さて、今回のチャレンジ(?)は・・・・
今回は、連続してデータが挿入されているMemSQLのテーブルに対して、連続して一定間隔の処理を実行して指定された時間範囲に入るデータを抽出・テーブル生成を行ってみたいと思います。時間が押し押しの状況での検証ですので、今少し詰めが甘い感が否めませんが、一方で秒に数個の挿入処理を実行中のMemSQLが、別の処理要求を連続して受けた場合にどのような動きになるかを確認する意味で、とりあえずザクッと実施してみます。
バッチ的な定形処理の間隔を短縮化する
よくある作業としては、纏めてドン!型の世界におけるバッチ処理が有りますが、今回は以前より検証・紹介させて頂いているリアルタイム・ストリーミングをプログラムレスで構築できる、Equalumというソリューションが有りますので、それとの連携を想定した**「既存のオリジナル側データシステムに対してトランザクション泥棒と呼ばれずに」「時間を気にしないで」「想いのままに」「創造的なクエリ処理」**を実現する為の環境として、MemSQLがどの程度行けるか?を見てみたいと思います。
先ずは、以前のPythonスクリプトを改造して、定期的に実行されるプロセス内で
(1)起動したタイミングの日時情報でテーブル名を生成して新規テーブルを作成
(2)連続挿入されているオリジナル側のテーブルから必要情報を時間範囲指定で抽出
(3)返ってきた情報を(1)で作成した新規テーブルに格納
という処理を入れ込みます。(今回も力業でエイヤー版になる関係上、ツッコミ所満載かもしれませんが、その辺は平にご容赦の程・・・・)
因みに今回使用するSQLは以下の通りです。
SELECT ts, Category, Product, Price, Units, Card, Payment, Prefecture
FROM Qiita_Test
WHERE ts BETWEEN 'YYYY/mm/dd HH:MM:SS.000000' AND 'YYYY/mm/dd HH:MM:SS.000000'
SORDER BY ts;
検証は今回設定した一連の処理を30秒毎に処理を走らせて、その時点から30秒前までのデータを条件抽出する想定で実施しました。(実際には、その他の影響を受けて微妙にズレたりしていますが・・・(汗))連続挿入しているテーブルに、定期的に割り込みを掛けて条件抽出&新規テーブル作成の負荷を掛けたらどうなるか・・・を検証出来れば、とりあえずOkという事で作業を進めて行きます。
# coding: utf-8
#
# Pythonでタスクを一定間隔に実行する (力技バージョン)
# Version 2.7版
#
import sys
stdout = sys.stdout
reload(sys)
sys.setdefaultencoding('utf-8')
sys.stdout = stdout
# インポートするモジュール
import schedule
import time
import pymysql.cursors
# SQL文で使う情報
SQL1 = "SELECT ts, Category, Product, Price, Units, Card, Payment, Prefecture FROM Qiita_Test "
SQL3 = " ORDER BY ts"
# スナップショット・テーブルのカラム定義
DC0 = "id BIGINT AUTO_INCREMENT, PRIMARY KEY(id), O_ts DATETIME(6), "
DC1 = "Category VARCHAR(20), Product VARCHAR(20), Price INT, Units INT, "
DC2 = "Card VARCHAR(40), Payment INT, Prefecture VARCHAR(10)"
# SQLで書き込むカラム定義
DL1 = "O_ts, Category, Product, "
DL2 = "Price, Units, Card, Payment, "
DL3 = "Prefecture"
#
# 此処に一定間隔で走らせる処理を設定する
#
def job():
# スナップショットのタイミングから遡る時間設定
Time_Int = 30
Time_Adj = 0
from datetime import datetime, date, time, timedelta
# 現在日時情報の取得
now = datetime.now()
print ("JOBの開始 : " + now.strftime("%Y/%m/%d %H:%M:%S"))
# スナップショット用のテーブル名を生成してSQL文を生成
dt = 'Qiita_' + now.strftime('%Y%m%d_%H%M%S')
Table_Make = "CREATE TABLE IF NOT EXISTS " + dt
SQL_Head = "INSERT INTO " + dt
# SQLで使用する時間設定の終了情報(補正が必要な場合はTime_Adjで調整)
pre_sec = now - timedelta(seconds = Time_Int + Time_Adj)
from_dt = pre_sec.strftime("%Y/%m/%d %H:%M:%S")
# SQLで使用する時間設定の開始情報 (補正が必要な場合はTime_Adjと+-で調整)
now_sec = now + timedelta(seconds = Time_Adj)
to_dt = now_sec.strftime("%Y/%m/%d %H:%M:%S")
# 時間範囲指定のSQL文を生成
SQL2 = "WHERE ts BETWEEN '" + from_dt + ".000000' AND '" + to_dt + ".000000'"
SQL_Def = SQL1 + SQL2 + SQL3
# MemSQLとの接続
db = pymysql.connect(host = 'xxx.xxx.xxx.xxx',
port=3306,
user='qiita',
password='adminqiita',
db='Test',
charset='utf8',
cursorclass=pymysql.cursors.DictCursor)
with db.cursor() as cursor:
cursor.arraysize = 1000
# スナップショット用の新規テーブルを作成
cursor.execute(Table_Make +"("+DC0+DC1+DC2+")" )
db.commit()
# 作業用のバッファを初期化
Tmp_Data = []
# クエリ用のSQLを送信してコミット
cursor.execute(SQL_Def)
db.commit()
# クエリの結果を取得
rows = cursor.fetchall()
# クエリ結果を取り出す
for Query_Data in rows:
for item in Query_Data.values():
Tmp_Data.append(item)
# 各カラムへ反映
Category = str(Tmp_Data[0])
Product = str(Tmp_Data[1])
Price = str(Tmp_Data[2])
O_ts = str(Tmp_Data[3])
Units = str(Tmp_Data[4])
Prefecture = str(Tmp_Data[5])
Payment = str(Tmp_Data[6])
Card = str(Tmp_Data[7])
# SQLを作ってスナップショットテーブルに格納
DV1 = O_ts + "','" + Category + "','" + Product + "','"
DV2 = Price + "','" + Units + "','" + Card + "','" + Payment + "','"
DV3 = Prefecture
SQL_Data = SQL_Head + "("+DL1+DL2+DL3+") VALUES('"+DV1+DV2+DV3+"')"
# スナップショット用のテーブルに挿入
cursor.execute(SQL_Data)
db.commit()
Tmp_Data = []
#データベース接続を切断
db.close()
print ("JOBの終了 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
print ("+++++++++++++++++++++++++++++++")
print
#
# 此処からメイン部分
#
def main():
# 使用する変数の設定
Loop_Count = 3
Count = 0
Interval_Time = 30
# 処理全体のスタート時間
from datetime import datetime
print ("プログラム開始日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
print
# 10分ごと
# schedule.every(10).minutes.do(job)
# 2時間ごと
# schedule.every(2).hours.do(job)
# 毎日10時
# schedule.every().day.at("10:00").do(job)
# 毎週月曜日
# schedule.every().monday.do(job)
schedule.every(Interval_Time).seconds.do(job)
# 無限ループで処理を実施
while True:
schedule.run_pending()
# 謎の呪文・・ww
time.sleep(Interval_Time)
# 規定回数をチェック
if (Count >= Loop_Count):
break
else:
Count += 1
print
print (str(Count) + "回 : 規定回数のJOBが終了しました!")
print
from datetime import datetime
print ("プログラム終了日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S"))
if __name__ == "__main__":
main()
このスクリプトを動かした結果は以下の通りです。
プログラム開始日時 : 2020/10/12 14:31:35
JOBの開始 : 2020/10/12 14:32:05
JOBの終了 : 2020/10/12 14:32:06
+++++++++++++++++++++++++++++++
JOBの開始 : 2020/10/12 14:32:36
JOBの終了 : 2020/10/12 14:32:37
+++++++++++++++++++++++++++++++
JOBの開始 : 2020/10/12 14:33:07
JOBの終了 : 2020/10/12 14:33:09
+++++++++++++++++++++++++++++++
3回 : 規定回数のJOBが終了しました!
プログラム終了日時 : 2020/10/12 14:33:39
想定通り動いていれば、MemSQL上に開始時間情報を持つテーブルが3個出来上がっているはずです。
先ずは毎度お馴染みのDBeaverで確認してみます。
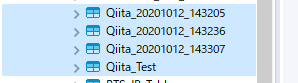
オリジナルテーブルのQiita_Testテーブルと併せて無事に出来上がっている様です。
念のために各テーブルの先頭部分と末端部分を確認してみます。


挿入スクリプトと今回のスクリプトを起動させた順番の関係上、最初のデータ時間が少し遅めになっていますが、とりあえず立ち上がりの抽出は上手く処理されている様です。
次に終端部分を比較してみます。


最後のデータのTIMESTAMP(6)のデータが14:32:04:804694ですので、想定通りに収まっている事が確認できます。
同様に他の2つも確認します。


処理のインターバルに挟まったデータをミスっていますが、定義された時間範囲はカバーされてます。(ロジックを練らねば・・(汗))


無事に範囲に収まっています。
最後のテーブルは・・・


先程と同様に処理過程で時間計算の葉境に嵌った2-3個のデータは収集出来ませんでしたが、SQL文上で定義した時間範囲には収まっている様です。


さて、取り出したテーブルをどうするか・・・・
もう少し気を利かして時間をコントロールできれば、より緻密に短いサイクルでのデータ利活用の精度は上がってくると思いますが、取り急ぎインメモリパワーに助けられて、大きな処理(例えば以前紹介させて頂いたEqualumを使って、今回の検証で行った連続挿入部分を置き換える等)をMemSQLに実行させていても、ミリ秒台の性能で自由にデータの抽出&次工程の作業を行う事が出来る事は極めて現実的であるとご理解頂けたかと思います。
また、大きなポイントは・・・
短時間の処理サイクルでは、基本的に取り扱うデータも少ないので、極めて今に近い状況を自由に想定しながらシュミレーション的にデータの抽出・集計処理等を行う事が可能です。深夜バッチで纏めてドン!ではないので、何時でもその時点までの取り扱い可能な全てのデータを、Equalumを使って上流側のサイロの壁を越えたデータソースから抽出・前処理済みで、MemSQLのメモリ空間上に展開し(この時点で、サイロ内の情報は同一のDBが管理するメモリ空間にフラットに展開されています)、サイロ透過の横串的なデータ利活用も簡単に行えるようになります。
もちろん、MemSQL上に今回のオリジナル側に展開した情報を10万行入れたターブルに対して、幾つかの条件を設定した抽出系クエリ(今回の時間指定も含めて)を仕掛けた際にも、安定してミリ秒台の性能が維持出来ていますので、メモリ展開の空間が大きな状況が想定されるのであれば、必要なIAサーバをクラスタリングして、存分なインメモリ・データ・コンピューティングを実施する事が可能です。
今回バッチ処理的に抽出したテーブルは、以前にご紹介させて頂いたExcelのテーブルとして読み込む事が出来るので、Excel上の機能を活用したBI的活用も可能ですし、MemSQLの高いMySQL互換性を活用した、その他のBI/AI等のソリューションへの元ネタとして即利用する事も可能でしょう。
MemSQLを使ってみようVol.6 : 脱線編が参考になるかと。
次回は・・・
次回は、今回抽出されたテーブルを使って、幾つかの外部連携を試してみたいと思います。この作業はMemSQLとは直接関係しませんが、MemSQL社がメッセージとして出している「オペレーショナル・データベース」(リレーショナルではない点が面白いかと・・)の部分を少し深掘りして、最近のモダン・トランザクション系データ・コンピューティングとのコラボを検証し、
既存のデータ・システム >> Equalum >>MemSQL >> BI/AI/ロボットetc..
リレーショナル <<<<<<<<<<<>>>>>>>> オペレーショナル
の世界を覗いてみたいと思います。
謝辞
本検証は、MemSQL社の公式Freeバージョン(V6)を利用して実施しています。
この貴重な機会を提供して頂いたMemSQL社に対して感謝の意を表すると共に、本内容とMemSQL社の公式ホームページで公開されている内容等が異なる場合は、MemSQL社の情報が優先する事をご了解ください。