなデータ即時同期型の並列処理の仕組みが作れる・・かもしれない!」という点はご理解頂けたかと思います。
また、適材適所・常時全量なデータ処理を前提にしておけば、ある意味で「将来的に何が来ても対応できそう・・」ですし、明確な役割分担に対する「ピンポイントの稼働仕様」で構成できれば、「実は幾つかの課題を透過的に高い投資対効果で実現し易くなる」かもしれません。
何よりも・・今までの電子帳簿型システム自体が、その設計構築段階で「多分・・・・現在巷を騒がせているDXやデータ利活用は想定外」だと思いますし・・・・その想定外の解消の為に「大きなリスクを取って、安定稼働している既存の仕組みから全部やり直す」か?・・・・という「清水の舞台から飛び降りる」的な決断を強いられるのであれば、シンプルに「役割分担型データ・システム上で、データ処理の時系列透過性を実現し、適材適所・常時全量なデータ運用を」・・・というのも一つの選択肢になるかと思います。
発想の転換をサポートできる技術・ソリューション的な環境が、ようやくこれらの課題解消や新たな可能性創出に対して追いついてきた・・という事を是非この機会に記憶の片隅に置いておいて頂ければ幸いです。
謝辞
本検証は、Equalum社とSingleStore社の全面バックアップにより実施しています。この貴重な機会を提供して頂いた両社に対して感謝の意を表すると共に、本内容と両社の公式ホームページで公開されている内容等が異なる場合は、両社の情報が優先する事をご了解ください。