ZoomdataとHortonworksで、BI on Hadoop
Zoomdataと呼ばれる、BIプラットフォームを使って、Hive Tableのデータを可視化をしてみよう。Zoomdataは、内部でSparkを利用しておりデータをメモリにキャッシュする事で、高速にデータを可視化する事ができる。Azureでは、HortonworksもZoomdataもSandboxが提供されているので、そちらを使って簡単に試す事ができる。

手順
-
Azureで、Hortonworks Sandboxを使い、Hadoop、Sparkを試してみようを参考に、HDP Sandboxを展開する。
-
Marketplaceから、Zoomdataを展開する。詳細は、Getting Started with Microsoft Azure and Zoomdataを参照するといいだろう。
-
起動したら、https://ip_address:8443/zoomdata に、下記ユーザーでアクセスする
userid: admin
passwd: インスタンス名 -
左上の歯車アイコンをクリックし、「Hive On Tez」をクリック

-
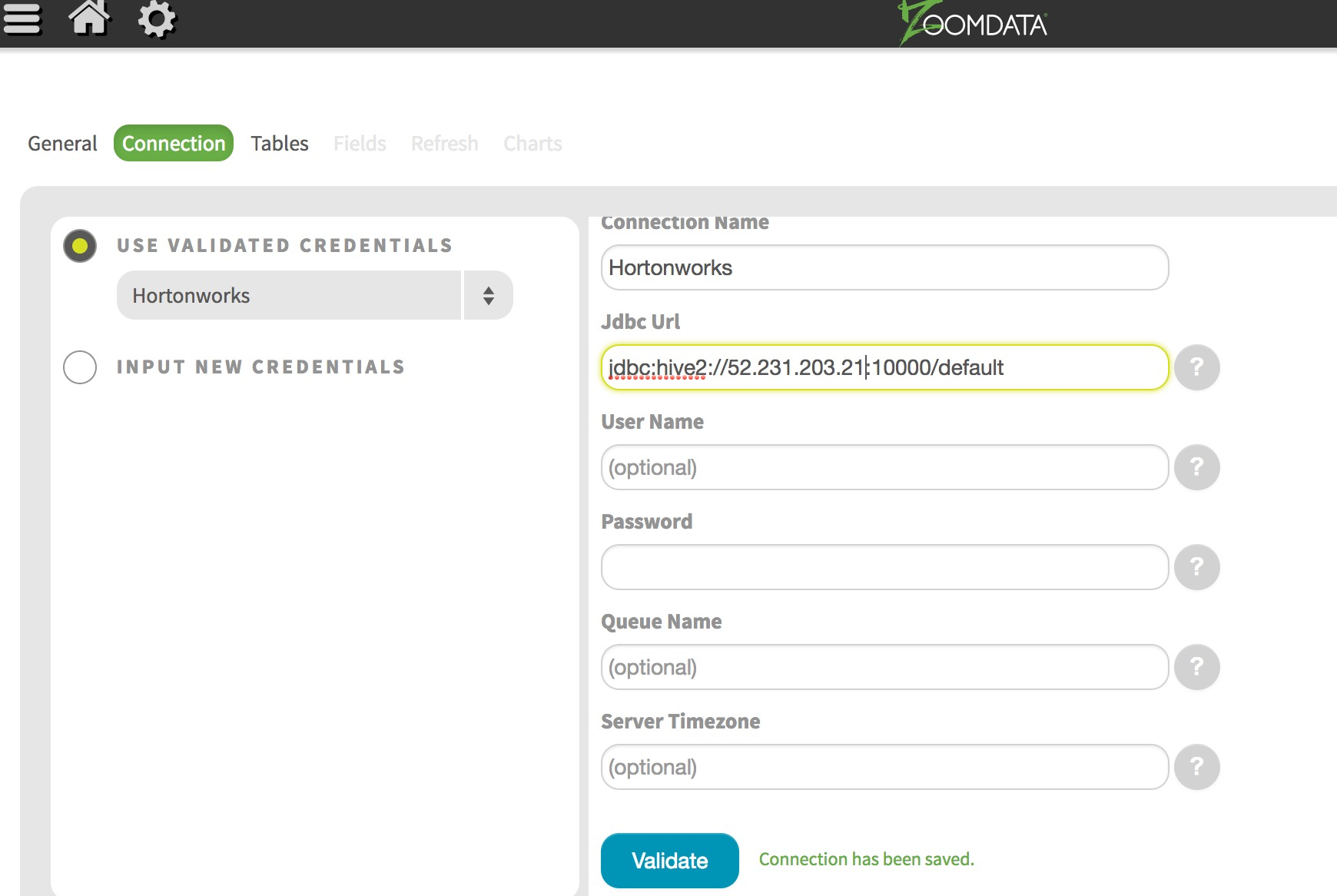
Hive On Tez Connectorに沿って、値を入力する

-
ConnectionのJDBCの設定は下記のように入力し、Validateをクリックし、Next
jdbc:hive2://ip_address:10000/default
(port 10000をネットワークセキュリティグループで開放しておく)
(再起動時には、割り当て解除にしておくと、ip_addressが変更されるので注意。)
-
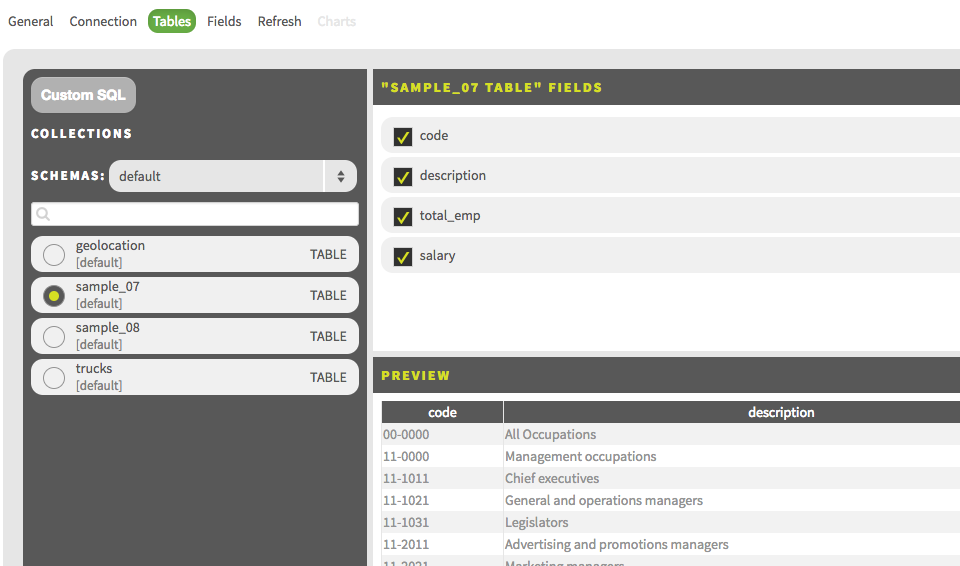
Hive tableを選択し、Next
-
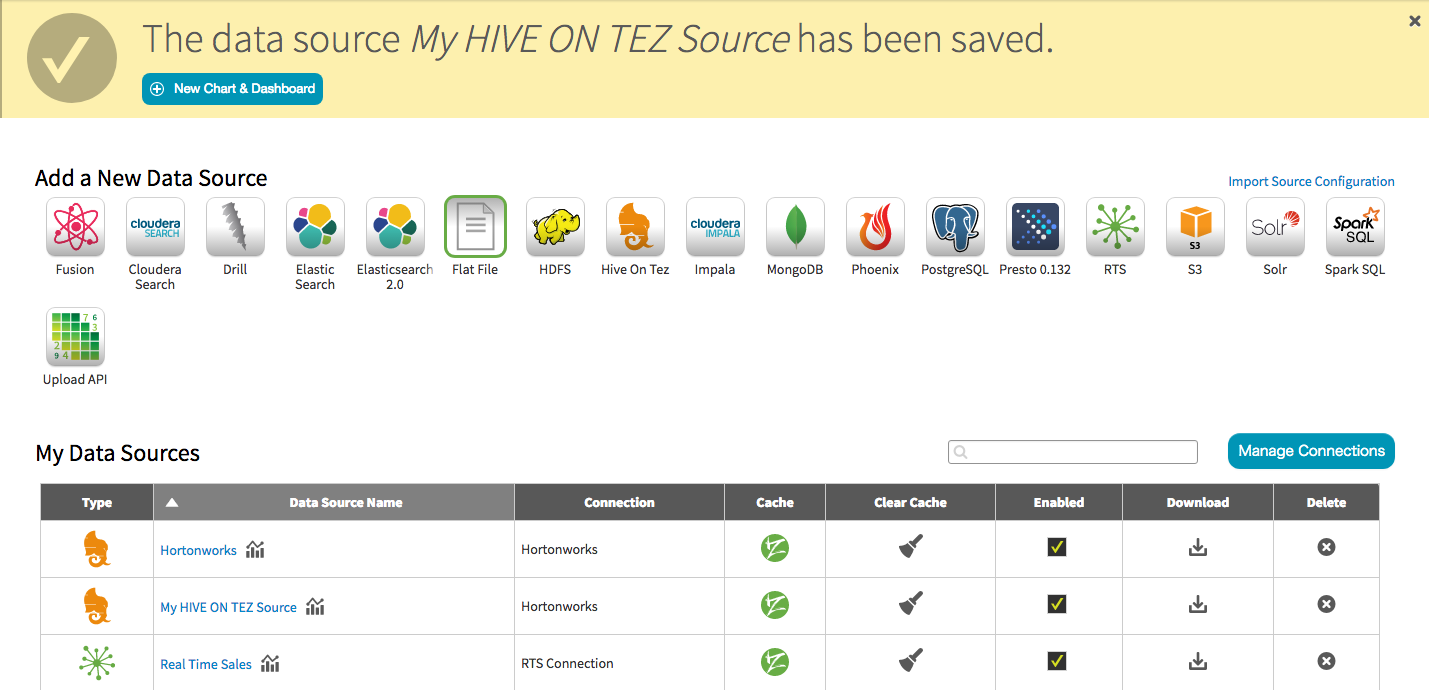
Saveしたら、New Chart & Dashboardをクリックし、お好みのチャートを作成する
-
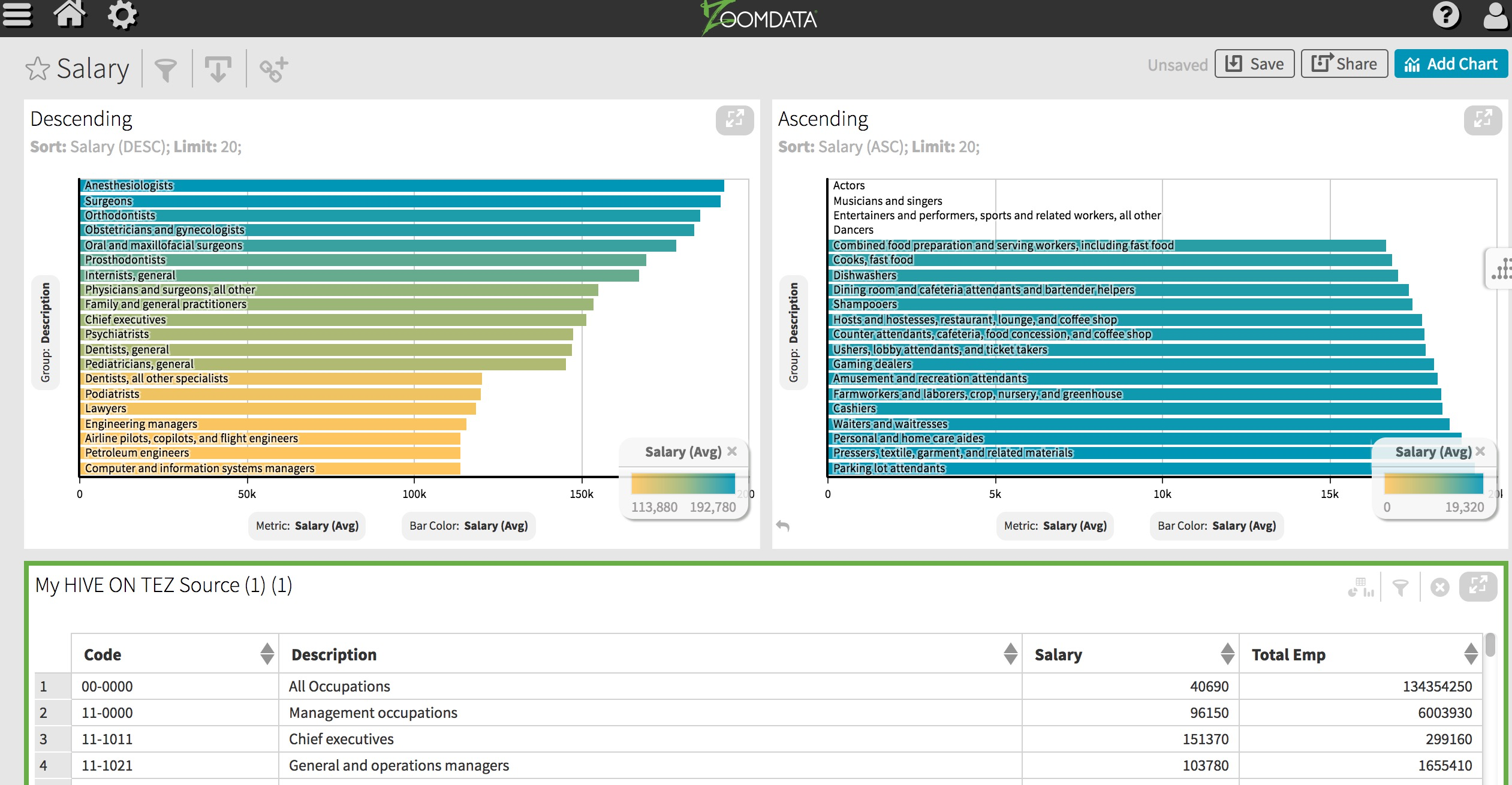
下記のようなチャートが作成できる。保存する場合は、Saveで保存する
以上