はじめに
midPoint by OpenStandia Advent Calendar 2024 の5日目は、4日目で構築した開発/検証環境の上でmidPointの設定を行い、ユーザー情報を含むCSV形式の源泉データをmidPointにインポートします。
4日目で構築したDocker Composeを利用した環境が前提となります。
源泉データの準備
サンプルの源泉データを準備します。なお、このダミーのユーザーデータはChatGPTに生成してもらいました。primaryOrgIdは主務の組織ID、secondaryOrgIdsは兼務の組織IDを表します。兼務は複数可能として、;を区切り文字としたマルチバリューとしています。
employeeNumber,givenName,familyName,email,primaryOrgId,secondaryOrgIds
1001,太郎,山田,taro.yamada@example.com,005,006;007
1002,花子,佐藤,hanako.sato@example.com,006,005;009
1003,次郎,鈴木,jiro.suzuki@example.com,007,006
1004,美咲,高橋,misaki.takahashi@example.com,008,009
1005,健一,田中,kenichi.tanaka@example.com,009,008
1006,陽菜,伊藤,hina.ito@example.com,005,
1007,翔,渡辺,sho.watanabe@example.com,006,
1008,さくら,小林,sakura.kobayashi@example.com,007,
1009,優,中村,yu.nakamura@example.com,008,005;007
1010,一郎,山本,ichiro.yamamoto@example.com,009,006
上記内容のCSVファイルを作成し、hrディレクトリを作成してその配下にusers.csvとして保存しておきます。
.
├── docker-compose.yml
├── hr
│ └── users.csv
└── post-initial-objects
└── 000-system-configuration.xml
docker-compose.ymlの修正
下記修正を行い、hrディレクトリをmidPointコンテナにマウントさせておきます。これでmidPointからは、/var/lib/hr/users.csvでCSVファイルにアクセス可能になります。
midpoint_server:
image: evolveum/midpoint:${MP_VER:-latest}-alpine
container_name: midpoint_server
hostname: midpoint-container
depends_on:
data_init:
condition: service_completed_successfully
midpoint_data:
condition: service_started
command: [ "/opt/midpoint/bin/midpoint.sh", "container" ]
ports:
- 8080:8080
environment:
- MP_SET_midpoint_repository_jdbcUsername=midpoint
- MP_SET_midpoint_repository_jdbcPassword=db.secret.pw.007
- MP_SET_midpoint_repository_jdbcUrl=jdbc:postgresql://midpoint_data:5432/midpoint
- MP_SET_midpoint_repository_database=postgresql
- MP_SET_midpoint_administrator_initialPassword=Test5ecr3t
- MP_UNSET_midpoint_repository_hibernateHbm2ddl=1
- MP_NO_ENV_COMPAT=1
- MP_ENTRY_POINT=/opt/entry-point
- TZ=Asia/Tokyo
networks:
- net
volumes:
- midpoint_home:/opt/midpoint/var
- ./post-initial-objects:/opt/entry-point/post-initial-objects:ro
+ - ./hr:/var/lib/hr
midPointの起動
docker compose up -dで環境を起動します。
リソース設定の追加
ここからmidPointの画面を操作して、CSVをインポートするためのリソース設定を追加していきます。例によってシステム管理者(administrator)でmidPointにログインし、設定作業を行います。
実は2022年10月にリリースされたmidPoint 4.6より、リソース設定のウィザード画面が刷新されました。今回はこの新しいウィザード画面を使い、XMLを直接編集せずに設定してみます。
1日目の記事で紹介した、
Methodology: First Steps With MidPointという新しい学習コンテンツでは、midPoint 4.8よりGUIウィザードを使用してセットアップする方法で最初は学ぶことを推奨しています。このアプローチの利点として、midPointのXML仕様について学習することなく始められるという点が挙げられています。
Methodology: First Steps With MidPoint より引用
Before midPoint 4.8, we recommended our users and customers to review our samples and base their midPoint configuration on them. These samples represented a sample final configuration. They were written in midPoint XML language and any customization required our users to understand the midPoint language.
Since midPoint 4.8, the recommended way of starting with midPoint is using GUI wizards and following this methodology. The advantage of this approach is obvious: administrators can configure midPoint features and try them without learning another language such as midPoint XML object language. One significant burden is removed. New features such as Simulations can be used right from the beginning. Exceptions using Object Marks can be defined directly in GUI. This all helps to achieve a safe environment to try midPoint and avoid any unexpected modifications or even deletes in the target systems.
But there is also a small disadvantage: when using interactive wizards such as resource wizard, it’s hard to prepare complete examples for learning purposes. Having a ready-to-use example in final state or even for each step of the interactive process would not be efficient and would beat the purposes of the interaction entirely.
As the initial state for this methodology is basically an empty midPoint, we have decided to document the methodology by following the interactive wizards. Therefore, be prepared that connecting and configuring a new system is an iterative and interactive process. If you get lost, do not hesitate to watch the video mentioned in the Introduction chapter.
出所:https://docs.evolveum.com/midpoint/methodology/first-steps/#how-to-use-this-methodology
リソースの作成
画面左のメニューより「リソース > 新規リソース」をクリックします。

新規リソース作成の画面が表示されるので、「スクラッチ」を選択します。
今回は使用しませんが、事前にテンプレートを作成しておいて、それをベースに作成する方法も用意されています。
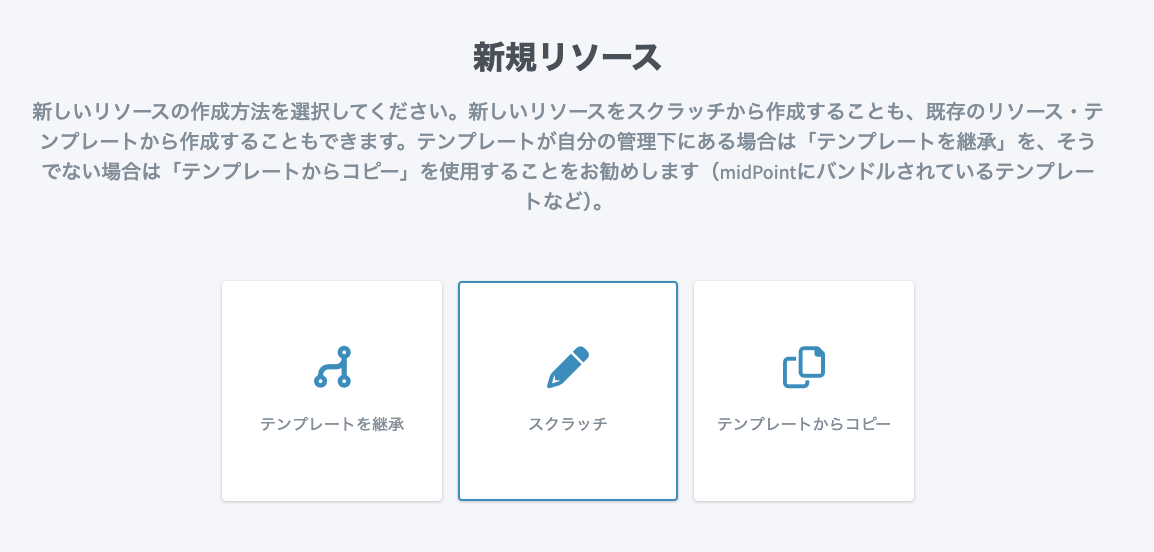
リソースカタログの一覧が表示されます。今回はCSVファイルからインポートを行うため、「CsvConnector」を選択します。
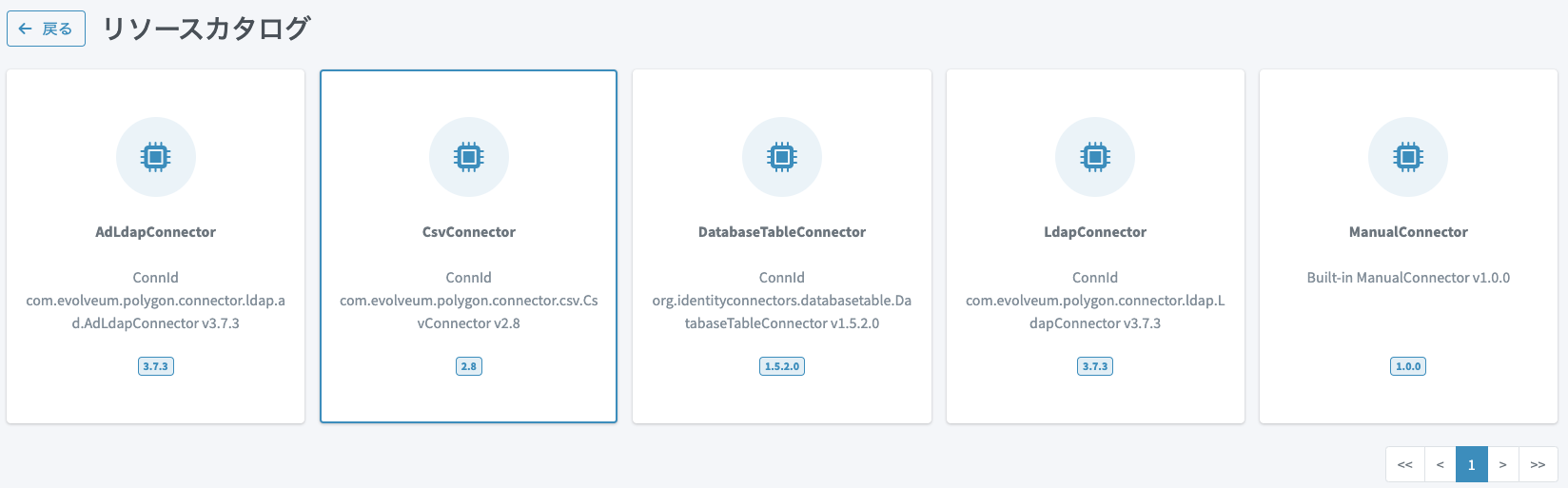
リソースの基本情報の入力画面が表示されるので、以下のように設定して「次へ:設定」ボタンをクリックします。
-
名前:
HR Users -
ライフサイクル状態:
Active (production)
「ライフサイクル状態」はデフォルトではProposed (simulation)となっています。この状態にすると、midPoint 4.7で追加されたシミュレーション機能を使用して、変更を行うことなく事前に安全に動作を確認することができます。シミュレーション機能については、また別の日に紹介する予定ですので、本記事ではActive(production)として設定します。
次の画面では、CSVファイルのパスを設定します。以下のように設定し、「次へ:ディスカバリー」ボタンをクリックします。
-
File path:
/var/lib/hr/users.csv

次の画面では、CSVコネクターの詳細設定を行います。以下のように設定します。
CSVコネクターはディスカバリーと呼ばれるAPIを実装しているため、実際のCSVファイルを読み込んで設定値をサジェストしてくれます。キーボードで入力する必要はなく、マウスで値を選択するだけで済みます。
-
Multivalue delimiter:
; -
Field delimiter:
, - User password attribute name:(空のまま)
-
Name attribute:
employeeNumber -
Unique attribute name:
employeeNumber -
Multivalue attributes:
secondaryOrgIds1

「Multivalue attributes」 はデフォルトでは非表示です。「空項目を表示する」ボタンをクリックすると、非表示となっているその他の設定項目を表示することができます。その中にある 「Multivalue attributes」 にsecondaryOrgIdsを設定します。その後、「次へ:スキーマ」ボタンをクリックします。

次の画面では、コネクターがサポートするオブジェクトタイプの一覧が表示されます。その中で使用するものを選択します。デフォルトで「AccountObjectClass」が選択済みのため、そのまま「リソースの作成」ボタンをクリックします。

リソースの作成が一旦完了します。

なお、「Preview Resource Data」を選択すると、コネクターを通じてリソース内のデータ一覧を参照することができます。

次は、「オブジェクト・タイプの設定」を選択して、CSVのデータをmidPoint内のどのオブジェクトにマッピングしてインポートするか設定していきます。
オブジェクト・タイプの追加
もし、「ウィザードを終了」ボタンをクリックするなどで画面を閉じてしまった場合は、作成済みのリソースの詳細画面を開き、「スキーマ処理」メニューを開いて「オブジェクトタイプの追加」ボタンをクリックすると、オブジェクト・タイプの設定ウィザードをまた開始できます。

基本情報の画面では以下を設定し、「次へ:リソース・データ」ボタンをクリックします。
-
表示名:
Account -
種類:
アカウント

次のリソース・データの画面では、特に設定は不要です。「次へ:MidPointデータ」をクリックして先に進みます。

MidPointデータの画面では以下を設定し、「設定を保存」をクリックします。今回はmidPointのユーザーオブジェクトとして取り込みたいので、「ユーザー」を設定します。
アーキタイプは重要な機能なのですが、本記事ではまだ使用しません。別の記事で紹介したいと思います。
-
タイプ:
ユーザー

オブジェクトタイプを保存すると、追加したオブジェクトタイプに関するウィザード画面が表示されますので、次は「マッピング」を選択します。
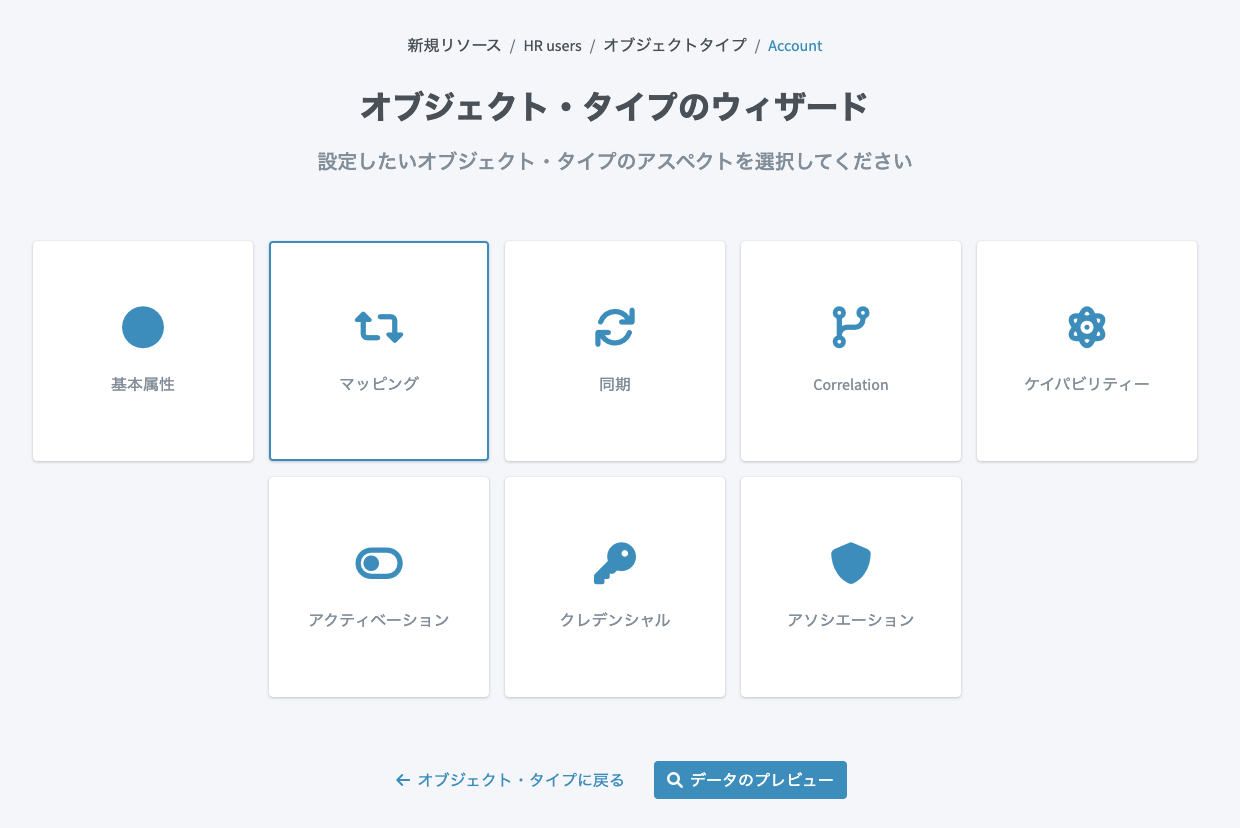
マッピングの設定
もし、画面を閉じてしまった場合は、作成済みのリソースの詳細画面を開き、「スキーマ処理」メニューを開いて、先程追加した「Account」オブジェクトタイプの表示名部分をクリックすると、オブジェクト・タイプのウィザード画面にまたアクセスできます。
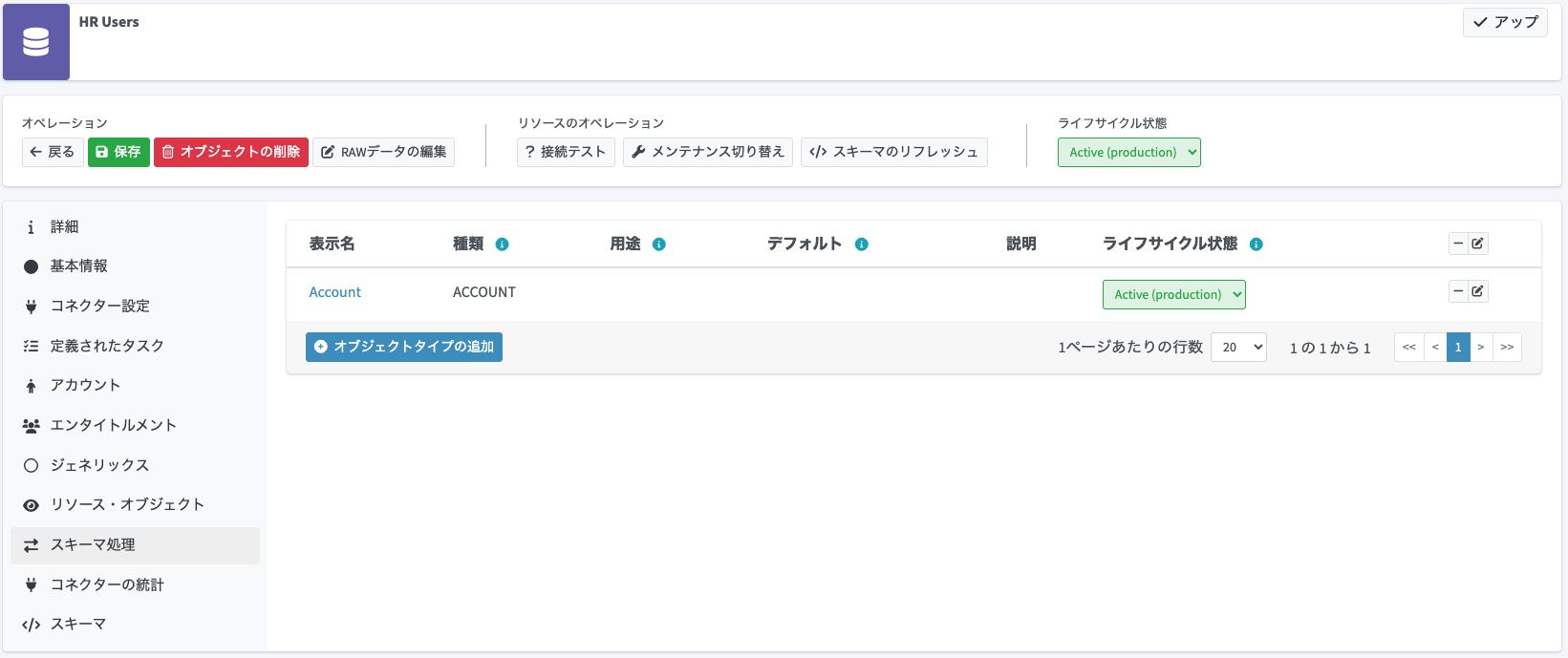
今回はCSVファイルを源泉データとして取り込み、midPoint内にユーザーを作成したいので、インバウンドマッピングを設定します(別の記事で解説予定ですが、midPoint内のデータを外部のリソースにプロビジョニングしたい場合は、アウトバウントマッピングを使用します)。
「インバウンドマッピング」タブが選択されていることを確認し、「インバウンドの追加」ボタンをクリックします。
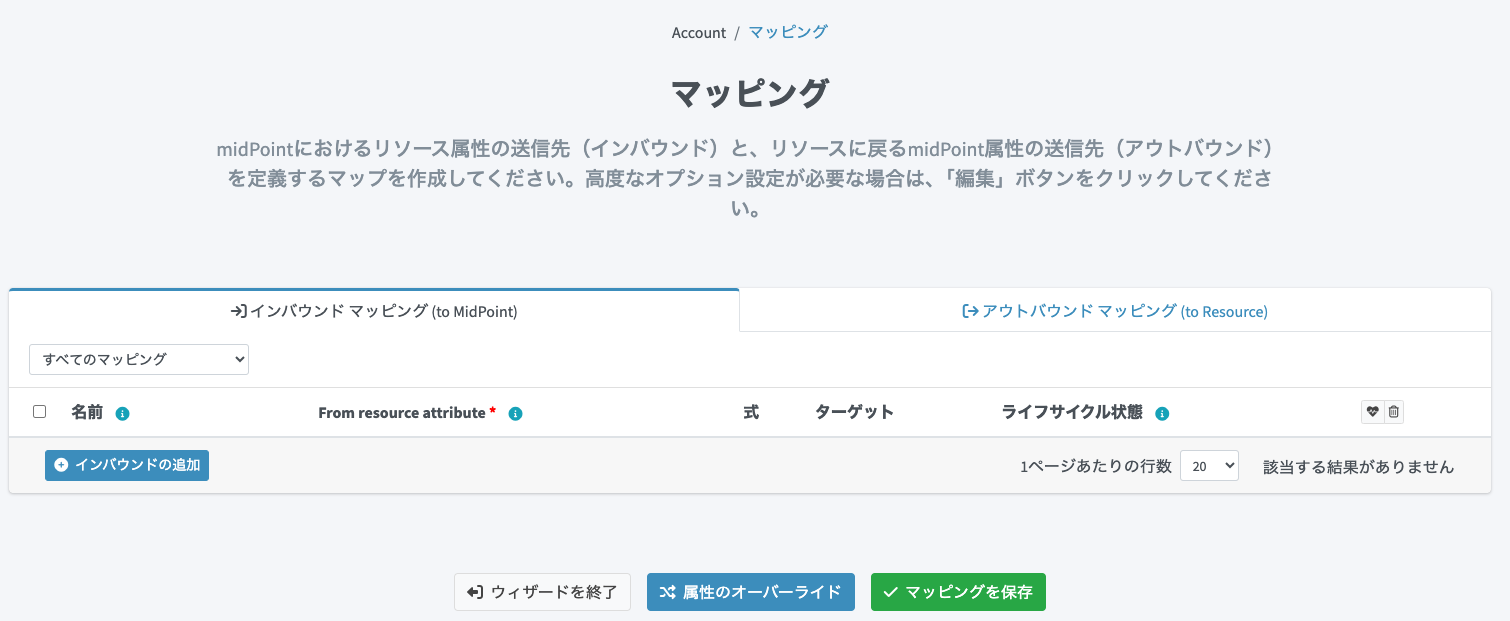
そうすると編集行が追加されます(緑色の箇所)。

入力フィールドではサジェスト機能が働くため、マウスで選択や、先頭文字を少し入力すると絞込んで表示してくれます。
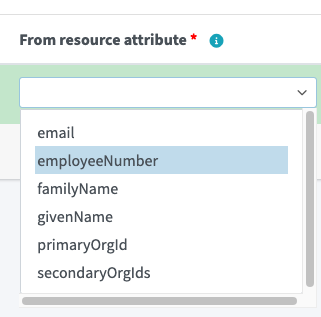
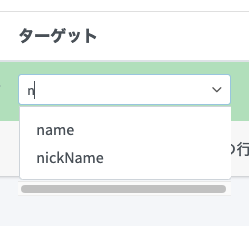
以下のように設定します。なお、名前(このマッピングの名前)は必須ではありません。デバッグ用途で使われます。From resource attribute はソース側(取り込み元)であるCSVの属性を指定します。ターゲット にはターゲット側(取り込み先)であるmidPointのユーザー属性を指定します。
-
From resource attribute:
employeeNumber -
式:
現状2 -
ターゲット:
name

続けて「インバウンドの追加」ボタンをクリックし、編集行を追加して他の属性のマッピングも設定します。これを取り込みたい属性の数分繰り返します。マッピング内容は下表を参考に設定してください。
| From Resource Attribute | 式 | ターゲット |
|---|---|---|
| employeeNumber | 現状 | name |
| 現状 | emailAddress | |
| familyName | 現状 | familyName |
| givenName | 現状 | givenName |
| primaryOrgId | 現状 | organization |
| secondaryOrgId | 現状 | organizationalUnit |
最終的には以下のようなインバウンドマッピングが設定された状態となります。

「マッピングを保存」をクリックして保存します。

またウィザード画面に戻るため、次は「同期」を選択します。
同期の設定
インバウンドマッピングを設定しただけでは、midPointはまだデータの取り込み(同期)をしてくれません。細かい同期のルールを設定する必要があります。この同期のルール設定では、midPointがリソースとの間で検知した状況(Situation)に応じて、どのようなアクションを取るかを設定していきます。
「Add reaction」ボタンをクリックします。

そうすると編集行が追加されます(緑色の箇所)。

以下を設定します。Unmatchedという状況は、CSV内のユーザーに対応するデータがmidPoint内にまだ存在しない状況を意味します。この時、実現したいこととしては「midPointにユーザーを作成する」ですので、フォーカスの追加を選択します。
フォーカス(Focus)はmidPoint用語の1つです。midPointでは管理の中心となるmidPointのオブジェクト(ユーザー、ロール、組織、サービス)のことを、まとめてフォーカスと呼んでいます。
-
状況:
Unmatched -
アクション:
フォーカスの追加

続けて「Add reaction」ボタンをクリックして編集行を追加し、他のルールも追加します。ここでは例として、一般的な設定を行います。下表を参考に設定してください。
| 状況 | アクション | 設定意図 |
|---|---|---|
| Unmatched | フォーカスの追加 | midPoint内にまだ存在しない場合にユーザーを作成する |
| Linked | 同期 | すでにインポート済みのユーザーに対してはCSV内容で属性を更新する |
| Deleted | フォーカスの削除 | CSVから削除された場合はmidPointのユーザーも削除する |
| Unlinked | 紐づけ | 既存のmidPointユーザー(画面から登録したユーザーや別の源泉から登録されたユーザーなど)と名寄せで一致する場合は紐づけ(そのShadowオブジェクトのオーナーをmidPointユーザーに設定)を行う |
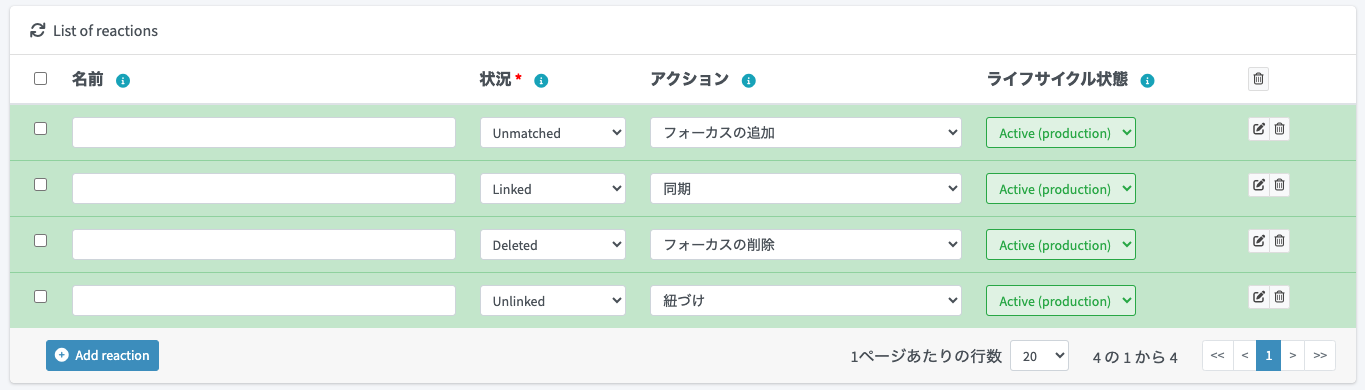
「Synchronization設定を保存」ボタンをクリックして保存します。

またウィザード画面に戻るため、次は「Correlation」を選択します。

Correlationの設定
Correlationはいわゆる 名寄せ の設定です。先程の同期の設定で、状況が「Unlinked」の際にアクションを「紐づけ」と設定しました。この紐づけを正しく動作させるには、Correlationの設定を行い、どういったロジックで名寄せを行うのか設定する必要があります。
「ルールの追加」ボタンをクリックします。

そうすると編集行が追加されます(緑色の箇所)。

「ルール名」に区別が付くようにnameと入れておきます。 アイコンをクリックして編集画面を開きます。
アイコンをクリックして編集画面を開きます。

「Add correlator」ボタンをクリックします。

そうすると編集行が追加されます(緑色の箇所)。

「アイテム」に選択可能なアイテムは、インバウンドマッピングで設定したターゲットとなるmidPointのユーザーの属性になります。インバウンドマッピングの設定では、マッピング元となるリソース側(CSVファイル側)の属性を設定しており、employeeNumberを指定していました。このインバウンドマッピングの情報を利用して名寄せのルールを設定します。
今回は、CSVファイルのemployeeNumberカラムの値を使用してmidPointのユーザーをname属性で検索し、完全一致するユーザーに対して名寄せを行う、シンプルなルールを設定します。以下のように設定します。
-
アイテム:
name -
Search method:
完全一致(デフォルトのまま)

この設定により、nameに対するインバウンドマッピングの設定を参照して、CSVファイルのemployeeNumberカラムを名寄せに使用します。
「設定を確認」ボタンをクリックして元の画面に戻ります。

ルールの一覧画面に戻ります。「Correlation設定を保存」ボタンをクリックして保存します。

ユーザーのインポート
リソースの作成が完了しましたので、いよいよユーザーをインポートします。リソースの詳細画面から、手動で対象アカウントを選択してインポートすることもできますが3、今回はインポートタスクを作成して一括取り込みを行います。
インポータタスクの作成
インポート処理を実行するタスクを作成します。いくつかやり方はありますが、今回は作成したリソースの編集画面の「アカウント」メニューから作成します。
画面左メニューの「リソース > すべてのリソース」をクリックしてリソースの一覧を表示します。先ほどのウィザードで作成したリソースが表示されます。

リソースの編集画面を開き、「アカウント」メニューをクリックしてアカウント一覧を表示します。

リソースの作成ウィザードで「Preview Resource Data」を選択してリソースオブジェクトの一覧を参照していた場合は、そのタイミングでShadowオブジェクトが作成されるため、この画面でもアカウント一覧が表示されます。

画面上部にある「タスク」メニューを開き、「タスク作成」をクリックします。

タスクの作成画面が開きます。今回はインポートタスクという種類のタスクを作成したいので、「Import Task」を選択します。これで「タスク作成」ボタンをクリックします。
今回はシミュレーション機能は利用しませんので、「Simulate task」は「OFF」のままとします。

基本設定画面が表示されるので、以下を設定して「次へ:リソース・オブジェクト」ボタンをクリックします。
-
名前:
HR import users

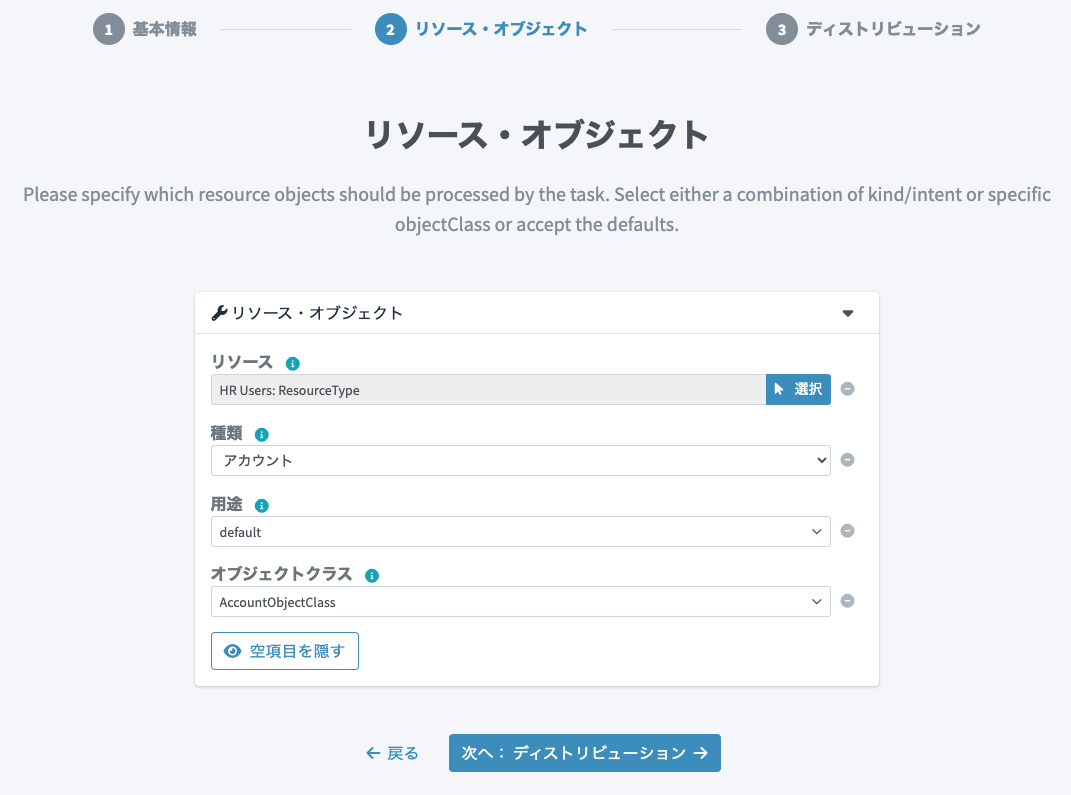
リソース・オブジェクトの設定画面が表示されるので、以下を追加設定して「次へ:ディストリビューション」ボタンをクリックします。
-
オブジェクトクラス:
AccountObjectClass
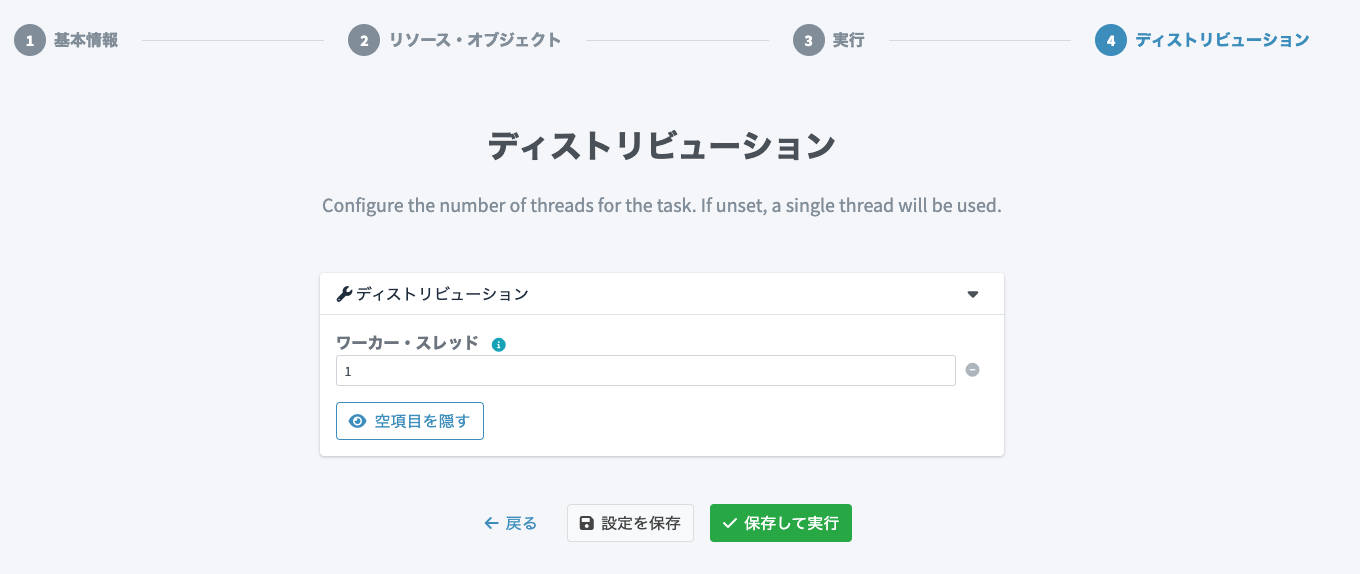
ディストリビューションの設定画面が表示されます。このタスクの同時実行スレッド数4を設定します。以下を設定して「設定を保存」をクリックします。
「保存して実行」をクリックすると、インポートタスクが即座に開始されますので注意してください。
-
ワーカー・スレッド:
1
リソースの編集画面に戻ってきます。「タスク」メニューを開き、「View import tasks」をクリックします。

インポートタスクの一覧画面に遷移します。作成したインポートタスクが登録されていることが分かります。次はこのタスクを実行してユーザー取り込みをいよいよ行います。
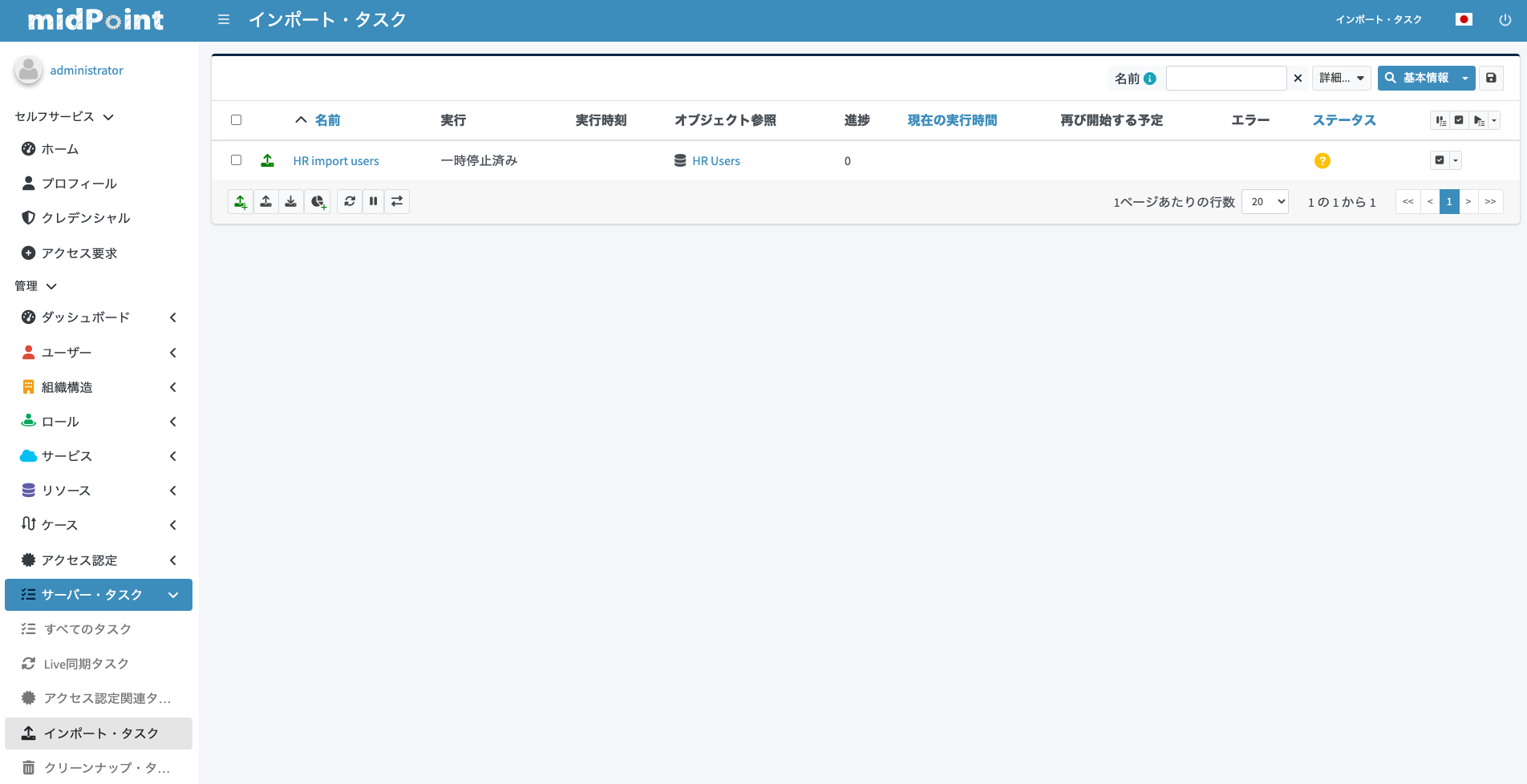
インポートタスクの実行
作成したインポートタスクの詳細画面を開きます。現在はまだ未実行の状態であり「一時停止済み」という状態になっています。「再開する」ボタンをクリックするとタスクが開始されます。

少し待つと、画面がリフレッシュされてタスクの実行結果が更新されます。以下のように「終了」状態となればタスクは実行完了しています。ここまで設定が正しく行われていれば、「成功」で完了しているはずです。

「オペレーション統計」メニューを開くと、もう少し詳細な実行結果を参照することができます。このタスクにより、10件処理されすべて成功したことが分かります。

画面左メニューより「ユーザー > すべてのユーザー」を開いて、ユーザーの一覧を確認してみましょう。無事にユーザーが取り込まれていることを確認できます。
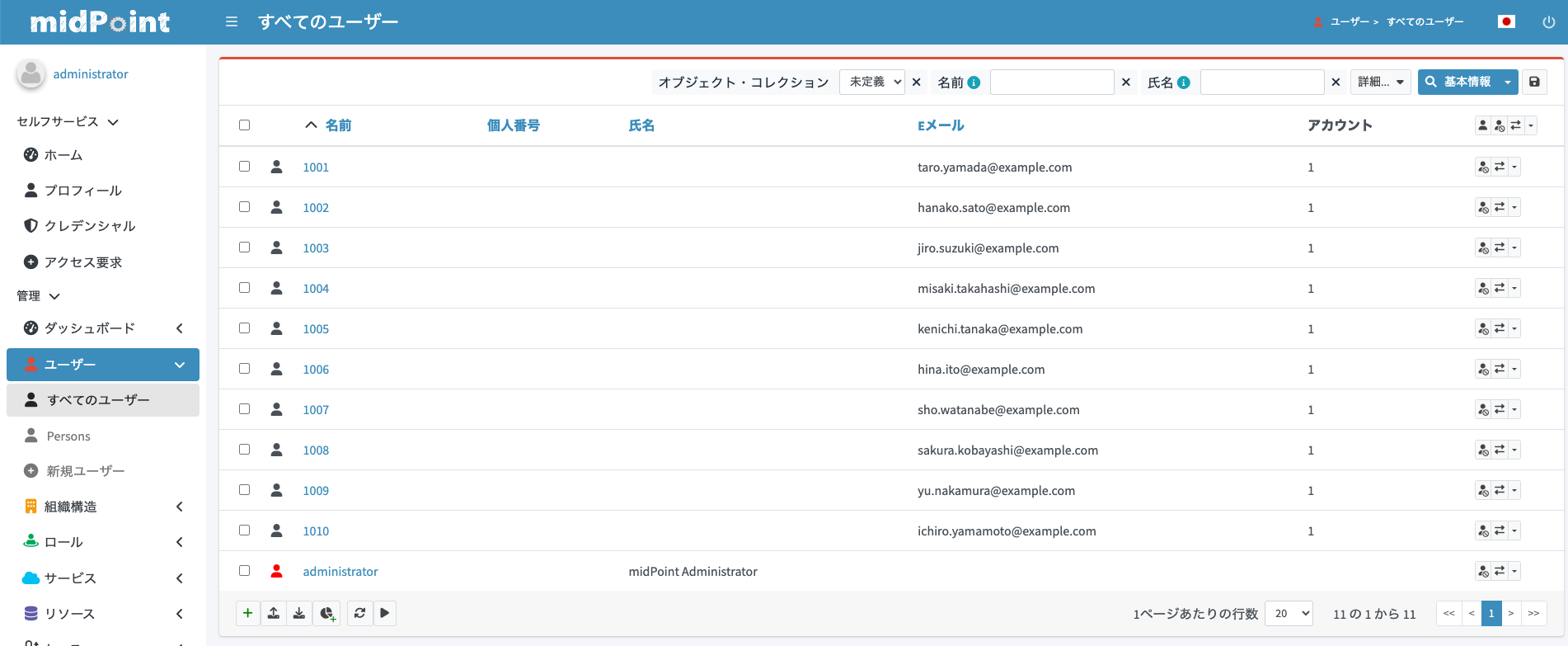
ユーザーの詳細画面をみると、各属性に想定通りマッピングされていることが分かります。

CSVファイルを変更して再インポート
CSVファイルの内容を編集して行を増減させたり、値を変更して再度インポートタスクを実行した際の挙動を確認しておきます。
行の追加
CSVファイルに以下の行を追加します。
1011,菜々子,石井,nanako.ishii@example.com,007,005;009
インポートタスクの詳細画面より、「今すぐ実行」ボタンをクリックして再度実行します。

midPointのユーザー一覧を再度確認すると、追加されていることが分かります。

行の削除
ちょうど先ほど追加した行(1011の行)をCSVファイルから削除して、同様にインポートタスクを再実行します。
すると、先程取り込んだ1011のユーザーは残ったままです。

これは、インポートタスクでは、同期の設定で追加した「状況(Situation)が Deleted」の状態を検知できない仕様 のためです。もし、源泉データから物理削除された状態を元に反映したい場合は、「Reconciliation Task(リコンシリエーションタスク)」か「Live Synchronization Task(Live同期タスク)」のどちらかを使用する必要があります。
「Reconciliation Task(リコンシリエーションタスク)」と「Live Synchronization Task(Live同期タスク)」による源泉データの削除同期については、また別の記事で紹介したいと思います。ひとまず現時点では、インポートタスクだとデータの物理削除をmidPointに反映することはできない、という点を理解していただければと思います。
値の更新(シングルバリュー項目)
以下のように、CSVファイルのメールアドレスを変更して、同様にインポートタスクを再実行します。
1001,太郎,山田,taro.yamada@example.com,005,006;007
↓
1001,太郎,山田,yamada-taro@example.org,005,006;007
midPointのユーザー一覧を再度確認すると、メールアドレスが更新されていることを確認できます。

値の更新(マルチバリュー項目)
今回のサンプルでは、midPointのユーザー属性である「組織(organization)」と「組織単位(organizationalUnit)」はマルチバリュー項目となっています。マッピング元となるCSVファイルのprimaryOrgId、secondaryOrgIds列を更新するケースを次は試します。
以下のようにCSVファイルを更新して、同様にインポートタスクを再実行します。
1001,太郎,山田,yamada-taro@example.org,005,006;007
↓
1001,太郎,山田,yamada-taro@example.org,006,007;009
そうすると、midPointユーザーは以下のように更新され、古い値が残り続けます。

これは、マッピング先のユーザー属性はマルチバリュー項目であり、midPointではマルチバリュー項目に対してはデフォルトでは安全のため古い値を消さないという戦略を取っているためです。
このあたりの話は、公式ドキュメントではRangeと呼んで説明しています。CSV側を正にして値を完全に入れ替えたい場合は、追加の設定が必要となります。ただし現状(4.8 LTSだけでなく、最新のバージョン4.9でも)では、このRange設定はGUIでサポートされておらず、XMLを編集する必要があります。この設定についてはまた別の記事で紹介したいと思います。
Post-Initial Import化
今回設定したリソースとタスクも、4日目の記事で紹介したPost-Initial Importを使うようにしておくと、一度環境を破棄しても再構築が容易になります。midPointでは「リポジトリ・オブジェクト」の画面から内部で管理されるオブジェクトをすべて参照・更新できますが、ここからエクスポートも可能です。
画面左メニューより「リポジトリ・オブジェクト > すべてのオブジェクト」を開きます。

「タイプ」を「リソース」に変更し、リソースの一覧を表示します。今回作成したリソース設定の「出力」ボタンをクリックしてエクスポートします。

同様に「タイプ」を「タスク」に変更してタスク一覧を表示し、「出力」ボタンをクリックして今回作成したインポートタスクの設定をエクスポートします。
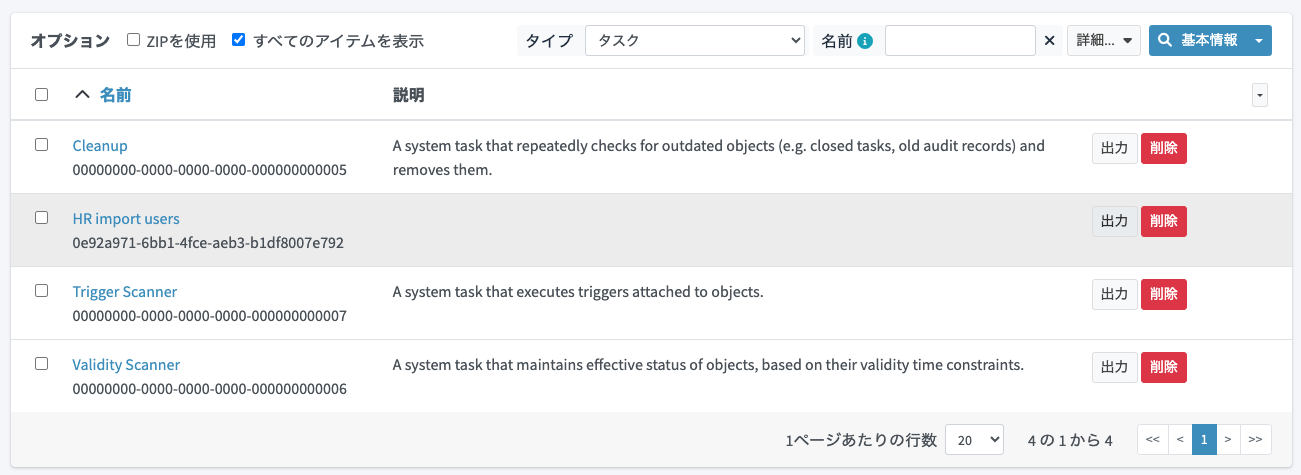
エクスポートしたファイルをそれぞれリネームして分かりやすい名前に変更し、post-initial-objectsディレクトリ配下に配置します。リソース設定は100-resource-hr-users.xml、インポートタスク設定は900-task-hr-import-users.xmlとします。
.
├── docker-compose.yml
├── hr
│ └── users.csv
└── post-initial-objects
├── 000-system-configuration.xml
├── 100-resource-hr-users.xml
└── 900-task-hr-import-users.xml
なお、Post-Initial Importではファイル名のソート順で適用されます。よって、依存関係のあるファイルは依存元より順番に適用されるように、ファイル名の先頭に番号を振って調整するとよいでしょう。今回の場合、タスク設定のXMLからリソースを参照しているため、リソースを先に適用します。
<activity>
<work>
<import>
<resourceObjects>
<resourceRef oid="26d1d987-0359-4de2-bdc8-c1bcfeb10a4b" relation="org:default" type="c:ResourceType">
<!-- HR Users -->
</resourceRef>
<kind>account</kind>
<intent>default</intent>
<objectclass>ri:AccountObjectClass</objectclass>
</resourceObjects>
</import>
</work>
<distribution>
<workerThreads>1</workerThreads>
</distribution>
</activity>
また、リソース設定では一工夫必要になります。XMLファイルを開き、 <connectorRef>タグの箇所を探して以下の様に修正します。<connectorRef oid="..."で参照しているコネクターオブジェクトは、midPoint初回起動時に自動登録されたものです。そのため、このOID(UUID形式)は新規環境構築時に毎回変わってしまいます。そこで、OIDに頼らずにコネクターオブジェクトを参照するように設定変更を加えます。<filter>タグを使うとOIDではなく論理名を使って対象オブジェクトを探し、参照関係を設定することができます。
- <connectorRef oid="e8ae015b-0a97-48ad-8323-b530c65c7763" relation="org:default" type="c:ConnectorType">
- <!-- ConnId com.evolveum.polygon.connector.csv.CsvConnector v2.8 -->
+ <connectorRef relation="org:default" type="c:ConnectorType">
+ <filter>
+ <q:equal>
+ <q:path>c:connectorType</q:path>
+ <q:value>com.evolveum.polygon.connector.csv.CsvConnector</q:value>
+ </q:equal>
+ </filter>
</connectorRef>
これでDocker Composeで新規に環境構築時に、今回作成した設定が自動適用されます。
試しにdocker compose down -vで環境破棄後、docker compose upで再構築すると、以下のようにPost-Initial Importが実行されることを確認できます。
midpoint_server | 2024-12-05 08:24:49,151 [] [main] INFO (com.evolveum.midpoint.init.PostInitialDataImport): Directory /opt/midpoint/var/post-initial-objects exists. Using it.
midpoint_server | 2024-12-05 08:24:49,161 [] [main] INFO (com.evolveum.midpoint.init.PostInitialDataImport): Starting post-initial import of file 000-system-configuration.xml.
midpoint_server | 2024-12-05 08:24:49,587 [MODEL] [main] INFO (com.evolveum.midpoint.model.impl.importer.ObjectImporter): Imported object systemConfiguration:00000000-0000-0000-0000-000000000001(SystemConfiguration)
midpoint_server | 2024-12-05 08:24:49,591 [] [main] INFO (com.evolveum.midpoint.init.PostInitialDataImport): Starting post-initial import of file 100-resource-hr-users.xml.
midpoint_server | 2024-12-05 08:24:49,917 [MODEL] [main] INFO (com.evolveum.midpoint.model.impl.importer.ObjectImporter): Imported object resource:26d1d987-0359-4de2-bdc8-c1bcfeb10a4b(HR Users)
midpoint_server | 2024-12-05 08:24:49,928 [] [main] INFO (com.evolveum.midpoint.init.PostInitialDataImport): Starting post-initial import of file 900-task-hr-import-users.xml.
midpoint_server | 2024-12-05 08:24:50,190 [MODEL] [main] INFO (com.evolveum.midpoint.model.impl.importer.ObjectImporter): Imported object task:0e92a971-6bb1-4fce-aeb3-b1df8007e792(HR import users)
midpoint_server | 2024-12-05 08:24:50,191 [] [main] INFO (com.evolveum.midpoint.init.PostInitialDataImport): Post-initial object import finished (3 objects imported, 0 scripts executed)
まとめ
5日目では、4日目に構築した開発・検証環境上で、CSV形式の源泉データをmidPointのユーザーとしてインポートするための設定を紹介しました。2019年のAdvent Calendarの記事「midPointにおける「IDライフサイクル管理」実践編(CSV/画面からの取り込み)」ではXML設定を直接編集していましたが、midPoint 4.8では基本的な設定がGUIベースでも可能になっていることがお分かりいただけたかと思います。
とはいえ、現時点では高度な設定を行うにはXMLを直接編集する必要がある場合も多いです。midPointのさらなる進化に期待したいところですが、個人的には、Gitでの設定ファイル管理との相性を考えると、最終的にはXMLでの管理の方がしっくりきています。
また、タスクの種類による挙動の違い、マルチバリュー項目に対するマッピング時のデフォルトの挙動についても取り上げました。これらについては、また別の記事で紹介したいと思います。
次回は、ユーザーデータではなく、組織データのインポートについて紹介する予定です。お楽しみに!
-
今回のダミーデータでは複数兼務を表現するため、
secondaryOrgIdsカラムはマルチバリュー項目になっています。CSVコネクターにマルチバリューであることを認識させるために、この設定が必要となります。 ↩ -
日本語翻訳がよくありませんが、英語だとAs isとなっています。意味としては、その値のままマッピングするという意味です。 ↩
-
2019年のAdvent Calendarの記事「midPointにおける「IDライフサイクル管理」実践編(CSV/画面からの取り込み)」では、リソースの詳細画面から手動でインポートする手順を紹介していました。 ↩
-
インポート対象のデータ件数が多い場合、同時実行スレッド数を増やすとCPUをより消費しますが処理速度を上げることができます。ただし、CSVレコードの順番通りに処理されることを前提とするケースでは注意が必要です。マルチスレッドモードでは処理の順番は保証されません。 ↩