今回は、前回のKafka部分をノーコードで処理した、データパイプライン接続設定を使って具体的なFLOWをノーコードで作成していきます。
前回は、KafkaとSPARKに関する作り込み部分を、簡単なGUIベースの設定画面処理だけで完了出来るEqualumのノーコード機能を検証しましたが、今回は前回設定したテーブルのCDC連携機構を使って、その先のFLOW処理を幾つか付け加えたリアルタイムストリーミング処理をノーコードで作成してみたいと思います。
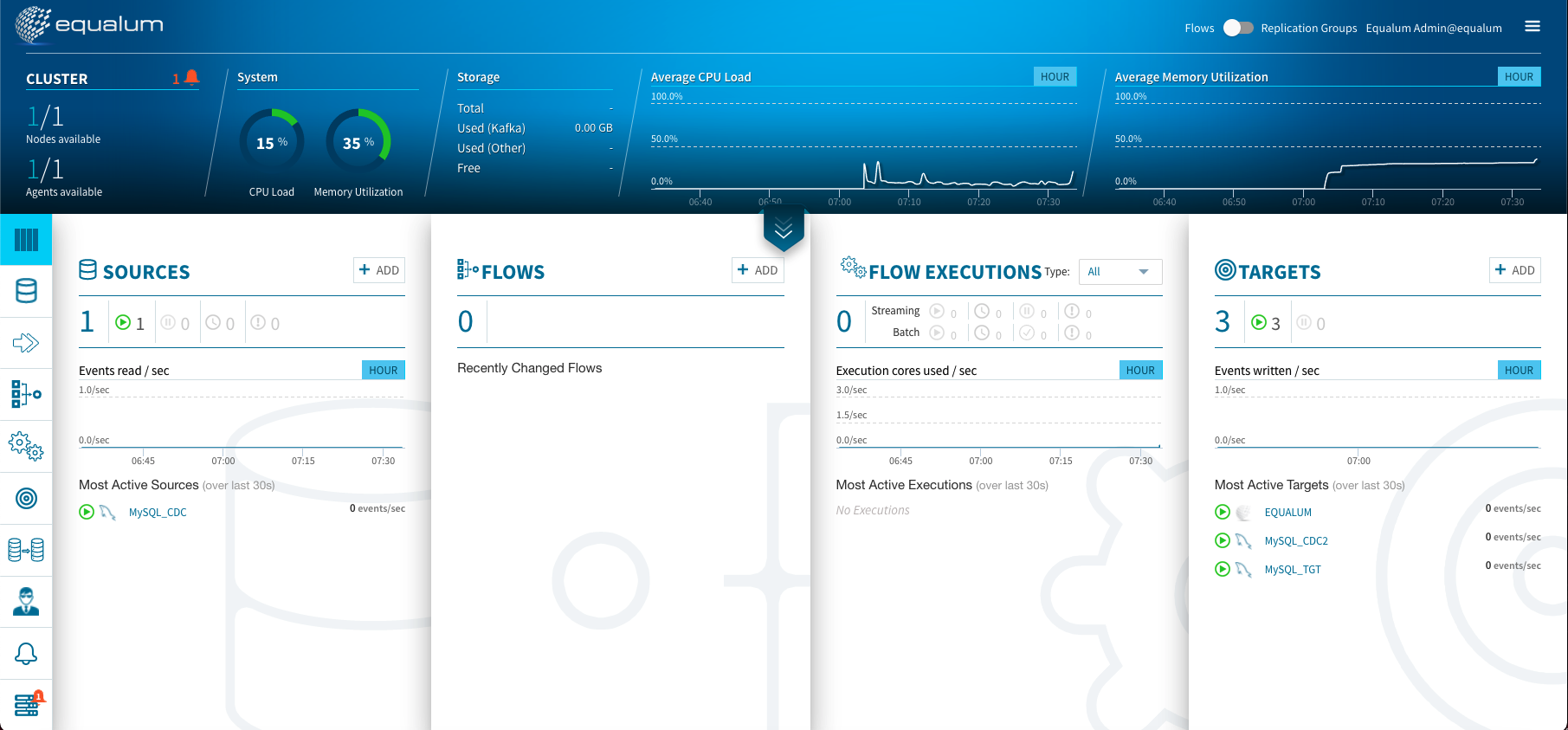
まずは、GUIベースのFLOWデザイナーを起動する。
Equalumのコンソールに戻って、左から2番目のFLOWSを選択します。
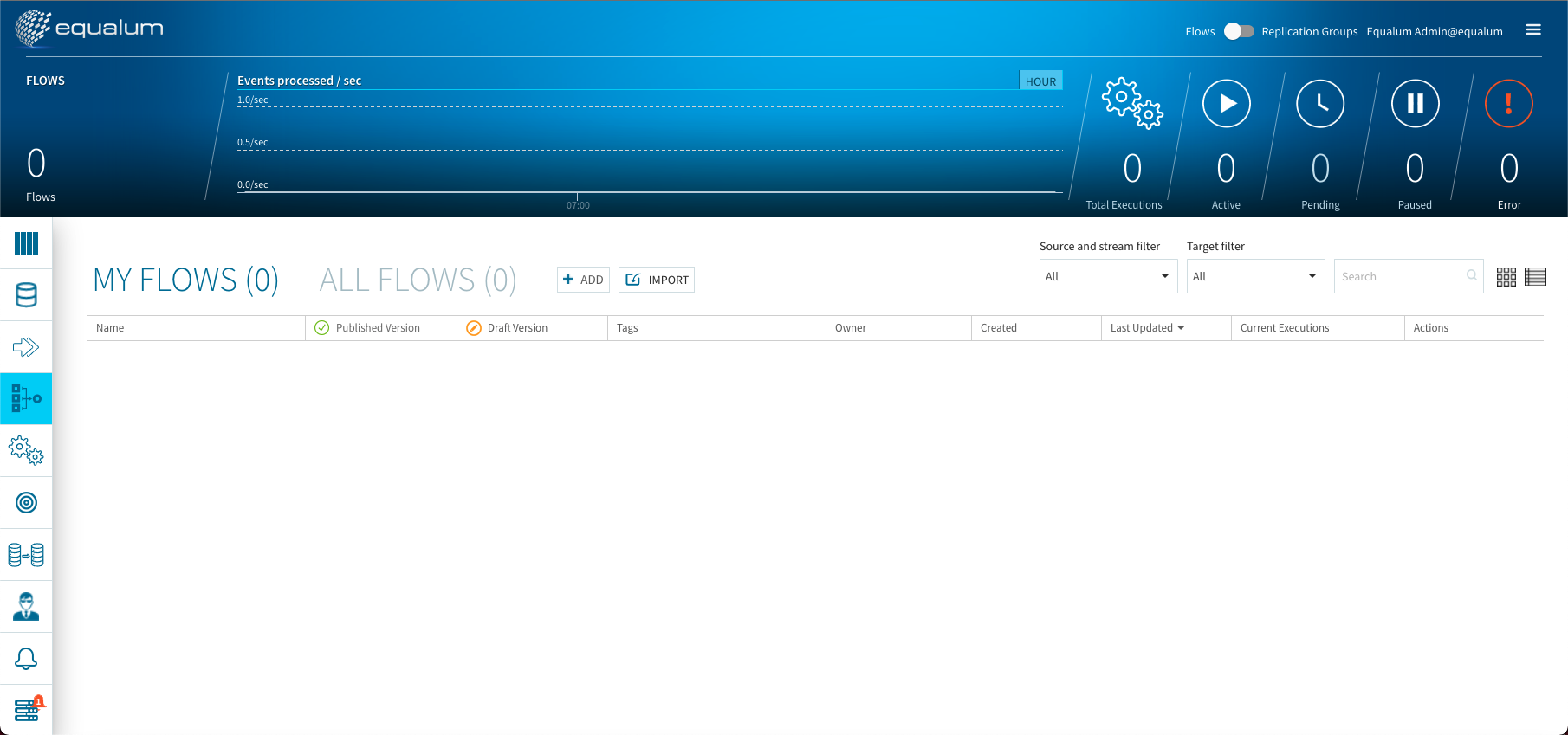
FLOWの編集画面になるので、マウスを使って必要な処理を設置・定義していきます。
画面上部中央の**+ADDを選択して、GUIベースのエディタ画面に移ります。
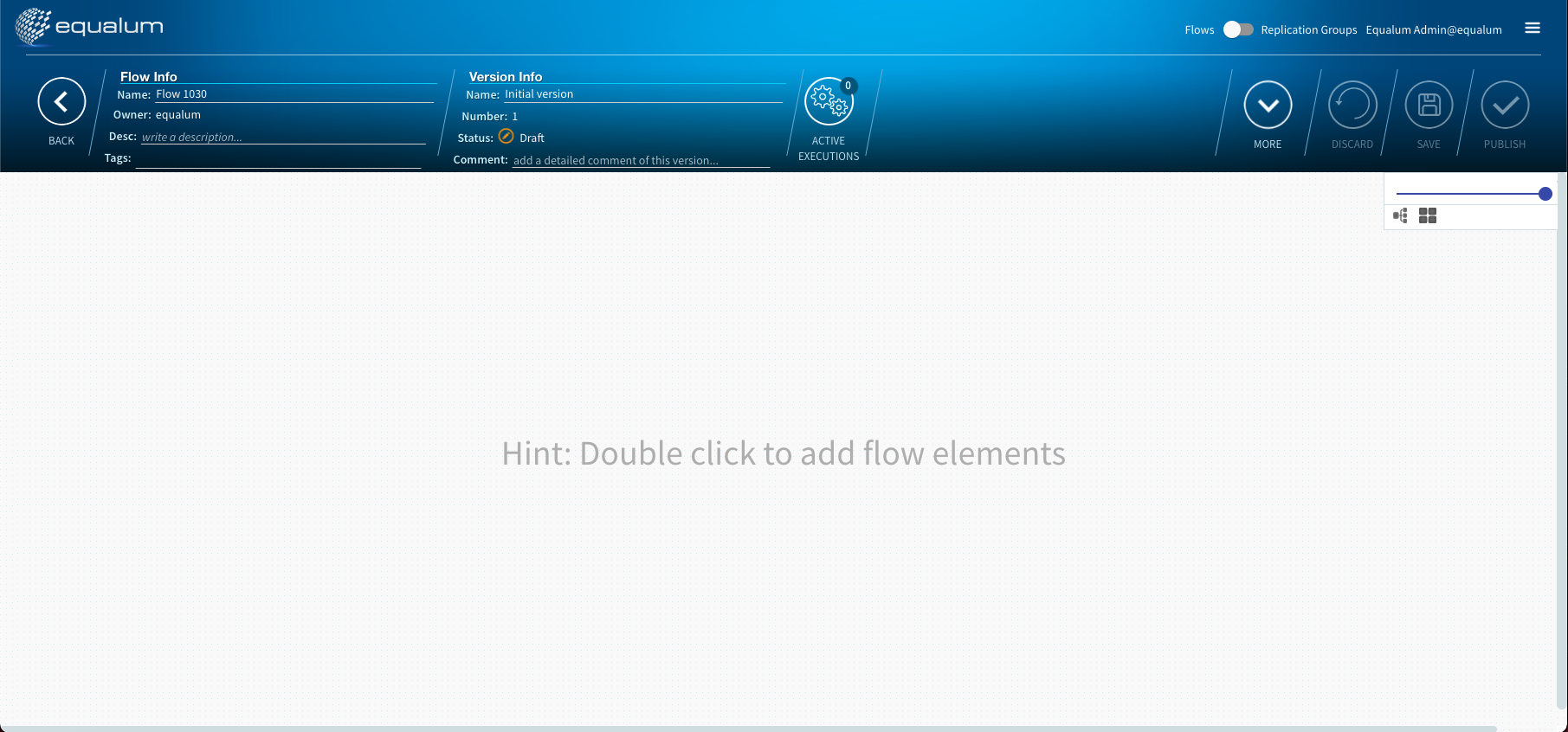
基本的には、マウス操作でFLOWの処理順序をデザインし、それぞれの必要項目を設定・選択して行くだけで作業が完結出来ます。
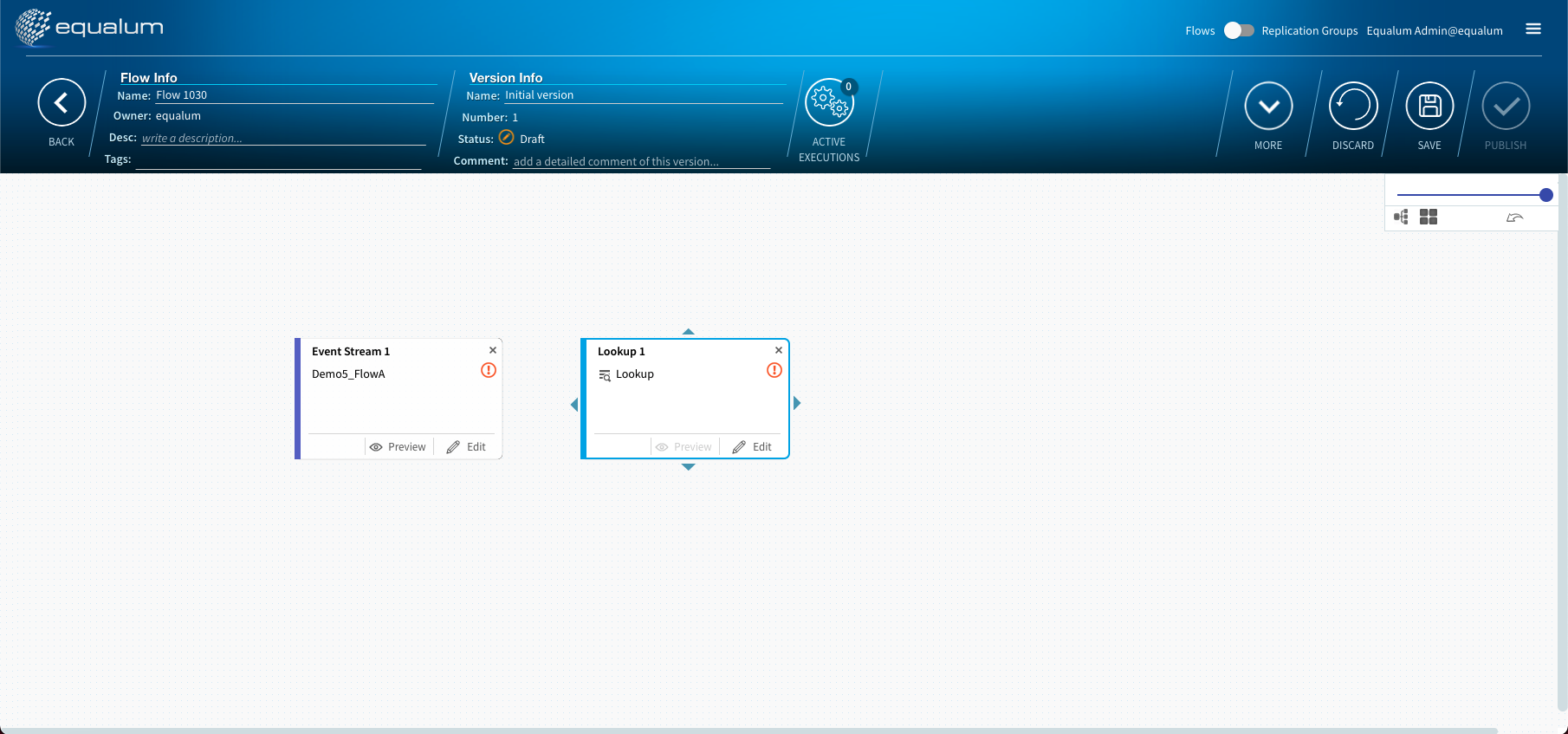
最初にマウスのダブルクリックでポップアップ・メニューを呼び出して、最上流部分のCDC設定された起点になるテーブル選択を行います。
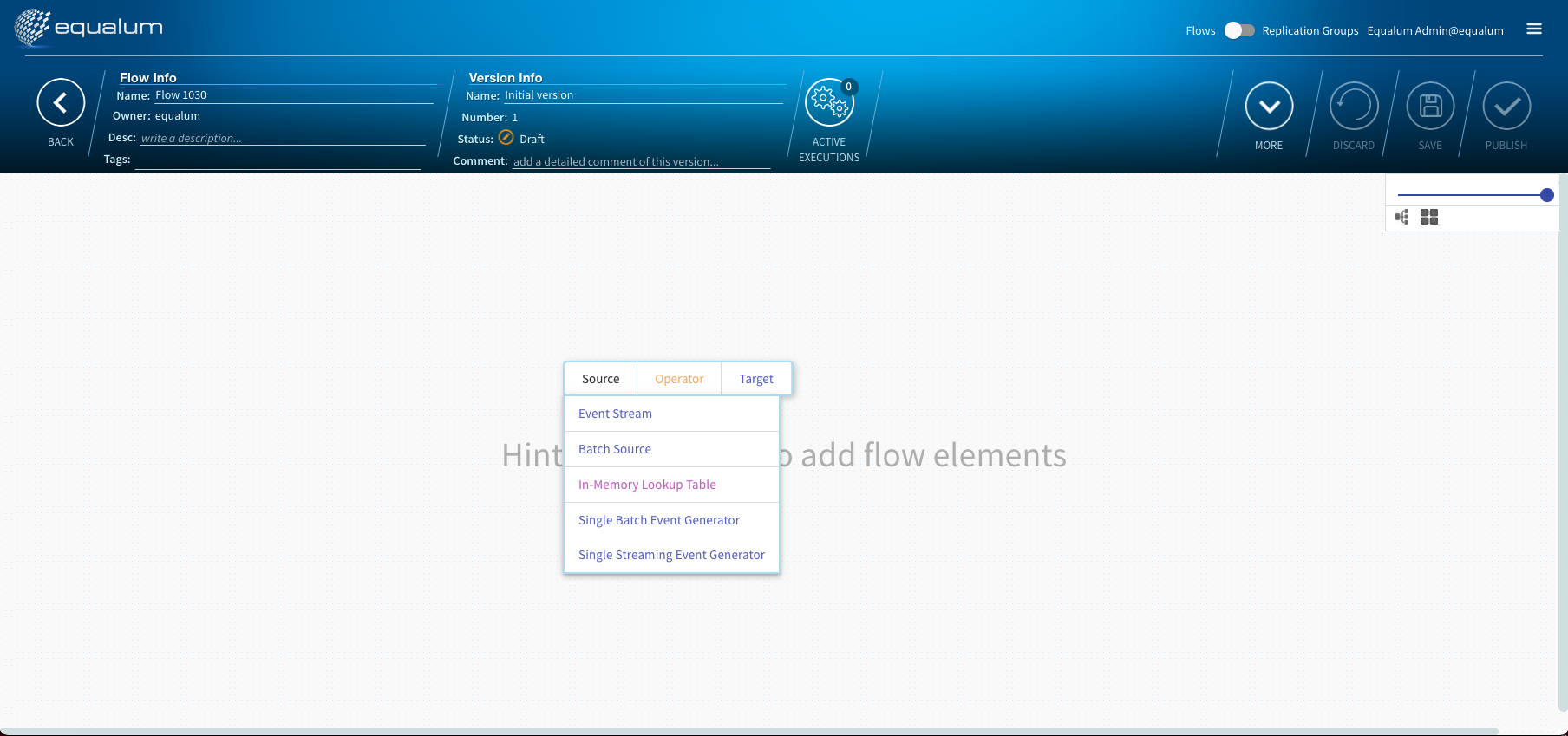
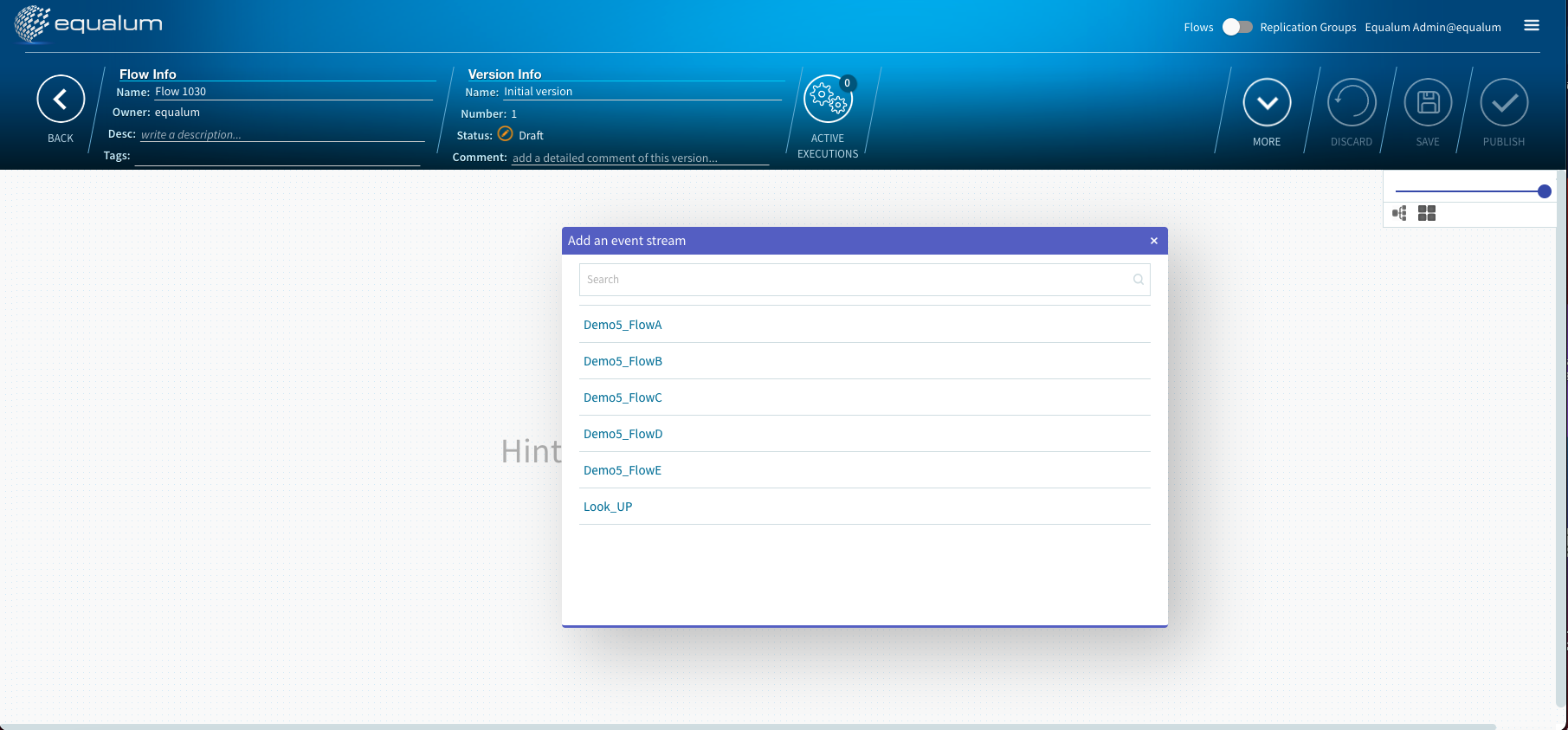
以降の具体的な処理手順の設定も同様にGUIの画面上に処理エレメントが出てきますので、次にこのエレメントに対して処理を定義・設定して行けばOK!です。
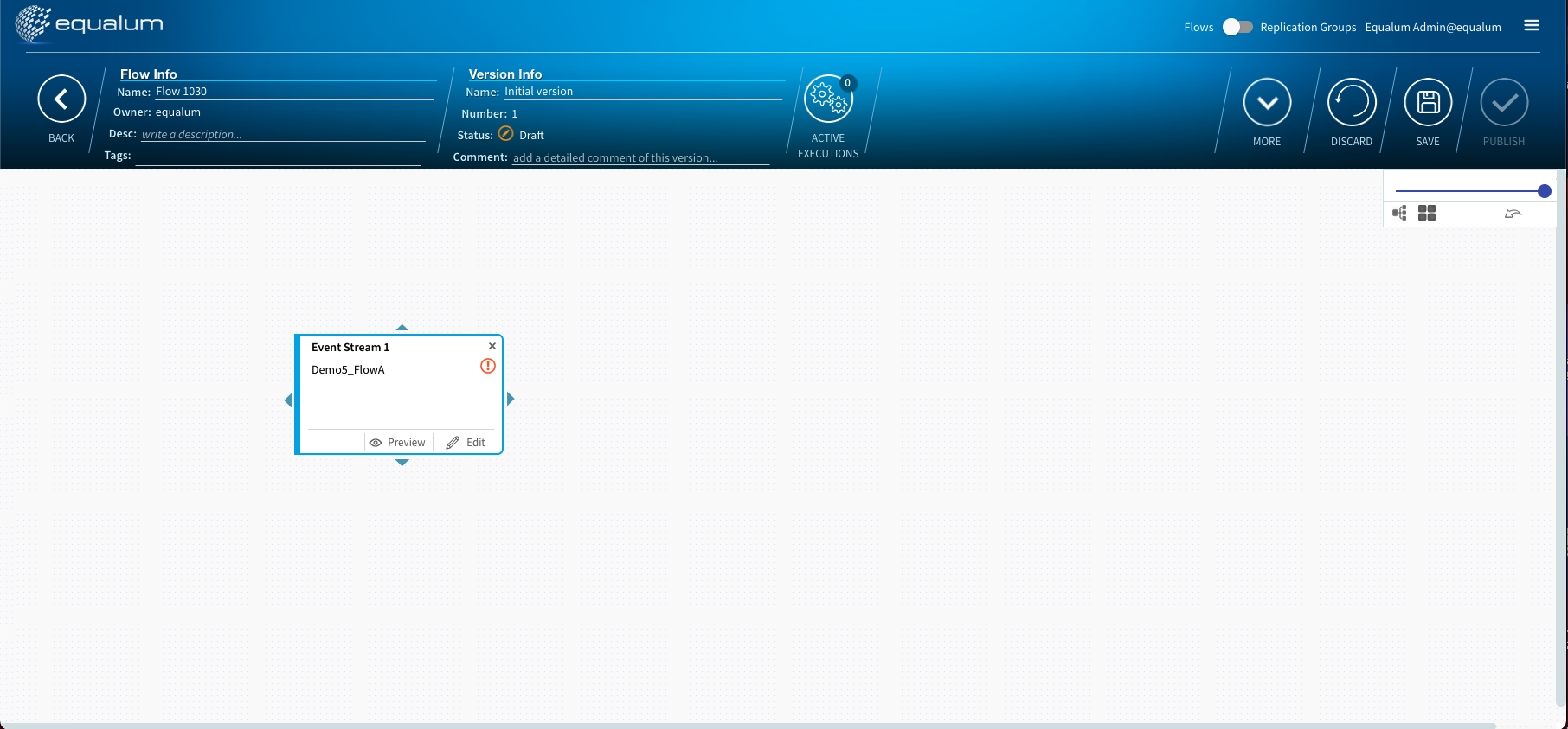
これで、かなりハイレベルなリアルタイム・ストリーミング型データ・パイプラインの第1段階は終了です。
試しにPreview**を選択してみます。
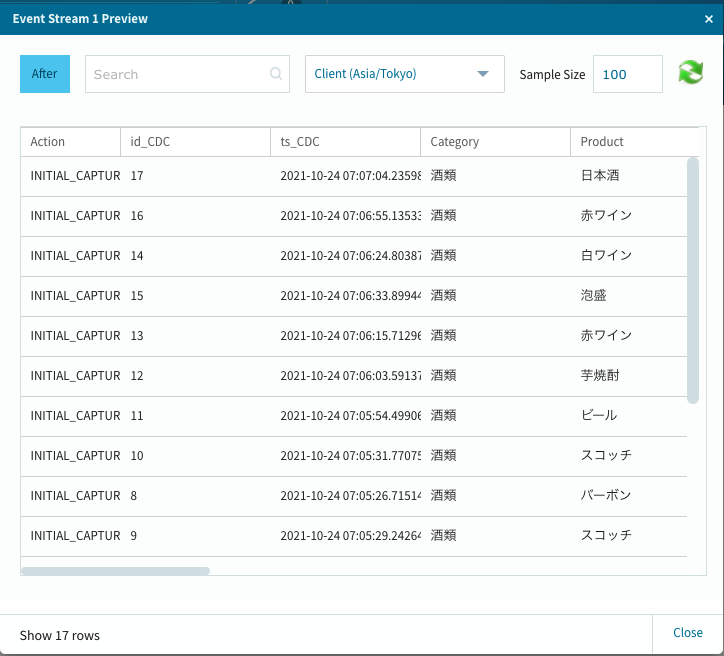
このときに選択したテーブルにデータが既に存在している場合、Equalumがその内容を最初の20個まで自動的に呼び出してくれるので、データパイプラインが上手く立ち上がっていることが確認出来ます。
実際のFLOW処理部分を作成する
データが取り出せる事を確認出来ましたので、取り出したデータを順次ストリーミング処理する流れを作って行きたいと思います。
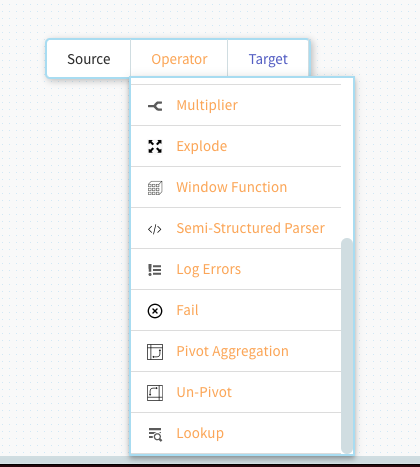
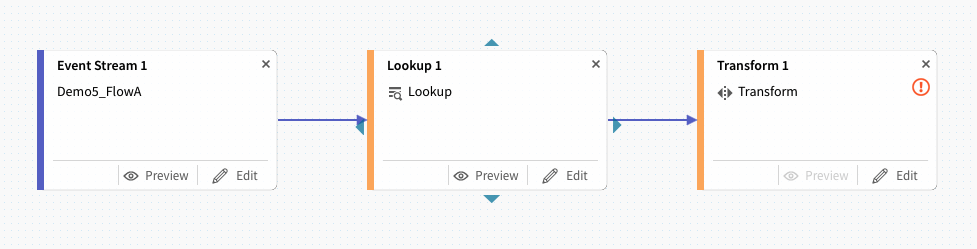
先程と同様に、マウス操作でポップアップ・メニューを呼び出しOperatorからLookupを選択します。
先程設置したテーブルをマウスを使って上下左右に有る三角マークを使って接続します。
Editボタンを選択して必要項目を選択・設定します。
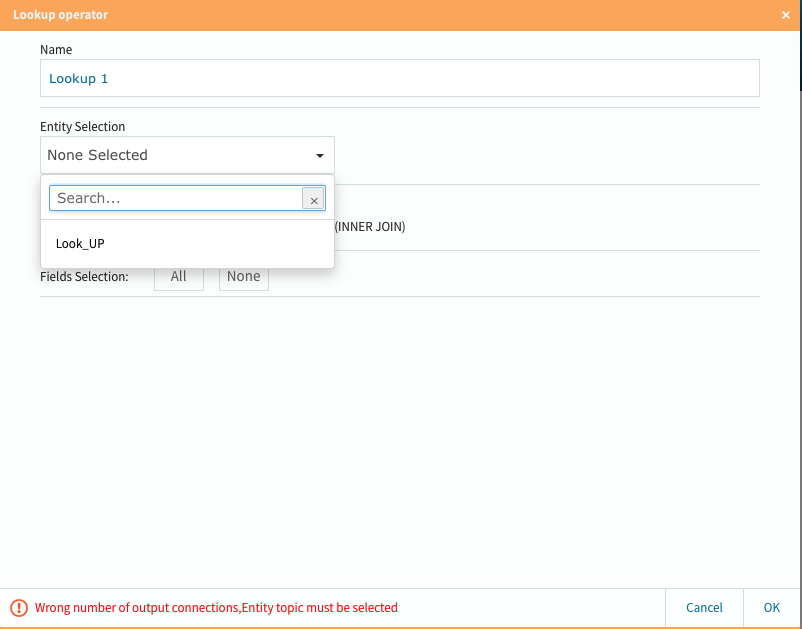
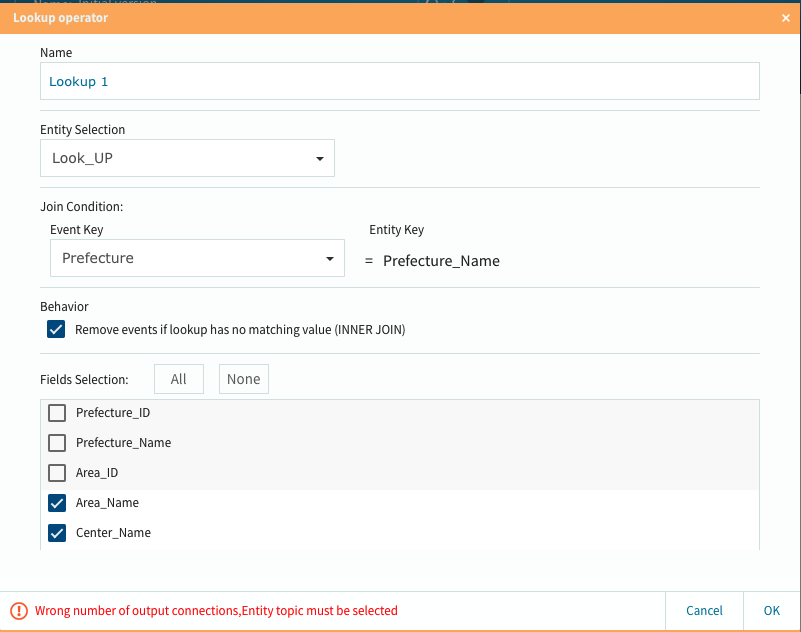
取り敢えず設定が完了したので、右下のOKボタンを選択します。
同様にTransformを選択します。
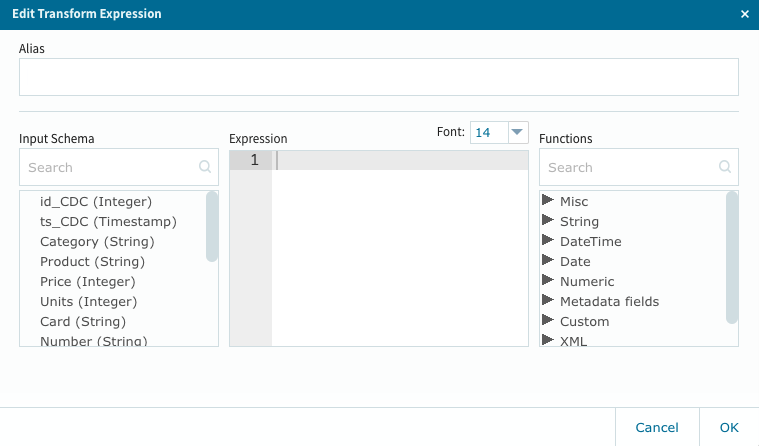
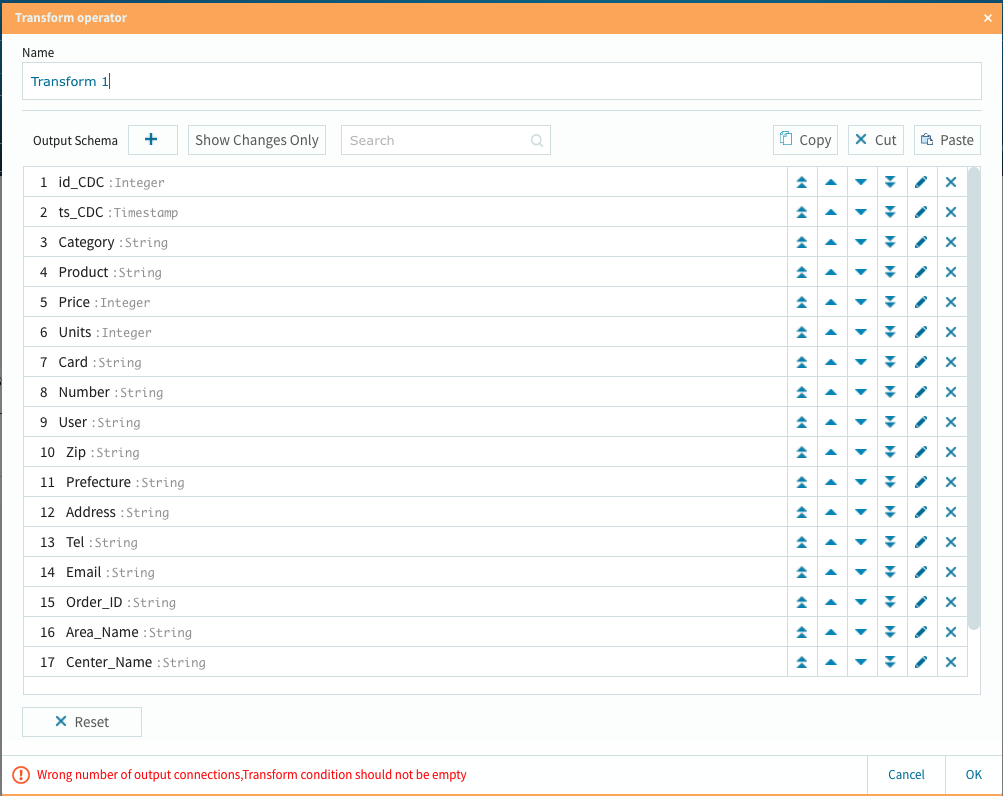
此処では、購入金額の総計と消費税、各店舗商材毎に異なるポイント計算とそれぞれの派生カラムを設定します。
基本的にはExcel等の操作と同じですので、それの環境での類似経験が有れば簡単に作業を進める事が出来ると思います。
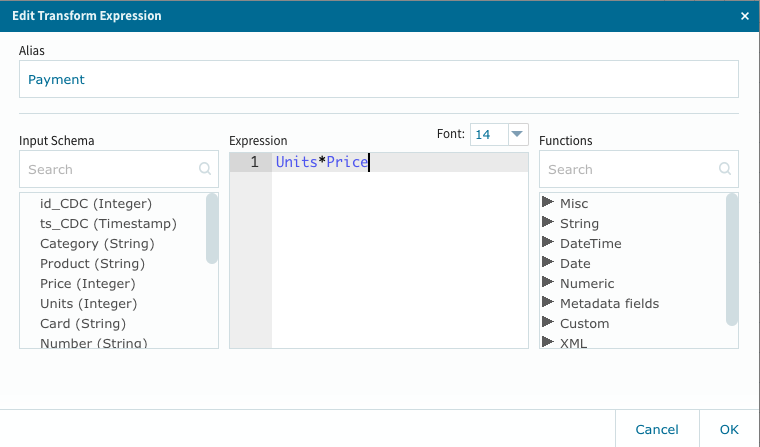
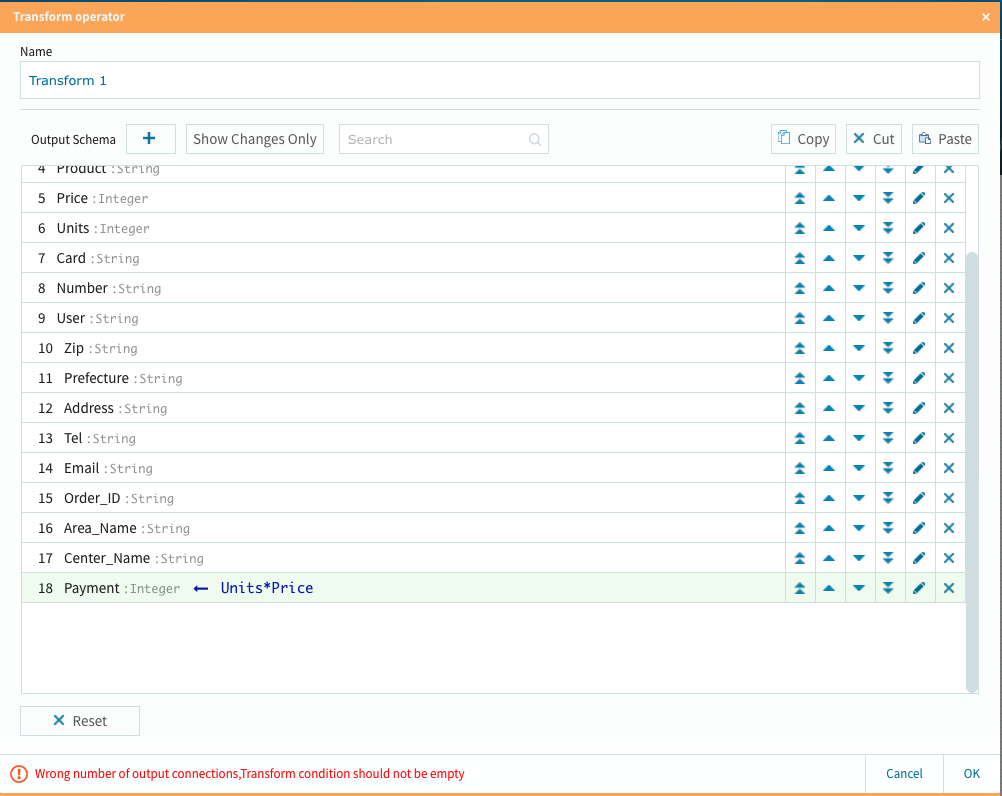
以下、同様の手続きを行えばOKです。
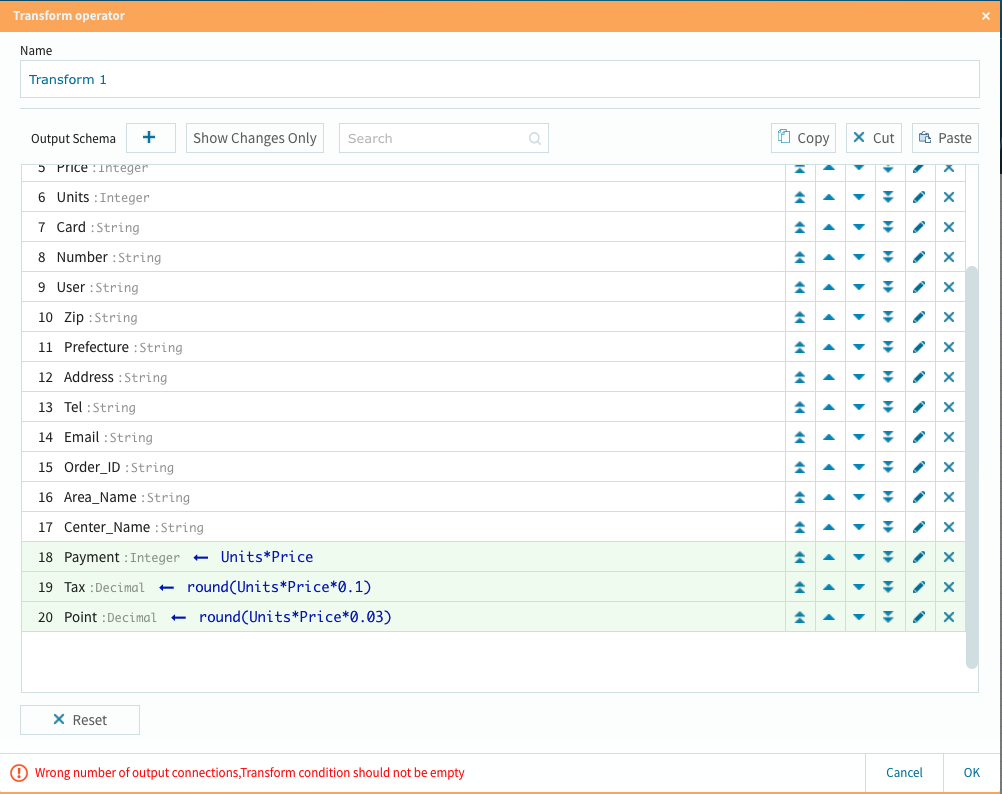
3個の派生カラム処理が終わりました。此処までの作業も相変わらずノーコードでOK!です.
最後に統合テーブルを接続します。
ポップアップ・メニューから右側のTargetを選択します。
今回の検証では、多段構成になりますのでCDC設定されている側のMySQL上にテーブルを作ります。
勿論、CDC設定は必要な分だけの独立したMySQLに対して可能ですので、複数の異なるエンジンを跨いだ構成も可能です。
今回は検証構成の関係上、上流側のCDC環境を共有していますが、EqualumはCDC情報で処理を行いますので、余計なクエリ等を投げない関係上、大きな負担をDB側に強いる事はありません。
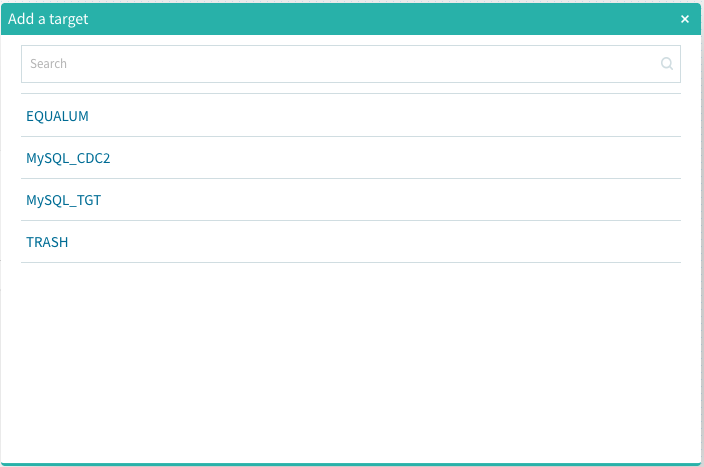
此処ではMySQL_CDC2で登録されているCDC設定済みのDBをターゲットにします。
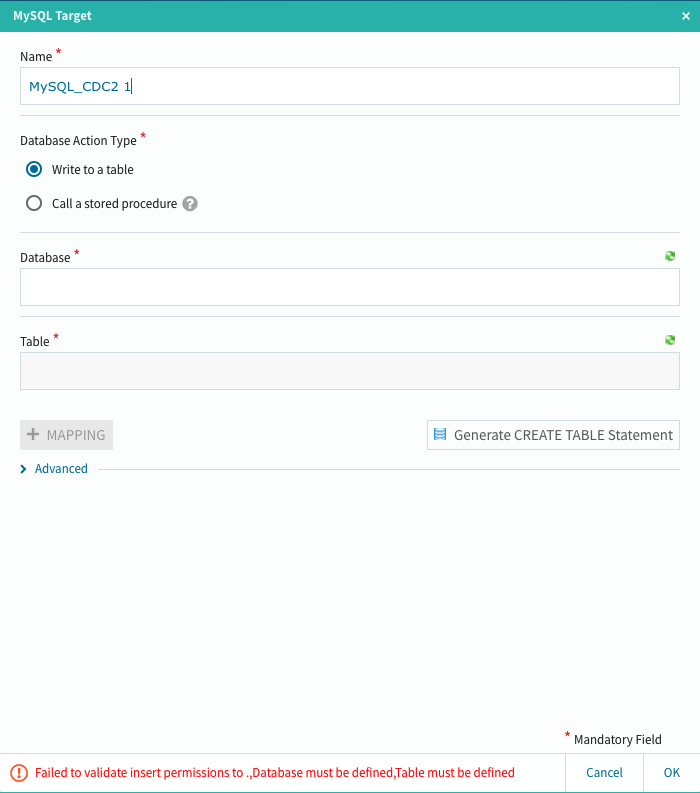
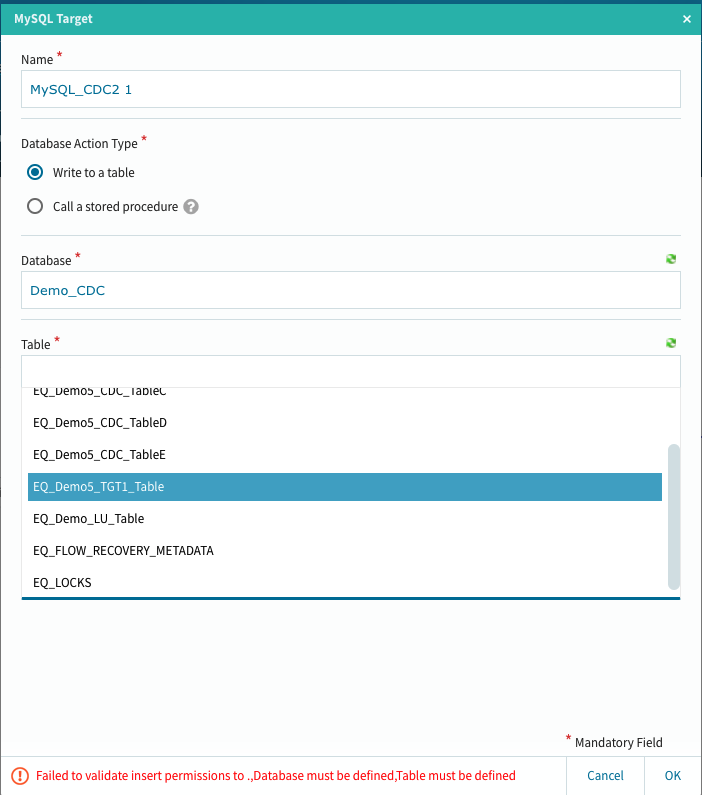
データベースを選択し、予め定義してあるテーブルを選択します。
+MAPPINGを選択して、テーブル間の整合性を設定・確認します。
今回はルックアップ処理で配送センターと地域名を参照挿入していますので、忘れずにそれらを反映しておきます。
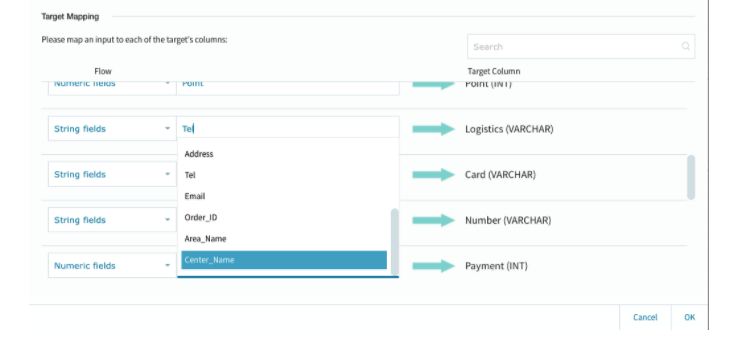
データパイプラインが1本完成!!
以降は、同じ作業を5つの商材別に5店舗分行えばOKです。ポイントはターゲット側のDBを共通化するだけで、基本的に統合DBがノーコードで作成出来るという点になります。

出来上がったFLOWに識別しやすい名前を付けて登録・配備・起動させます。この辺の手順等は以前の回と同じですので、慌てず確実に処理を進めて行ってください。
最初にEqualumを検証した際には、1本のFLOWで全ての商材別に異なるポイント計算を含めたFLOWを作りましたので、出来上がった手順定義がかなり長くなってしまいましたが、今回は逆に目的を絞る事でそれぞれの定義を簡略化する事が出来ました。
この辺の戦略は慣れが必要かと思いますが、間違い無く言える事は・・・・・
どちらを選んでも、Equalumのノーコード処理が劇的にサポートしてくれる!
と言うことでしょう。
複雑奇々怪々なプログラミング・構築作業を、単純な「まるでオフィス系アプリを操作する」かの様なイメージに変えた・・・と言っても過言ではありませんね。
因みに、今回はデータ・パイプラインの構成上「シンプルなFLOW設定になりましたが、勿論必要に応じて
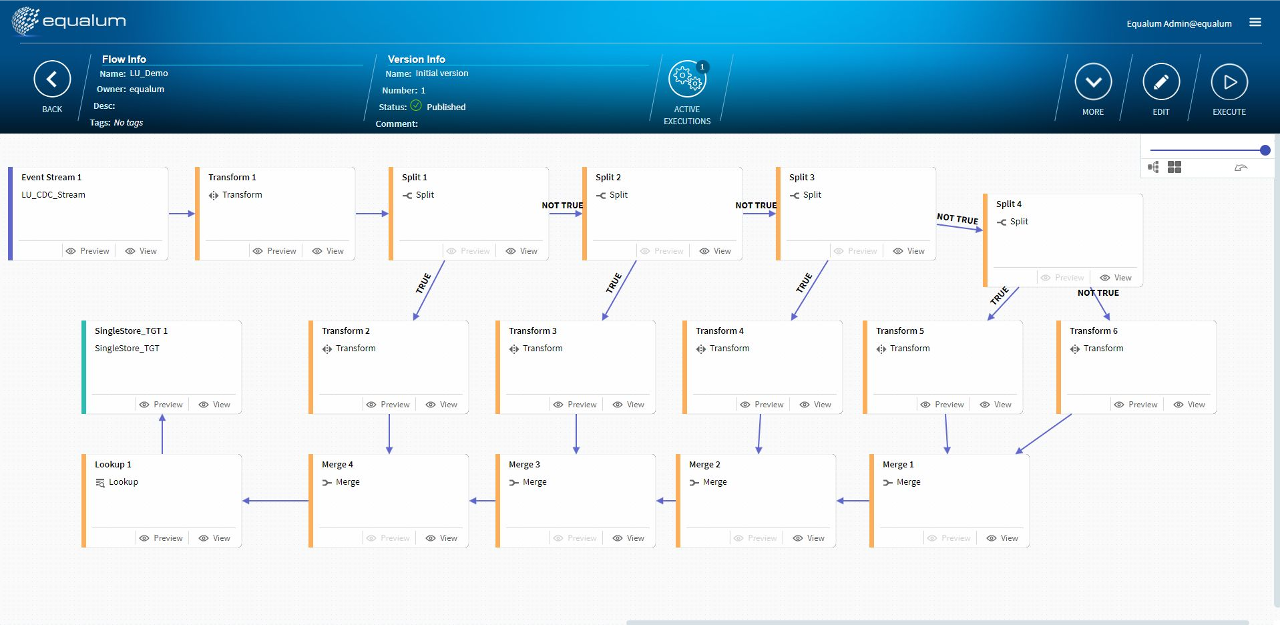
的な「大作系FLOW」も、ノーコードの組み合わせで誰でも簡単に実現する事ができます。
余談ですが、最近xxOpsというコンセプトが多く見られるようになりましたが、Equalumを使うと「それまでは禁断の余人入るべからず!」的な領域だった部分を、ノーコードでサポート出来るので、DataOpsも簡単に実現出来ると同時に、「余計な苦労はしない」で「事の本質に注力」し、環境変化や速度変化に対応出来るプラットホームを選択する事により、大きな潮目の変化が訪れてきたのかもしれない・・・とリアルに感じています。
今回のまとめ
今回は、前回に引き続き実際のデータ・パイプラインのFLOW部分について、GUIベースの環境でのノーコード作成を検証・紹介しました。
実際に掛かった時間は・・・・現実的には目標の1時間を遙かに超えない20−30分程度の作業で行う事が可能でした。勿論システムや仕組みに対する慣れの問題はありますが、今まで仮に同様の仕組みを開発・構築・導入したプロセスが有れば・・・・・この辺はかなり主観が入る部分ではありますので、これ以上のコメントは差し控えさせて頂きますが、データそのものの中身や重要性、関係性を理解している、データ現場の方々でも、最適なデータ環境の構築を自分達の手で作れる・・という大いなる可能性を、Equalumは徹底したノーコード戦略で強力にバックアップする事が出来るという事が確認出来ました。
圧倒的な即時性とExactlyOnceを含めた確実性、そしてそれらをワープロで文章を作る様に作り出せるノーコードの仕組みは、進化したデータドリブンでのDxを全面的にサポート出来るソリューションだと言えるでしょう。
次回は、最終回として後半部分のパイプラインの作成を行い、その後でPythonベースの検証ツールを使った動作検証を実施してみたいと思います。
Equalumで多段のデータパイプラインを1時間以内でノーコード作成する!(その1)はこちら
Equalumで多段のデータパイプラインを1時間以内でノーコード作成する!(その3)はこちら
謝辞
本検証は、Equalum社の公式バージョン(V2.27)を利用して実施しています。
この貴重な機会を提供して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。