前回は、複数のデータソースを一つに纏めて取り扱う事が出来る、フュージョン機能についてご紹介しました。マイクロクエリーを最大限に活用し、ネットワーク上に散在する貴重なデータソースを、一つのデータソースとして透過的に取り扱う事により、データの持つ価値や可能性をより一層向上させると同時に、データソースに関わる仕組み自体の発想を、より効率的で柔軟な方向に進化させることが出来るという事をご理解頂けたかと思います。
さて、今回からはZoomdataの本領発揮である、ビッグデータとの連携についてご紹介していこうと思います。
既に、Kitaseさんが書かれたZoomdataとHadoop(Hive on Tez)の連携(Azure編)といった記事も公開されていますので、実際に連携検証を行われた方もいらっしゃるかもしれませんが、今回は一般に公開されている著名なビッグデータ・ソリューションを、それぞれのSandboxを仮想空間で使わせて頂くことで、Zoomdataとローカルに連携させながら、その基本的な設定手順等を説明して行きたいと思います。
(1)まずは環境の準備
ビッグデータの環境としては、今回の一連の作業を仮想環境上で行っている関係もあり、Sandboxと呼ばれる構築済みの仮想イメージを活用する方向で作業を進めさせて頂きたいと思います。
検索エンジンで探して頂けば、すぐに幾つかの試用環境に関する情報が手に入るかと思いますが、第1回目の今回は、**Cloudera**社様より提供されているSandboxを使わせて頂き、Zoomdataとの接続検証を行ってみる事にします。
Cloudera社のホームページよりDownloadを選択し、QuickStartsにある**DOWNLOAD NOWを選択して頂くと、現在配布されている仮想イメージのダウンロード登録が出来るかと思いますので(執筆時点)、所定の情報を正確に登録頂いて目的の仮想イメージを入手してみてください。また、今回からはZoomdata**以外に接続検証を行うビッグデータ環境用のメモリ空間や、要求されるCPUリソース等が必要になりますので、場合によっては稼働用のハードウエアを分けて立ち上げるなどの工夫(ネットワーク等の整合性を合わせるなど)が必要になるかもしれませんが、それぞれの環境構築は、自己責任でお願い致します。また本件に関するCloudera社様へのお問合せ等はお控え頂ければ幸いです。
無事にダウンロードが終了し、起動が成功すればデスクトップ画面が表示されると思います。(注:画面が日本語化されていますが(あくまでも個人的な興味で設定しています・・)、オリジナルの環境は英語版になります。もちろん、英語環境でも問題なく検証できますので、そのまま進めてください)
まず最初に、検証用データの設定をします。ブラウザ上の上の方にHueという表示が有りますので、それを選択してみてください。表示が変わり、Step 1の作業が開始されると思いますが、暫くすると画面に環境のチェック内容が表示されます。
次にStep 2のExamplesを選択します。
今回の検証で使うデータを選択します。今回はImpalaと検索系のSolr Searchの接続検証を行うと思いますので、順番に選択してインストールしておきます。
念のためにデータの生成を確認しておきます。
ブラウザ画面の上部にある家(My Documents)のアイコンを選択します。
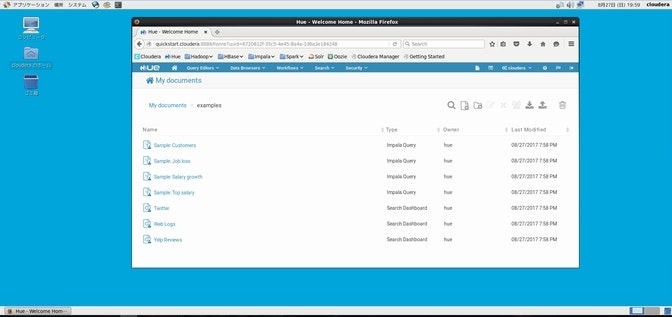
検証用のデータが無事にセットアップされた事が確認できると思いますので、併せて仮想マシンのIPアドレスを調べておいてください。
(2)Zoomdataとの接続
さて、ビッグデータソース側の準備が出来ましたので、これからZoomdataとの接続設定を始めたいと思います。
まずはadminで入って頂き、コンソール画面上部の歯車アイコンを選択し、Sourcesを選択してください。
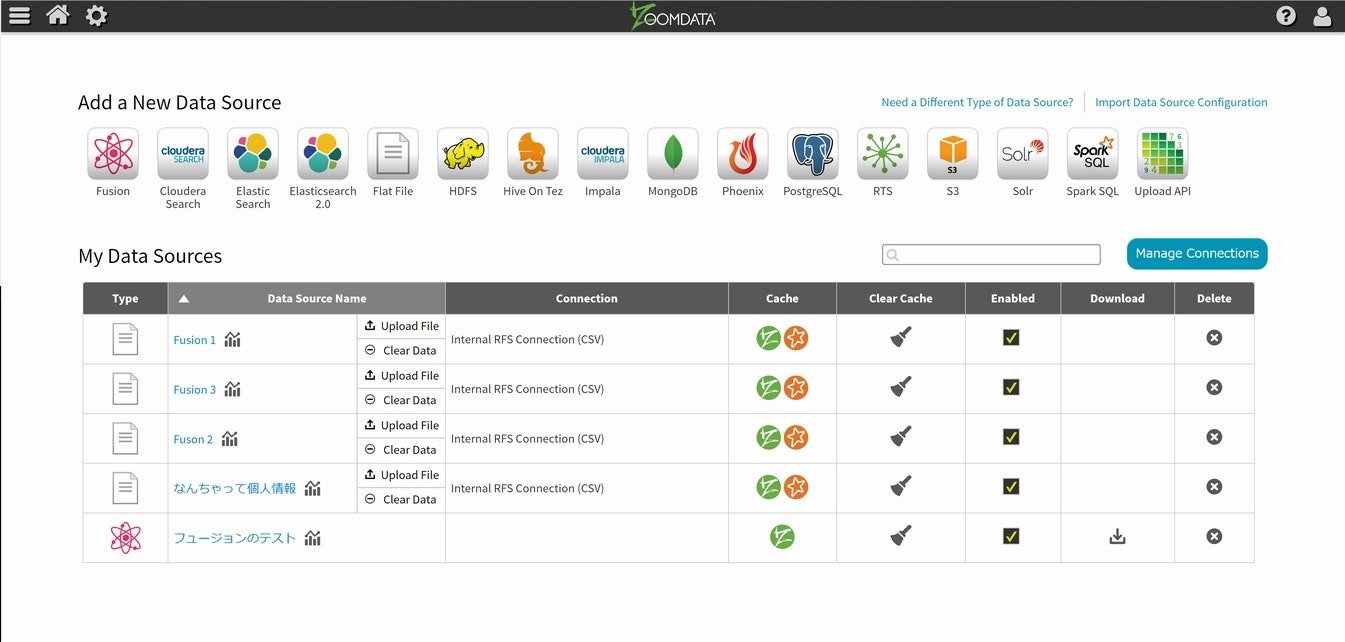
次にCloudera Impalaのアイコンを選択します。
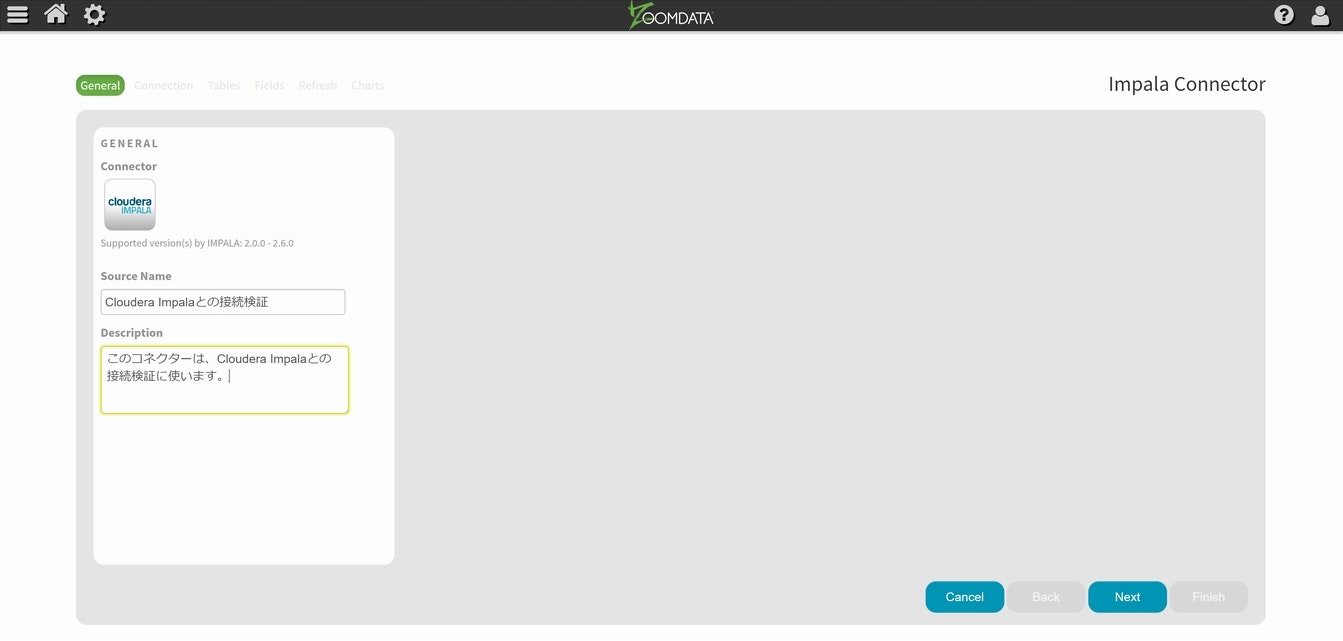
必要事項を設定し左側下部にあるNextを選択します。
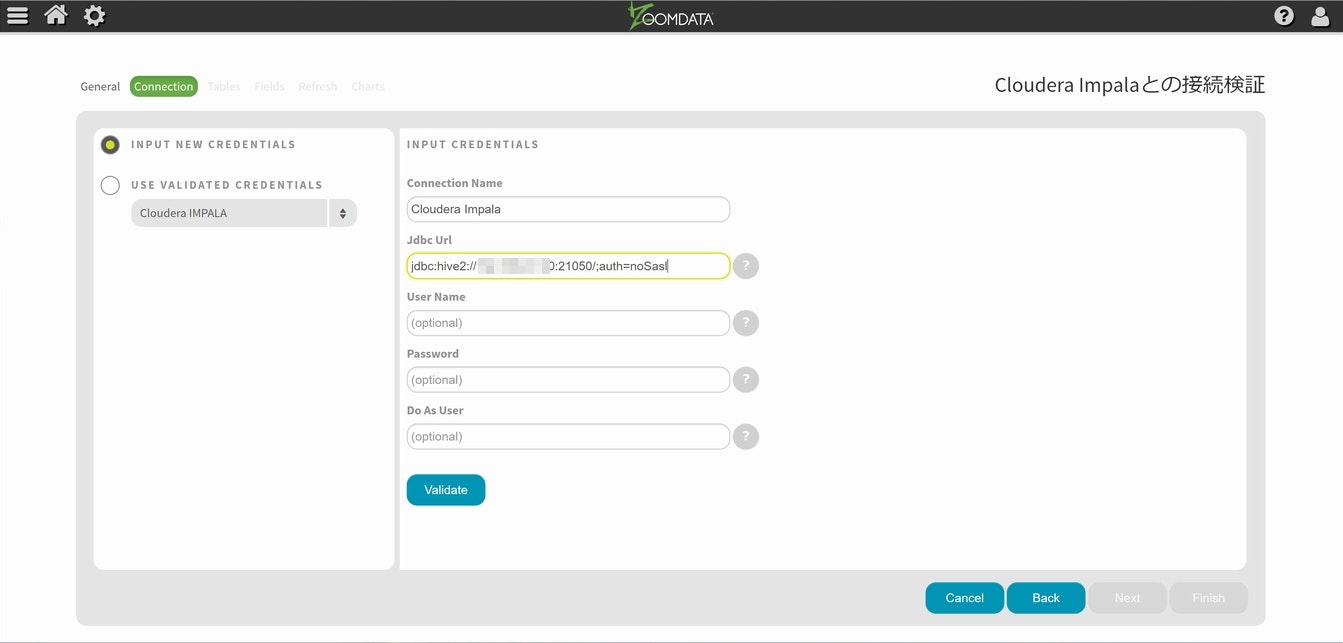
新規のコネクター設定を選択し、必要なパラメータを設定します。コネクター毎にユニークな名前を設定し、JdbcUrlの情報を以下の様に入力してみてください。
jdbc:hive2://xxx.xxx.xxx.xxx:21050/;auth=noSasl
xxx.xxx.xxx.xxxについては、先程確認したIPアドレスを設定し、ポート番号は各データソースによって事前に定義されていますので、基本的にそれらの数値をそのまま使ってください。また、その他の項目については、そのままで結構です。(この辺の情報については、提供元のドキュメントをご確認ください)
基本設定が終わったらValidateを選択すると接続検証が行われますので暫くお待ちください。
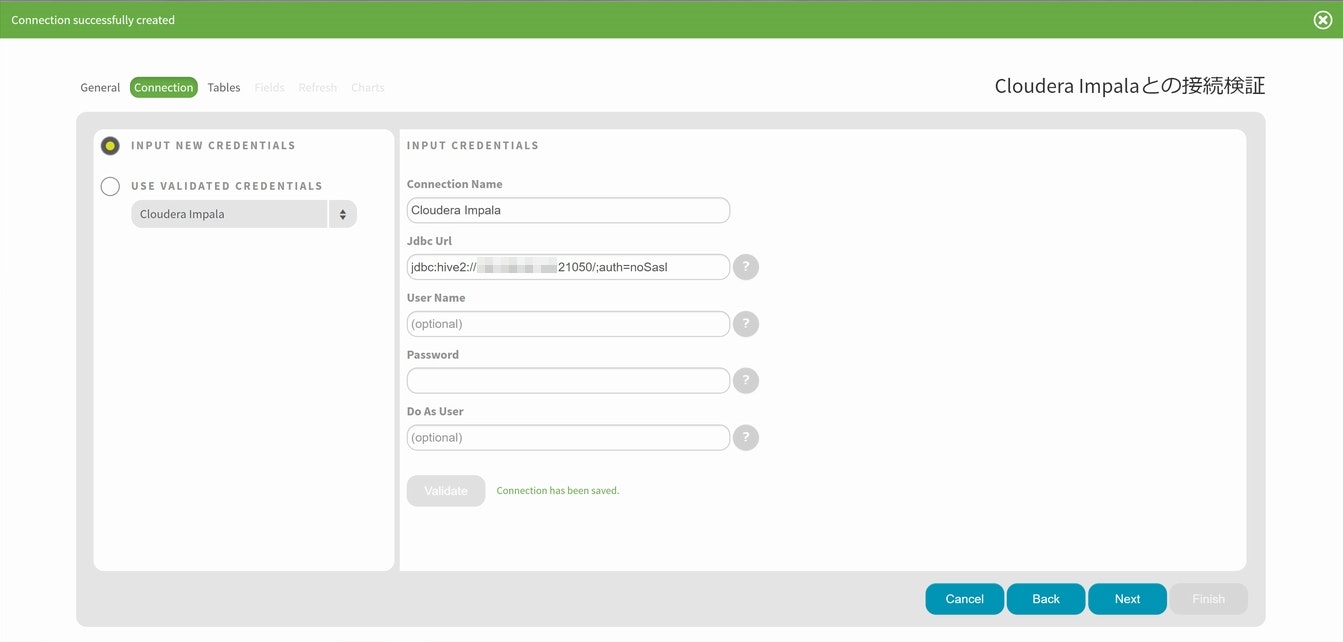
画面上部に緑色の接続完了を占めるポップアップが表示されれば、無事にデータソースとの接続設定は完了です。
次に取り扱うデータの選択に入ります。画面右下にあるNextを選択してください。
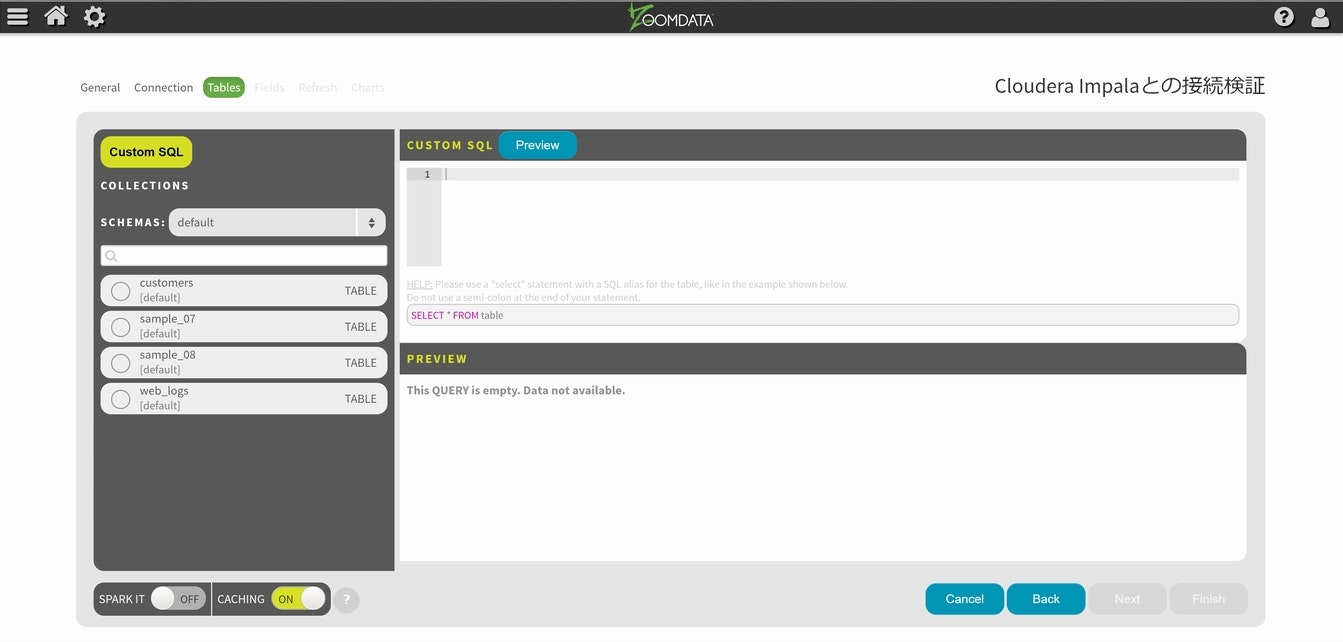
事前に設定されているサンプルが幾つか出てきますので、今回は一番沢山のデータの項目が有りそうな、web_logsを選択してみます。
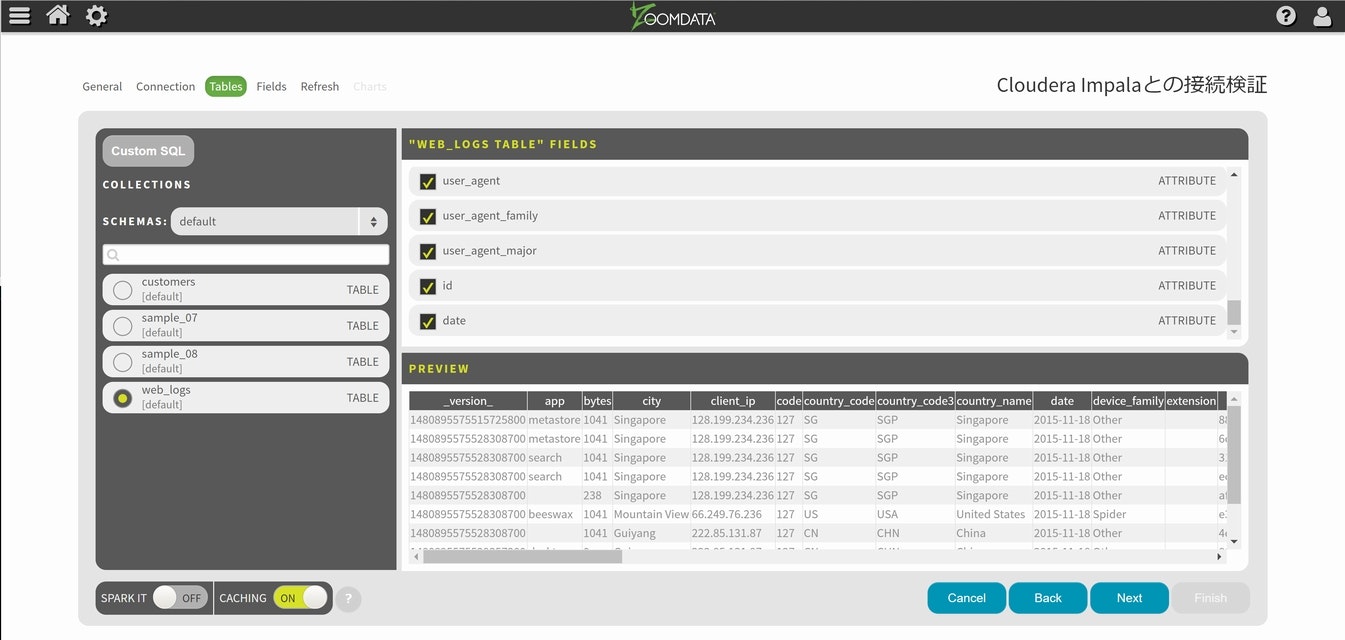
各データの詳細が表示されますので、右下のNextを選択します。
今回は、サクッと試すという事ですので、基本的には以降の画面についてもそのまま進行してください。ただし、データをTime Barと連携させるために、以前説明させて頂いたデータ項目の属性を一部変更しておいてください。(具体的には、dayの属性をTIMEに変更し、カスタム設定をyyyy-MM-ddに置き換えた後、次項目をDAYにしておけばOKです)
dayの属性変更が首尾よく終了し、全体のパラメータ設定が完了するとZoomdata側から、得意のマイクロクエリーでImpalaへアクセスできるようになります。
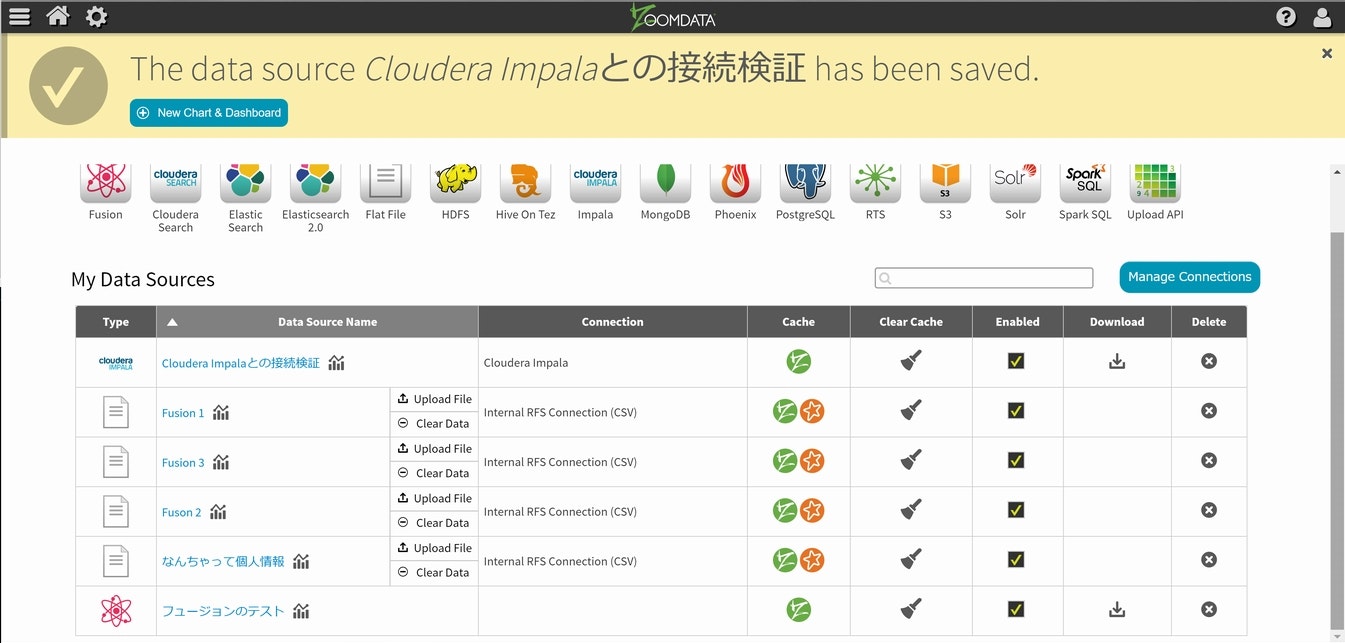
(3)ダッシュボードの作成して接続を検証
では、接続を検証するために簡単なダッシュボードを作成してみましょう。手順は前回までと同じになりますので、サクッと進行していきます。
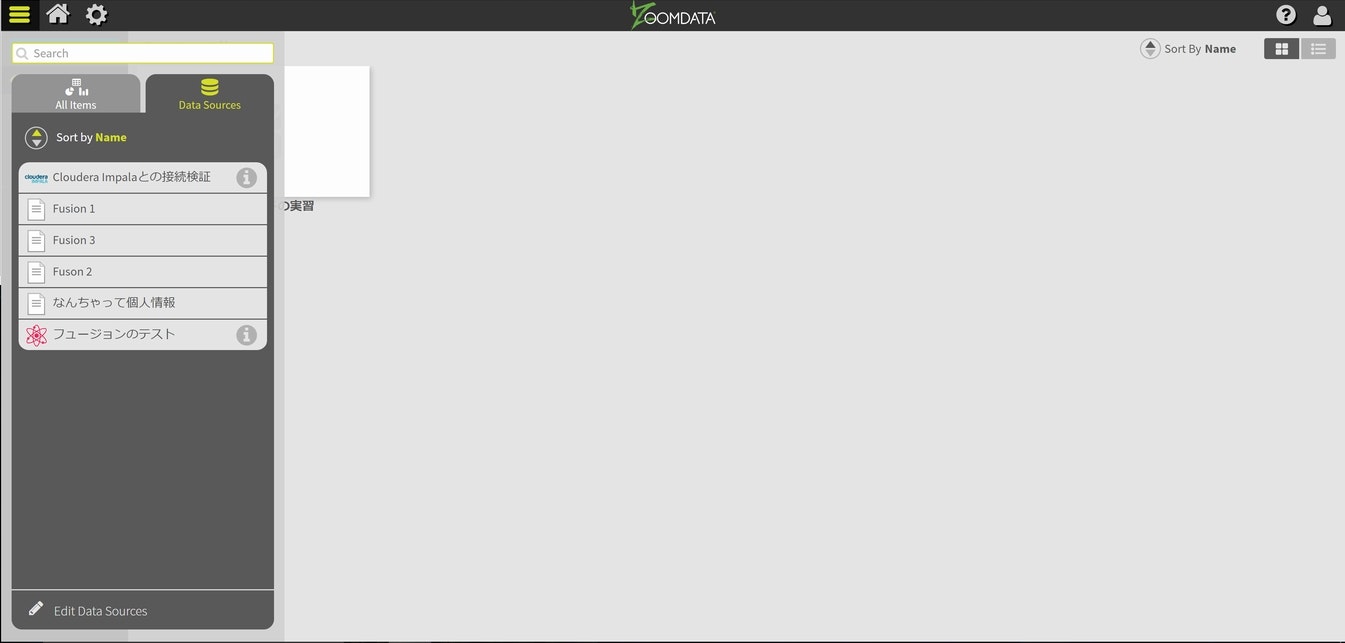
左上のアイコンからダッシュボードの作成から今回設定したCloudera Impalaを選択します。
利用可能なチャートが出てきますのでBarsを選択し、チャート下側のGroupをCityにします。
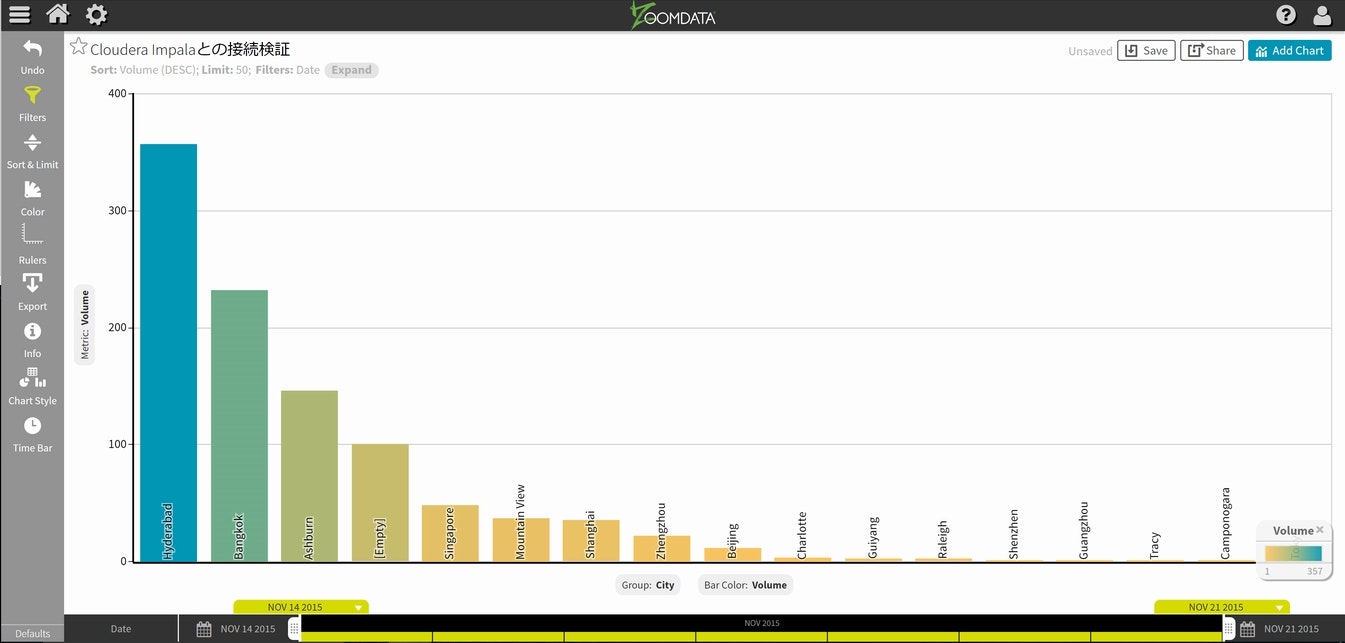
チャート下部にあるTime Barをスライドして、表示が同期するか確認してみてください。
次に、ドーナッツ・チャートを作成してみます。手順は依然と同じですので、ここでは流れのみのご紹介とさせて頂きます。
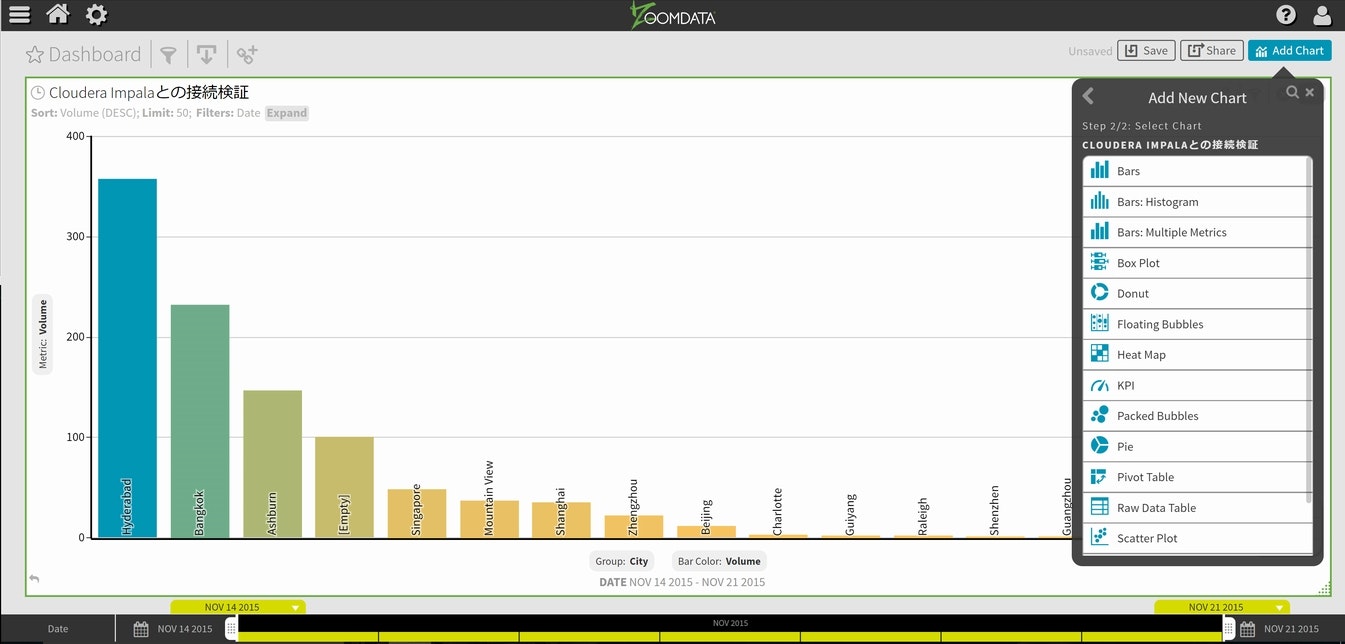
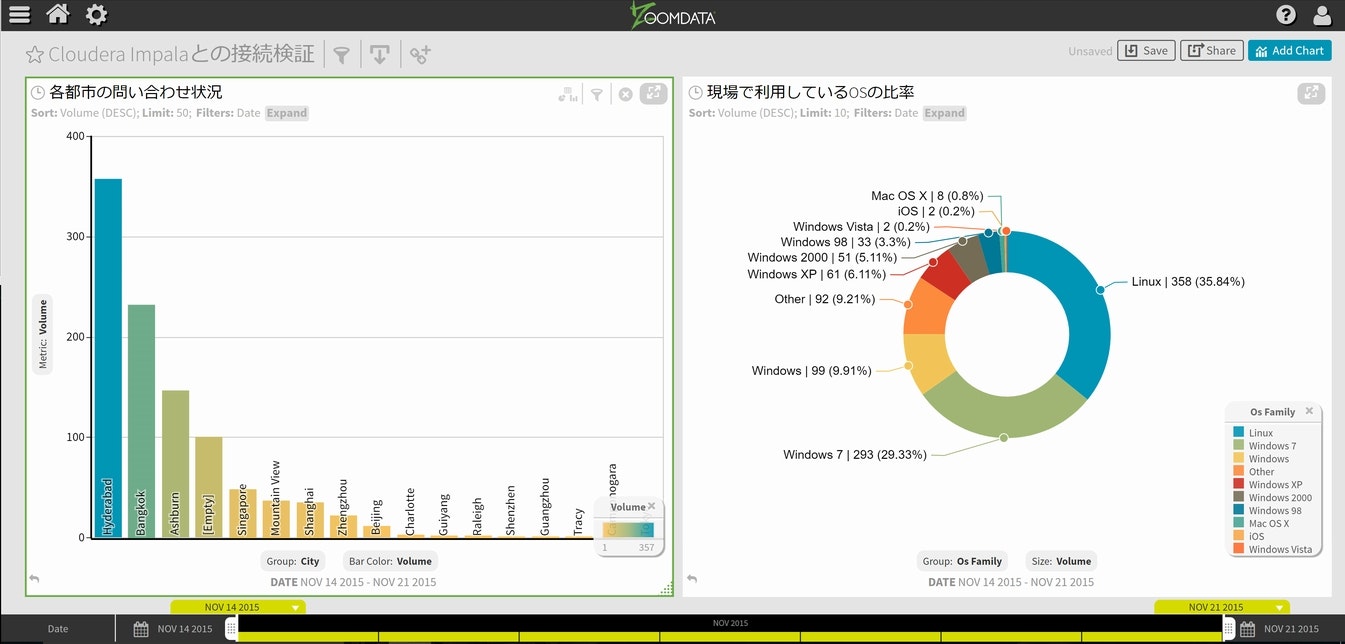
ドーナッツ・チャートの表示データは、データ項目にOSの利用割合が有りましたので、それをGroupで選択しています。
最後に、今回作成したダッシュボードを保存しておきたいと思います。
必要であれば、各チャート・タイトルとダッシュボード・タイトルを変更(例によって”なんちゃってタイトル”ですが・・)した後、コンソール画面右上のSaveを選択して必要事項を入力してから、ポップアップ右下のSaveを選択すれば、コンソールのホーム画面に表示されますので、次回以降はここからスタートできるようになります。
(4)今回のまとめ
今回は、ビッグデータとZoomdataの連携について、Cloudera Impalaを例に仮想環境を使った検証を行いました。適切に構築されたビッグデータ環境への接続が、実は非常にシンプルに実現できることがご理解頂けたかと思います(この点については、今後予定されている各ビッグデータ・ソリューションも同様です)もちろん検証環境ですので、ビッグではないという制限は存在しますが、もとよりスケールアウトを前提の各ソリューションに対して、マイクロクエリー接続とインメモリ・テクノロジーによる効率的&高速な接続を実現できますので、実際の巨大な”リアル・ビッグデータ”環境においても、同様にシンプルかつ柔軟な利用・運用を実現する事が可能になります。
次回は、冒頭の設定でデモデータの存在を確認できた、Solrでの接続を行ってみたいと思います。
(5)謝辞
今回の記事作成に関し、ビッグデータソースのエンジンとして、**Cloudera**社様が公開されているSandboxを活用させて頂きました。この場をお借りして厚く御礼申し上げます。