midPoint by OpenStandia Advent Calendar 2024 の22日目は、これまで構築してきた開発/検証環境の上で、今度はSaaSアプリケーションと連携させてみます。例として、クラウド型の人事アプリケーションであるSmartHRを源泉システムとして利用する例を紹介します。
4日目の記事で構築した開発/検証環境が必要となります。
標準コネクターと追加のコネクター
midPointでは標準で下記5つのコネクターが組み込まれています。ManualConnectorはマニュアルオペレーションとの組み合わせを必要とする特殊なコネクターですので、実質4つです。
- AdLdapConnector
- CsvConnector
- DatabaseTableConnector
- LdapConnector
- ManualConnector
その他のシステムに接続したい場合は、以下の公式サイトのコネクターリストなどから欲しいものを探して追加する必要があります。SaaSアプリケーションに接続する場合も、まずはここから探します。
SmartHR用のコネクターに関しても上記リストに記載があり、利用することができます。
もし、使いたいSaaSアプリケーション用のコネクターがない場合でも、アプリケーションがSCIMプロトコルに対応していれば、SCIM用コネクターが利用できるかもしれません。ただし、SCIMによる標準化には限界があり、アプリケーション固有のクセを吸収しきれないケースもありますので、検証は必ず必要です。
SCIM用コネクターがうまく使えない、またはそもそもSaaSアプリケーションが独自のAPIしか提供していない場合は、カスタムコネクターを作って対応することも可能です。幸いなことに、コネクターリストで公開されているコネクターは基本的にOSSで開発されていますので、ソースコードを自由に参考にしつつ開発することが可能です。コネクターの開発については、以下に開発者向けのガイドが公開されています。
https://docs.evolveum.com/connectors/connid/1.x/connector-development-guide/
準備作業
オフィシャルのmidPointコンテナイメージを使う場合、SaaS連携で外部にHTTPS接続する際に、参照するトラストストアには初期構築時に自動生成されたキーストアが使われており、そのままではサーバー証明書の検証ができずエラーになってしまいます。これを解決するには以下の2つのアプローチがあります。
- 自動生成されたキーストアに信頼する証明書をインポートする
- midPointの実行に使われるJavaの標準トラストストアを参照するようにmidPointの設定を切り替える
今回は後者で設定します。以下のように、docker-compose.ymlを修正します。
midpoint_server:
image: evolveum/midpoint:${MP_VER:-latest}-alpine
container_name: midpoint_server
hostname: midpoint-container
depends_on:
data_init:
condition: service_completed_successfully
midpoint_data:
condition: service_started
command: [ "/opt/midpoint/bin/midpoint.sh", "container" ]
ports:
- 8080:8080
environment:
- MP_SET_midpoint_repository_jdbcUsername=midpoint
- MP_SET_midpoint_repository_jdbcPassword=db.secret.pw.007
- MP_SET_midpoint_repository_jdbcUrl=jdbc:postgresql://midpoint_data:5432/midpoint
- MP_SET_midpoint_repository_database=postgresql
- MP_SET_midpoint_administrator_initialPassword=Test5ecr3t
- MP_UNSET_midpoint_repository_hibernateHbm2ddl=1
- MP_NO_ENV_COMPAT=1
- MP_ENTRY_POINT=/opt/entry-point
+ - MP_SET_javax.net.ssl.trustStore="/etc/ssl/certs/java/cacerts"
+ - MP_SET_javax.net.ssl.trustStoreType="JKS"
- TZ=Asia/Tokyo
追加コネクターの導入
追加のコネクターのモジュール(JARファイル)を取得し、midPointが読み込むディレクトリに配置する必要があります。今回はJARファイルを直接ダウンロードしてきて、コンテナイメージにディレクトリをマウントして読み込ませます。
その他、オフィシャルのコンテナイメージをベースコンテナとして独自のイメージをビルドするようにして、ビルドプロセスでJARファイルをダウンロードしてコンテナイメージ内に含めてしまう方法もあります。こちらの方が、ステージングや本番環境にデプロイする際にも同じコンテナイメージを使うとコネクターも必ず同じものを利用させることができるので、デプロイ面で有利です。
配置用のディレクトリを作成します。
$ mkdir ./icf-connectors
作成したディレクトリにSmartHRコネクターをcurlコマンドで取得して配置します。
SmartHRコネクターはMaven Centralリポジトリにデプロイされておりダウンロードするだけですが、コネクターはコミュニティベースで提供されているものが多く、その取得方法は異なります。自前でビルドが必要なケースもあります。
$ curl -O --output-dir ./icf-connectors https://repo1.maven.org/maven2/jp/openstandia/connector/connector-smarthr/1.0.3/connector-smarthr-1.0.3.jar
あとはディレクトリをコンテナにマウントさせるように、docker-compose.ymlを修正します。
midpoint_server:
image: evolveum/midpoint:${MP_VER:-latest}-alpine
container_name: midpoint_server
hostname: midpoint-container
depends_on:
data_init:
condition: service_completed_successfully
midpoint_data:
condition: service_started
command: [ "/opt/midpoint/bin/midpoint.sh", "container" ]
ports:
- 8080:8080
environment:
- MP_SET_midpoint_repository_jdbcUsername=midpoint
- MP_SET_midpoint_repository_jdbcPassword=db.secret.pw.007
- MP_SET_midpoint_repository_jdbcUrl=jdbc:postgresql://midpoint_data:5432/midpoint
- MP_SET_midpoint_repository_database=postgresql
- MP_SET_midpoint_administrator_initialPassword=Test5ecr3t
- MP_UNSET_midpoint_repository_hibernateHbm2ddl=1
- MP_NO_ENV_COMPAT=1
- MP_ENTRY_POINT=/opt/entry-point
- MP_SET_javax.net.ssl.trustStore="/etc/ssl/certs/java/cacerts"
- MP_SET_javax.net.ssl.trustStoreType="JKS"
- TZ=Asia/Tokyo
networks:
- net
volumes:
- midpoint_home:/opt/midpoint/var
+ - ./icf-connectors:/opt/midpoint/var/icf-connectors
環境の起動
Docker Composeで環境を起動します。midpoint_serverコンテナのログを見ると、追加したコネクターが起動時に認識されてロードされた旨を確認することができます。
midpoint_server | 2024-12-21 09:14:09,904 [] [main] INFO (com.evolveum.midpoint.provisioning.ucf.impl.connid.ConnectorFactoryConnIdImpl): Discovered ICF bundle in JAR: jp.openstandia.connector.connector-smarthr version: 1.0.3
SmartHRとの連携
SmartHRを源泉システムとして、従業員と部署をmidPointのユーザーと組織として取り込むようにしてみます。やることは、接続先のリソース種類が変わっただけであり、既に解説した以下の源泉取り込み系の記事と同じです。
- 5日目の記事「midPoint にCSVの源泉データをインポートする(ユーザー編)」
- 8日目の記事「midPoint にCSVの源泉データをインポートする(組織編)」
- 9日目の記事「midPoint にCSVの源泉データをインポートする(ユーザーと組織のアサイン編)」
基本的な設定の流れは上記の記事で既に解説済みのため、本記事ではSmartHR固有の設定を中心に紹介します。
SmartHRの準備
接続先となるSmartHRの環境が必要です。本記事では、SmartHRのサンドボックス環境を利用して確認しています。試されたい方は以下のページを参照してください。
API/Webhookを用いたシステム開発の検証、連携先外部サービスの接続確認の検証及び権限に関する検証を目的としたサンドボックス環境となっていますので、ご注意ください。
また、SmartHRのAPI接続のための、アクセストークンを発行しておきます。
リソースの作成
SmartHRコネクターを正しく導入できていると、リソースの作成画面で「SmartHRConnector」を選択できるようになっています。

名前はSmartHRとしておきます。
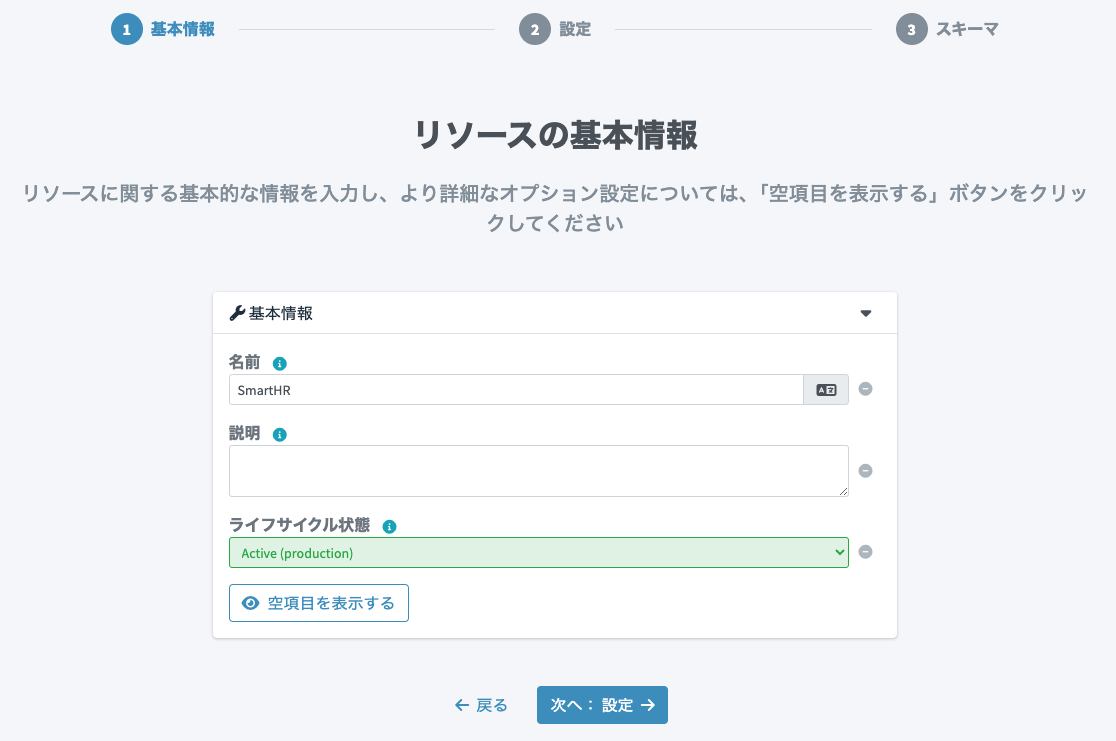
SmartHRのAPI URLとアクセストークンを設定します。
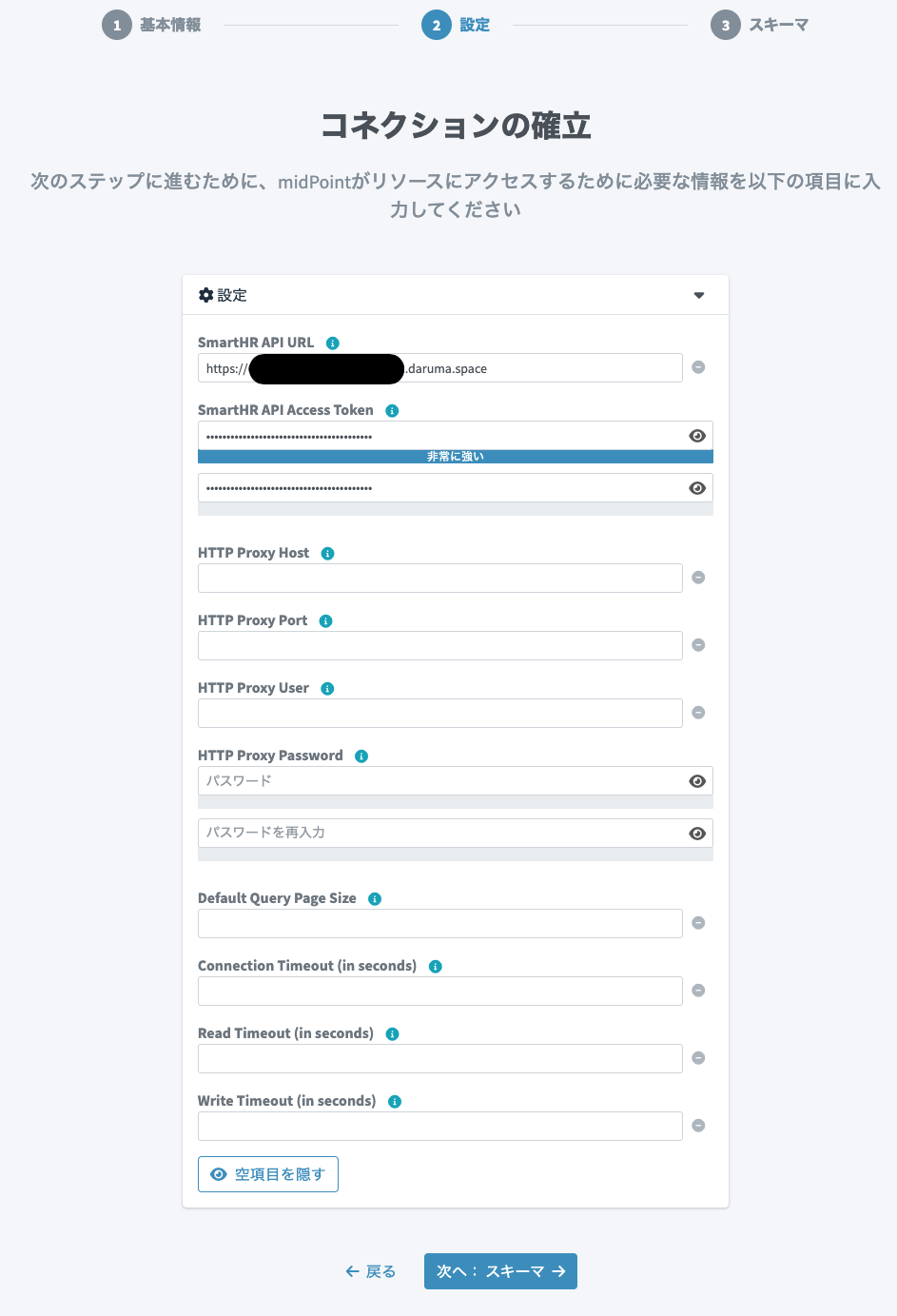
もし、インターネットアクセスにHTTPプロキシが必要な環境であれば、設定項目がありますので必要に応じて設定します。
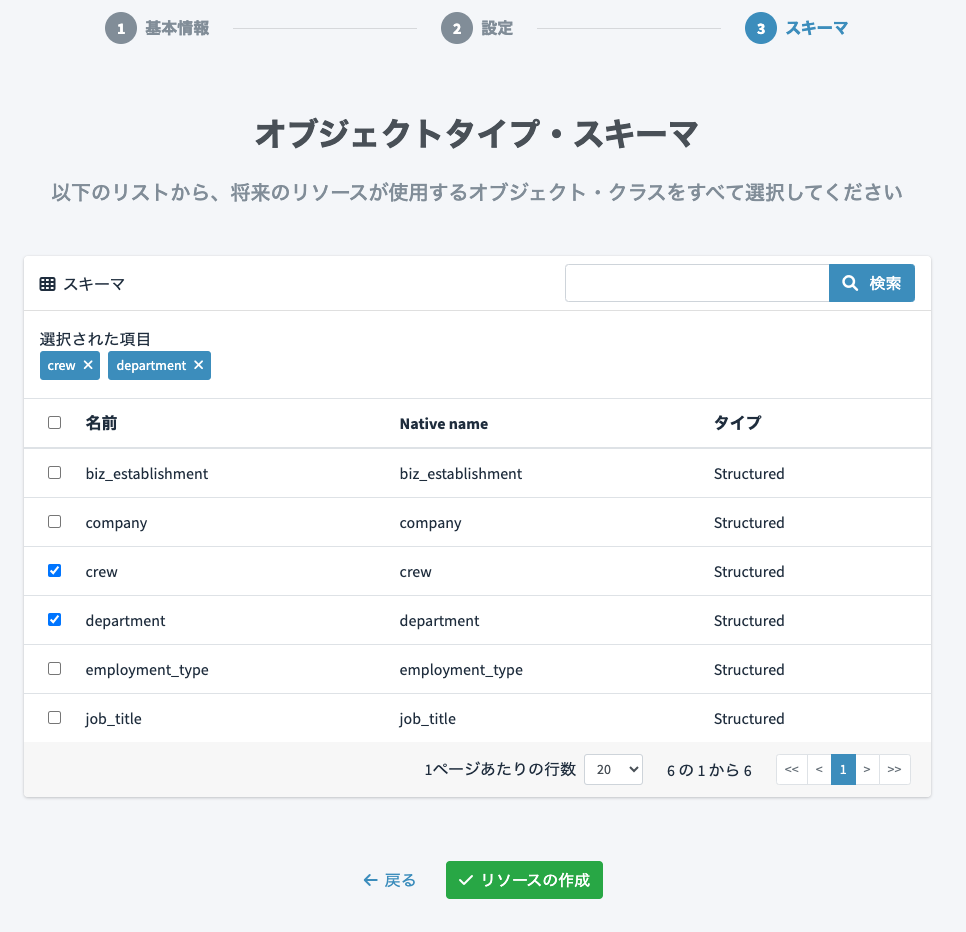
オブジェクトタイプ・スキーマは、従業員を表すcrewと部署を表すdepartmentのみを今回は使用します。
ケイパビリティーの設定
リソースを作成したら、最初にケイパビリティーの設定をして、midPointからSmartHR側を誤って更新や削除をしないように制限をかけておきます。
ケイパビリティーとは、そのコネクターが対応している内容(作成、参照、更新、削除などの基本となるCRUD操作や、ライブ同期といった特殊オペレーションなど)のことです。コネクターの実装であらかじめ対応されるケイパビリティーは決まっていますが、それをリソース設定で上書きして無効化することもできます。
リソースの詳細画面より「詳細」メニューを開きます。すると「ケイパビリティー一覧」が表示されます。
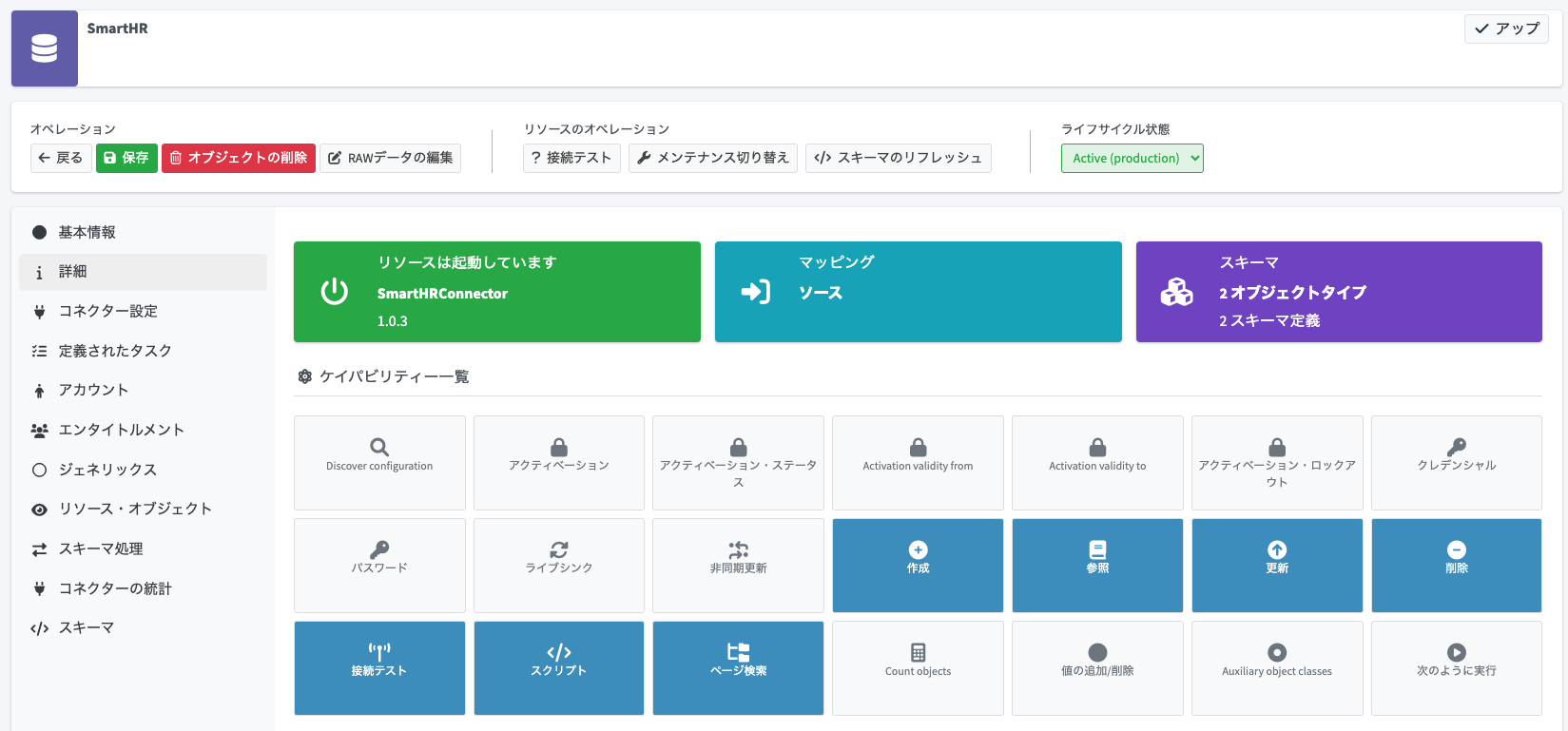
この中で、「作成」「更新」「削除」をクリックして無効化します。「更新」をクリックした際には詳細オプションのダイアログが表示されるので、「有効」をFalseにして「OK」ボタンをクリックします。
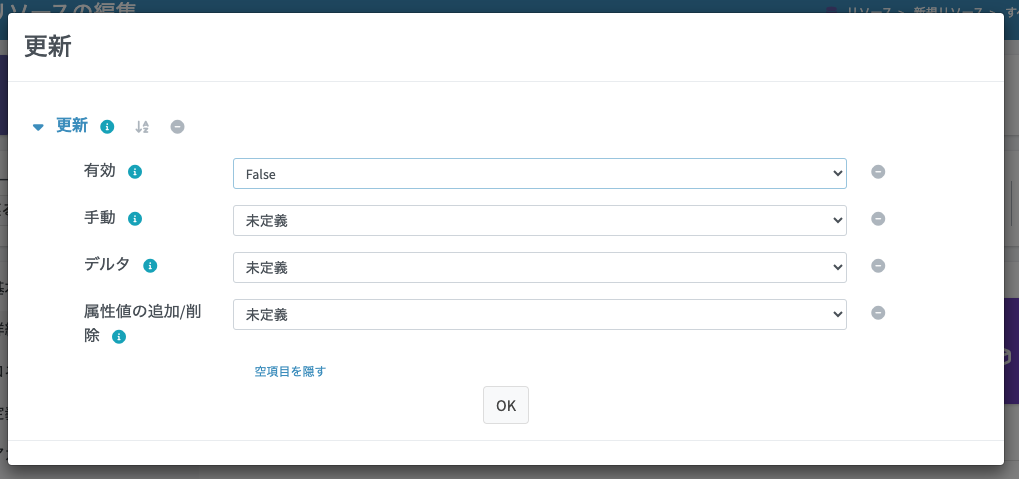
最終的に以下のようにグレーアウトされた状態になっていることを確認し、リソースの「保存」ボタンをクリックして保存します。

これで設定ミスや誤操作でSmartHR側に更新や削除処理が発生した場合に、midPointが検知してエラーを返すようになります。
midPoint側ではでなく、SmartHR側のアクセストークンの設定で更新不可とする制御も可能ですので、不必要な権限を与えないように設定しておくとよいでしょう。
オブジェクトタイプの追加
SmartHRのデータをmidPointにユーザーと組織として取り込むため、オブジェクトタイプの追加を行います。
Crew(従業員)の追加
SmartHRのCrew(従業員)用のオブジェクトタイプを追加します。
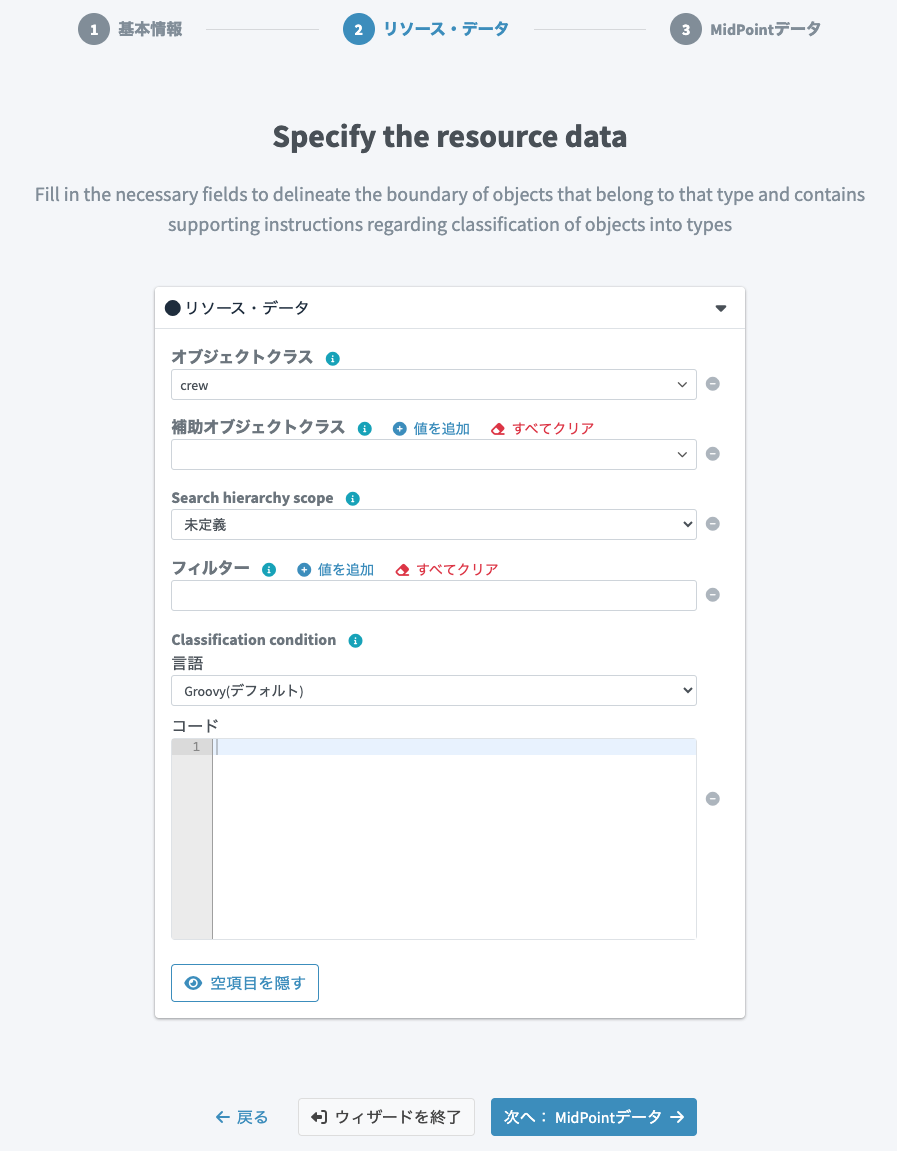
オブジェクトクラスにはcrewを設定します。
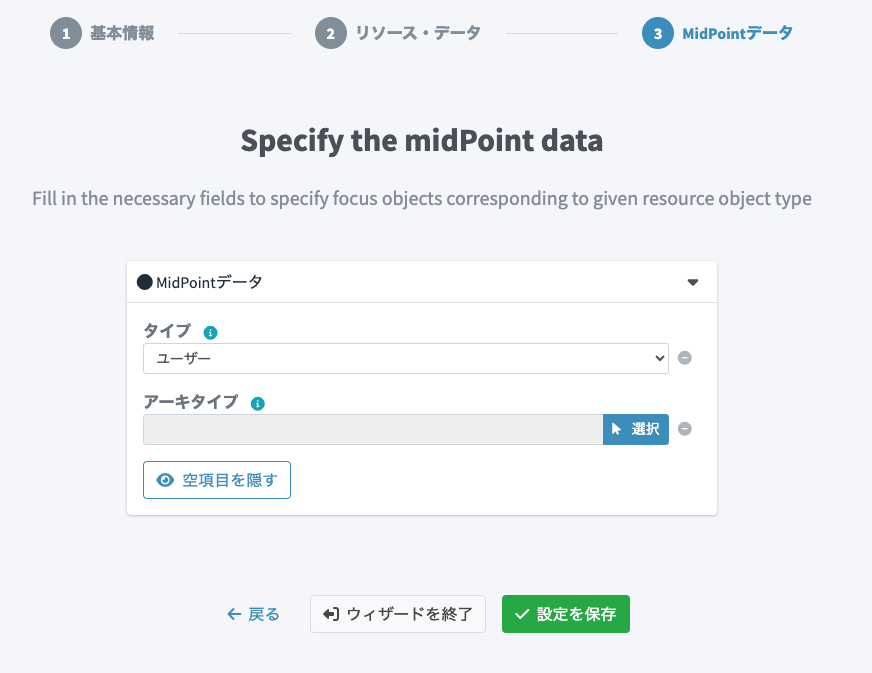
midPointのユーザーとして取り込みたいので、「タイプ」ではユーザーを選択します。
インバウンドマッピングの設定
以下のように設定します。「departments」の「ターゲット」はアサインを行う設定をRAW編集で行うため、一旦未設定で保存します。
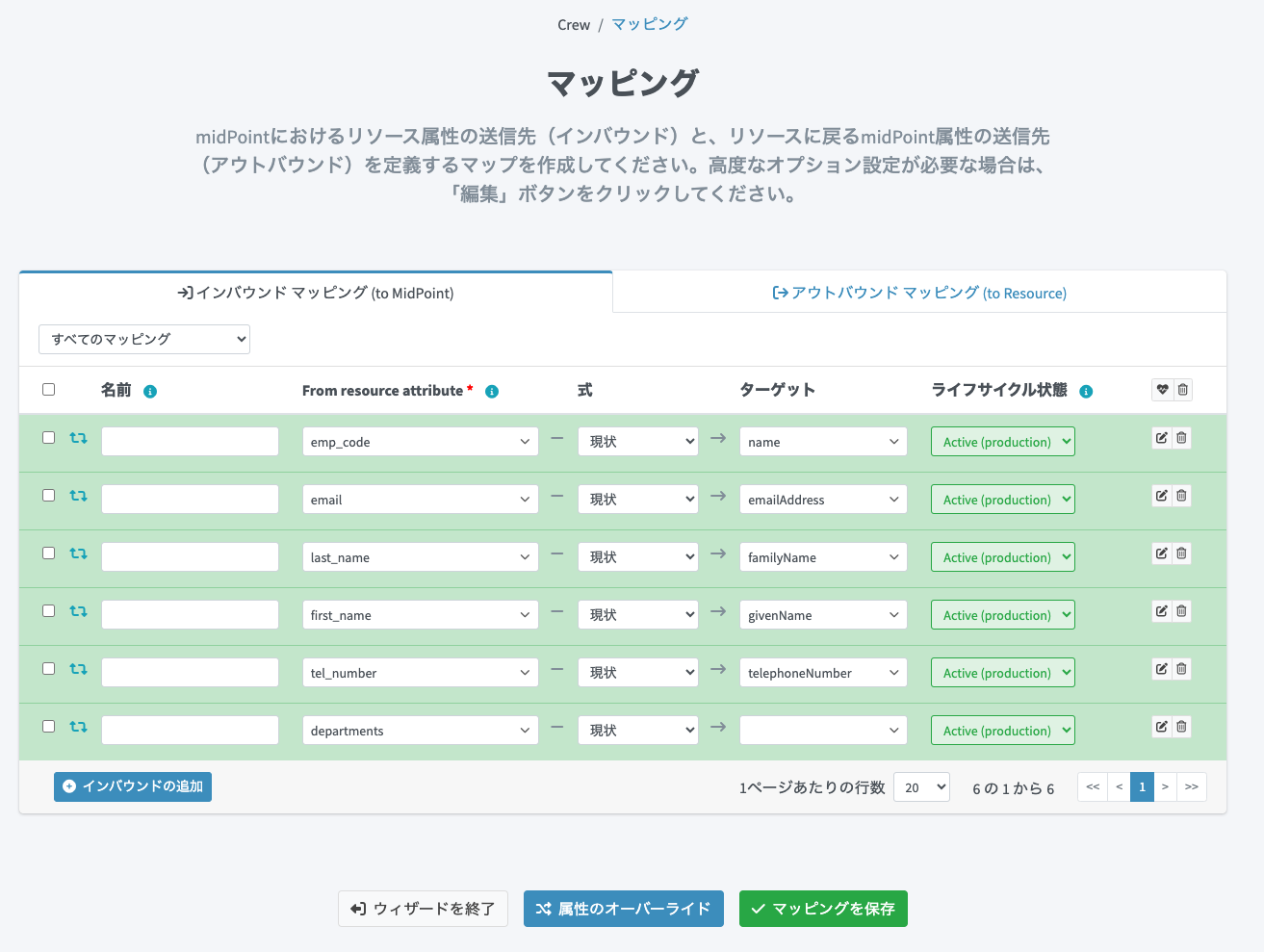
RAW編集画面を開き、以下を設定します。9日目の記事「midPoint にCSVの源泉データをインポートする(ユーザーと組織のアサイン編)」で解説したように、<assignmentTargetSearch>を利用して所属組織に自動アサインするように設定します。
CSVの時と違い、少し複雑な設定になっています。SmartHRのAPIでは、主務と兼務も混ざった状態でdepartmentsという項目に配列で格納されており、主務はその配列の先頭という仕様になっています。よって、midPointで主務と兼務を区別するには少し工夫が必要です。というのも、マルチバリューであるdepartmentsの値は1つずつ展開されてマッピングに渡されて評価されるため、マッピング処理時に配列の何番目であるか判断できないためです。
そこで、<relativityMode>absolute</relativityMode>という設定を入れることで、マルチバリュー全体の値をマッピング中のinput変数にバインドするモードに切り替えます。そうすることで配列の先頭を主務に、残りを兼務としてmidPointにマッピングするようにしています。
<attribute id="...">
<ref>ri:departments</ref>
<inbound id="...">
<strength>strong</strength>
+ <expression>
+ <assignmentTargetSearch>
+ <relativityMode>absolute</relativityMode>
+ <targetType>c:OrgType</targetType>
+ <filter>
+ <q:equal>
+ <q:path>identifier</q:path>
+ <expression>
+ <queryInterpretationOfNoValue>filterNone</queryInterpretationOfNoValue>
+ <script>
+ <code>
+ <![CDATA[
+ input?.size() > 0 ? input[0] : null
+ ]]>
+ </code>
+ </script>
+ </expression>
+ </q:equal>
+ </filter>
+ <assignmentProperties>
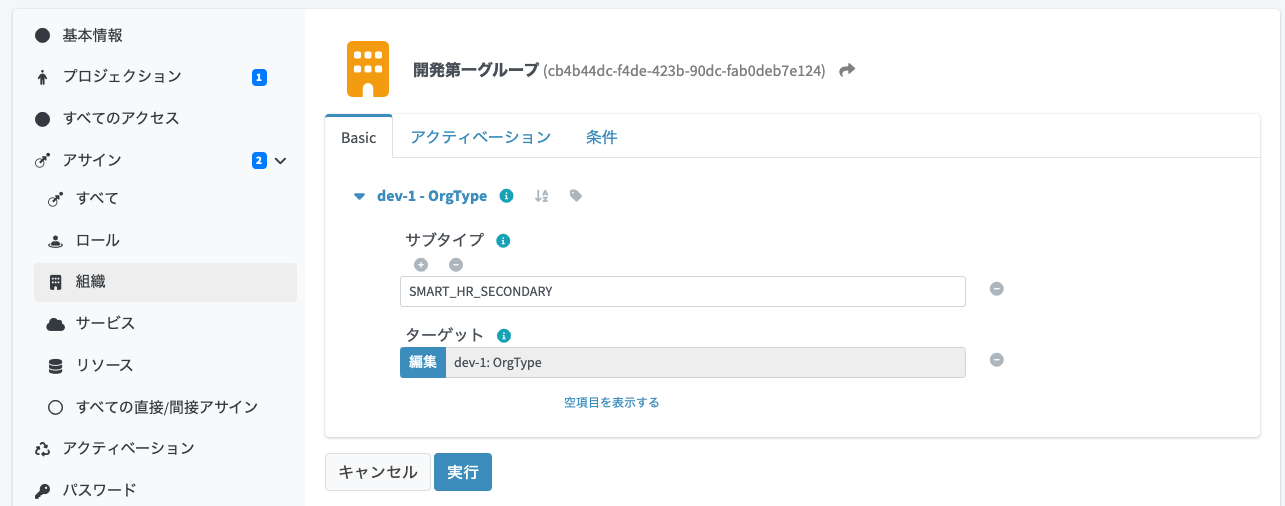
+ <subtype>SMART_HR_PRIMARY</subtype>
+ </assignmentProperties>
+ </assignmentTargetSearch>
+ </expression>
+ <target>
+ <path>assignment</path>
+ <set>
+ <condition>
+ <script>
+ <code>
+ assignment?.subtype.contains("SMART_HR_PRIMARY")
+ </code>
+ </script>
+ </condition>
+ </set>
+ </target>
+ </inbound>
+ <inbound>
+ <strength>strong</strength>
+ <expression>
+ <assignmentTargetSearch>
+ <relativityMode>absolute</relativityMode>
+ <targetType>c:OrgType</targetType>
+ <filter>
+ <q:equal>
+ <q:path>identifier</q:path>
+ <expression>
+ <queryInterpretationOfNoValue>filterNone</queryInterpretationOfNoValue>
+ <script>
+ <code>
+ <![CDATA[
+ input?.size() > 1 ? input[1..-1] : null
+ ]]>
+ </code>
+ </script>
+ </expression>
+ </q:equal>
+ </filter>
+ <assignmentProperties >
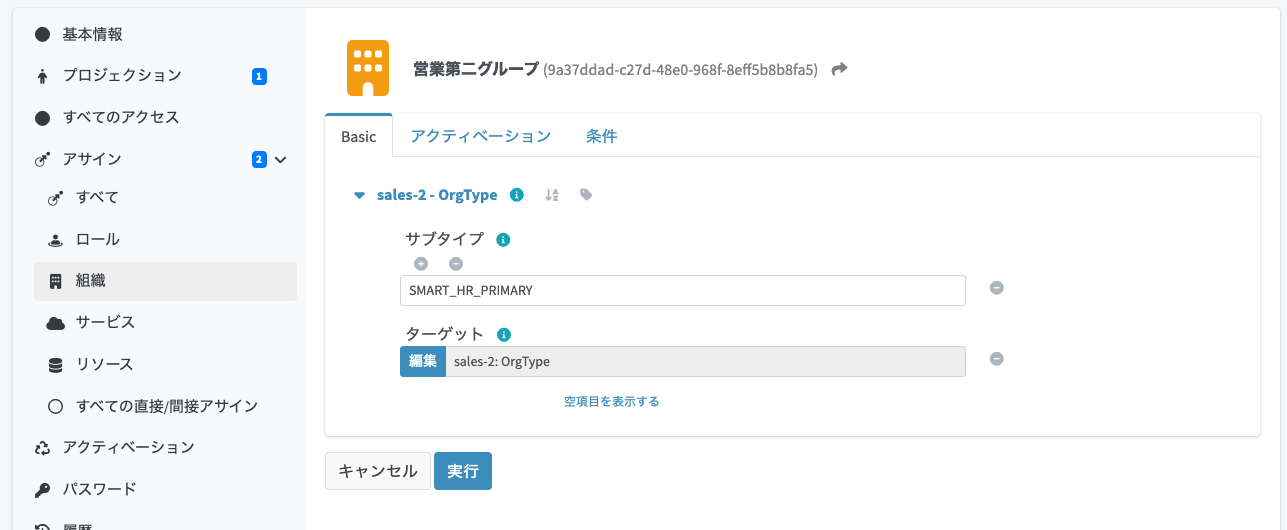
+ <subtype>SMART_HR_SECONDARY</subtype>
+ </assignmentProperties>
+ </assignmentTargetSearch>
+ </expression>
+ <target>
+ <path>assignment</path>
+ <set>
+ <condition>
+ <script>
+ <code>
+ assignment?.subtype.contains("SMART_HR_SECONDARY")
+ </code>
+ </script>
+ </condition>
+ </set>
+ </target>
</inbound>
</attribute>
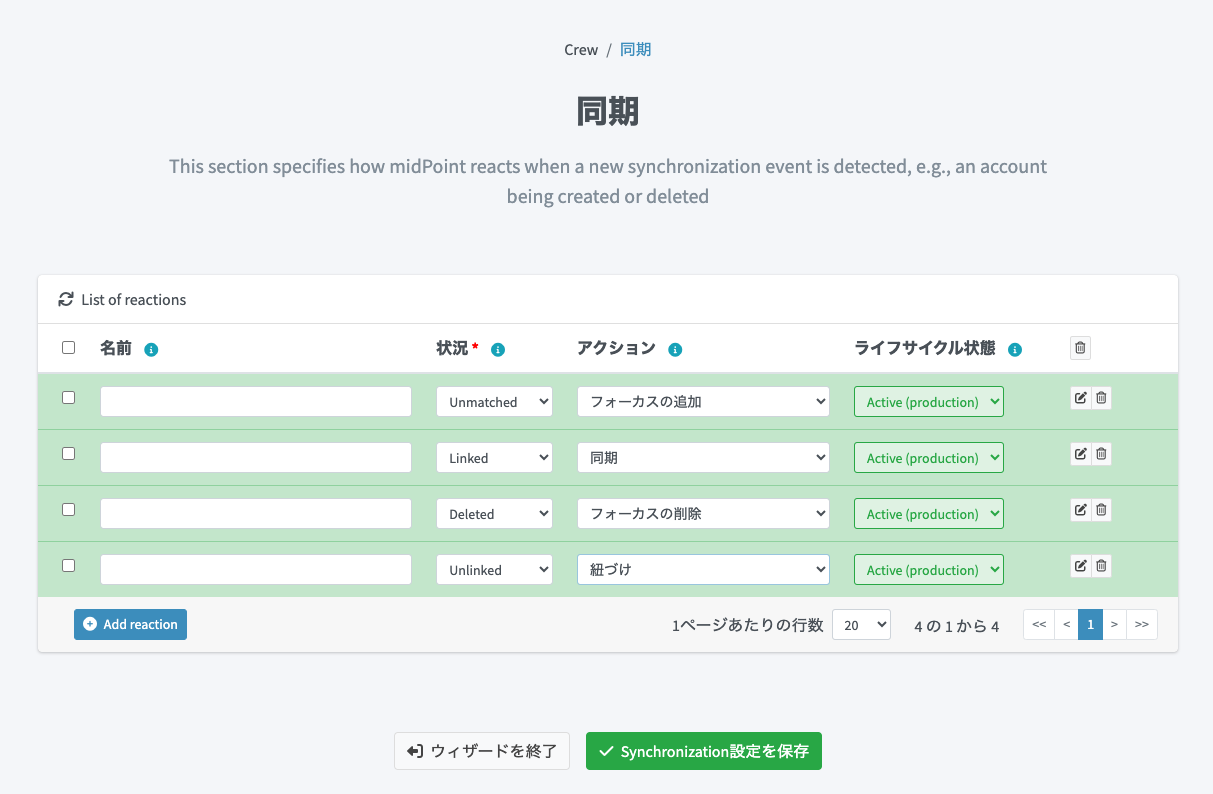
同期の設定
5日目の記事「midPoint にCSVの源泉データをインポートする(ユーザー編)」と同じ同期の設定をしておきます。
Correlationの設定
今回は省略します。
Department(部署)の追加
SmartHRのDepartment(部署)用のオブジェクトタイプを追加します。「用途」はdepartmentとしておきます。
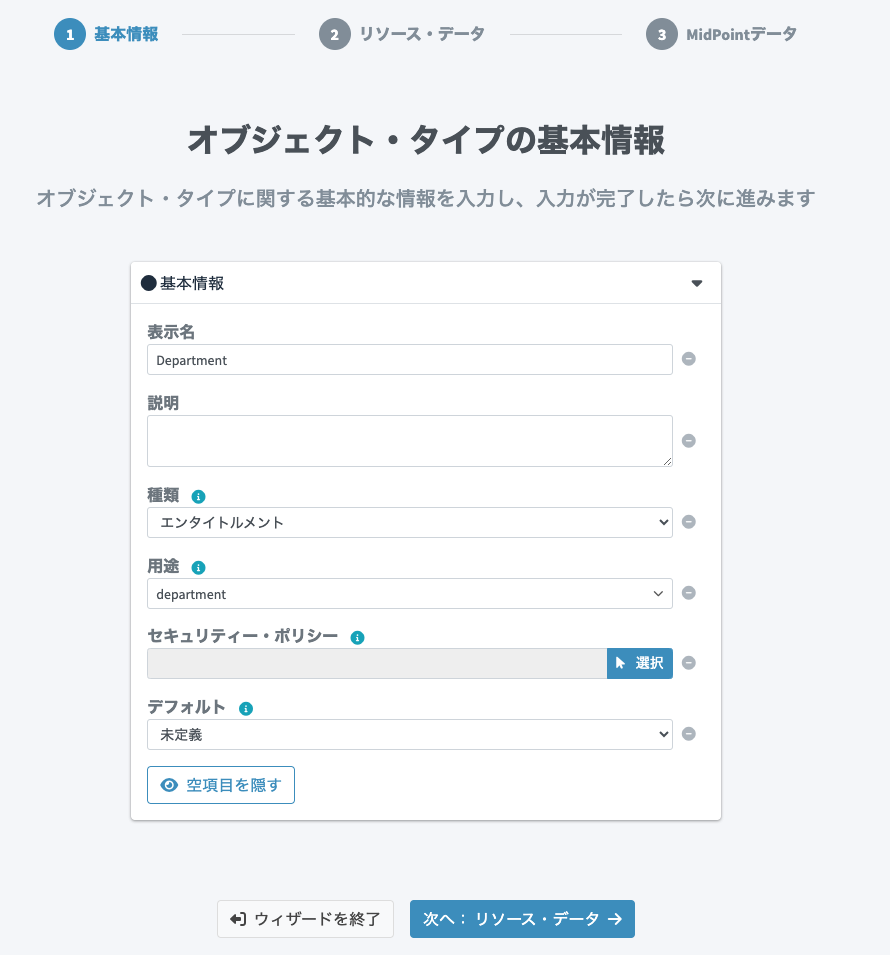
オブジェクトクラスにはdepartmentを設定します。
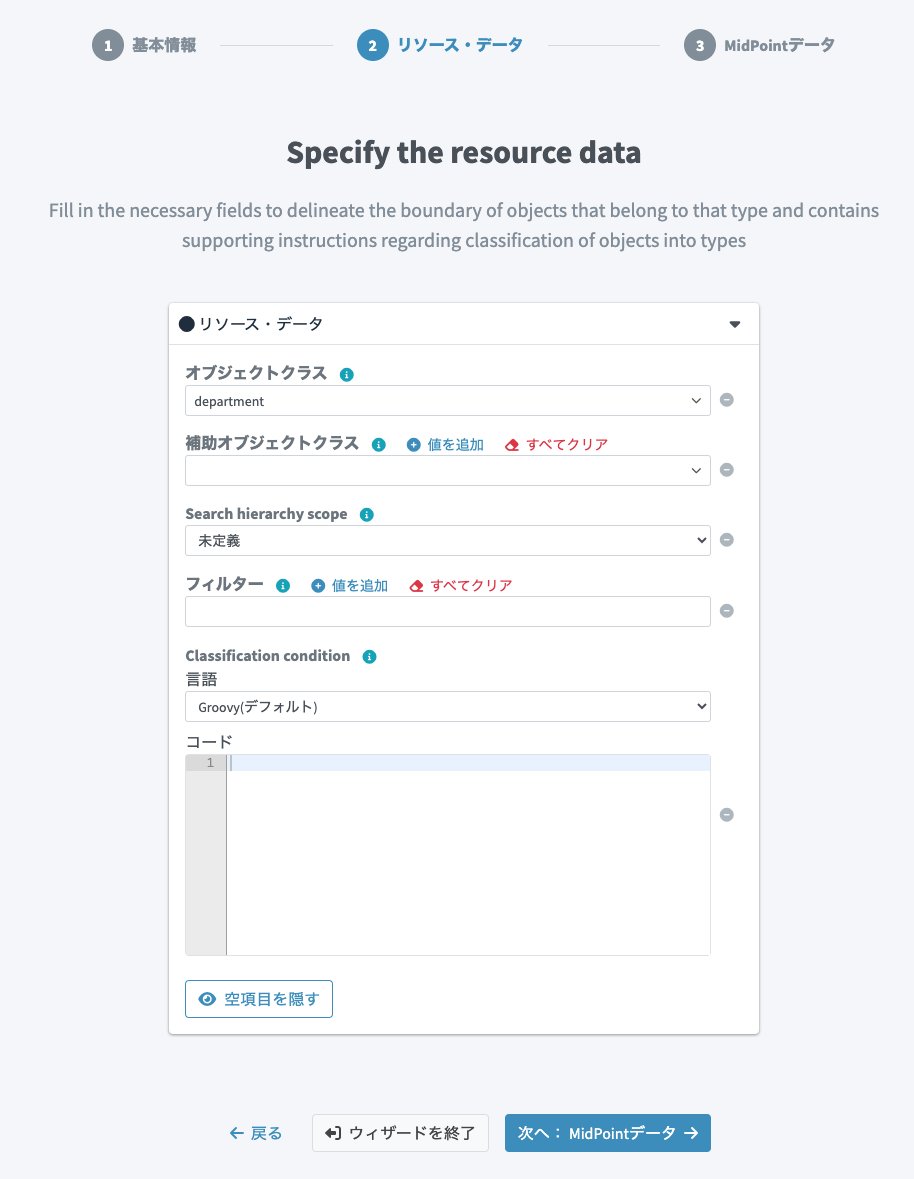
midPointの組織として取り込みたいので、「タイプ」では組織を選択します。
SmartHRの部署のルート組織の作成
SmartHRの部署データは、親組織のない最上位の部署を複数作ることができます。そのままmidPointに取り込むと、きれいな組織ツリーにならないため、SmartHRの組織用のルート組織を今回は作成しておきます。
以下の内容で組織を作成しておきます。識別子 を使って、SmartHRからの部署取り込み時にこの組織を自動アサインするため、注意してください。
-
名前:
smarthr-root -
表示名:
SmartHR組織 -
識別子:
smarthr-root
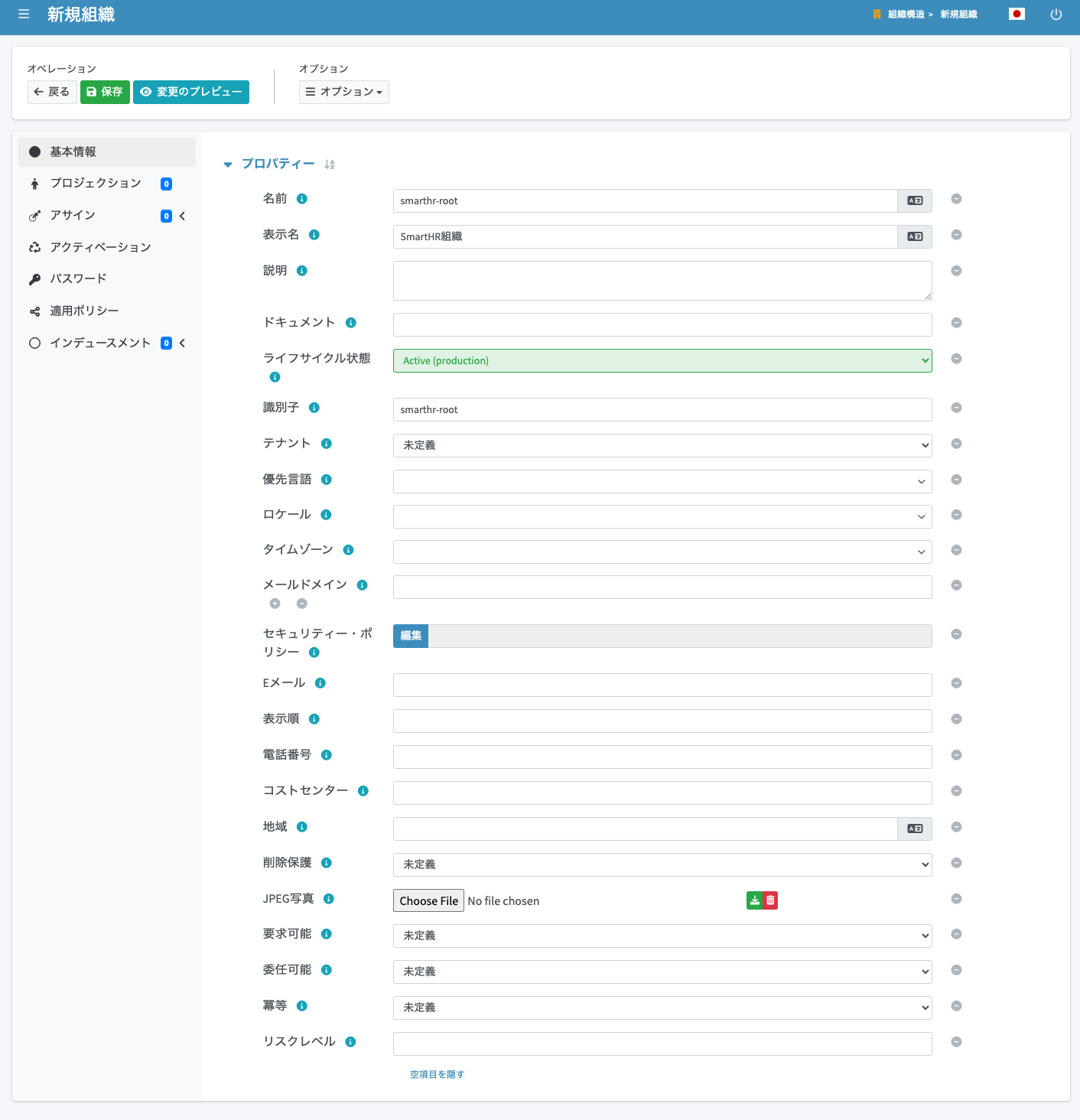
インバウンドマッピングの設定
以下のように設定します。「parent_id」の「ターゲット」は8日目の記事「midPoint にCSVの源泉データをインポートする(組織編)」と同様に、一旦未設定で保存します。
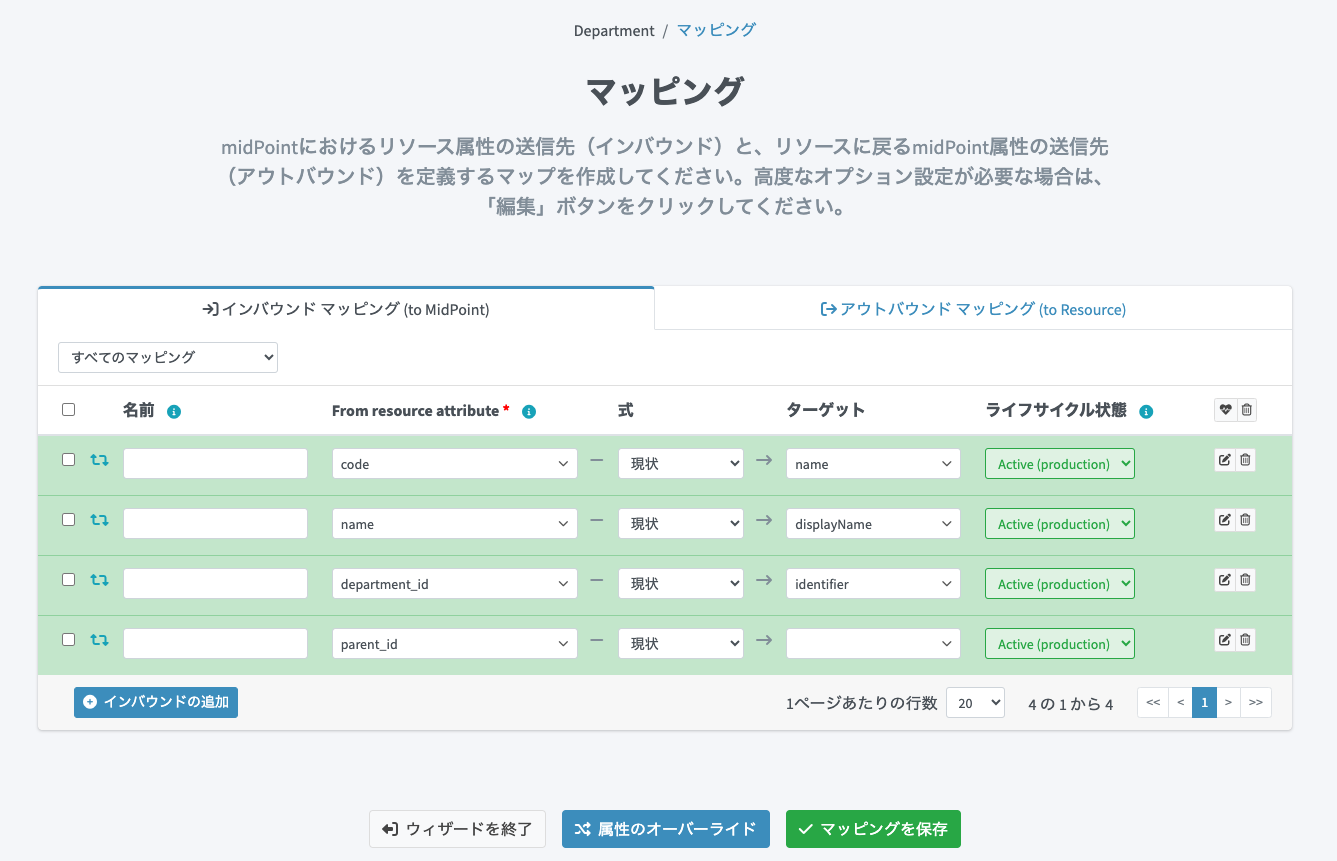
RAW編集画面を開き、以下を設定します。
CSVの時と異なるポイントとして、<includeNullInputs>true</includeNullInputs>を設定しています。これは、インプットとなるソースのデータがnullの時に、nullを含めてマッピングを評価させるかどうかを決定するオプション設定です。SmartHRではトップレベルの部署については親組織が存在しないため、「parent_id」はnullとなります。このnullをハンドリングして先ほど作成した「SmartHR組織」を親組織としてアサインしたいので、trueに設定しています。
<attribute id="...">
<ref>ri:parent_id</ref>
<inbound id="...">
<strength>strong</strength>
+ <expression>
+ <assignmentTargetSearch>
+ <includeNullInputs>true</includeNullInputs>
+ <targetType>c:OrgType</targetType>
+ <filter>
+ <q:equal>
+ <q:path>identifier</q:path>
+ <expression>
+ <queryInterpretationOfNoValue>filterNone</queryInterpretationOfNoValue>
+ <script>
+ <code>
+ input == null ? "smarthr-root" : input
+ </code>
+ </script>
+ </expression>
+ </q:equal>
+ </filter>
+ <assignmentProperties>
+ <subtype>SMART_HR</subtype>
+ </assignmentProperties>
+ </assignmentTargetSearch>
+ </expression>
+ <target>
+ <path>assignment</path>
+ <set>
+ <condition>
+ <script>
+ <code>
+ assignment?.subtype.contains("SMART_HR")
+ </code>
+ </script>
+ </condition>
+ </set>
+ </target>
</inbound>
</attribute>
同期の設定
8日目の記事「midPoint にCSVの源泉データをインポートする(組織編)」と同じ同期の設定をしておきます。
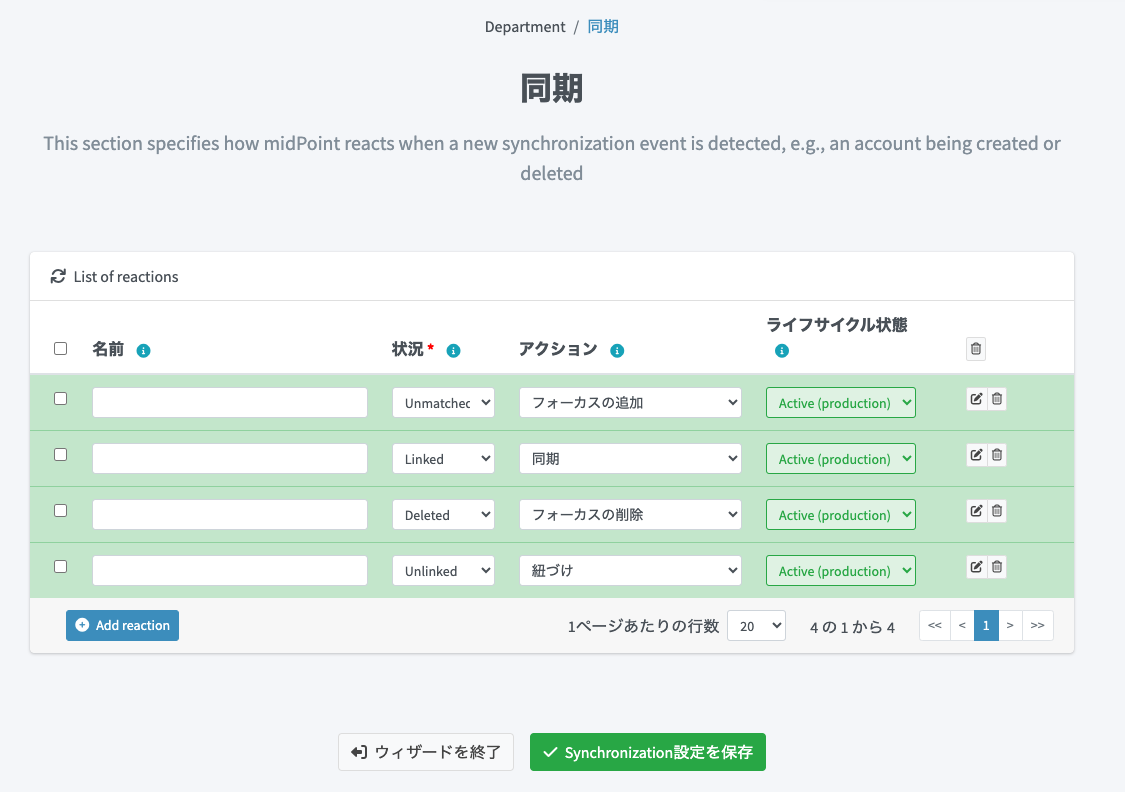
Correlationの設定
今回は省略します。
タスクの作成
5日目の記事「midPoint にCSVの源泉データをインポートする(ユーザー編)」、8日目の記事「midPoint にCSVの源泉データをインポートする(組織編)」と同様に、それぞれ取り込み用のタスクを作成しておきます。
- 「SmartHR import users」インポートタスク
- 「SmartHR recon orgs」リコンシリエーションタスク
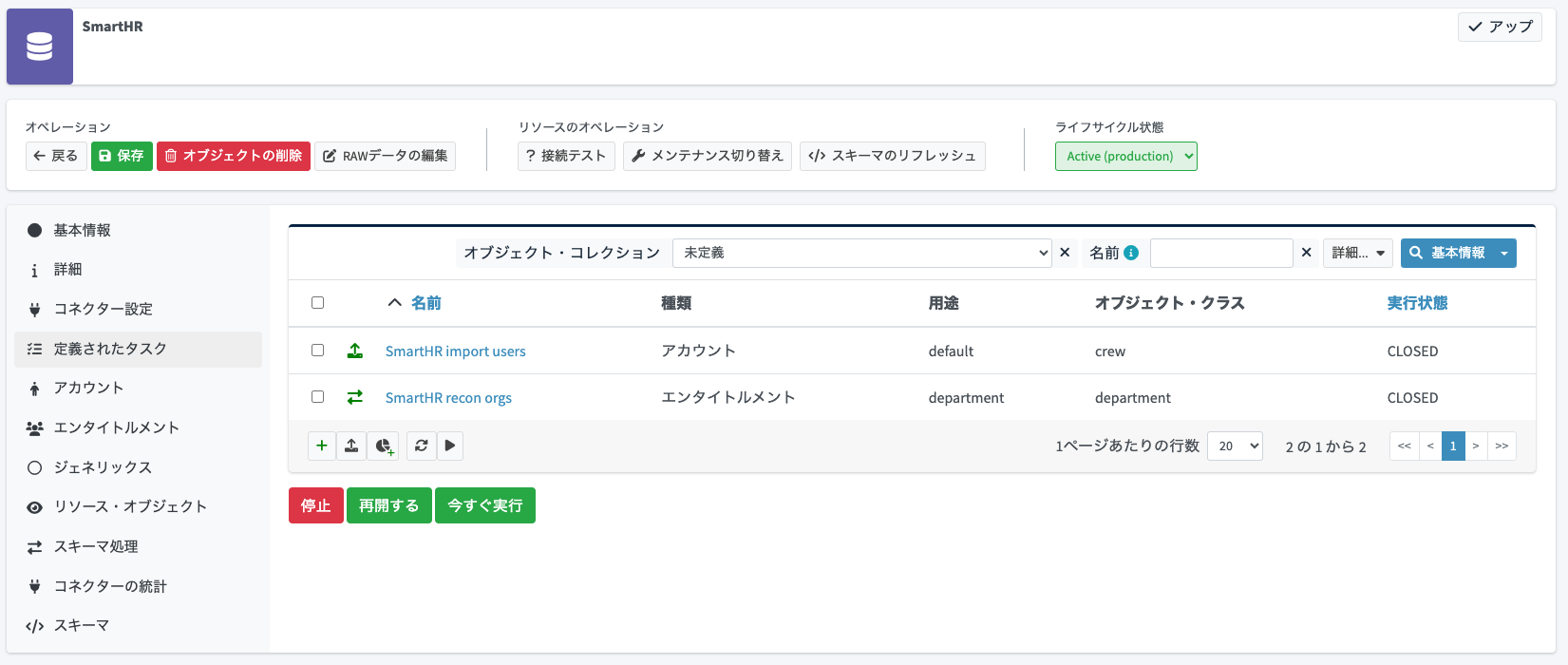
SmartHR側のテストデータの準備
サンドボックス環境を利用すると、デフォルトでユーザーに関しては登録されていますが、部署情報は入力しておく必要がありますので、適当なデータを入れておきます。
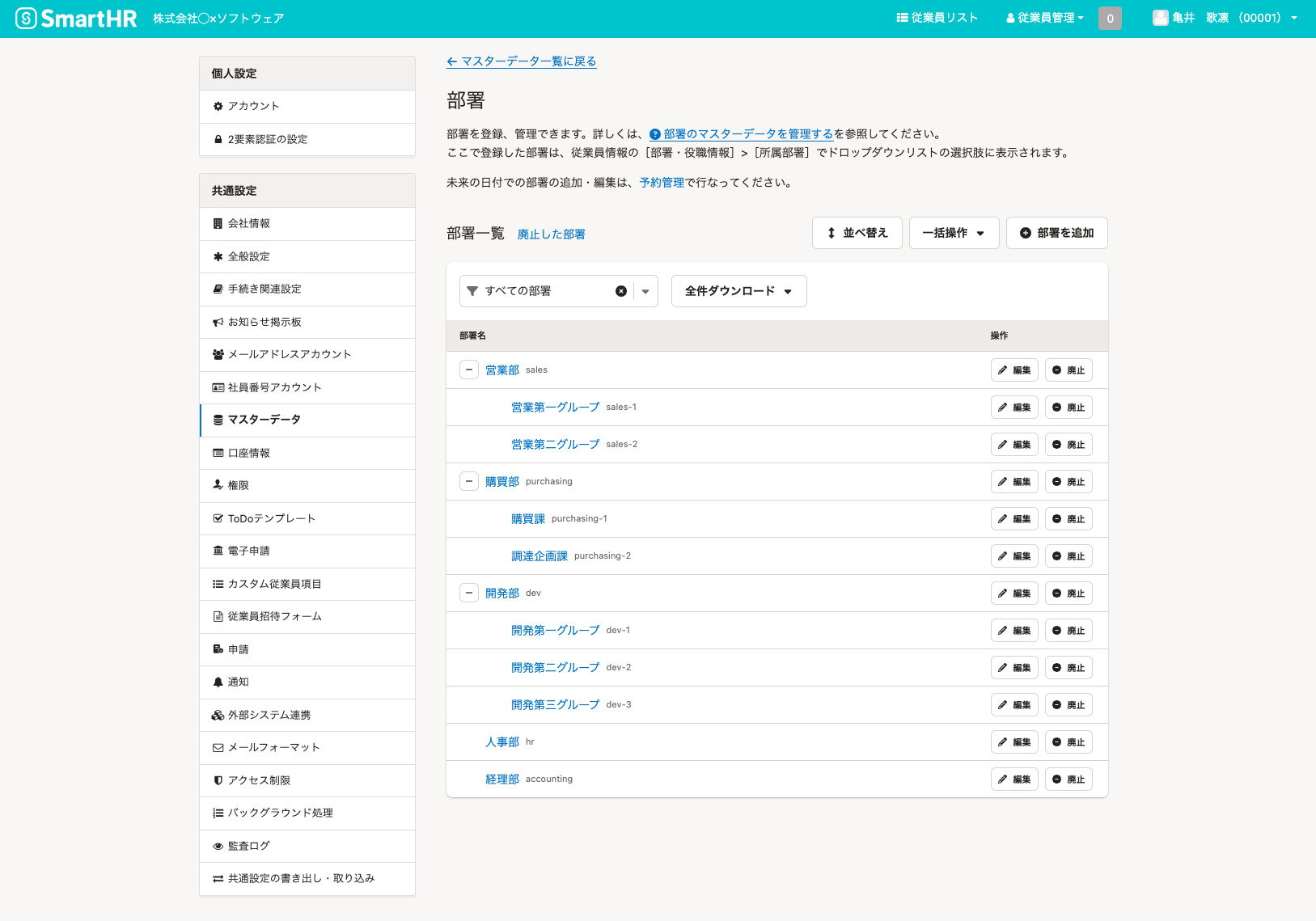
作成した部署データと従業員の紐付けも実施しておきます。
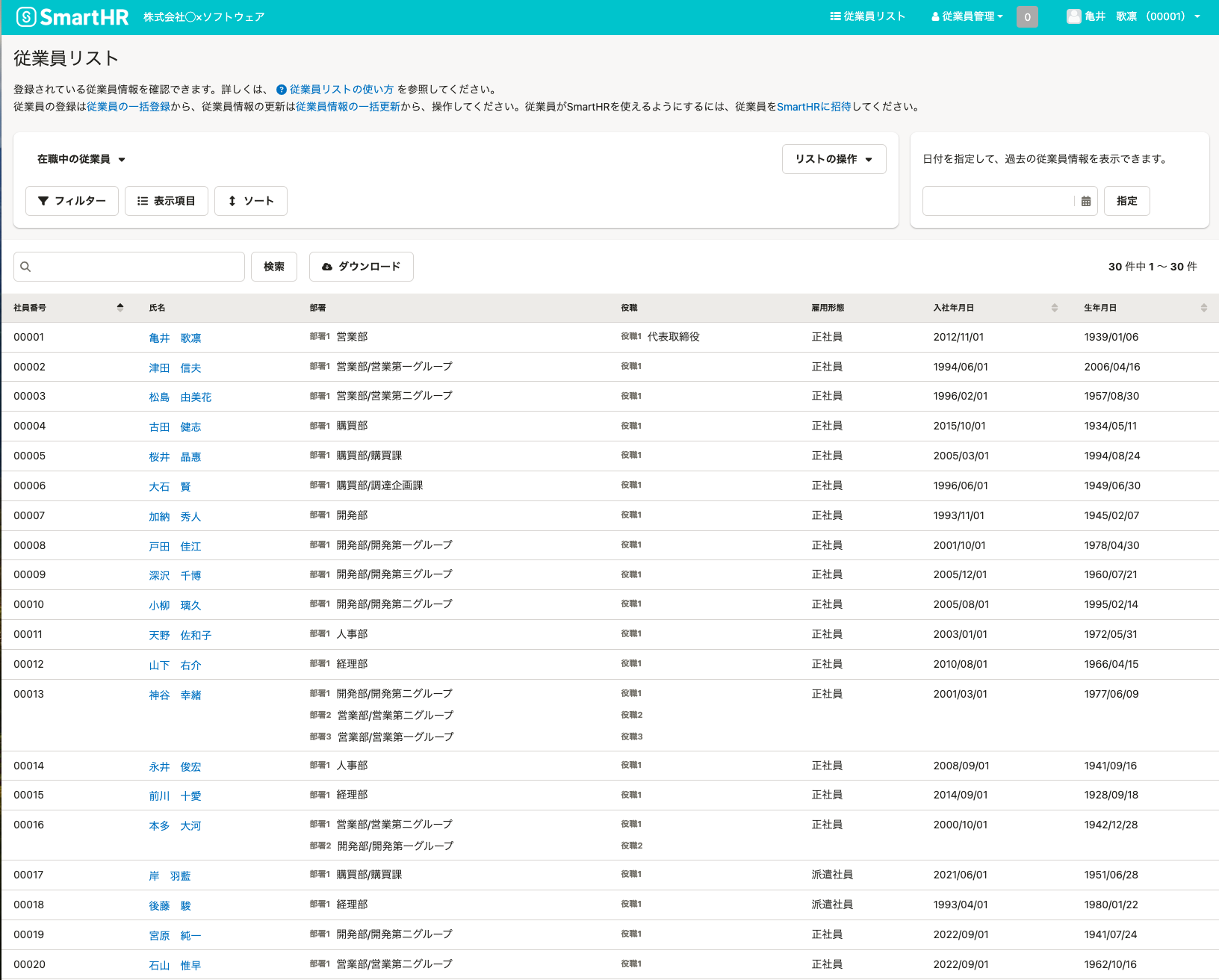
動作確認
SmartHRの部署の取り込み
「SmartHR recon orgs」リコンシリエーションタスクを実行して、部署情報を組織として取り込みます。タスク実行完了後、組織ツリー画面を開いて想定通りツリー構造で取り込まれているかどうか確認します。
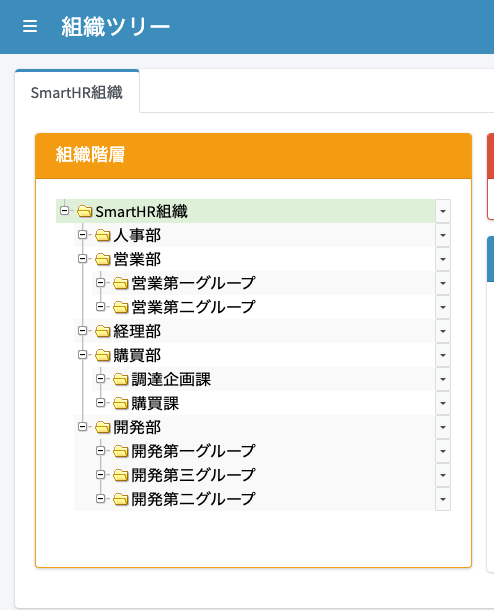
SmartHRの従業員の取り込み
「SmartHR import users」インポートタスクを実行して、従業員情報をユーザーとして取り込みます。タスク実行完了後、ユーザー一覧画面を開いて取り込まれているかどうか確認します。
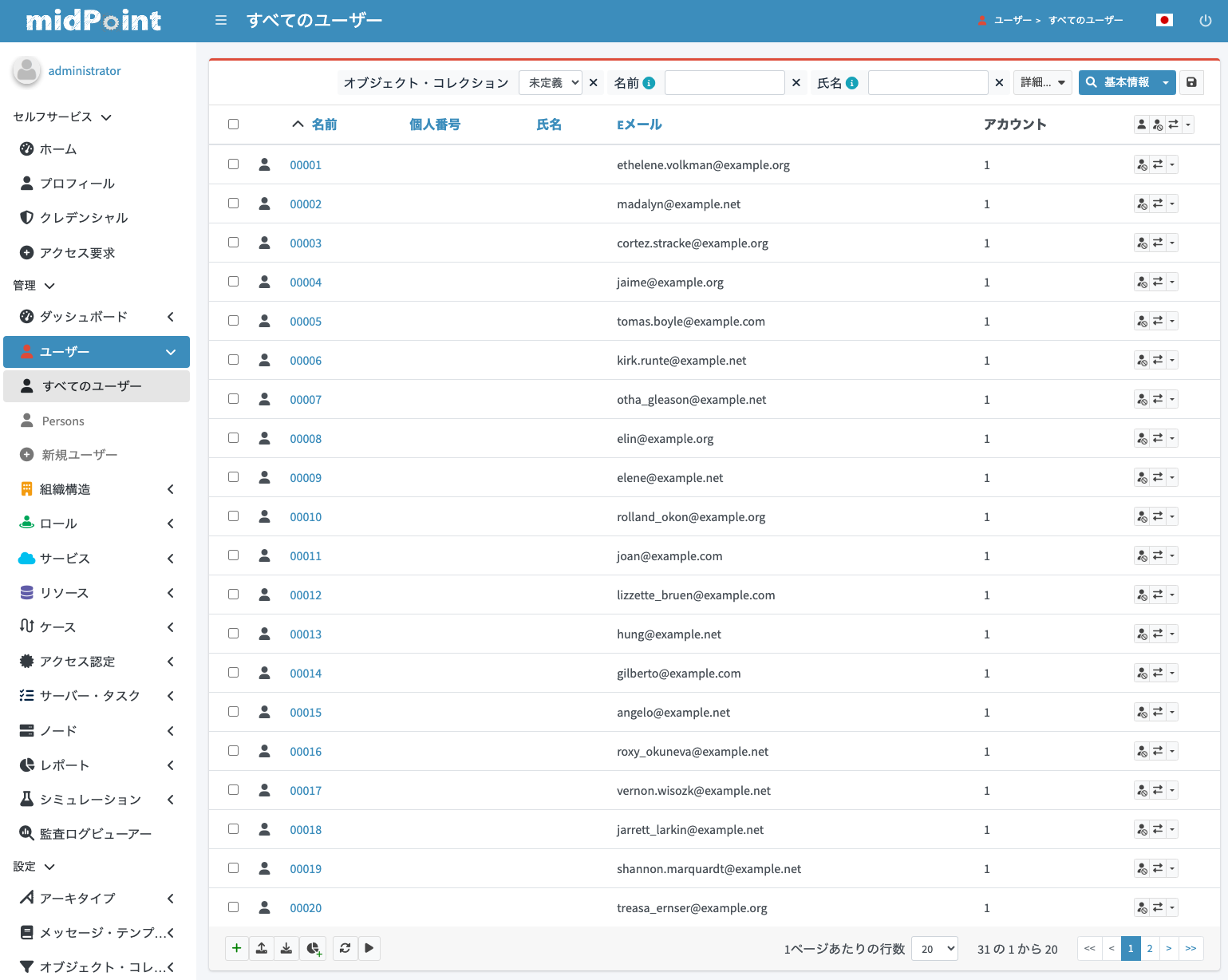
主務と兼務も想定通り付いているか確認します。
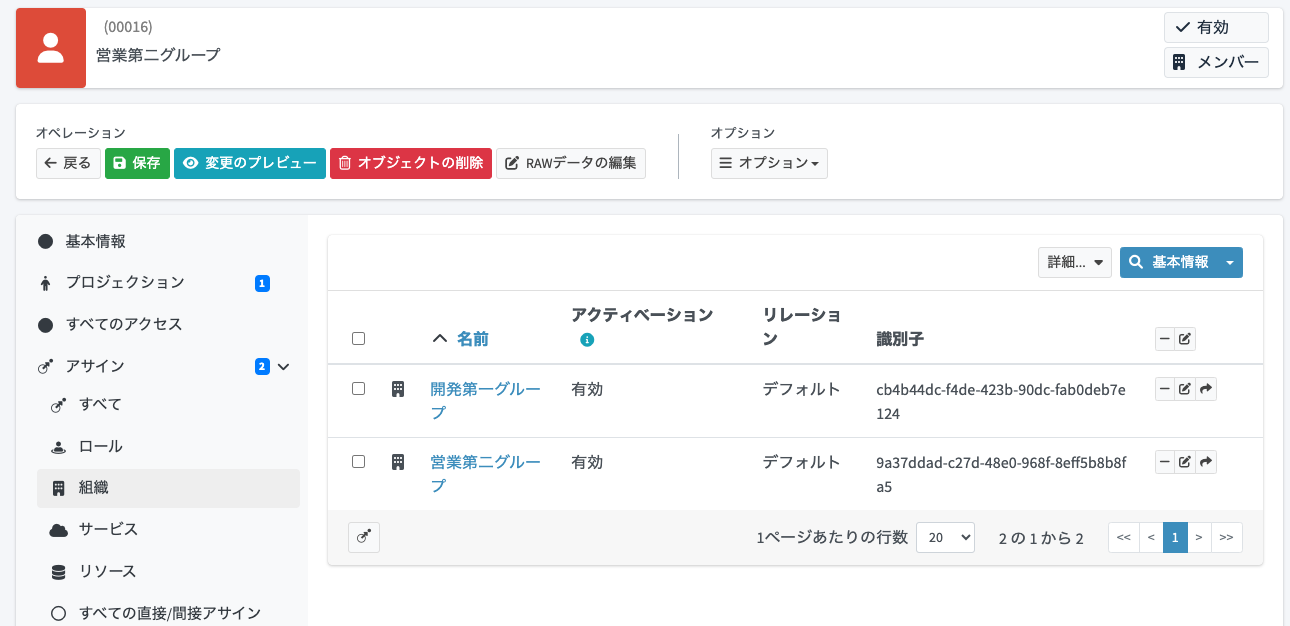
主務と兼務の区別がついているかは、各アサインの詳細画面を開いてサブタイプを確認します。
まとめ
22日目では、SaaSアプリケーションの一つであるSmartHRとの連携方法について解説しました。既にCSVファイルを源泉とした取り込みについては、5日目、8日目、9日目の記事で解説済みでした。そのため、今回の連携ではコネクターが異なるだけで、midPoint側ではほぼ同じ設定手順で対応できることをご理解いただけたかと思います。
オンプレミスのアプリケーションであれ、SaaSアプリケーションであれ、midPointではコネクターを通じてデータ連携を標準化しています。そのため、リソース設定においては、主に項目間のマッピング調整が必要な作業となります。
今回紹介したSmartHR以外にも、コネクターリストにはいくつかSaaSアプリケーション向けのコネクターが掲載されていますので、ぜひ試してみてください。ただし、コネクターの数に関しては、大手ベンダーが提供するIDM/IGAソリューション1と比べると、midPointにはまだ課題が残っています。もし連携を希望するSaaSアプリケーションに対応するコネクターが見つからない場合は、コメントやX(旧Twitter)などを通じてフィードバックをお寄せいただければ、何かお手伝いできるかもしれません。是非お気軽にご連絡ください。
-
SailPoint、Savyintといった大手IGAベンダーや、Microsoft Entra ID、Oktaといった大手IDaaSベンダーのソリューションでは、コネクターの数はやはり豊富です。 ↩