前回の続き・・・
今回は、前回の実践編1で作成したデータベースに、違う形式のテーブルを作成してみます。データの形式は縦型に長い形になり、メトリックスではなく属性志向でスタックされるイメージになります。
また、今回はMemSQLを導入したマシン上で通常のターミナルを使って作業を実施します。
まずはテーブルの定義を行います・・・
ターミナルを起動して、プロンプトで
memsql
を入力します。
このコマンドで、MemSQLの内部に入る事ができますので、以下順番にクエリを書いて行けばOKです。
memsql> USE test_db;
memsql> DROP TABLE IF EXISTS test_table02;
memsql> CREATE TABLE test_table02(
-> sensor CHAR(5) NOT NULL,
-> date_time DATETIME NOT NULL,
-> data DECIMAL(10,9) NOT NULL,
-> SHARD KEY(date_time)
-> );
memsql> LOAD DATA INFILE '/tmp/Test_Data02.csv'
-> INTO TABLE test_table02
-> FIELDS TERMINATED BY ',' ENCLOSED BY '"'
-> LINES TERMINATED BY '\r\n'
-> IGNORE 1 LINES;
検証用のCSVファイルは、前回同様に事前に**/tmp**にコピーしておきます。

基本的にメモリへの処理になりますので、非常に高速に処理が行われる事をご理解頂けるかと思います。
作業結果は同じターミナル経由でCLIベースのオペレーションでも確認できますが、今回はWebコンソール経由で確認してみます。

今回作成したテーブルも無事に作られています。

データも格納されている事が判ります。
Zoomdataで可視化してみる
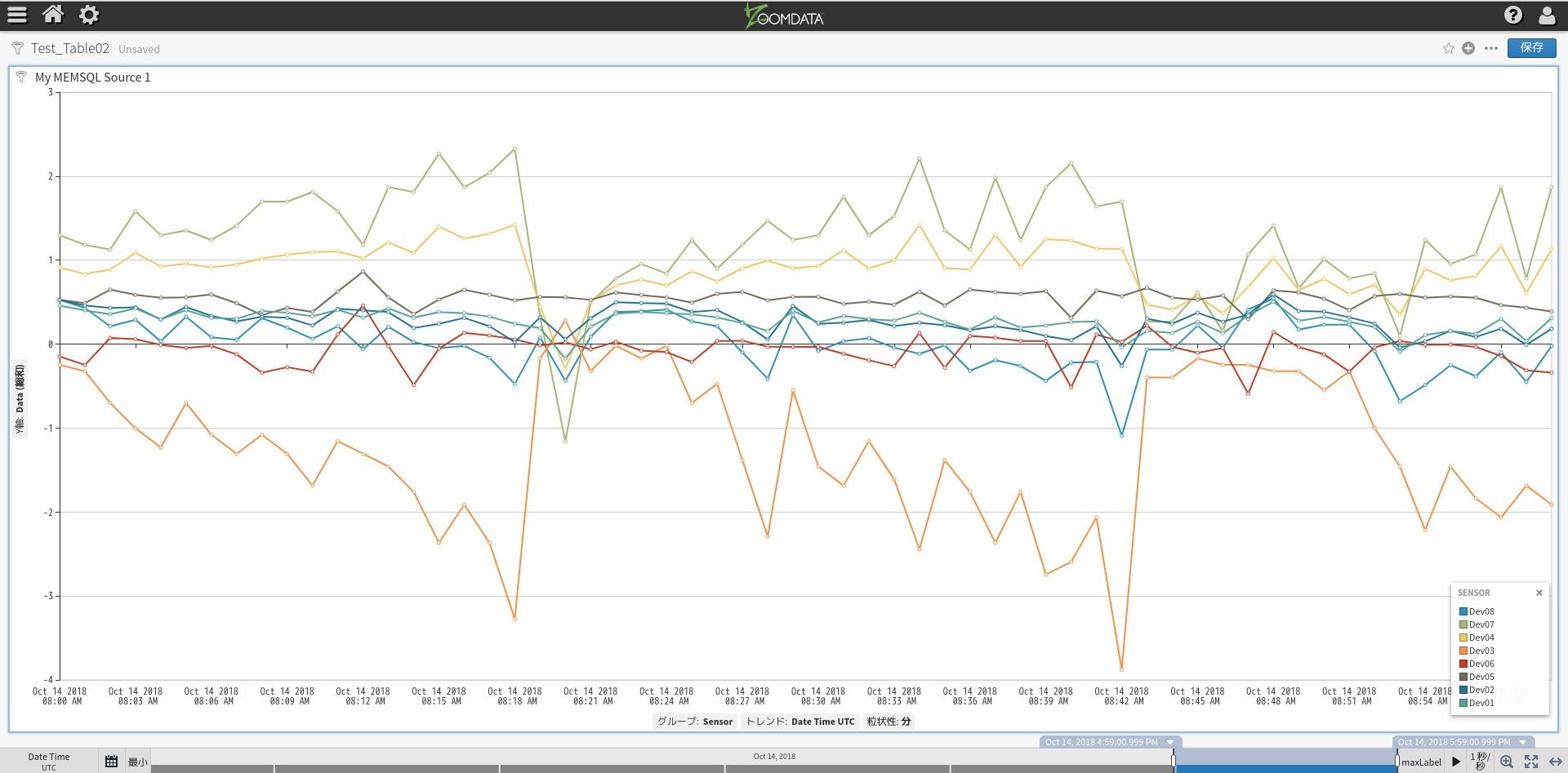
前回同様に、Zoomdataの試用版を使って可視化確認してました。

左側に前回のテーブルを表示してみました。
前回はライントレンドの複数メトリクスをチャートとして選択しましたが、今回の場合はライントレンドの属性値を選択して可視化を行っています。
ちょっとした性能評価をやってみる・・・
今回の最後の検証として、今まで実施してきたテーブル定義とCSVファイルからのデータローディングを一気に行ってみたいと思います。
実施環境について
(1)最初に実施したシンプルなCSVファイルを用いた場合
(2)2番目に実施したBI的に編集したCSVファイルを用いた場合
(3)(2)のファイルを用いてテーブル上のキー設定を変えた場合
(4)(3)と同様にキー設定を変えた場合
キーの取り扱いに関しては、実際にSQLクエリを多用する場合の最適化に直結しますので(正直Zoomdataでの可視化にはあまり影響しませんが。。。)別の機会に少し突っ込んで解説したいと思います。ですので、今回の”ちょっとした”編では、テーブル定義を微妙に変えて、異なるテーブルを4個一気に作成し、データを一気にローディングするという感じの緩い性能評価(確認)になります。
ハードウエアは、天下のmade in 秋葉原で、自作のCore i7(4コア8スレッド)+32GBメモリになります。(HDDではなく、240GBのSSDを搭載)GPUとかの高額アドオン系は一切使わない、極めてエコ(CPUの消費電力も少ないやつを購入して組み込んていますので、クロックも極めて普通かと)なピュアインメモリSQLサーバですね。
走らせるスクリプト
CREATE DATABASE IF NOT EXISTS test_db;
USE test_db;
DROP TABLE IF EXISTS test_table01;
CREATE TABLE test_table01(
date_time DATETIME NOT NULL,
dev1 DECIMAL(10,9) NOT NULL,
dev2 DECIMAL(10,9) NOT NULL,
dev3 DECIMAL(10,9) NOT NULL,
dev4 DECIMAL(10,9) NOT NULL,
dev5 DECIMAL(10,9) NOT NULL,
dev6 DECIMAL(10,9) NOT NULL,
dev7 DECIMAL(10,9) NOT NULL,
dev8 DECIMAL(10,9) NOT NULL,
SHARD KEY(date_time)
);
LOAD DATA INFILE '/tmp/Test_Data01.csv'
INTO TABLE test_table01
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
LINES TERMINATED BY '\r\n'
IGNORE 1 LINES;
DROP TABLE IF EXISTS test_table02;
CREATE TABLE test_table02(
sensor CHAR(5) NOT NULL,
date_time DATETIME NOT NULL,
data DECIMAL(10,9) NOT NULL,
SHARD KEY(date_time)
);
LOAD DATA INFILE '/tmp/Test_Data02.csv'
INTO TABLE test_table02
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
LINES TERMINATED BY '\r\n'
IGNORE 1 LINES;
DROP TABLE IF EXISTS test_table03;
CREATE TABLE test_table03(
sensor CHAR(5) NOT NULL,
date_time DATETIME NOT NULL,
data DECIMAL(10,9) NOT NULL,
SHARD KEY(date_time,sensor)
);
LOAD DATA INFILE '/tmp/Test_Data02.csv'
INTO TABLE test_table03
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
LINES TERMINATED BY '\r\n'
IGNORE 1 LINES;
DROP TABLE IF EXISTS test_table04;
CREATE TABLE test_table04(
sensor CHAR(5) NOT NULL,
date_time DATETIME NOT NULL,
data DECIMAL(10,9) NOT NULL,
SHARD KEY(sensor)
);
LOAD DATA INFILE '/tmp/Test_Data02.csv'
INTO TABLE test_table04
FIELDS TERMINATED BY ',' ENCLOSED BY '"'
LINES TERMINATED BY '\r\n'
IGNORE 1 LINES;
このスクリプトをクリーンな状態のMemSQLで走らせます。(もちろん、事前に必要なCSVファイルを**/tmp**に転送しておきます)
実行してみます!
念のためデータベースの状況をWebコンソールで確認します。

スクリプトをターミナル経由で実行します。
[MemSQL_Test@localhost ~]$ memsql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 32
Server version: 5.5.58 MemSQL source distribution (compatible; MySQL Enterprise & MySQL Commercial)
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
memsql> CREATE DATABASE IF NOT EXISTS test_db;
Query OK, 1 row affected (2.58 sec) <<<下準備なので、少し時間が掛ります。
memsql> USE test_db;
Database changed
memsql>
memsql> DROP TABLE IF EXISTS test_table01;
Query OK, 0 rows affected (0.00 sec) **<<<計測不能??な位で終了**
memsql> CREATE TABLE test_table01(
-> date_time DATETIME NOT NULL,
-> dev1 DECIMAL(10,9) NOT NULL,
-> dev2 DECIMAL(10,9) NOT NULL,
-> dev3 DECIMAL(10,9) NOT NULL,
-> dev4 DECIMAL(10,9) NOT NULL,
-> dev5 DECIMAL(10,9) NOT NULL,
-> dev6 DECIMAL(10,9) NOT NULL,
-> dev7 DECIMAL(10,9) NOT NULL,
-> dev8 DECIMAL(10,9) NOT NULL,
-> SHARD KEY(date_time)
-> );
Query OK, 0 rows affected (0.11 sec) <<<サクッと定義終了
memsql>
memsql> LOAD DATA INFILE '/tmp/Test_Data01.csv'
-> INTO TABLE test_table01
-> FIELDS TERMINATED BY ',' ENCLOSED BY '"'
-> LINES TERMINATED BY '\r\n'
-> IGNORE 1 LINES;
Query OK, 3660 rows affected (0.05 sec) <<<約3600行x8個+1(日時)の流し込み終了
memsql>
memsql> DROP TABLE IF EXISTS test_table02;
Query OK, 0 rows affected (0.00 sec) <<<ここは以降無視します・・
memsql> CREATE TABLE test_table02(
-> sensor CHAR(5) NOT NULL,
-> date_time DATETIME NOT NULL,
-> data DECIMAL(10,9) NOT NULL,
-> SHARD KEY(date_time)
-> );
Query OK, 0 rows affected (0.03 sec) <<<カラムが少ない分早い??
memsql>
memsql> LOAD DATA INFILE '/tmp/Test_Data02.csv'
-> INTO TABLE test_table02
-> FIELDS TERMINATED BY ',' ENCLOSED BY '"'
-> LINES TERMINATED BY '\r\n'
-> IGNORE 1 LINES;
Query OK, 29280 rows affected (0.04 sec) <<<データの大きさ的には同じなので誤差の範囲かと
memsql>
memsql> DROP TABLE IF EXISTS test_table03;
Query OK, 0 rows affected (0.00 sec)
memsql> CREATE TABLE test_table03(
-> sensor CHAR(5) NOT NULL,
-> date_time DATETIME NOT NULL,
-> data DECIMAL(10,9) NOT NULL,
-> SHARD KEY(date_time,sensor)
-> );
Query OK, 0 rows affected (0.02 sec) <<<SHARD KEYの設定を変えた影響??
memsql>
memsql> LOAD DATA INFILE '/tmp/Test_Data02.csv'
-> INTO TABLE test_table03
-> FIELDS TERMINATED BY ',' ENCLOSED BY '"'
-> LINES TERMINATED BY '\r\n'
-> IGNORE 1 LINES;
Query OK, 29280 rows affected (0.03 sec) <<<テーブル定義と同じ傾向で少し時短
memsql>
memsql> DROP TABLE IF EXISTS test_table04;
Query OK, 0 rows affected (0.00 sec)
memsql> CREATE TABLE test_table04(
-> sensor CHAR(5) NOT NULL,
-> date_time DATETIME NOT NULL,
-> data DECIMAL(10,9) NOT NULL,
-> SHARD KEY(sensor)
-> );
Query OK, 0 rows affected (0.02 sec) <<<センサーのカラムをキーにするとdate_time単独より少し定義時間が早くなりした(注1)
memsql>
memsql> LOAD DATA INFILE '/tmp/Test_Data02.csv'
-> INTO TABLE test_table04
-> FIELDS TERMINATED BY ',' ENCLOSED BY '"'
-> LINES TERMINATED BY '\r\n'
-> IGNORE 1 LINES;
Query OK, 29280 rows affected (0.04 sec) <<<ただし、流し込み時間が少し増加します。
memsql>
memsql>
コンソール上に表示された時間の総計は2.92秒なので、今回の検証は3秒掛からない作業時間で無事終了!という事になります。またデータ数的には、計測データだけで約29,000個のテーブルを4個作っていますので、メモリへ書き込むという速度が圧倒的に早い事は少なくともご理解頂けたかと思います。
同じCSVファイルで同じテーブル定義を行った場合でも、SHARD KEYの設定でそれぞれの時間が微妙に変化する点が興味深いですね。その辺についての解説は次回以降で順次進めて行ければと考えておりますので、ここでは”MemSQLを上手く使うにはSHARD KEYなる謎の定義が重要な役割になる・・・”という位の認識で結構です。
また、可視化層としてZoomdataと連携させる場合は、必ずキーに時間情報を含めるようにしてください。これはZoomdataの内部特性上必須の条件になりますので、IoT等のストリーミング可視化(ライブモード)を検討されている場合等では十分留意するようにお願い致します。(今回の注1の設定の場合は、プレイバック・ライブ機能等が選択出来なくなります)
実際にテーブルが出来たか、MemSQLのWebコンソールで確認してみます。

無事に4つのテーブルがデータベースに収まっている事が確認できましたので、念のためZoomdataの試用環境で可視化してみます。

今回のまとめ
MemSQLがIoTや機械学習からのAI、またBI導入に成功して性能問題に直面しているユースケースに非常に有効に応用出来そうな感じは掴めて頂けたかと思います。
また、MemSQLの前後(上流側・下流側)は、基本的にMySQLで接続可能な環境を活用できる(MySQLの特定のバージョンを固定するものには注意が必要ですが)と思いますので、既存の電子帳簿型データベースや、クラウド連携で向こう側に蓄積されているいるデータ、またKafka等を通じてリアルタイムに流れ込んでくるIoT的なデータを高速・透過的に処理し、下流側に展開する利活用系のAIや深度解析ソリューションへ効率よく流し込む仕組みを統合的に構築できるデータベースであるとも言えるでしょう。
次回は・・・
完全な年末進行に入りますので、もしかすると1回か2回のチュートリアル紹介(MemSQL社が公式に公開している)をさせて頂き、新年の稼働開始のタイミングから少し突っ込んだ検証等に入るかもしれません。(済みません・・・・(汗))
では、一足早い締めになりますが、良いお年を!!
謝辞
本解説に転載させて頂いているスクリーンショットは、一部を除いて現在MemSQL社が公開されている公式ホームページの画像を使わせて頂いております。また、本内容とMemSQL社の公式ホームページで公開されている内容が異なる場合は、MemSQL社の情報が優先する事をご了解ください。