midPoint by OpenStandia Advent Calendar 2024 の11日目は、いよいよmidPointからプロビジョニングしてみます。これまでは源泉システム(HRシステム)からCSVファイルでユーザーと組織情報をmidPointにインポートする部分を設定してきました。今回は外部のシステムにmidPointで保持しているデータをプロビジョニングする部分を設定していきます。連携先の種類として、一番シンプルであるCSVを利用します。
10日目までで構築した環境が前提となります。
連携先システムの仕様
今回のサンプル連携システムは、「アドレス帳(Addressbook)」システムとします。このシステムはCSVファイルで、以下の情報を受け取る仕様とします。
- userId:従業員番号
- familyName:姓
- givenName:名
- email:メールアドレス
- tel:電話番号
- orgId:主務組織の名称
- orgName:主務組織の名称
出力されるCSV内容例としては以下のイメージです。
userId,familyName,givenName,email,tel,orgId,orgName
1001,山田,太郎,taro.yamada@example.com,09001234567,005,営業第一部
...(省略)
出力されるCSVファイルの空データのもの(ヘッダ行のみ存在)を作成し、./addressbook/users.csvとして配置しておきます。midPointからはこのファイルにユーザー情報をプロビジョニングするように設定します。
.
├── .env
├── addressbook
│ └── users.csv
├── docker-compose.yml
├── hr
│ ├── orgs.csv
│ └── users.csv
└── post-initial-objects
├── 000-system-configuration.xml
├── 100-resource-hr-orgs.xml
├── 100-resource-hr-users.xml
├── 900-task-hr-import-users.xml
└── 900-task-hr-recon-orgs.xml
userId,familyName,givenName,email,tel,orgId,orgName
docker-compose.ymlの修正
./addressbook/配下をmidPointコンテナからアクセスできるように、docker-compose.ymlを以下のように修正しておきます。これで、midPointからは/var/lib/addressbook/users.csvでこのファイルにアクセスできます。
midpoint_server:
image: evolveum/midpoint:${MP_VER:-latest}-alpine
container_name: midpoint_server
hostname: midpoint-container
depends_on:
data_init:
condition: service_completed_successfully
midpoint_data:
condition: service_started
command: [ "/opt/midpoint/bin/midpoint.sh", "container" ]
ports:
- 8080:8080
environment:
- MP_SET_midpoint_repository_jdbcUsername=midpoint
- MP_SET_midpoint_repository_jdbcPassword=db.secret.pw.007
- MP_SET_midpoint_repository_jdbcUrl=jdbc:postgresql://midpoint_data:5432/midpoint
- MP_SET_midpoint_repository_database=postgresql
- MP_SET_midpoint_administrator_initialPassword=Test5ecr3t
- MP_UNSET_midpoint_repository_hibernateHbm2ddl=1
- MP_NO_ENV_COMPAT=1
- MP_ENTRY_POINT=/opt/entry-point
- TZ=Asia/Tokyo
networks:
- net
volumes:
- midpoint_home:/opt/midpoint/var
- ./post-initial-objects:/opt/entry-point/post-initial-objects:ro
- ./hr:/var/lib/hr
+ - ./addressbook:/var/lib/addressbook
midPointの起動
docker compose up -dで環境を起動します。
リソース設定の追加
5日目の記事などで解説した源泉データのインポートと同じように、プロビジョニングする際もリソース設定の追加を行います。作成の流れは基本的に同じですので、具体的な操作は過去の記事も参考にしてください。
midPointでは源泉データの取り込みもプロビジョニングも、リソースを作成してオブジェクト・タイプを追加し、その外部システムとのマッピングを定義します。今までは源泉データからの取り込みを実施するため、インバウンドマッピングという種類のマッピングを設定していました。一方、プロビジョニングの場合は、アウトバウントマッピングという種類のマッピングを設定します。
midPointでは、インバウンドマッピングとアウトバウンドマッピングの両方を設定し、双方向の同期を設定することも可能です。ただし、データフローが複雑化するため、基本的には一方向にデータが流れるように全体を設計した方がよいでしょう。
新規リソース作成時のリソースカタログでは、CSVファイルに連携したいため「CsvConnector」選択します。
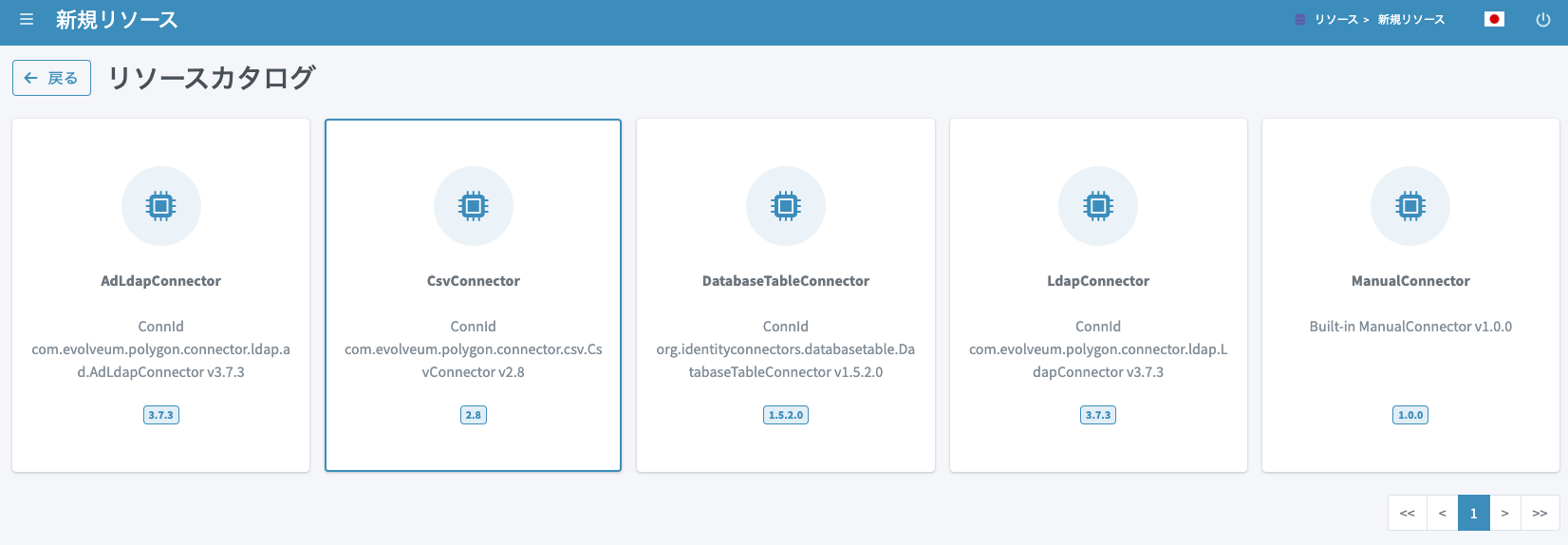
基本情報の設定です。区別が付くように名前を設定します。
-
名前:
Addressbook Users
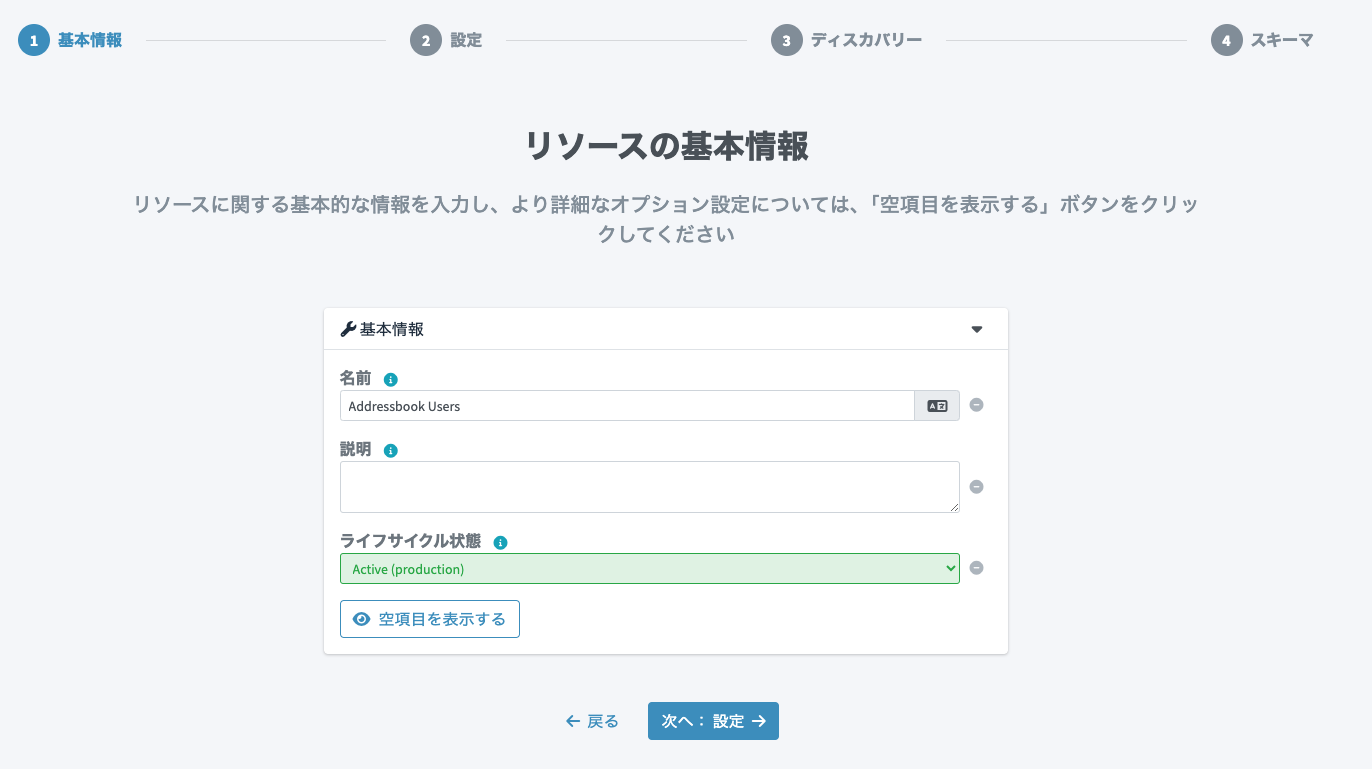
先ほど配置したヘッダのみのCSVファイルのパス(midPointコンテナ内での)を設定します。
-
File path:
/var/lib/addressbook/users.csv
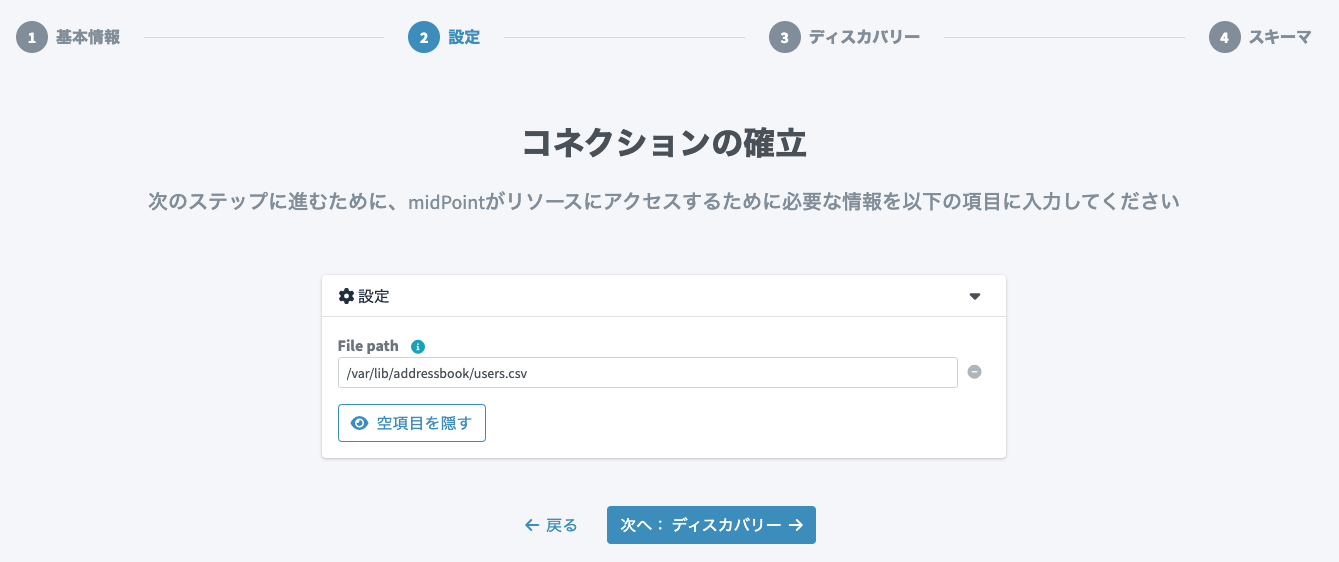
CSVコネクターの設定は下記の通りとします。
-
Field delimiter:
, - User password attribute name:(空のまま)
-
Name attribute:
userId -
Unique attribute name:
userId
オブジェクトタイプ・スキーマはデフォルトの「AccountObjectClass」のままでよいです。これでリソースの作成を行います。
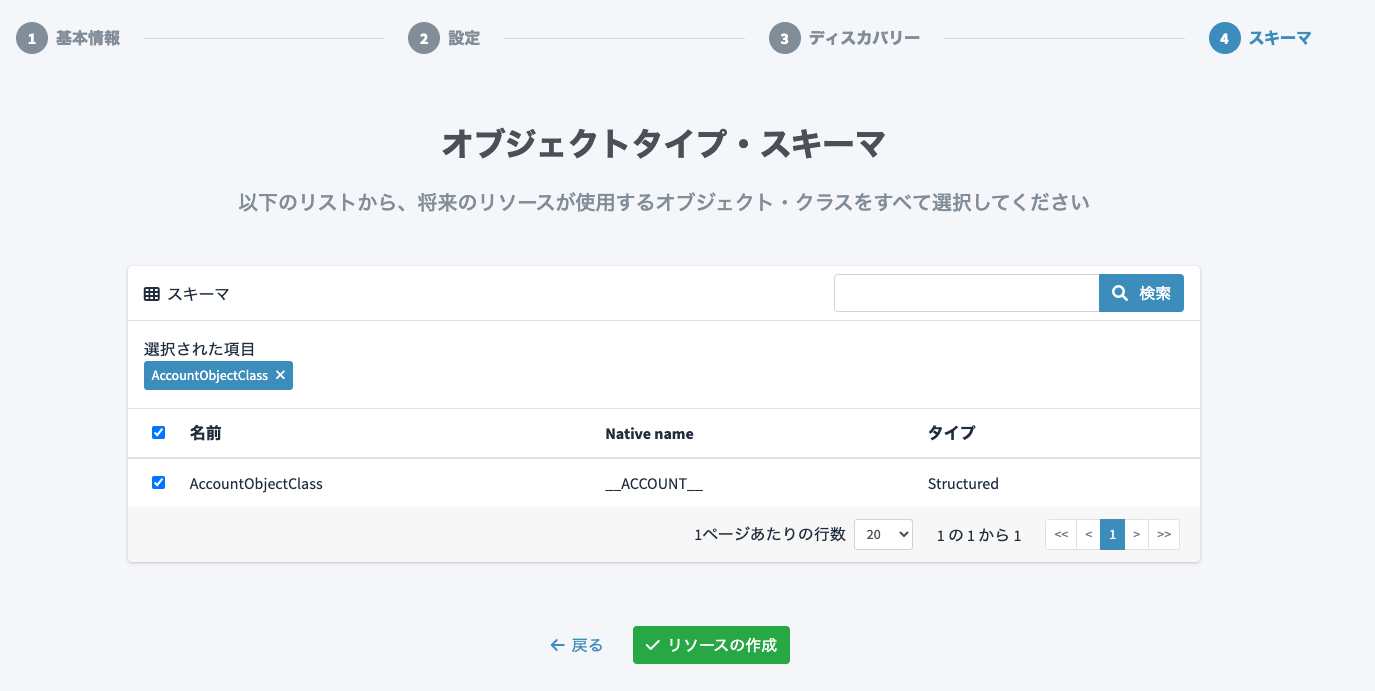
オブジェクト・タイプの追加
続いて作成した「Addressbook Users」リソースに、オブジェクトタイプを追加していきます。基本情報では、以下を設定します。
-
表示名:
Account -
種類:
アカウント
リソース・データの設定はデフォルトのままで次へ進みます。
MidPointデータの設定では、以下を設定します。midPoint内のユーザーオブジェクトをプロビジョニングするため、ここではユーザーを選択します。
-
タイプ:
ユーザー
マッピングの設定
マッピングの設定では、プロビジョニングを行うために 「アウトバウンドマッピング」 タブをクリックし、こちらのマッピングを追加していきます。
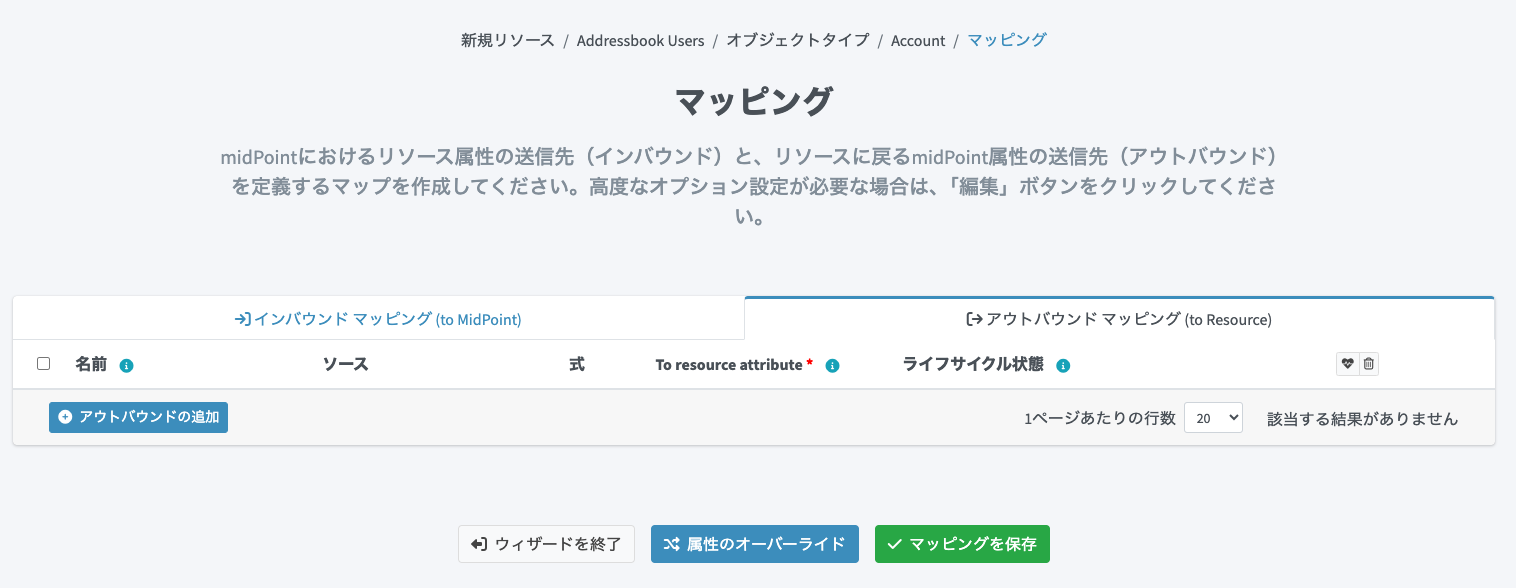
「アウトバウンドの追加」ボタンをクリックすると、編集行が追加されます(緑色の箇所)。

入力フィールドではサジェスト機能が働くため、先頭文字を少し入力すると絞込んで表示してくれます。
以下のように設定します。なお、名前(このマッピングの名前)は必須ではありません。デバッグ用途で使われます。ソース はプロビジョニング元であるmidPointのユーザー属性を指定します。To resource attribute にはターゲット側(プロビジョニング先)である連携先システム(CSVファイル)のカラム名を指定します。
-
ソース:
name -
式:
現状 -
To resource attribute:
userId

続けて「アウトバウンドの追加」ボタンをクリックし、編集行を追加して他の属性のマッピングも設定します。これをプロビジョニングしたい属性の数分繰り返します。マッピング内容は下表を参考に設定します。
| ソース | 式 | ターゲット |
|---|---|---|
| name | 現状 | userId |
| familyName | 現状 | familyName |
| givenName | 現状 | givenName |
| emailAddress | 現状 | |
| telephoneNumber | 現状 | tel |
| organization | 現状 | orgId |
| organization | スクリプト | orgName |
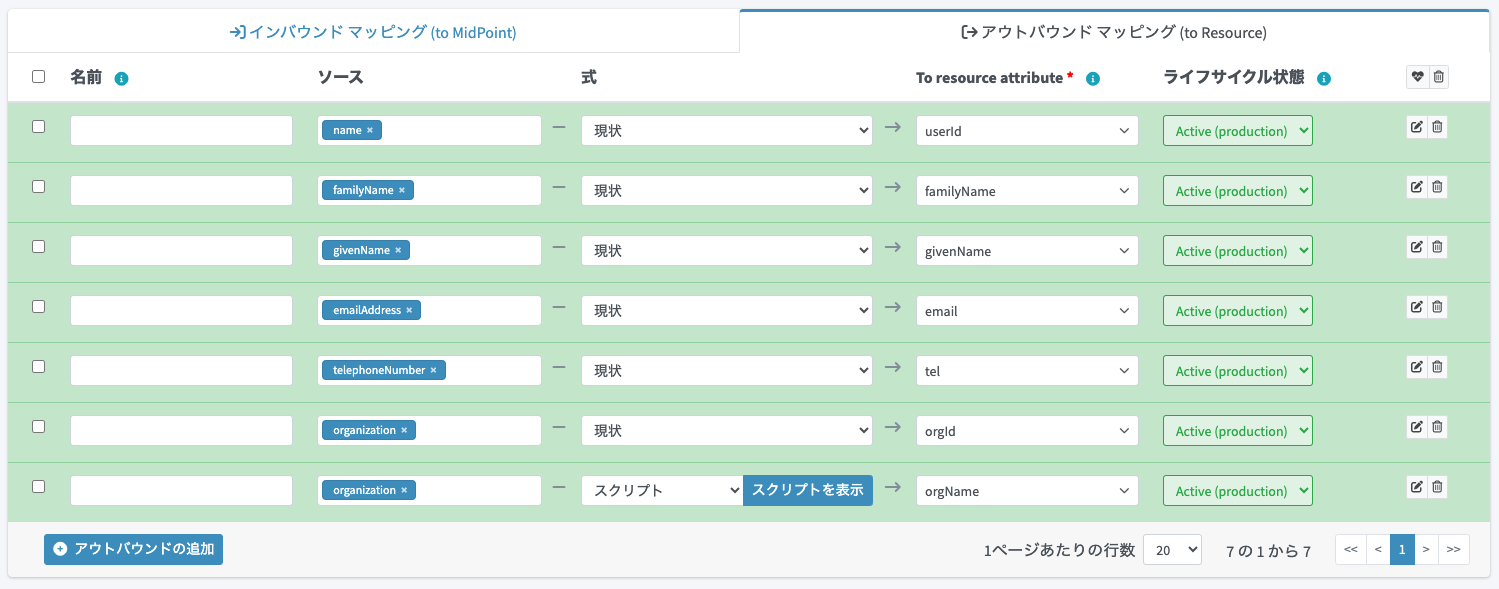
orgNameへのマッピングでは、スクリプトを選択している点に注意してください。今回、orgNameにはmidPointで管理している組織オブジェクトの表示名(displayName属性)をマッピングします。しかしながら、ユーザーのorganization属性には、組織IDが入っています。この組織IDから組織オブジェクトの表示名を解決する必要があります。
そこで、「式」 でスクリプトを設定しつつ、Groovyコードを記述して解決するように設定します。すぐ横の「スクリプトを表示」ボタンをクリックすると、「スクリプトの値」設定のダイアログがポップアップしますので、コードにmidpoint.getOrgByName(organization.orig)?.displayName.origを設定します。「実行」ボタンをクリックしてダイアログを閉じます。
midPointでは、Groovyスクリプト内で利用可能なビルトインの関数ライブラリが提供されています。以下のドキュメントに記載されています。
https://docs.evolveum.com/midpoint/reference/support-4.8/expressions/expressions/script/functions/
そのうちの一つがmidpoint変数で利用可能な「MidPoint Library」です。今回利用しているmidpoint.getOrgByName(String name)は、組織名(name属性)の値を引数で渡すと組織オブジェクトを検索して返してくれます。「ソース」で設定したmidPoint側の属性であるorganizationは、その変数名で参照できるため、これを引数に渡せばよいです。ただし、注意点としてorganization属性の型はPolyStringとなっており、そのままgetOrgByName関数に渡すことができません。PolyStringは、origプロパティでオリジナルの値を参照可能ですので、organization.origとします。
スクリプトを設定すると、以下のように「Evaluator value is set」と値が設定されている状態に変わります。これで「マッピングを保存」ボタンをクリックして保存します。

同期の設定
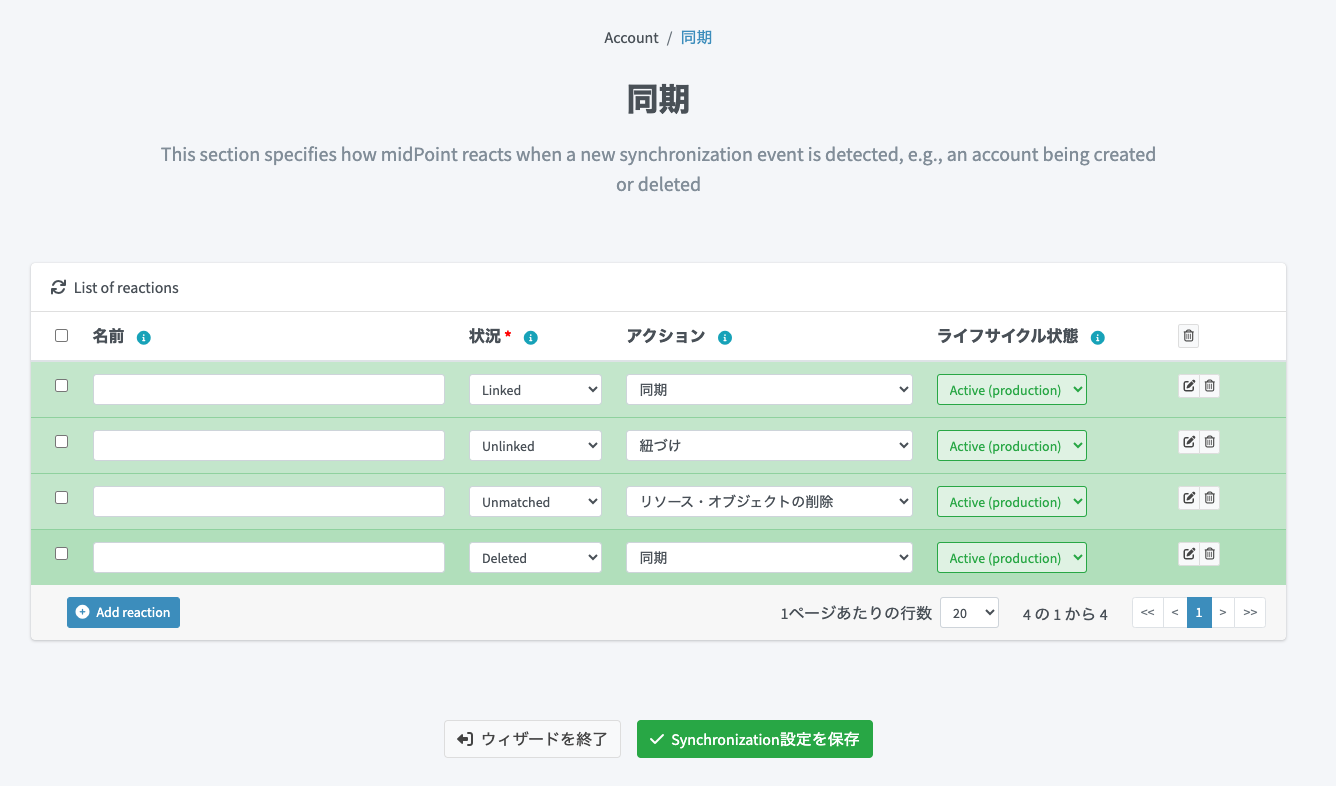
プロビジョニング目的の場合、同期の設定は実はなくてもプロビジョニング自体は可能です。ただし、このリソースに対するリコンシリエーションタスクを使用して名寄せにより紐づけ(リンク)させたり、同期や不整合の解消を行う場合は必要なので、ここではその設定を追加しておきます。
| 状況 | アクション | 設定意図 |
|---|---|---|
| Linked | 同期 | 既にLinked状態のユーザーに対して、リコンシリエーションタスクの実行時に差分があれば反映する1 |
| Unlinked | 紐づけ | 名寄せ処理にて、プロビジョニング先システムのデータと一致するmidPoint側のデータを発見した場合に、紐づけを行う |
| Unmatched | リソース・オブジェクトの削除 | リコンシリエーションタスク実行時にCSV側にだけ存在するユーザを発見した場合は、CSVから削除する |
| Deleted | 同期 | リコンシリエーションタスク実行時にプロビジョニング先システム側でユーザーが削除されたことを検知した場合は、再び連携先にユーザーをプロビジョニングする |
状況がUnmatchedのときにリソース・オブジェクトの削除を実行することで、連携先システム側でmidPointと関係なく追加されたデータを自動的にお掃除することができます。一方、運用上削除されると困るケースも想定されます。その場合はUnmatchedのルールは定義しないようにします。
Correlationの設定
名寄せ の設定です。先程の同期の設定で、状況が「Unlinked」の際にアクションを「紐づけ」と設定しました。この紐づけを正しく動作させるには、Correlationの設定を行い、どういったロジックで名寄せを行うのか設定する必要があります。また、後述するプロビジョニング時に名寄せを行うケースに対応するためにも、Correlationの設定が必要となります。
名寄せ用のインバウンドマッピングの追加
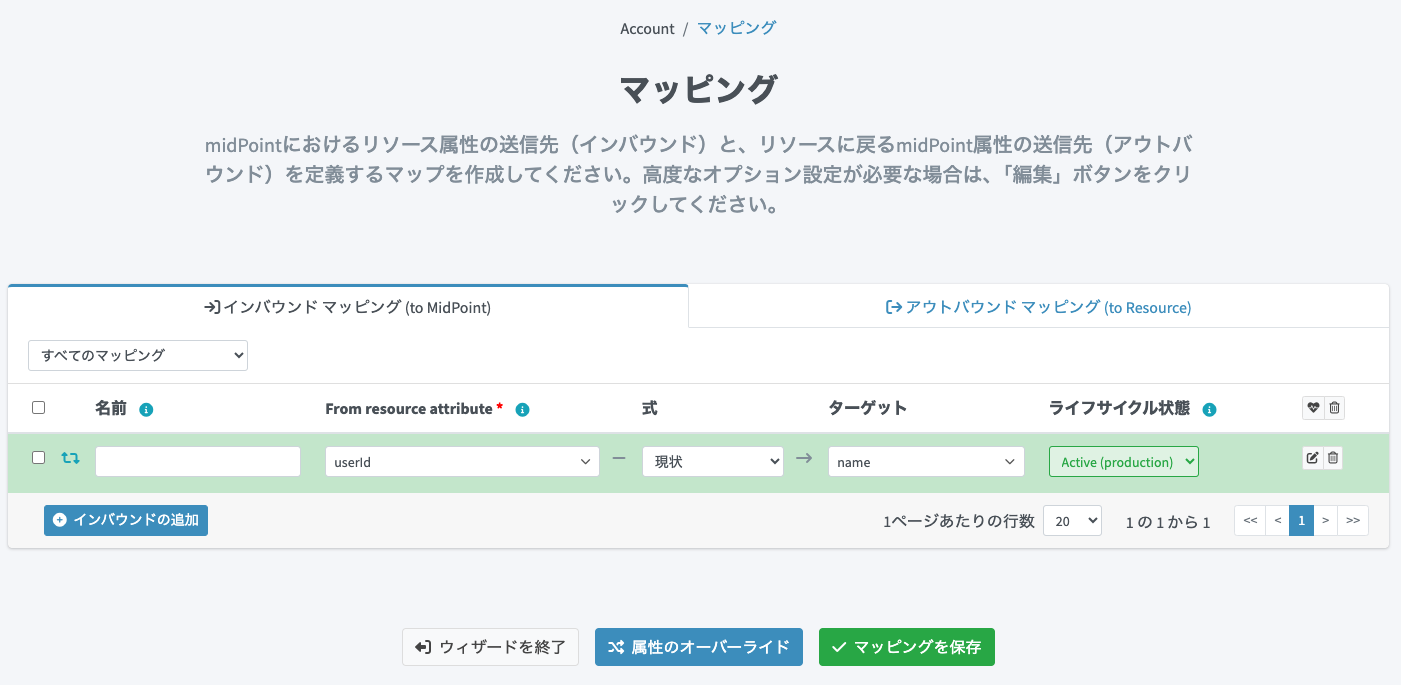
先程マッピングの設定にて、アウトバウンドマッピングのみを設定しました。しかし名寄せではインバウンドマッピングの情報を利用するため、名寄せ用のインバウンドマッピングを追加します。再度マッピングの設定画面を開き、以下の内容でインバウンドマッピングを追加します。
-
ソース:
name -
式:
現状 -
To resource attribute:
userId
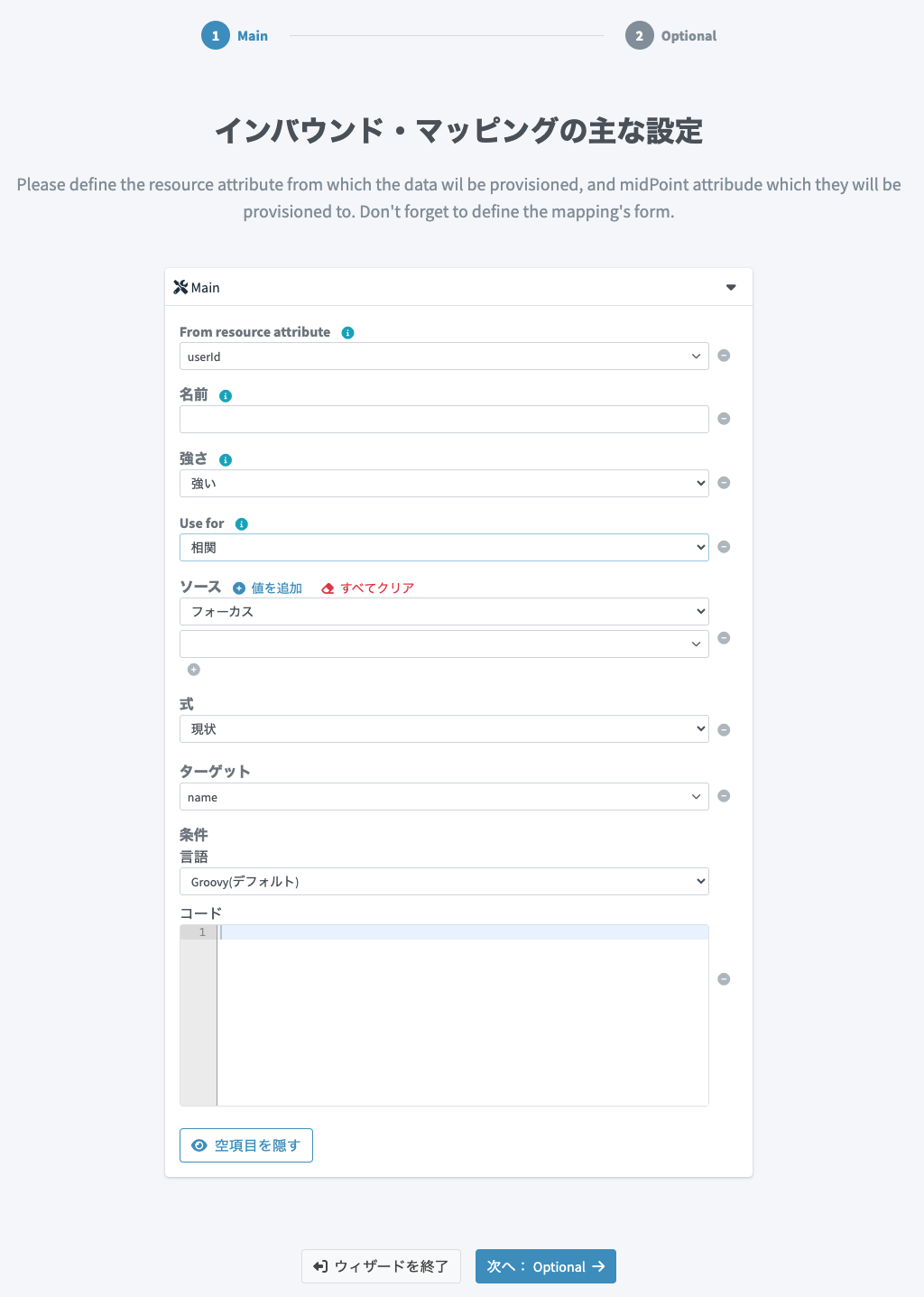
さらに、 をクリックしてこのインバウンドマッピングの詳細設定画面を表示します。ここで、Use for に
をクリックしてこのインバウンドマッピングの詳細設定画面を表示します。ここで、Use for に相関を設定します。これにより、このインバウンドマッピングは名寄せ用途のみで使われます。同期には使用されません。
「ウィザードを終了」ボタンをクリックしてマッピング画面に戻ります。そして「マッピングを保存」ボタンをクリックして保存します。
Correlationの設定
Correlationの設定画面を開き、ルールを追加ます。「ルールの追加」ボタンをクリックし、ルール名に区別が付くようにルール名(例:userId)を入力し、をクリックして詳細設定画面を開きます。

「Add correlator」ボタンをクリックし、「アイテム」に先ほど追加した名寄せ用のインバウンドマッピングのアイテムであるnameを選択します。
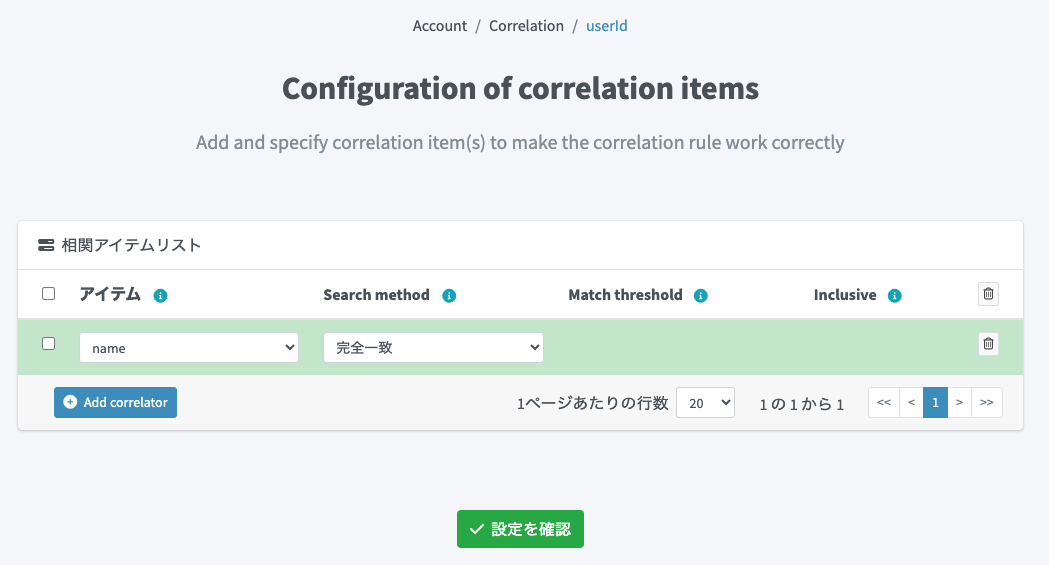
「設定を確認」ボタンをクリックしてCorrelationの設定画面に戻り、「Correlation設定を保存」ボタンをクリックして保存します。
プロビジョニングの確認
リソースの設定が完了したので、いよいよプロビジョニングさせてみます。いくつかやり方がありますが、簡易的な確認方法として、リソースを直接アサインしてプロビジョニングする方法を今回は紹介します。
リソースアサイン追加によるプロビジョニング
プロビジョニングを行うユーザーの詳細画面を開き、「アサイン > リソース」メニューを開きます。
 アイコンをクリックして、「オブジェクトの選択」ダイアログを表示します。「Addressbook Users」リソースにチェックを入れて、「種類」では
アイコンをクリックして、「オブジェクトの選択」ダイアログを表示します。「Addressbook Users」リソースにチェックを入れて、「種類」ではアカウント、「用途」ではdefaultを選択して、「追加」ボタンをクリックします。
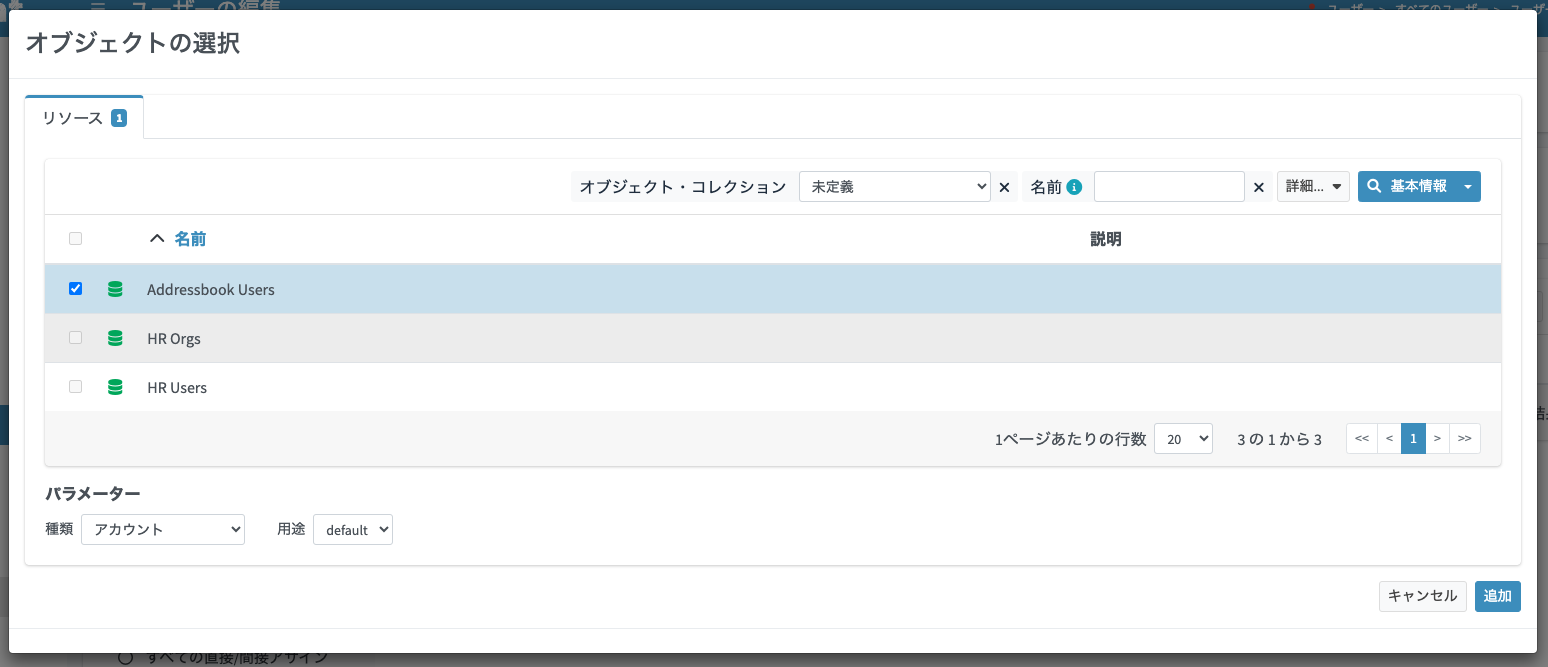
アサイン追加予定のリソースが追加されます(緑色の箇所)。
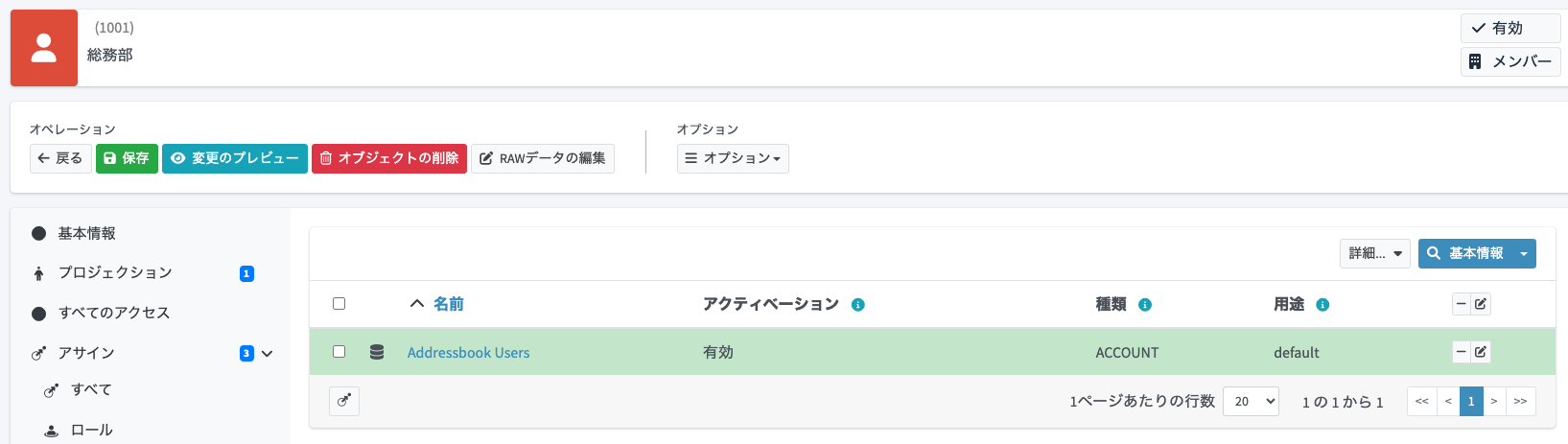
この状態で、「変更のプレビュー」をクリックしてみましょう。リソースの設定が正しければ、CSVへのプロビジョニング処理のプレビューが見れるはずです。
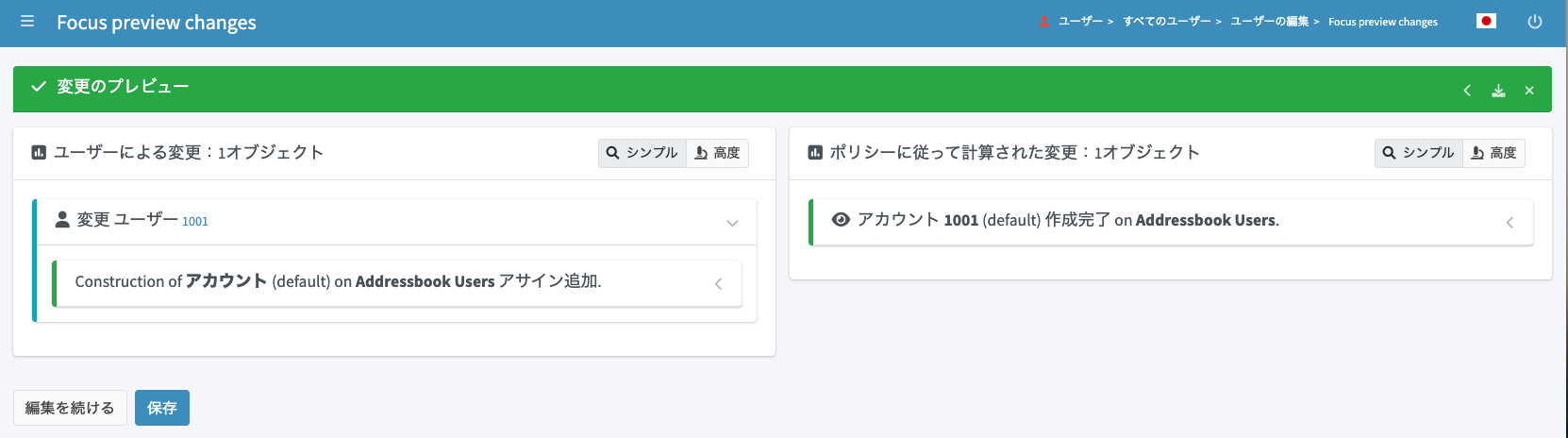
右上の「高度」の箇所をクリックすると、「Addressbook Users」リソースに対する変更内容の詳細を展開できます。CSVに追加されるデータ内容を確認し、想定通りの値になっていることを確認します。
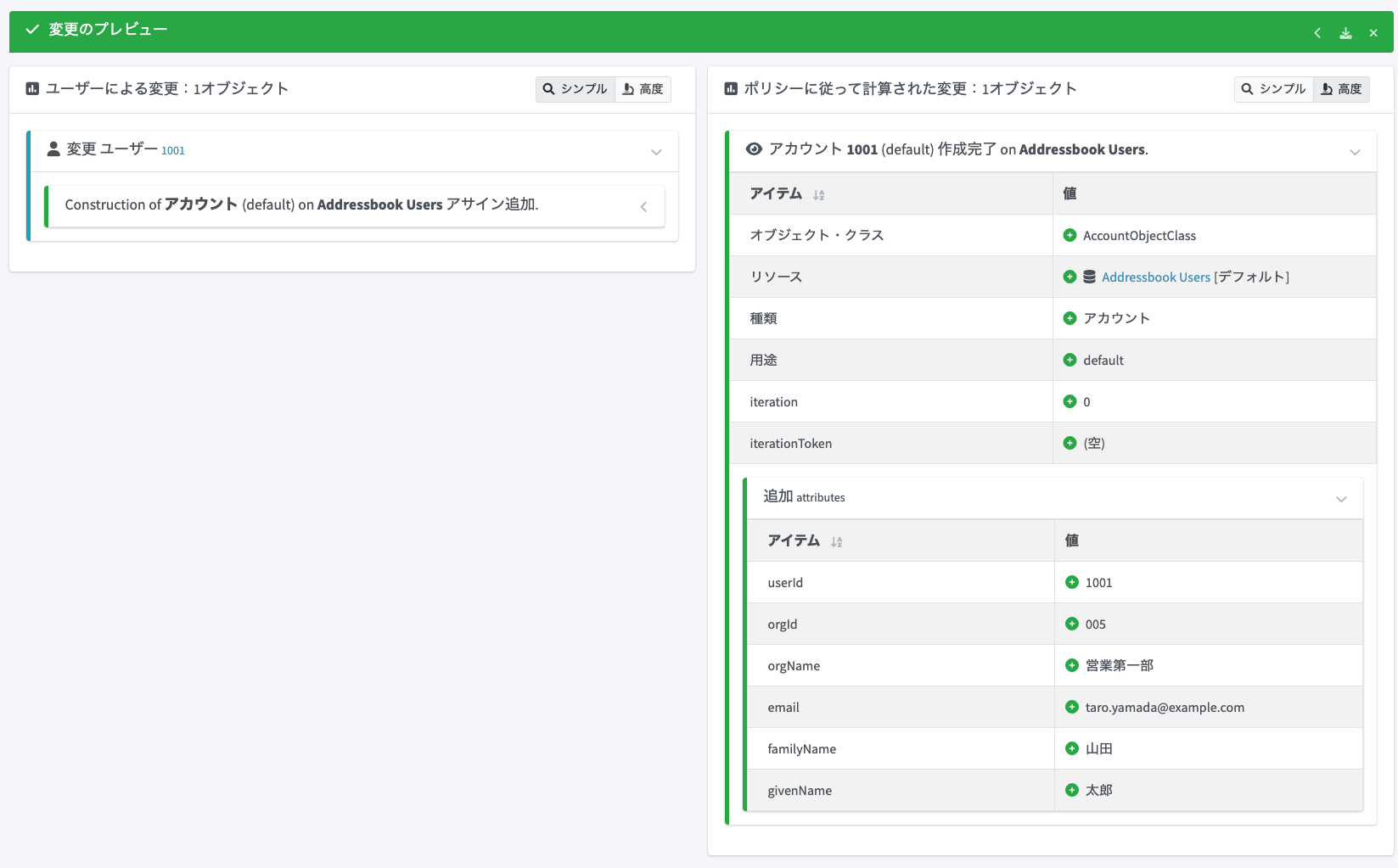
「保存」をクリックしてエラーが発生しなければ、CSVファイルにデータが書き込まれているはずです。CSVファイルの内容を確認しておきます。
userId,familyName,givenName,email,tel,orgId,orgName
1001,山田,太郎,taro.yamada@example.com,,005,営業第一部
また、ユーザーの詳細画面よりプロジェクションの状態も確認しておきます。「Addressbook Users」のプロジェクションが追加されていることが分かります。
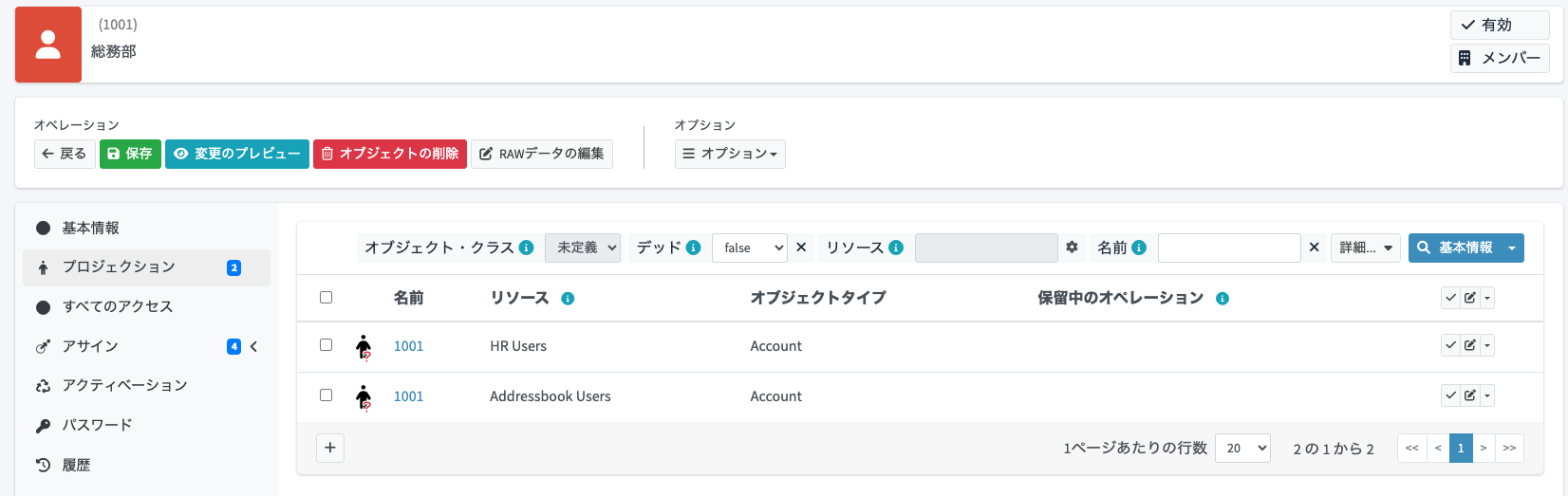
プロジェクションの詳細を開くと、連携したCSVレコードの内容を確認することができます。
ユーザーデータ更新時のリアルタイププロビジョニング
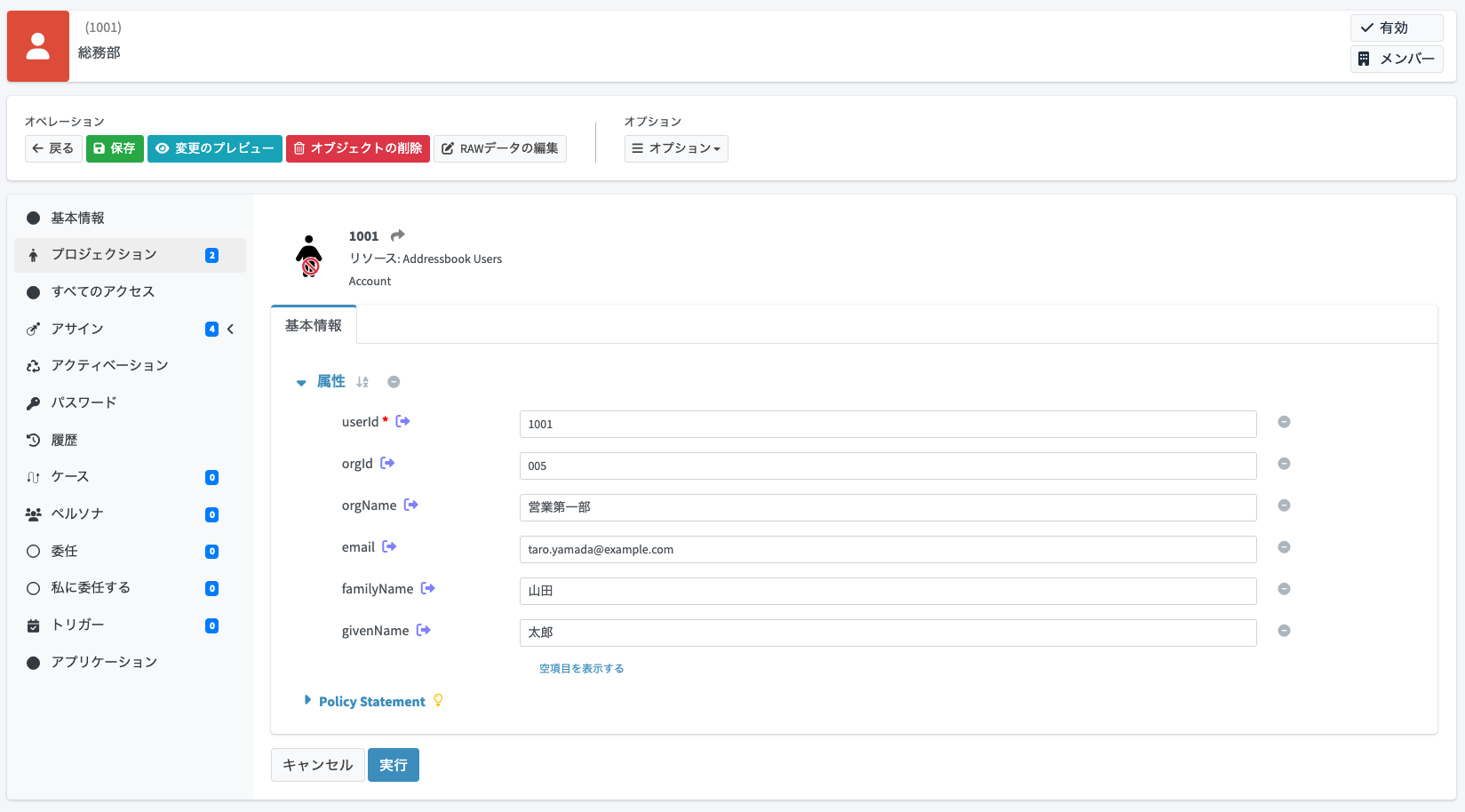
出力されたCSVには、電話番号が含まれていません。これは今回のサンプルでは、電話番号は源泉システムから提供されておらず、midPointのユーザーオブジェクトでは空のままのためです。それでは、画面からこのユーザーの電話番号を設定した場合の挙動を確認してみましょう。
ユーザーの詳細画面を開き、「空項目を表示する」をクリックします。そうすると、現在は空が設定されているその他の属性が表示されます。「電話番号」に090-0123-4567と入力し、「変更のプレビュー」をクリックします。

変更内容の詳細を展開すると、ユーザーに対する電話番号の追加に伴い、リアルタイムに「Addressbook Users」リソースに対しても電話番号を設定しようとしていることが分かります。「保存」ボタンをクリックします。
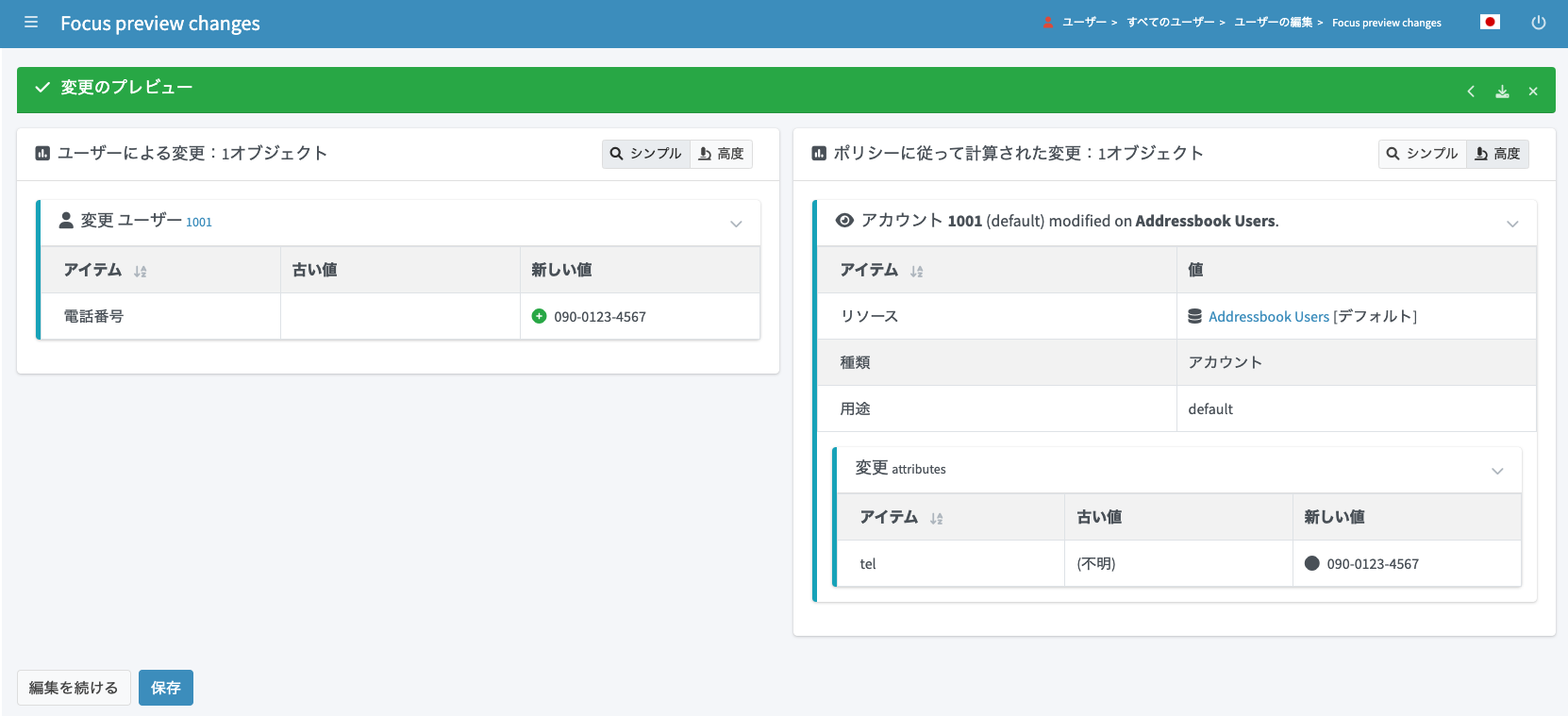
CSVファイルを確認すると、電話番号が設定されていることが分かります。
userId,familyName,givenName,email,tel,orgId,orgName
1001,山田,太郎,taro.yamada@example.com,090-0123-4567,005,営業第一部
midPointの基本思想として、midPointのオブジェクトと連携先がリンク状態にある場合、何らかの変更がmidPointのオブジェクトに対して行われると、アウトバウンドマッピングが評価されリアルタイムにプロビジョニングが行われます。この事は、The Bookの「Synchronization and Provisioning」でmidPointの特徴として語られており、他のIDMプロダクトのように追加のプロビジョニング用タスクを必要としない点をアピールされています。
リソースアサイン解除によるデプロビジョニング
プロビジョニングだけでなく、CSVからのユーザーの削除(デプロビジョニング)の動作も確認しておきます。
ユーザーの詳細画面を開き、「アサイン > リソース」メニューを開きます。登録されている「Addressbook Users」リソースの行の をクリックします。
をクリックします。
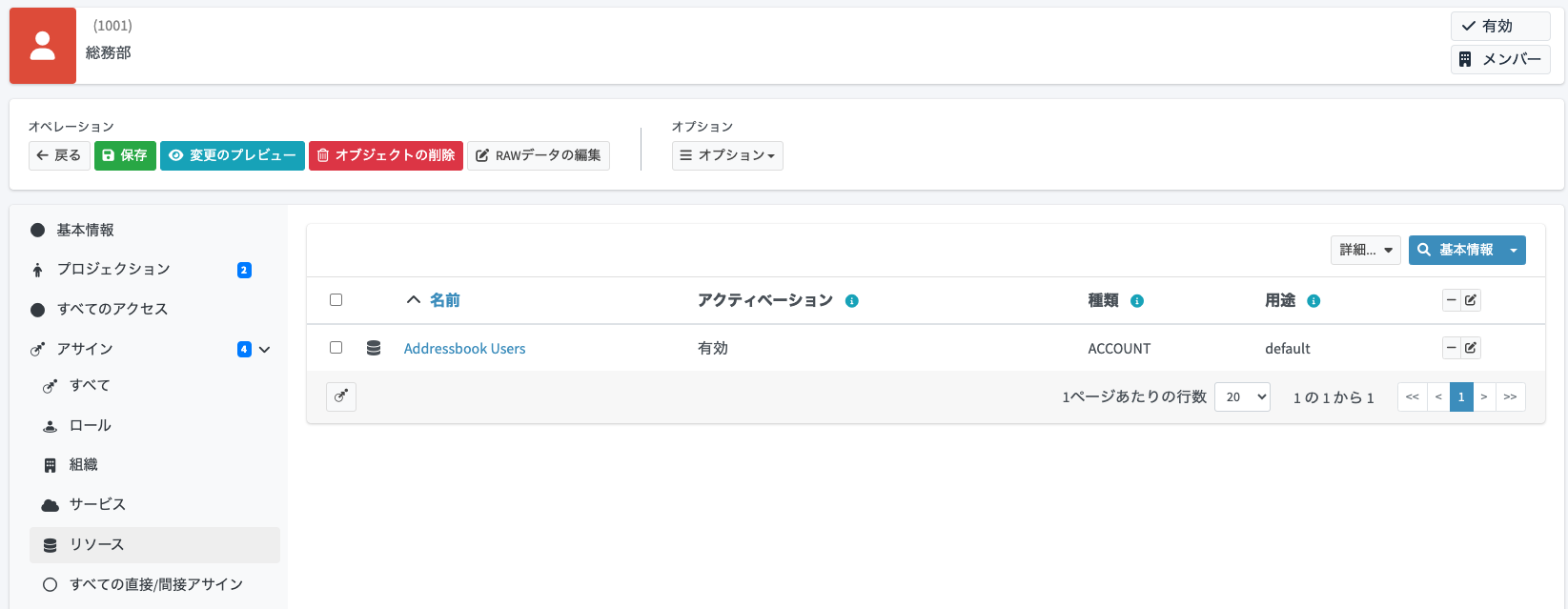
すると、削除予定を示す色に変わります(まだ保存されていません)。
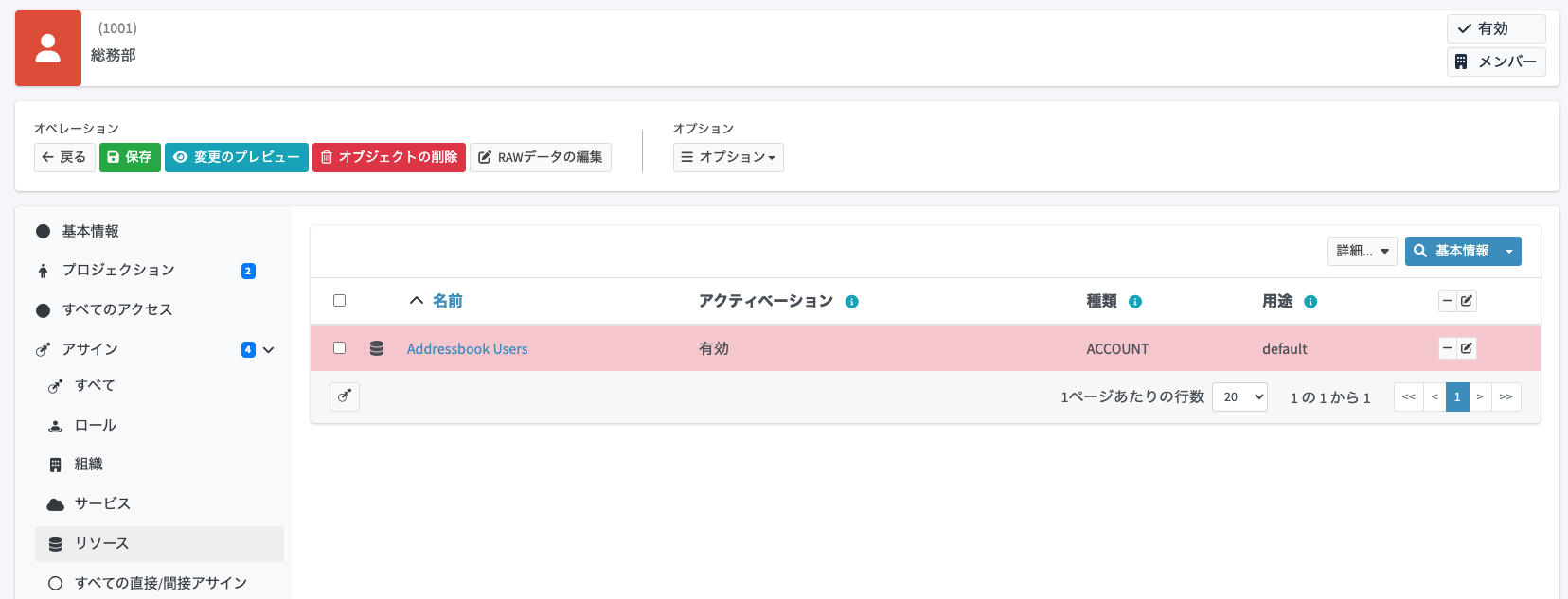
追加時と同様に、まずは「変更のプレビュー」をクリックして変更内容を確認してみましょう。リソースアサインの解除に伴い、「Addressbook Users」リソース上の「アカウント 1001」が削除予定である旨を確認できます。
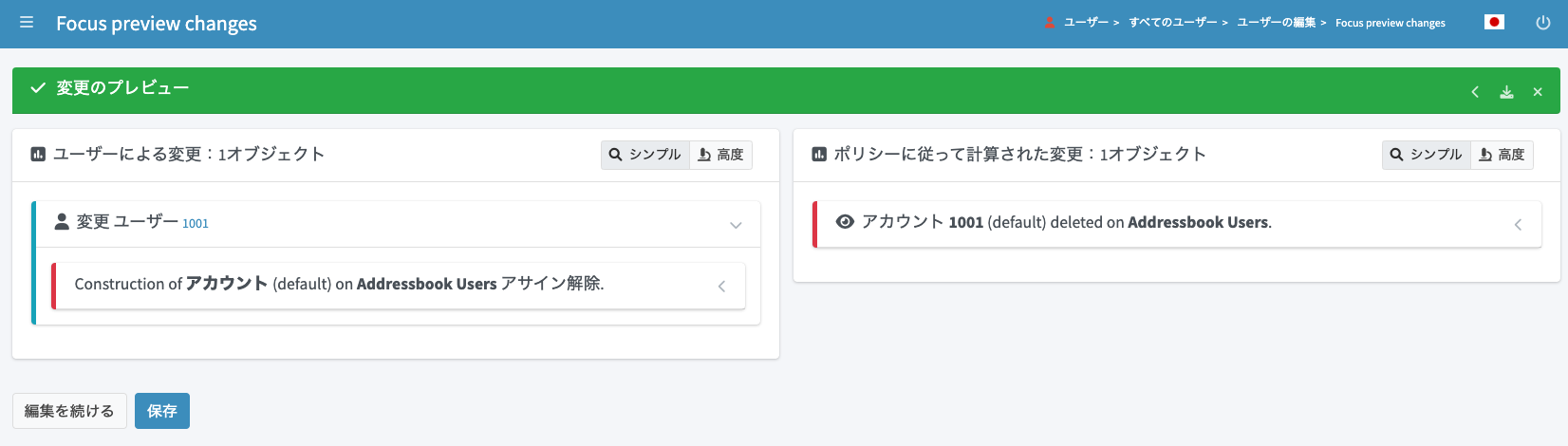
「保存」をクリックすると、アサインが解除されCSVからもデータが削除されます。
userId,familyName,givenName,email,tel,orgId,orgName
プロビジョニング時の名寄せ
リコンシリエーションタスクの実行時ではなく、プロビジョニング時にも名寄せが行われるケースがあります。midPointは設定したアウトバウンドに従って連携先へのプロビジョニングデータを用意して、作成を試みます。ここで成功すれば名寄せは必要ありません。しかし、すでに同名のデータが存在することを示すエラーがリソース(コネクター)側から返された場合2に、midPointはDiscoveryというタイプの同期処理を開始します。このDiscovery処理では、Correlation設定に従って名寄せ処理を行います。このそして名寄せでmidPoint内に該当のデータが1件見つかった場合は自動的にリンクを作成3し、今度は更新処理を行います。
実際にこの動きも確認してみましょう。今、ユーザー1001にはリソースがアサインされていない状態であり、AddressbookのCSV側にも存在しません。CSVファイルを開き、以下のように1001のデータを追加しておきます。この時、更新を確認できるようにmidPoint側で持っているのと別の属性(例:メールアドレスをyamada@example.org)にしておきます。
userId,familyName,givenName,email,tel,orgId,orgName
1001,山田,太郎,yamada@example.org,111,005,営業第一部
これでmidPoint側のユーザー1001に対して、再度「Addressbook Users」リソースをアサインします。すると処理は正常終了し、CSVが更新されたことを確認できます。もし名寄せの設定を行ってない場合は、コンフリクトのエラーが発生し、CSVは更新されません。
userId,familyName,givenName,email,tel,orgId,orgName
1001,山田,太郎,taro.yamada@example.com,111,005,営業第一部
監査ログを確認すると、リソースのアサイン追加に伴いプロビジョニングを試みたがエラーとなり、その後名寄せを行いCSVの更新を行ったことが分かります。
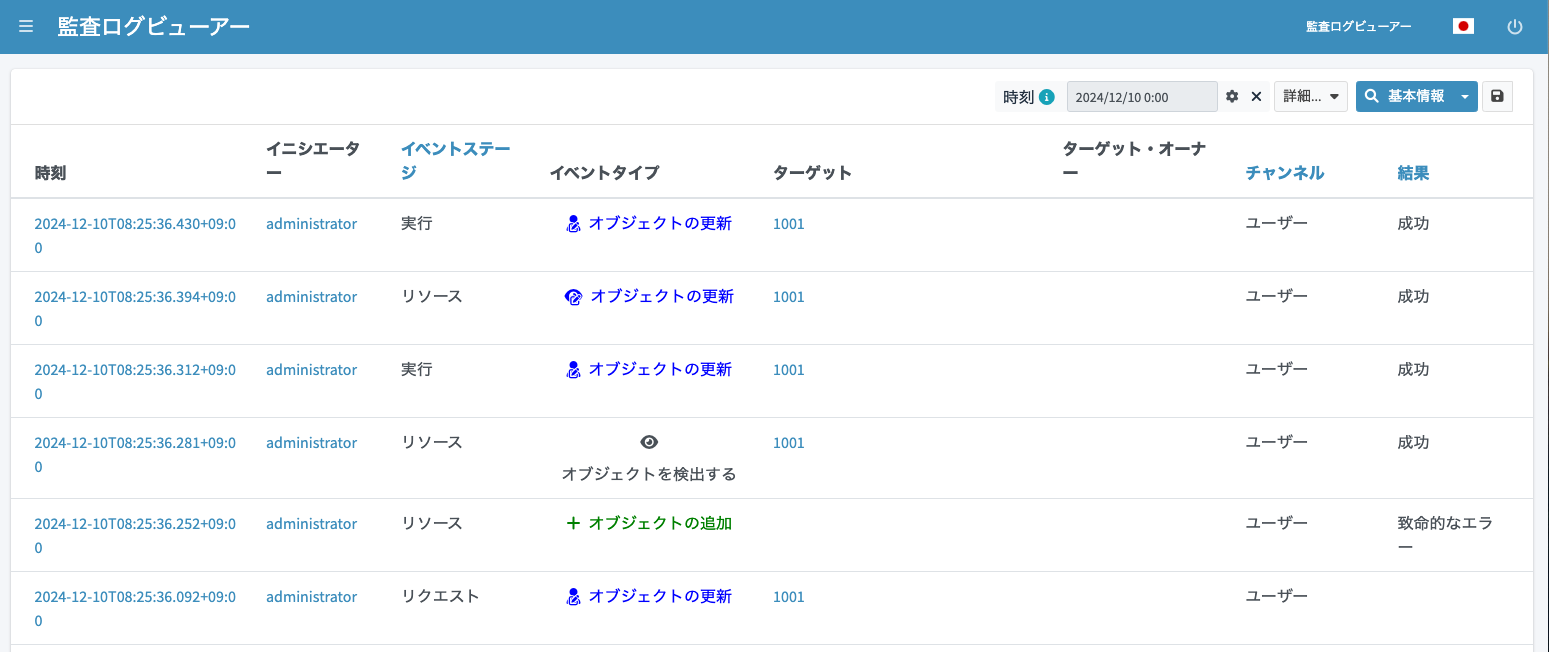
このようにCorrelationの設定を行っておくことで、プロビジョニング時に既に同名のデータが連携先にある状況でもうまくリカバリして更新を行うことができます。
既に同名のデータが連携先に存在するケースとしては、既存システムをmidPointの連携先として新たに繋ぐ場合が多いかと思います。ここで紹介したDiscoveryの処理を検知して名寄せによりリンクを作成する方法もありますが、マイグレーション用に一度リソースを設定しつつ、リコンシリエーションタスクを実行して名寄せを行ってリンクを作成し、その後アウトバウンドマッピングによりmidPointを正にした同期を行うという、段階的なアプローチもあります。詳しくは、1日目の記事で紹介したThe Bookの「Synchronization Example: LDAP Account Correlation」で解説されています。
まとめ
11日目では、midPointから外部システムへのプロビジョニング設定の追加について解説しました。midPointではプロビジョニングの場合も、源泉システムと同様にリソース設定を追加して実施する形になっていることをご理解頂けたかと思います。記事内ではユーザー情報のプロビジョニングを行いましたが、同様のリソース設定を追加することで、組織情報を別のCSVファイルにプロビジョニングすることも簡単にできます。是非試してみてください。
また、プロビジョニングの動作確認のために、今回はリソースのアサインという方法で解説しました。ただし、この方法は限定的な使い方であり、実際にはロールやアーキタイプ経由で間接的にリソースをアサインするように設計することが多いです。次回は、そのロール経由でアサインする方法(いわゆるロールベースプロビジョニング)を紹介したいと思います。お楽しみに!
-
例えば、連携先システム側で値の変更が行われた場合に、リコンシリエーションタスクの実行でmidPointのデータ内容で正すことができるようになります。なお、アウトバウンドマッピングの項目単位の詳細設定で、強さ(strength) に
strongを設定しておく必要があります。GUIからマッピングを設定した場合はデフォルトでstrongが設定されています。 ↩ -
より詳細に言うと、コネクターから
org.identityconnectors.framework.common.exceptions.AlreadyExistsExceptionという例外がスローされた場合です。 ↩ -
このリンクの作成は、同期の設定を行わなくても実施されます。同期の設定はタスクの実行時に利用されます。 ↩