年末進行のため、少し脱線します・・・
以前の回でDocker上で小さなMemSQLを立ち上げるお話をさせて頂きましたが、今回はその際に紹介させて頂いた公式のチュートリアルについて、少し突っ込んだ解説をさせて頂く事にします。なお、この一連の作業に関しては、MemSQL社がネット上に公開している環境との通信が入りますので、インターネット接続が前提となります。
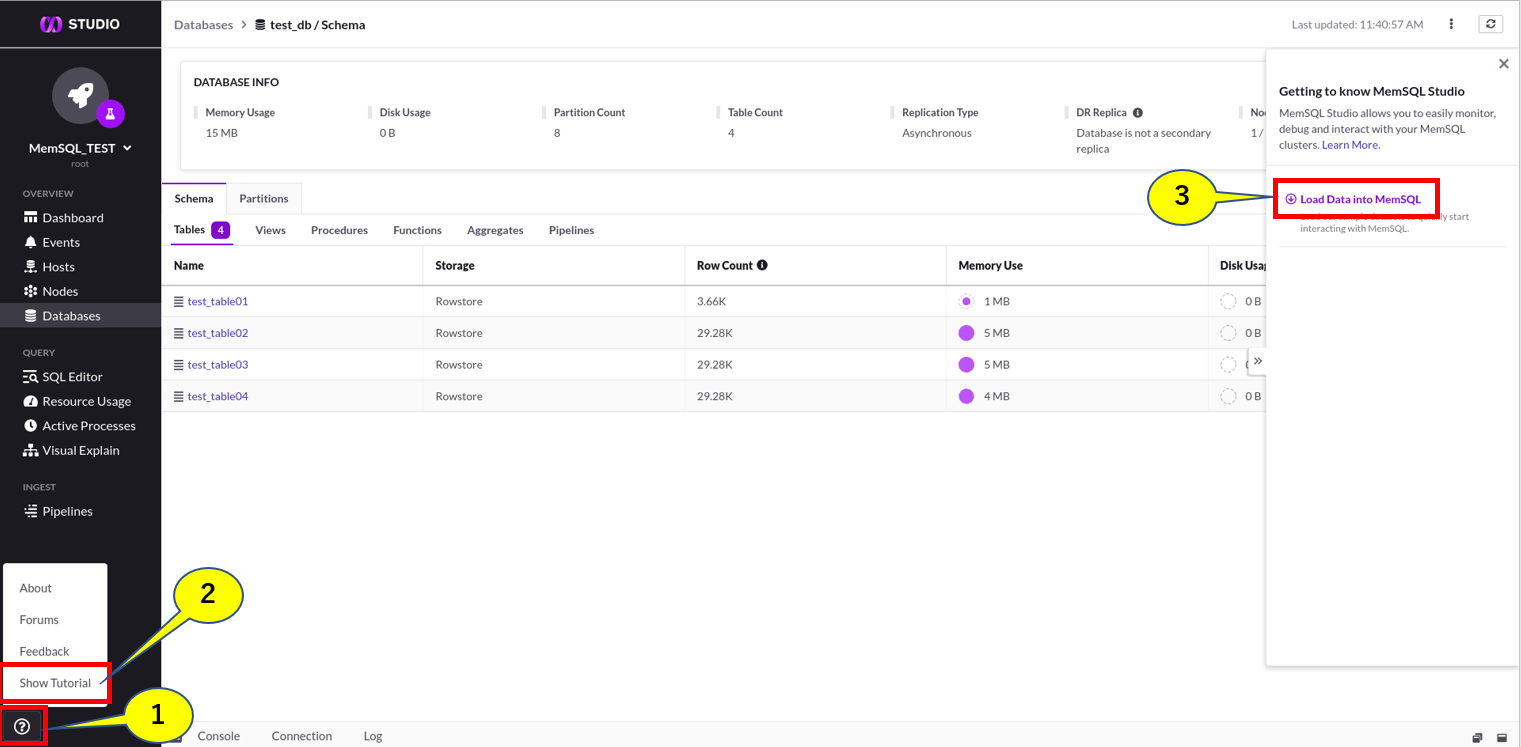
チュートリアルへの入り方
(1)Webコンソールの左下にある**?マークを選択
(2)Show Tutorialを選択
(3)右側にスライドしてきたパネルからLoad Data into MemSQL**を選択
検証作業の進め方
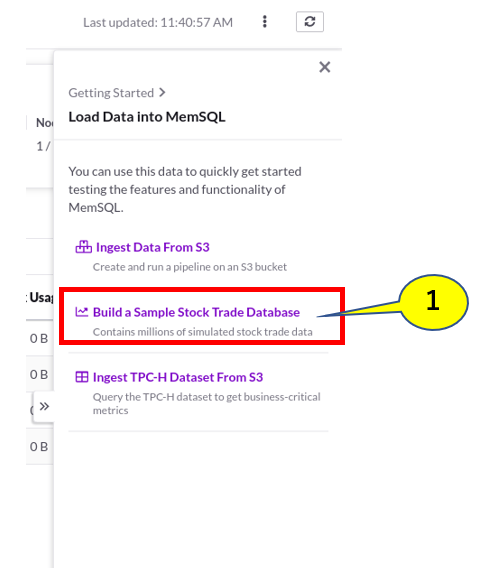
今回は、真ん中のBuild a Sample Stock Trade Databaseを選択します。
左下のStartを選択し、Webコンソールの左側メニューよりSQL Editorを選択します。

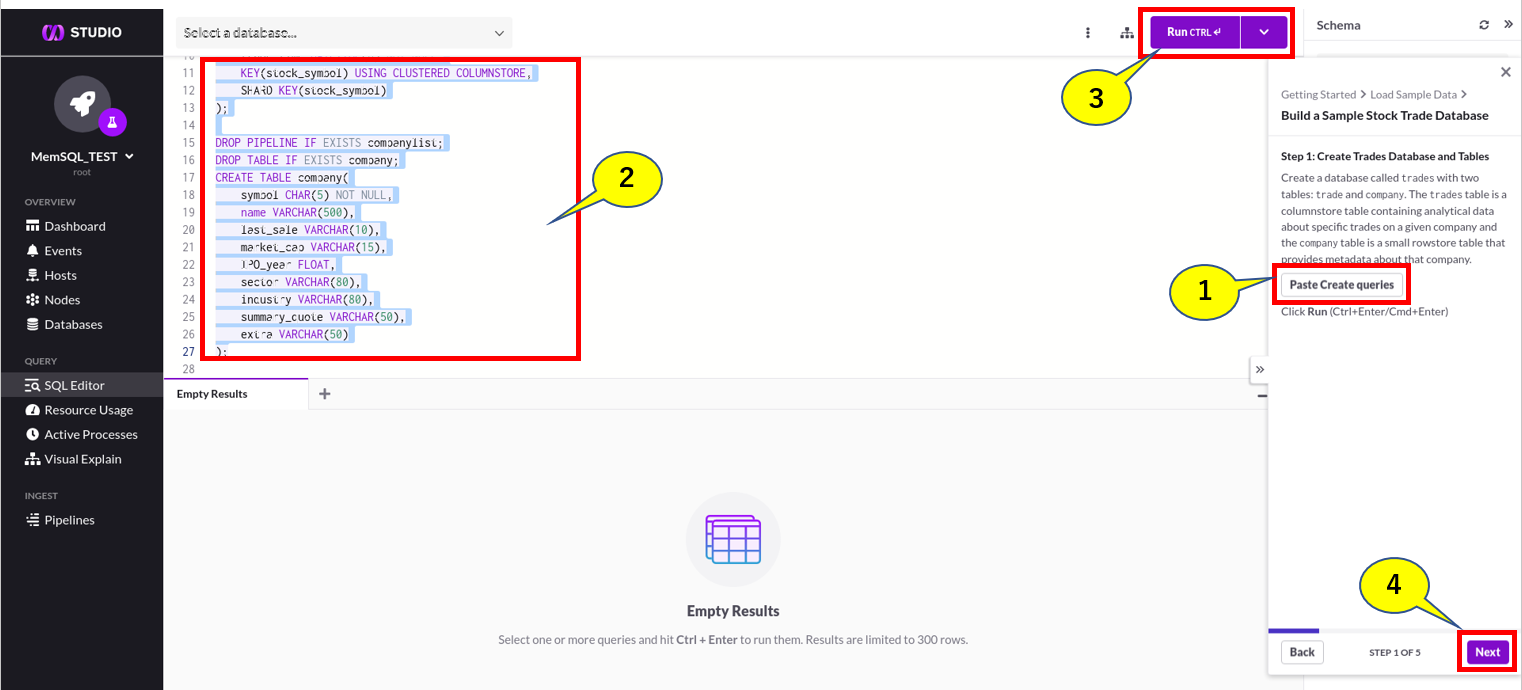
(1)Paste Create queriesを選択します。
(2)SQL Editorに作業を行うクエリコマンドが自動的に挿入されます。
(3)Webコンソールの左側上部にあるRunを選択します。
(4)作業終了を確認して、スライドパネル右下のNextを選択します。
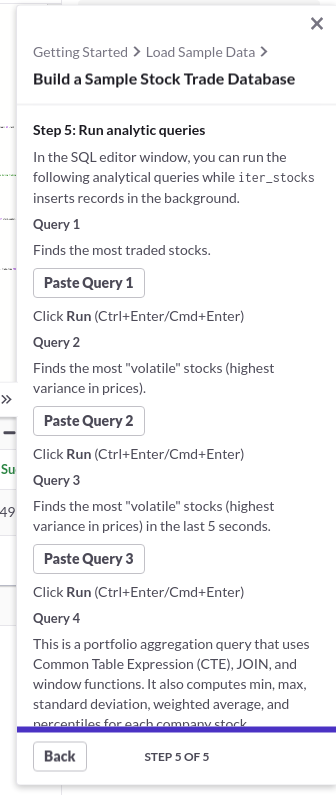
以降は、この作業の繰り返しになり、このスライドパネルで作業が終了します。
最後のパネルは、出来上がったデータベースに対して、幾つかのクエリを投げる検証作業になりますが、それぞれ”ほぼ”瞬時に作業が終了しますので、くれぐれも終了待ちという前提で油断されないようにお願い致します。
データベースが出来たかを確認
無事に作業が完了すれば、Webコンソールに生成されたデータべースを確認する事が出来ます。

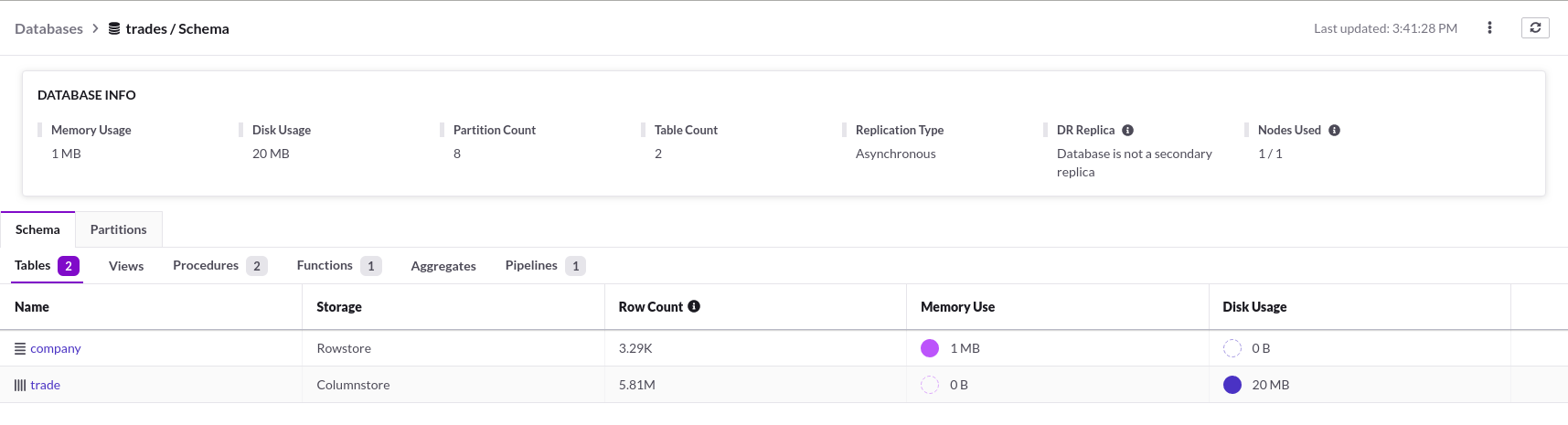
あれっ?!
Webコンソールで生成されたデータベースを確認された際に、今回は何か違う違和感を感じられたでしょうか?
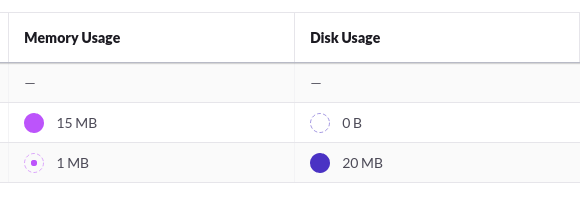
上側のデータベースは、前回までに生成されたメモリ上に展開されるデータベースの状況になりますが、当然メモリ上にしかテーブルを展開していませんので、ストレージ側にデータが存在しない形で稼働しています。ところが、今回のチュートリアルで生成したデータベースは、逆にメモリ上に展開されるデータよりも、圧倒的にストレージ側に展開されるデータが多い状況になっています。
カラムストアについて
MemSQLでは、基本的にHOTデータをメモリ領域に展開し、各種のデータアプリケーションに対して圧倒的に早く、分散並列の高効率なSQLトランザクションを提供しています。しかし、この仕組みの最大の弱点は・・・・メモリ空間を必要なだけ大量に用意しなければならない!という点に有ります。もちろん、スケール出来る仕組みでもありますので、クラスターをオンラインで追加し、タイミングを見てリバランスを実行すれば”今までのデータベース”の様なドタバタを覚悟する必要は有りません。しかし、大容量・低価格化が進んできているとはいえ、そこまでリッチにメモリを奮発する事は・・・というのが実情なのではないでしょうか。
ではどうするか?
MemSQL社の回答としては、参照系のデータ(過去の実績や、各種の基本台帳的な殆ど更新が無い系)を、縦の系列で揃える(この方式の利点は、データの性質が一定化出来るので、圧縮等の効率化が期待出来ます)事により、アクセスを出来るだけ局所的に抑える方式を提供し、外部からは通常のデータベースとして扱え、内部でカラムに特化したテーブル管理を開発し提供する事にしました。また、メモリ上に展開するテーブルにも幾つかの属性(通常、参照、一時)があり、それらと上手く組み合わせる事で効率よくデータベースを構築する事を可能にしています。さらに、このカラムストはには、専用のI/Oキャッシュ領域がメモリ上に存在し(逆に言えば、OSやアプリが利用する領域を除く全てのメモリ空間をメインのデータベースが使える訳ではありません)頻繁に参照するデータ等はこのメモリキャッシュから呼び出されますので、速度的にも十分期待できる機能だと思いますし、参照分析系のデータアプリに対しては、むしろ積極的に活用の検討を行っても良いかもしれません。
クエリに使われるSQLについて
Webコンソールに付属しているSQL Editorには、幾つかの便利な機能が有り、例えば外部で作成したSQLをファイル化してインポートしたり、逆にファイル化して外部に取り出す事が出来る様になっています。
今回はその機能を使って、チュートリアルで使われたSQLを眺めてみたいと思います。
取り出したSQLを眺めてみる・・・
まずはお約束のデータベースの作成と利用宣言から・・
CREATE DATABASE IF NOT EXISTS trades;
USE trades;
次にデータベースに展開するテーブルの作成
DROP TABLE IF EXISTS trade;
CREATE TABLE trade(
id BIGINT NOT NULL,
stock_symbol CHAR(5) NOT NULL,
shares DECIMAL(18,4) NOT NULL,
share_price DECIMAL(18,4) NOT NULL,
trade_time DATETIME(6) NOT NULL,
KEY(stock_symbol) USING CLUSTERED COLUMNSTORE,
SHARD KEY(stock_symbol)
);
**KEY(stock_symbol) USING CLUSTERED COLUMNSTORE,がカラムストアにテーブルを作成する決まり文句になります。クエリ的にstock_symbolを宣言し、それらをカラムストアに展開する宣言になります。詳細は改めて説明しますので今は・・・ふーん・・・という感じで記憶に留めておいてください。
DROP PIPELINE IF EXISTS companylist;
ここでも、謎のPIPELINEという定義が出てきました。このパイプライン機能は、MemSQLの特徴の一つでもあり、使いこなすと非常に便利な機能になりますので、詳細は改めて説明する事に致します。
DROP TABLE IF EXISTS company;
CREATE TABLE company(
symbol CHAR(5) NOT NULL,
name VARCHAR(500),
last_sale VARCHAR(10),
market_cap VARCHAR(15),
IPO_year FLOAT,
sector VARCHAR(80),
industry VARCHAR(80),
summary_quote VARCHAR(50),
extra VARCHAR(50)
);
メモリ上に展開するテーブルの定義を行います。
CREATE or REPLACE PIPELINE companylist
AS LOAD DATA S3 'download.memsql.com/first-time/'
CONFIG '{"region": "us-east-1"}'
INTO TABLE `company`
FIELDS TERMINATED BY ',' ENCLOSED BY '"';
START PIPELINE companylist FOREGROUND;
ここで、先ほどのパイプラインの生成と定義を行っています。
以下は幾つかプロシージャを定義しています
DELIMITER //
CREATE OR REPLACE FUNCTION marketcap_to_DECIMAL(s VARCHAR(15))
RETURNS DECIMAL(18,2) AS
DECLARE
m CHAR(1) = SUBSTR(s, LENGTH(s), 1); -- M or B
raw_v DECIMAL(18,2) = SUBSTR(s, 2, LENGTH(s) - 1);
v DECIMAL(18,2) = NULL;
BEGIN
IF m = "B" THEN
v = raw_v * 1000;
ELSE
v = raw_v;
END IF;
RETURN v;
END //
DELIMITER ;
DELIMITER //
CREATE OR REPLACE PROCEDURE seed_trades(num_trades INT) RETURNS INT AS
DECLARE
ranked_companies ARRAY(RECORD(symbol CHAR(5), _rank INT));
DECLARE
q QUERY(symbol CHAR(5), _rank INT) =
SELECT symbol, rank() OVER (ORDER BY marketcap_to_DECIMAL(market_cap)) AS _rank
FROM company
WHERE LENGTH(symbol) < 5
ORDER BY _rank DESC LIMIT 200;
i INT = 0;
rank_num INT;
next_id INT = 1;
sym CHAR(5);
price_base DECIMAL(18,4);
current_prices ARRAY(INT);
l ARRAY(RECORD(symbol CHAR(5), _rank INT));
BEGIN
l = collect(q);
FOR r IN l LOOP
i += 1;
rank_num = r._rank;
sym = r.symbol;
price_base = FLOOR(rand() * 50) + 50;
FOR j IN 1..((rank_num / 10) + RAND() * 10) LOOP
INSERT trade VALUES(
next_id,
sym,
FLOOR(1 + RAND() * 10) * 100, -- shares
price_base, -- share_price
DATE_ADD(NOW(), INTERVAL RAND() * 6 HOUR)); -- random time during trading day, roughly
next_id += 1;
IF next_id > num_trades THEN RETURN(next_id); END IF;
END LOOP;
END LOOP;
RETURN(next_id);
END //
DELIMITER ;
DELIMITER //
CREATE OR REPLACE PROCEDURE iter_stocks(iterations INT) as
DECLARE
tickers ARRAY(CHAR(5));
prices ARRAY(DECIMAL(18,4));
last_ids ARRAY(bigINT);
counts ARRAY(INT);
next_id bigINT = 1;
ticker CHAR(5);
price DECIMAL(18,4);
c INT;
rand DECIMAL(18,4);
tickers_q QUERY(t CHAR(5), p DECIMAL(18,4), lid BIGINT, c INT) = SELECT stock_symbol, share_price, MIN(id), COUNT(*) FROM trade GROUP BY stock_symbol;
q ARRAY(RECORD(t CHAR(5), p DECIMAL(18,4), lid bigINT, c INT));
q_count QUERY(c INT) = SELECT COUNT(*) FROM trade;
total_c INT;
BEGIN
q = COLLECT(tickers_q);
tickers = CREATE_ARRAY(LENGTH(q));
prices = CREATE_ARRAY(LENGTH(q));
last_ids = CREATE_ARRAY(LENGTH(q));
counts = CREATE_ARRAY(LENGTH(q));
total_c = SCALAR(q_count);
FOR r IN 0..LENGTH(q)-1 LOOP
tickers[r] = q[r].t;
prices[r] = q[r].p;
last_ids[r] = q[r].lid;
counts[r] = q[r].c;
END LOOP;
FOR j IN 0..(iterations-1) LOOP
FOR i IN 0..LENGTH(tickers)-1 LOOP
ticker = tickers[i];
price = prices[i];
next_id = last_ids[i];
c = counts[i];
rand = POW(-1, FLOOR(RAND()*2)) * RAND();
INSERT INTO trade
SELECT id + total_c, stock_symbol, shares, share_price + rand, trade_time FROM trade WHERE stock_symbol = ticker AND id >= next_id;
prices[i] = price + rand;
last_ids[i] = next_id + total_c;
END LOOP;
END LOOP;
END //
DELIMITER ;
プロシージャを呼び出して作業を行い・・
CALL seed_trades(100000);
CALL iter_stocks(100);
ここから良く見るSQLクエリを投げていきます・・・
SELECT stock_symbol, COUNT(*) AS c
FROM trade
GROUP BY stock_symbol
ORDER BY c DESC limit 10;
SELECT stock_symbol, VARIANCE(share_price) var
FROM trade
GROUP BY stock_symbol
ORDER BY var DESC;
SELECT stock_symbol, VARIANCE(share_price) var
FROM trade
WHERE trade_time * 1 > ( NOW() - 5 )
GROUP BY stock_symbol
ORDER BY var DESC;
WITH folio AS (
SELECT id, stock_symbol, shares, share_price, trade_time
FROM trade
),
AggCalcs AS (
SELECT
stock_symbol AS ACsymb,
MAX(share_price) AS pmax,
MIN(share_price) AS pmin,
STD(share_price) AS pstd,
SUM(share_price*shares)/SUM(shares) AS avg_pps, ## Weighted Average
SUM(share_price*shares) AS total_pvalue
FROM trade
GROUP BY 1
)
SELECT
DISTINCT folio.stock_symbol,
avg_pps,
pmin,
pmax,
percentile_cont(.25) WITHIN group (ORDER BY share_price) OVER (PARTITION BY stock_symbol) AS Q1,
percentile_cont(.5) WITHIN group (ORDER BY share_price) OVER (PARTITION BY stock_symbol) AS median,
percentile_cont(.75) WITHIN group (ORDER BY share_price) OVER (PARTITION BY stock_symbol) AS Q3
FROM folio
JOIN AggCalcs ON (folio.stock_symbol = ACsymb)
ORDER BY folio.stock_symbol;
SQLの経験がある方であれば、フーン・・・という感じで解読は一瞬かと思いますので、ここではそれぞれの詳細に関しての説明は省かせて頂きますが、結構ヘビーな処理が含まれている事はご理解頂けるかと思います。カラム側の特性を活かした(これは、ターゲットになるワークロードによるかと思います)テーブルを展開し、メモリ側にトランザクション&書き込み系のHOTデータを展開するイメージに加えて、パイプライン機能を使ってS3上のデータをネット経由で収集&展開を行うやり方も入っている、ある意味非常に基本的参考パターンのチュートリアルと言えるかもしれません。
年明け以降の予定・・・
年明け以降の稼働開始に合わせて、MemSQLの内部に少し踏み込んだ解説をしたいと考えています。また、今回のチュートリアル以外にも、幾つか例題がオンラインで試せますので、お時間と環境が許せば是非トライしてみてください。今後本格的にMemSQLを活用していく際に有効な、基本的なパターンを体験できるかと思います。
連携検証用のR環境構築関連は・・
ChromebookにLinux入れてRを使う・・に続く
謝辞
本解説に転載させて頂いているスクリーンショットは、一部を除いて現在MemSQL社が公開されている公式ホームページの画像を使わせて頂いております。また、本内容とMemSQL社の公式ホームページで公開されている内容が異なる場合は、MemSQL社の情報が優先する事をご了解ください。