今回は、Equalumのノーコード機能を使って、多段のリアルタイム・データ・パイプラインを1時間以内での作成に挑戦します!
取り急ぎでEqualumのおさらい・・・
以前の投稿にて、Equalumなるソリューションの検証報告をさせて頂いたかと思いますが、今回はその総集編的な感じで「多段の構成を実際に構築すると、どんな感じになるのか?」を出来るだけリアルな手順の実態を紹介しながら、Equalumが提唱している「ノーコードで高度なデータ・パイプラインを誰でも作れるようにする」という事が可能か否かを検証してみたいと思います。
Equalumの特徴としては・・・・
(1) Kafka&SPARKを活用した極めて高効率で高速なCDCベースのExactlyOnceをサポートしたデータ処理を提供
(2)徹底したノーコードオペレーションで、Excel経験者であれば、誰でも高度なリアルタイムストリーミング処理を実装可能
(3)既存の多くのDBが標準機能として提供している「ログ周辺情報」を活用し、余計なサービスやアプリを後入れで稼働中のDBに入れなくても良い
・・・
等があり、既に日本国内でも2社の公式取り扱い代理店が立ち上がり、積極的に市場開発をスタートさせています。
複雑な環境知識やJavaプログラミング等を一切使わずに、カラムの意味やテーブルの関係性等を理解していれば(ITの知識よりも、リアルなデータ現場の業務知識の方が重要です)誰でも高度なデータ利活用環境を構築でき、本当の意味でデータ・ドリブンなDxを実現出来るのがEqualumの強みだと言えるでしょう。
今回挑戦する構成の概要
今回の時短作成で挑戦する構成は、以下の通りです。
(1)以前の回で作成した、PythonベースのFakerで生成した「なんちゃって物販データ」を商材系統別(5種類)に仮想店舗を想定し、その店舗DBにランダムに生成データを挿入する。
(2)MySQL上に展開するCDC設定された店舗テーブルの変化をEqualumが読み取って、必要なストリーミング処理(今回は、ルックアップ、3個の派生カラム挿入を実施)を行い、全ての店舗データを統合データベースへ集約する。(図では、SingleStoreになっていますが、検証環境の都合で、MySQLインスタンスをもう1個立てて対応しています)
(3)集約された統合データを用途別(今回は、販売、決済、顧客に自動分類)のデータベースと、統合データをそのまま複製処理でターゲットに別のデータテーブルを作成する。

このパッ!と見た感じは、結構ハードルの高いデータ・パイプラインでありながら(概要は以前の回で紹介済み)、この「何処かに」「結構似たような」構成が多く有りそうな仕組みを、Equalumのノーコード機能をフルに使い、同時にExactlyOnceのデータハンドリングをサポートする形で、どれくらいの時間で稼働させられるか?!に挑戦したいと思います。
前段が、サイロの壁を「無理に取っ払わなくても」データ統合をオンタイムで自動更新出来る(夜間バッチ処理等の時差は不要)処理で、後半が目的別データテーブルを同時に作成してしまえ!(利活用向けや、本社・本部機能向けの対応自動化)という感じになります。
その前に・・・・
最初のPythonベースの連続データ生成型・検証ツールに関しては、今回のEqualumの検証とは直接的な関係が有りませんので、機会があれば別のトピックで中身を公開・・という形にさせてください。
今回は、誰でも簡単に「高速・低遅延・ストリーミングETL + ExactlyOnce」なデータ・パイプラインをノーコードで何処まで行けるか?がテーマですので・・・・
さてEqualumとご対面!

先ずは、お約束のログインを行います、
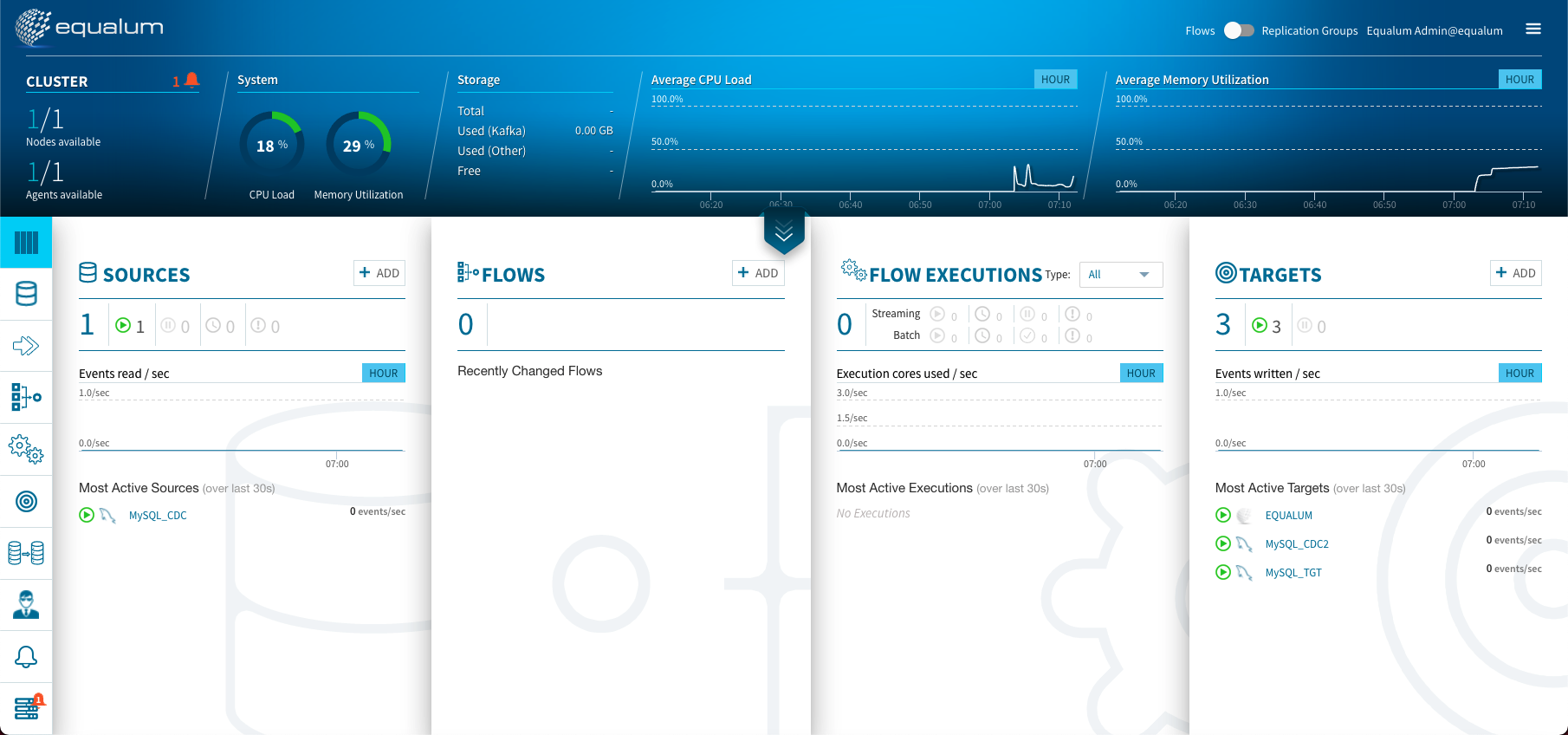
今回の環境は、ポータブルなデモ用途に特化した「シングルノード構成」で実施します。(左上の1/1が1台構成を表しています)
最初にKafkaの作業・・・・を行う?!(苦行前提かーっ?!)
Equalumの特徴の一つに、徹底した「良い意味」でのブラックボックス化があります。特にデータ現場の方々(仕事上、Excel経験は有る)でも、現場主導のDxをデータドリブンで実現するための環境を、自分達で構築出来るようにする!という部分に大きく貢献出来る仕様だと言えるでしょう。
先ずは、上流側(今回の構成では、店舗別データが飛び込んで来る想定)のMySQLにEqualumが内部で活用しているKafka関係の設定を行います。
Kafkaを普通に取り扱おうとすると、かなりハイレベルの知識やプログラミング技術が要求されるかと思いますが、Equalumの場合はその部分を圧倒的に簡略化し、基本的には専用画面で必要な項目を設定・選択するだけで、この高い壁をノーコードで突破出来るように工夫しています。
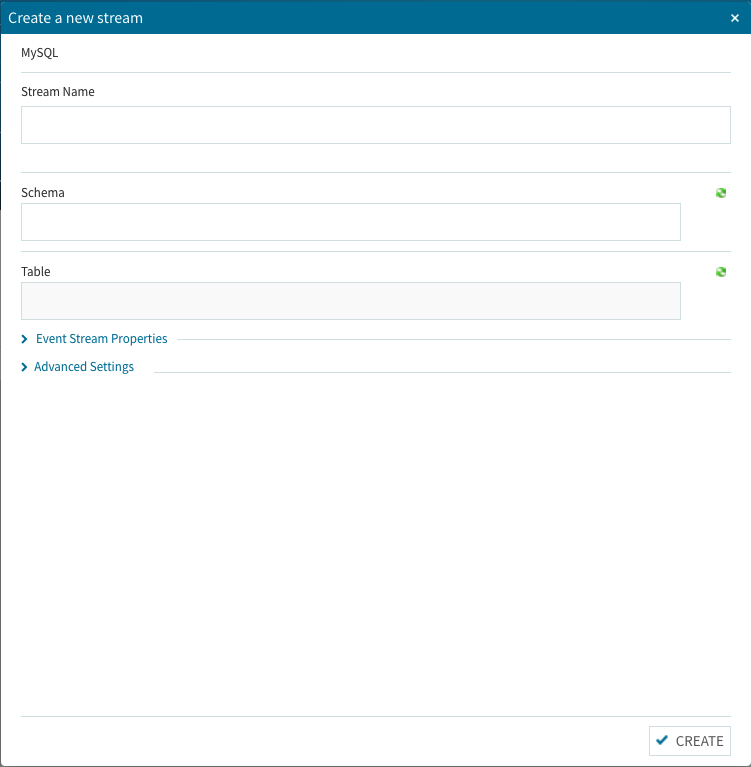
基本的に設定・選択する項目はこれだけOK!です。勿論、慣れてきたユーザは通常使わないより深い項目設定を行う事も出来ます。
こんな感じで作業を進めれるだけで、高度な(ExactlyOnceサポートの)Kafka連携を実現出来ます。

必要な項目を設定・選択できたら、右下のCREATEボタンを選択して終了します。
無事にKafka連携が出来る準備が整うと、このような画面が出てきます。(Kafka周りはこれだけでOK!です)

後は、同様の作業を必要なテーブル個数分行えばOK!です。

僅かこれだけの作業で、データベース上に展開されている必要なテーブルに変化が起きると、Equalumのクラスター上で稼働している(DB側ではありません)エージェントが、得意のCDC処理を即時実施して処理を行うので、ユーザは「複雑・奇々怪々なプログラミング」を「一切行わずに」リアルタイム・ストリーミングのデータパイプラインを作成・構築・運用する事が可能になります。もう2度とKafkaプログラミングに悩む必要はありません!
此処までの仕組みを「今までのアプローチで行った場合・・・」は、間違い無く冒頭の1時間という数字は不可能かと。。。
少し高度な設定例を・・・・
今回のFLOWでは、予め定義しておいたテーブルを参照する「ルックアップ処理」を組み込みますので、此処ではその基本的な手順を紹介したいと思います。基本的には前述の作業と殆ど同じになりますが・・・
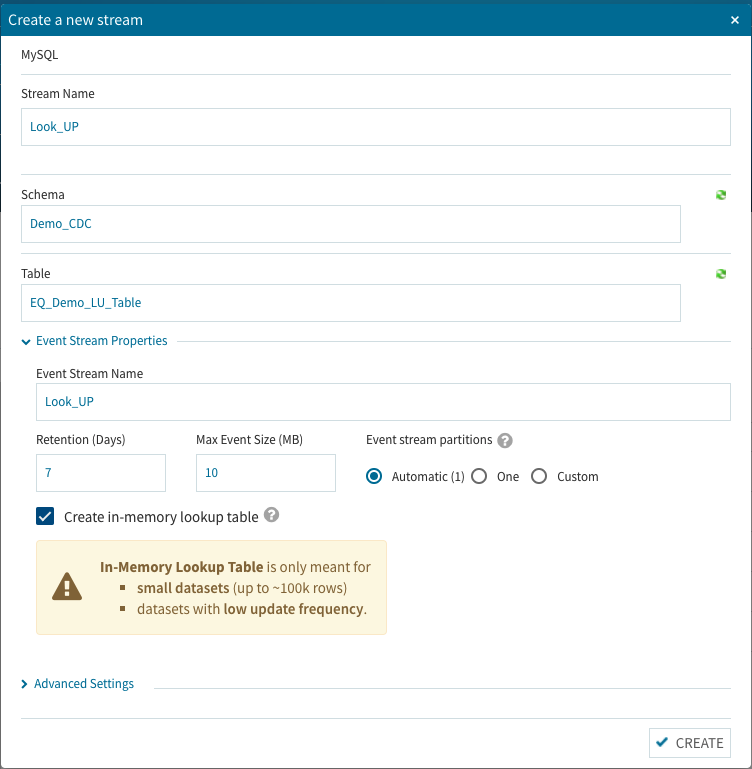
先ほどの設定画面で隠れていたEvent Stream Propertiesを選択して、必要な設定・選択作業を行います。
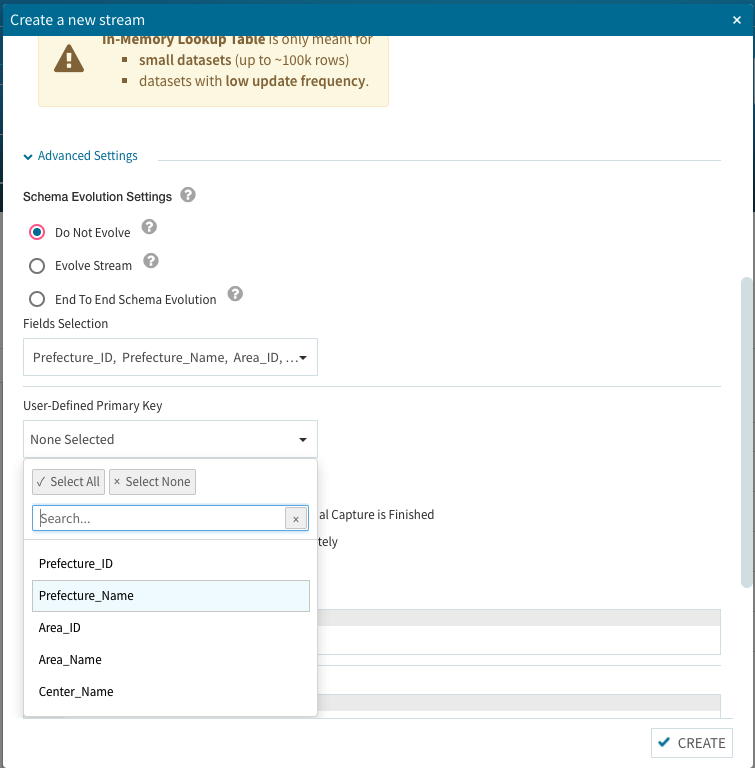
此処まで来れば後は前述の処理と同じですので、右下のCREATEボタンを選択して完了です。
此処までのノーコード作業が無事に終了すると、処理を支える基盤として高度な(Exactly Onceサポート)Kafkaスキームを従えた、リアルタイムのデータ・パイプラインの基礎部分が出来上がった事になります。
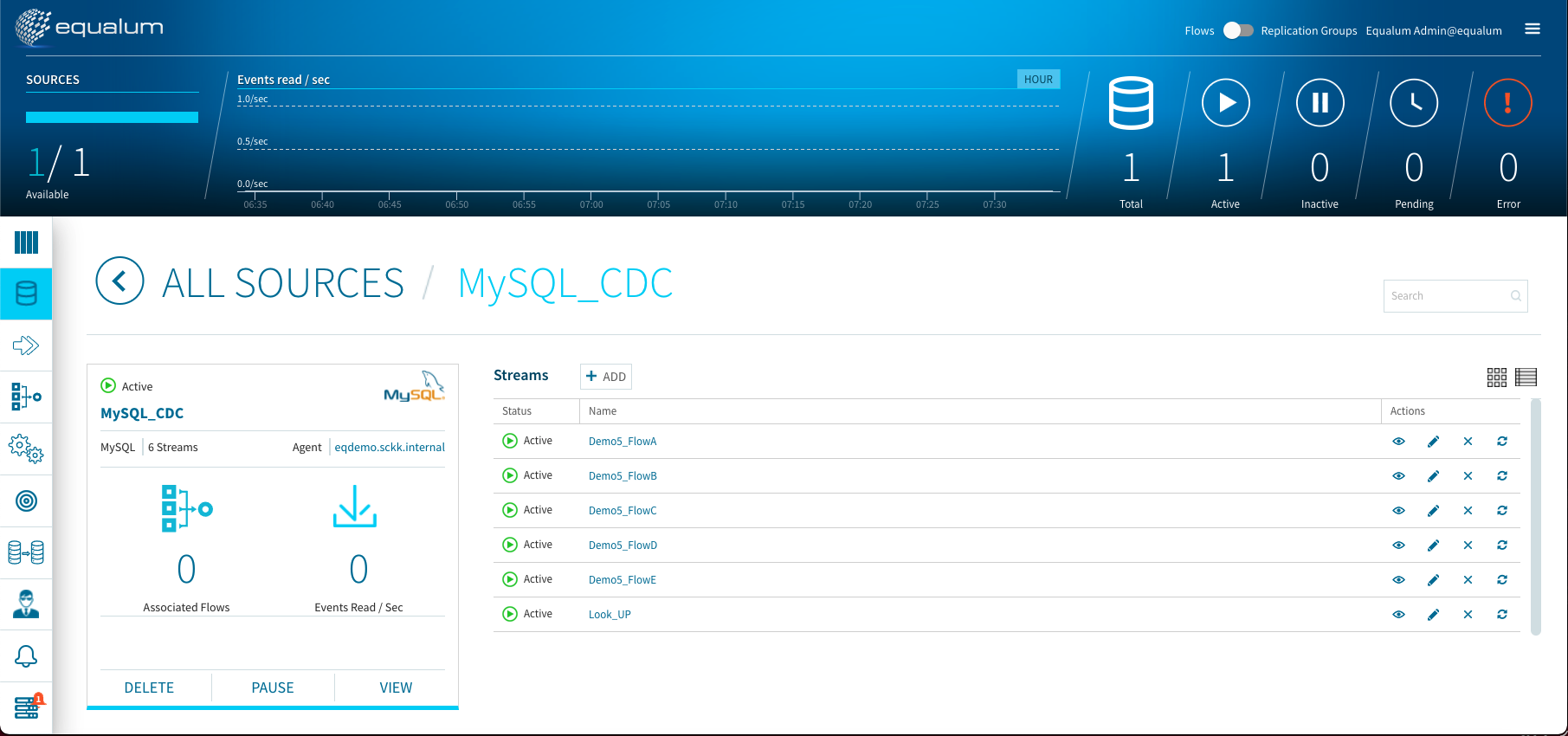
今回のまとめ
今回は、以前の回で概要だけ紹介しただけだった「多段CDCを活用した、結構リアルに悩まれるパターンのデータ処理」を、Equalumのノーコード機能を活用して「サクッと!」作成する為のリアルタイム・ストリーミングの重要部分を具体的に検証・紹介させて頂きました。
誰でも、簡単な選択・設定処理だけで「ExactlyOnceを含む」高度なデータ・パイプラインを、「複雑なJapanプログラミング等を行わず」「複雑奇々怪々な関連環境の選定・導入等を行わす」に「サクッと!」実現可能なEqualumは、この領域にリアルなアジャイルを実現し、市場・ビジネスの変化やそれらの速度に対応可能なDxの為の、データドリブン環境における利活用環境を簡単に構築出来る、極めて有効な選択肢であるとご理解頂けたかと思います。
取り留めも無くサラッと流してしまいましたが、此処までのノーコードワークで「高性能データ・パイプライン作成」に関する「最重要部分」を基本的な定型手順で実現する事が出来ました。
次回は、表側のFLOW部分の作成について検証・解説したいと思います。
Equalumで多段のデータパイプラインを1時間以内でノーコード作成する!(その2)はこちら
Equalumで多段のデータパイプラインを1時間以内でノーコード作成する!(その3)はこちら
謝辞
本検証は、Equalum社の公式バージョン(V2.27)を利用して実施しています。
この貴重な機会を提供して頂いたEqualum社に対して感謝の意を表すると共に、本内容とEqualum社の公式ホームページで公開されている内容等が異なる場合は、Equalum社の情報が優先する事をご了解ください。