概要
GoToEat大阪のキャンペーンページには、店舗検索のページはありますがマップ表示ができないんですね。
Google Map APIを使えばマップ表示できますが、その前にまず対象店をテーブル形式で保管する必要があります。
RubyのNokogiriを使ってスクレイピングしました。
コード
require 'open-uri'
require 'nokogiri'
require "csv"
@id=0
@page=1
@hashes=[]
# GoToEat大阪のページ(1ページ目)
@url = 'https://goto-eat.weare.osaka-info.jp/?search_element_0_0=2&search_element_0_1=3&search_element_0_2=4&search_element_0_3=5&search_element_0_4=6&search_element_0_5=7&search_element_0_6=8&search_element_0_7=9&search_element_0_8=10&search_element_0_9=11&search_element_0_cnt=10&search_element_1_cnt=18&searchbutton=%E5%8A%A0%E7%9B%9F%E5%BA%97%E8%88%97%E3%82%92%E6%A4%9C%E7%B4%A2%E3%81%99%E3%82%8B&csp=search_add&feadvns_max_line_0=2&fe_form_no=0'
def scraping(page)
# ページを開き、htmlを読み込んで変数htmlに渡す
html = open(@url) {|f| f.read}
charset = "utf8"
# htmlをパース(解析)してオブジェクトを作成
doc = Nokogiri::HTML.parse(html, nil, charset)
doc.xpath('/html/body/div/div[1]/main/section/div/div/ul/li').each { |node|
# データ格納庫であるhashを作成
hash=Hash.new(nil)
keys=[:id,:name,:address,:tel,:open,:close,:category1,:category2]
keys.each {|key| hash.store(key,nil)}
hash.store(:id,@id)
hash.store(:name,node.xpath("p").inner_text)
trs=node.xpath("table").xpath("tr")
address=trs[0].xpath("td").inner_text
address.gsub!("\r\n","")
address.gsub!(/[[:space:]]/,"")
hash.store(:address,address)
hash.store(:tel,trs[1].xpath("td").inner_text)
hash.store(:open,trs[2].xpath("td").inner_text)
hash.store(:close,trs[3].xpath("td").inner_text)
categories=node.xpath("ul").xpath("li")
hash.store(:category1,categories[0].inner_text) if categories[0]
hash.store(:category2,categories[1].inner_text) if categories[1]
@id+=1
@hashes << hash
CSV.open("GoToEatOsaka.csv", "a", headers: hash.keys) {|csv|
csv << hash.values
}
}
# 次のページを探します
as=doc.xpath("/html/body/div/div[1]/main/section/div/div/div[2]").xpath("a")
as.each{|a|
content=a.get_attribute("title")
if content=="Page #{page}" then
puts page
@url=a.attribute("href")
break
end
}
end
(2..221).each{|page|
scraping(page)
}
実行結果
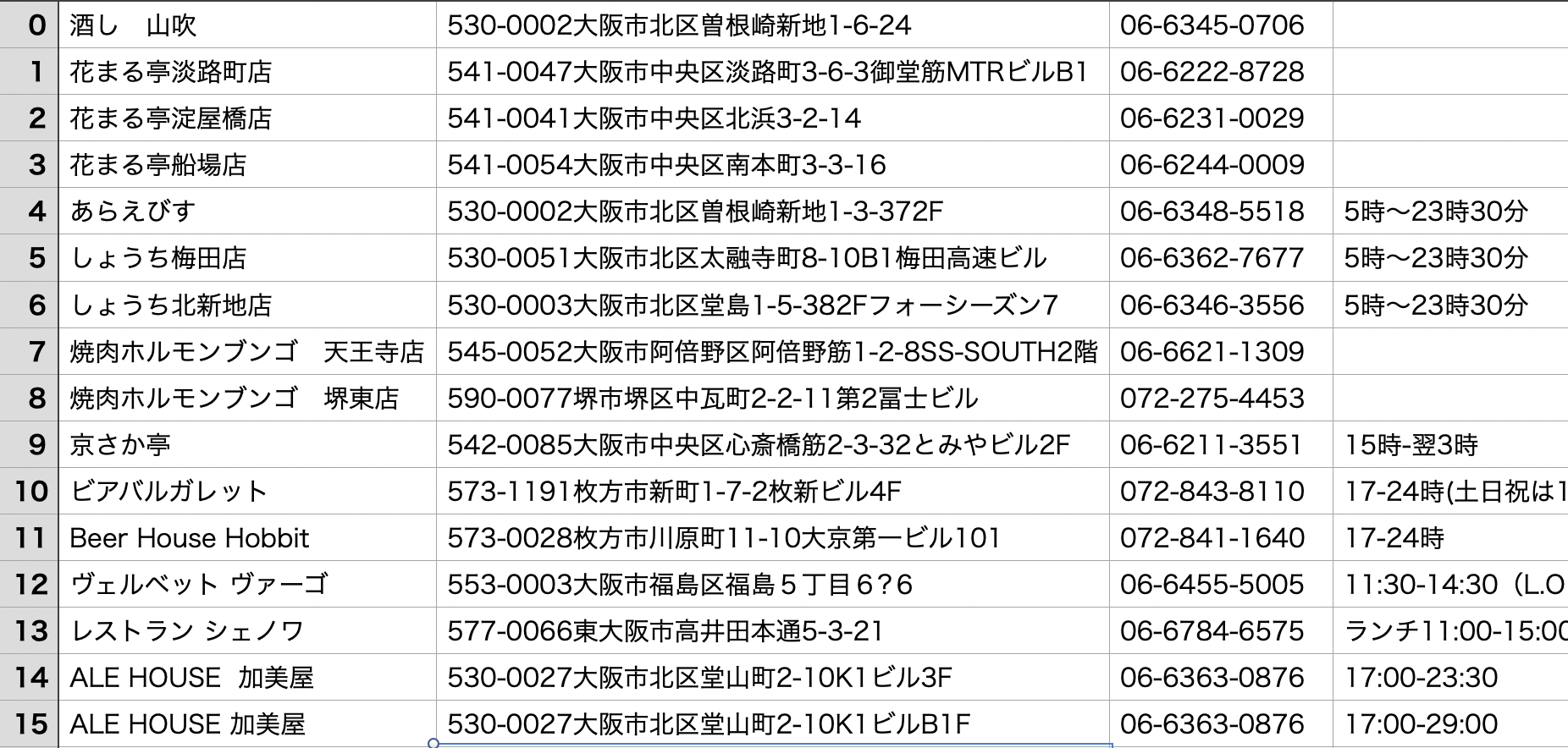
いい感じにcsvとして保存できました。