はじめに
はじめまして。Python初心者のYumiと申します。
完全に文系で、プログラミングのプの字も統計学のとの字もかじった事のなかった、しがないアラフォー女です。
手に職というものもなく、なんとなーくで生きてきたのですが、この辺りで何か一念発起せねばならんなと思い、Pythonを勉強することに決めました。
心折れつつ右往左往している様をありのままにお届けします。同じように四苦八苦している、初心者のあなたのもとに届けば嬉しいです。
(諸先輩方におかれましては、「こういう間違い、昔やったなあ」と暖かく見ていただければと思います。)
このブログはAidemy Premiumのカリキュラムの一環で、受講修了条件を満たすために公開しています
概要
- Spotify APIを使ってヒット曲を予想・分析できるのか?
- 仮説① 季節と相関する
- 仮説② 気温と相関する→気象庁データ
- 仮説③ 株価と相関する→pandas-datareader
- 機械学習でヒット曲を当てられるか
まずテーマ選びから詰まっていたのですが、ふと音楽を聞いている時に使っているSpotifyを見て、APIを使ってみたい!と思ったのが動機です。
全くの初心者にも敷居が低く感じられるように、というコンセプトのもと書き進めていきます。
データ収集
Spotifyチャートからcsvを取得する
より日本の週間ランキングチャートに移動。
2022/10/1〜2023/9/28間のチャート(csv)52週分を取得(直接ダウンロードできます)。
googleドライブの'weeklydata'フォルダに格納し、それを利用していきます。
googleドライブの利用
from google.colab import drive
drive.mount('/content/drive')
実行&許可するとgoogleドライブにマウントできます。
取得したcsvにどんな情報が入っているか、適当に1つ抜き出して確認してみます。
import pandas as pd
#googleドライブの中のcsvを読み込みます
rank0105_df = pd.read_csv('drive/My Drive/weeklydata/regional-jp-weekly-2023-01-05.csv')
print(rank0105_df)
print(rank0105_df.dtypes)
print(rank0105_df.columns.values)
rank uri artist_names \
0 1 spotify:track:49F3htNmwzPKFycPdOrDvf OFFICIAL HIGE DANDISM
1 2 spotify:track:3khEEPRyBeOUabbmOPJzAG Kenshi Yonezu
2 3 spotify:track:4IfrM44LofE9bSs6TDZS49 Tani Yuuki
3 4 spotify:track:2Dzzhb1oV5ckgOjWZLraIB natori
4 5 spotify:track:28MATCYDctW5EiBa2repxb Ado
.. ... ... ...
195 196 spotify:track:0V3wPSX9ygBnCm8psDIegu Taylor Swift
196 197 spotify:track:45YBVp6zMwQZRbUDcPzmMB Kenshi Yonezu
197 198 spotify:track:4qs3qswB84E0VPmM4tsTws Aimer
198 199 spotify:track:26OxcplUEuMjoqkjwVLcPq PornoGraffitti
199 200 spotify:track:0cN6iBeCR7NgeBeTIKjLml Ado
track_name source peak_rank previous_rank \
0 Subtitle IRORI Records 1 1
1 KICK BACK Sony Music Labels Inc. 1 2
2 W / X / Y Valley Records 1 4
3 Overdose なとり 2 3
4 新時代 Universal Music LLC 1 5
.. ... ... ... ...
195 Anti-Hero Taylor Swift 67 189
196 アイネクライネ Universal Music LLC 82 187
197 Deep down Sony Music Labels Inc. 113 152
198 サウダージ Sony Music Labels Inc. 138 -1
199 阿修羅ちゃん Universal Music LLC 53 -1
weeks_on_chart streams
0 13 2775470
1 13 2079021
2 54 1603556
3 17 1589064
4 30 1588536
.. ... ...
195 11 235020
196 83 234427
197 4 234299
198 9 233629
199 55 233558
[200 rows x 9 columns]
rank int64
uri object
artist_names object
track_name object
source object
peak_rank int64
previous_rank int64
weeks_on_chart int64
streams int64
dtype: object
['rank' 'uri' 'artist_names' 'track_name' 'source' 'peak_rank'
'previous_rank' 'weeks_on_chart' 'streams']
これだけでも結構な情報が得られます。
特に重要なのはuriですね。各楽曲のデータにアクセスするためのキーとなります。
データ整理
まずは現在取得済のこれらのデータを整理していきます。
- 1〜20位をA、21〜50位をB、51〜100位をC、101位〜200位をDとして分類→'score'
- それぞれのcsvファイル毎に識別記号→'date'
全てのデータを結合(weekly_all_df)し、ランクでソート、期間内の最高位だけ拾いたいので重複削除します。
#出力用の空データフレームの作成
weekly_all_df = pd.DataFrame()
import glob
import numpy as np
#weeklydataフォルダ内のcsvファイル名を取得しリスト化
csv_files = glob.glob('drive/My Drive/weeklydata/*.csv')
csv_list = []
for csv_name in csv_files :
csv_list.append(csv_name)
#一度リストをprintすると降順になっていたので昇順に並べ直す
csv_list.sort()
#for文を利用してcsvを処理していく
for file in csv_list :
df = pd.read_csv(file)
#csvファイル毎に識別番号(csv_listのインデックス)をつけた列を追加し'date'と名付ける
#あとから考えたら○週目なので'week'の方が良かったですね
df.loc[:,'date'] = csv_list.index(file)
weekly_all_df = pd.concat([weekly_all_df,df],ignore_index = True,axis = 0)
#ランク毎にA〜Dの'score'をつける
conditions = [(weekly_all_df['rank'] <= 20),(weekly_all_df['rank'] <=50),(weekly_all_df['rank'] <= 100)]
choices = ['A','B','C']
weekly_all_df['score'] = np.select(conditions,choices,default='D')
#一旦csvに出力する。index=Falseつけなかったら謎の列発生した
weekly_all_df.to_csv(f'/content/drive/My Drive/songdata/weeklyall.csv',index = False)
ここまでの間にしょっちゅうprintしてます。確認大事。
#重複数の確認
print(weekly_all_df.duplicated(subset = 'uri').sum())
9718
えっ、、、マジかよ、、、
200×52週分で10400件分のデータがあるのですが、ほぼ重複と判明。
確かにランキング下位は以前のヒット曲の可能性高いですね。
それにしても重複しすぎだろう…新しい曲がどんどん入れ替わるということはないということ…
とりあえず重複を除いたデータ(weekly_unique_df)を作成します。
#集計期間内最高位のランクを参照したいので、ランクでソートのち重複削除
weekly_unique_df = weekly_all_df.sort_values(by = 'rank')
weekly_unique_df.drop_duplicates(subset = 'uri',inplace = True)
print(weekly_unique_df['score'].value_counts())
D 307
C 211
A 96
B 68
Name: score, dtype: int64
データが少ない気がする…
1〜20位を取れる楽曲は52週で96曲。なんと狭き門かよくわかります。
ひとまず分析を進めてみます。
仮説① 季節の追加
季節によって特定のワード使った曲が流行ったりとかありますよね。なので相関があるんじゃないかと考えました。
便宜上テレビ局のカウントに倣って、4〜6月(春)、7〜9月(夏)、10月〜12月(秋)、1月〜3月(冬)とします。
反映した列を先ほどのデータフレーム(weekly_unique_df)に追加します。
(あとから考えるとここで追加する意味なかった)
conditions2 = [(weekly_unique_df['date'] <= 12),(weekly_unique_df['date'] <= 25),(weekly_unique_df['date'] <= 38)]
choices2 = ['autumn','winter','spring']
weekly_unique_df['season'] = np.select(conditions2,choices2,default='summer')
仮説② 気温の追加
季節が関係してくるなら気温も関係するのでは?
より東京の2022/10/1〜2023/9/30の日別気温をcsvで取得。
googleドライブに保存して使用します。
#'utf-8' codec can't decode byte 0x83 in position 0: invalid start byte
#と怒られたので、エンコードを入れます
temp_df = pd.read_csv('drive/My Drive/data/data.csv',encoding = 'Shift-JIS')
print(temp_df)
print(temp_df.dtypes)
print(temp_df.columns.values)
ダウンロードした時刻:2023/11/02 03:54:53
NaN 東京 東京 東京
年月日 平均気温(℃) 平均気温(℃) 平均気温(℃)
NaN NaN 品質情報 均質番号
2022/10/1 23.6 8 1
2022/10/2 23.5 8 1
... ...
2023/9/26 24.6 8 1
2023/9/27 25.3 8 1
2023/9/28 27.4 8 1
2023/9/29 26.3 8 1
2023/9/30 25.6 8 1
[368 rows x 1 columns]
ダウンロードした時刻:2023/11/02 03:54:53 object
dtype: object
['ダウンロードした時刻:2023/11/02 03:54:53']
気象庁のcsv、使いづらくない?
とても変なデータだ………ダウンロードした時間バレるの恥ずかしい
なんとか整地して、最終的に週の平均気温(木曜集計)を出していきます(temp_w_df)。
#インデックスを振り直して不要な行をdropします
temp_df.reset_index(inplace=True)
temp_df.drop(range(0,3),inplace=True)
#不要な列もdrop、カラムも新しく名付けます
temp_df.drop(['level_2','ダウンロードした時刻:2023/11/02 03:54:53'],axis=1,inplace=True)
temp_df.rename(columns={'level_0':'date','level_1':'temp'},inplace=True)
print(temp_df.head())
date temp
3 2022/10/1 23.6
4 2022/10/2 23.5
5 2022/10/3 23.0
6 2022/10/4 25.2
7 2022/10/5 19.8
import datetime as dt
#曜日で抽出できるようにしたいので日付をdatetime型に変えます
temp_df['date'] = pd.to_datetime(temp_df['date'],format='%Y-%m-%d')
#temp列を数値に変えます
temp_df['temp'] = pd.to_numeric(temp_df['temp'],errors='coerce')
#日付をindexに変えます
temp_df.set_index('date',inplace=True)
#週毎の平均気温を出します(集計曜日木曜)
temp_w_df = temp_df.resample('W-Thu').mean()
print(temp_w_df.head())
temp
date
2022-10-06 21.366667
2022-10-13 17.071429
2022-10-20 17.671429
2022-10-27 14.885714
2022-11-03 15.300000
weekly_unique_dfに左外部結合します
(再度言いますがここで結合する意味はあんまりなかった)
#結合しやすいようにtemp_w_dfに'key'列を増やしてint型にしておきます
temp_w_df['key'] = range(0,len(temp_w_df.index))
temp_w_df[['key']].astype('int')
#左外部結合
weekly_unique_df = pd.merge(weekly_unique_df,temp_w_df,how='left',left_on='date',right_on='key')
#key列の役目は終わったのでdrop
weekly_unique_df.drop(['key'],axis=1,inplace=True)
仮説③ 株価の追加
完全にイメージですが、景気が良くなるとみんな踊り出したくなるんじゃない?
2023年は久々に日経平均が30,000円を越え、最高値と最低値の差が大きいと思われるので、昨年分よりも相関がわかりやすいかもと思いました。
pandas-datareaderで株価取得
pandas-datareaderを使ってstooqというサイトから日経平均を取得していきます。
#pandas-datareaderをインストール
!pip install pandas-datareader
from pandas_datareader import data
#日経平均を2022/10/1〜2023/9/30の1年分取得します
start = "2022-10-01"
end = "2023-09-30"
stk_df = data.DataReader("^NKX","stooq",start,end)
#始値だけ残す
stk_df = stk_df.drop(['High','Low','Close','Volume'],axis=1)
#先ほどと同じようにto_datetimeを使っていきます
stk_df.reset_index(inplace=True)
pd.to_datetime(stk_df['Date'],format='%Y-%m-%d')
#曜日を追加
stk_df['Day'] = stk_df['Date'].dt.weekday
#木曜日のみ抽出して昇順に並べ直します
stk_thu_df = stk_df[stk_df['Day'] == 3]
stk_thu_df = stk_thu_df.sort_values(by='Date')
#使い終わった'Day'を削除
stk_thu_df = stk_thu_df.drop(['Day'],axis=1)
stk_thu_df.reset_index(inplace=True)
#'index'列ができていたのでそれも削除
#結合を見越してindexをint型、日付をdatetime型→str型に変更
stk_thu_df = stk_thu_df.drop(['index'],axis=1)
stk_thu_df.index.astype('int')
stk_thu_df['Date'] = stk_thu_df['Date'].astype('str')
stk_thu_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 49 entries, 0 to 48
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 49 non-null object
1 Open 49 non-null float64
dtypes: float64(1), object(1)
memory usage: 912.0+ bytes
ん?なんかサイズが合わない
確認のためtemp_w_dfと結合してわざと欠損を作ります
conf_df = pd.merge(temp_w_df,stk_thu_df,how='left',left_on='date',right_on='Date')
date temp Date Open
0 2022-10-06 21.366667 2022-10-06 27137.98
1 2022-10-13 17.071429 2022-10-13 26398.29
2 2022-10-20 17.671429 2022-10-20 26981.75
3 2022-10-27 14.885714 2022-10-27 27407.23
4 2022-11-03 15.300000 NaN NaN
5 2022-11-10 14.628571 2022-11-10 27459.08
:
19 2023-02-16 6.071429 2023-02-16 27654.72
20 2023-02-23 7.828571 NaN NaN
21 2023-03-02 9.900000 2023-03-02 27564.82
:
29 2023-04-27 15.828571 2023-04-27 28340.59
30 2023-05-04 18.642857 NaN NaN
31 2023-05-11 17.600000 2023-05-11 29110.79
:
:
祝日ですね!欠損値を休場直前の日のデータで補充します
#行挿入のために一旦分割
stk_thu_df1 = stk_thu_df.iloc[:4,:].copy()
stk_thu_df2 = stk_thu_df.iloc[4:19,:].copy()
stk_thu_df3 = stk_thu_df.iloc[19:28,:].copy()
stk_thu_df4 = stk_thu_df.iloc[28:,:].copy()
#該当日の株価を確認
print(stk_df[stk_df['Date']=='2022-11-02'])
print(stk_df[stk_df['Date']=='2023-02-22'])
print(stk_df[stk_df['Date']=='2023-05-02'])
#↑で確認したデータを分割後の各データフレームに追加
stk_thu_df1.loc[4] = ['2022-11-02',27678.92]
stk_thu_df2.loc[19] = ['2023-02-22',27265.99]
stk_thu_df3.loc[28] = ['2023-05-02',29278.8]
#再結合
stk_cor_df = pd.concat([stk_thu_df1,stk_thu_df2,stk_thu_df3,stk_thu_df4])
#結合しただけだとindexがおかしいままなのでindexを振り直します
stk_cor_df.reset_index(inplace=True)
#あとで結合することを考えてindexをint型にしておきます
#また'index'できてるのでdrop
stk_cor_df.index.astype('int')
stk_cor_df = stk_cor_df.drop(['index'],axis=1)
これで52週分の木曜日の株価データができました!
weekly_unique_dfに横結合します
(何度も言いますが、ここで結合しなくてもよかった)
weekly_unique_df = pd.merge(weekly_unique_df,stk_cor_df,how='left',left_on='date',right_on=stk_cor_df.index)
Spotify APIの使用
にて自分のIDをもとに登録をしておく必要があります。
アプリ登録までいくとclient_IDとclient_secretが振られますので、それをコード内に記載しなければいけません。
#spoti"py"のインストールが必要です
!pip install spotipy
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
client_id = 'My_id'
client_secret = 'My_secret'
client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret)
spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
何ができるかテスト、Adoさんのアーティスト情報・『唱』の曲情報を取ってみます。
#idはアーティストページのURLの最後にあります
artist_id = '6mEQK9m2krja6X1cfsAjfl' #Adoさん
spotify.artist(artist_id)
{'external_urls': {'spotify': 'https://open.spotify.com/artist/6mEQK9m2krja6X1cfsAjfl'},
'followers': {'href': None, 'total': 3282053},
'genres': ['j-pop', 'japanese teen pop'],
'href': 'https://api.spotify.com/v1/artists/6mEQK9m2krja6X1cfsAjfl',
'id': '6mEQK9m2krja6X1cfsAjfl',
'images': [{'height': 640,
'url': 'https://i.scdn.co/image/ab6761610000e5ebf3bb04995cb61f04936424ee',
'width': 640},
{'height': 320,
'url': 'https://i.scdn.co/image/ab67616100005174f3bb04995cb61f04936424ee',
'width': 320},
{'height': 160,
'url': 'https://i.scdn.co/image/ab6761610000f178f3bb04995cb61f04936424ee',
'width': 160}],
'name': 'Ado',
'popularity': 73,
'type': 'artist',
'uri': 'spotify:artist:6mEQK9m2krja6X1cfsAjfl'}
#各楽曲のURLの最後にあります
track_id = '2tlOVDJ3lQsUxz22vPJ4c4' #『唱』
spotify.audio_features(track_id)
[{'danceability': 0.616,
'energy': 0.975,
'key': 10,
'loudness': -0.425,
'mode': 0,
'speechiness': 0.208,
'acousticness': 0.172,
'instrumentalness': 1.62e-06,
'liveness': 0.143,
'valence': 0.742,
'tempo': 132.054,
'type': 'audio_features',
'id': '2tlOVDJ3lQsUxz22vPJ4c4',
'uri': 'spotify:track:2tlOVDJ3lQsUxz22vPJ4c4',
'track_href': 'https://api.spotify.com/v1/tracks/2tlOVDJ3lQsUxz22vPJ4c4',
'analysis_url': 'https://api.spotify.com/v1/audio-analysis/2tlOVDJ3lQsUxz22vPJ4c4',
'duration_ms': 189773,
'time_signature': 4}]
特に重要視すべきは楽曲の各パラメータでしょうか。
説明変数として使いたいです。
関連がありそうなのはこの辺り
acousticness アコースティック度(0.0〜1.0)
danceability ダンスのしやすさ(0.0〜1.0)
energy 激しさ、強度と活動性(0.0〜1.0)
mode 長調なら1、短調なら0
valance 明るいほど1に近づく(0.0〜1.0)
tempo テンポ、BPM
これらが辞書型で与えられることがわかりました。
視覚化のために情報を集めていきます(chart_an_df)
#'uri'列からtrack_idのみ抜き出します
weekly_unique_df['track_id'] = weekly_unique_df['uri'].str.split(':',expand=True)[2]
#各楽曲のパラメータ情報のみでデータフレームを作ります
chart_an_df = pd.DataFrame()
for track_id in weekly_unique_df['track_id'] :
df = pd.DataFrame.from_dict(spotify.audio_features(track_id))
chart_an_df = pd.concat([chart_an_df,df],ignore_index=True,axis=0)
と、ここで気付くのです。
どう考えてもこっちに仮説の各データを結合すべきやん
………。このまま続行します。
#もう、そのまま移植します
chart_an_df[['week','score','season','temp','Date','Open']] =
weekly_unique_df[['date','score','season','temp','Date','Open']]
紆余曲折ありましたが、これで可視化の準備ができました。
データの可視化
今回はSeabornのpairplotを主に使っていきます。複数項目の散布図を一気に作れるのが利点。
'danceability' 'energy' 'mode' 'acousticness' 'valence' 'tempo' と 'week' 'score' 'season' 'temp' 'Open'に相関がないかを見ていきたいです。
import seaborn as sns
import matplotlib.pyplot as plt
#'score'を色分けして打点
sns.pairplot(chart_an_df,
x_vars = ['week','temp','Open'],
y_vars = ['danceability','energy','acousticness','valence','tempo'],
hue = 'score')
#'season'を色分けして打点
sns.pairplot(chart_an_df,
x_vars = ['week','temp','Open'],
y_vars = ['danceability','energy','acousticness','valence','tempo'],
hue = 'season')
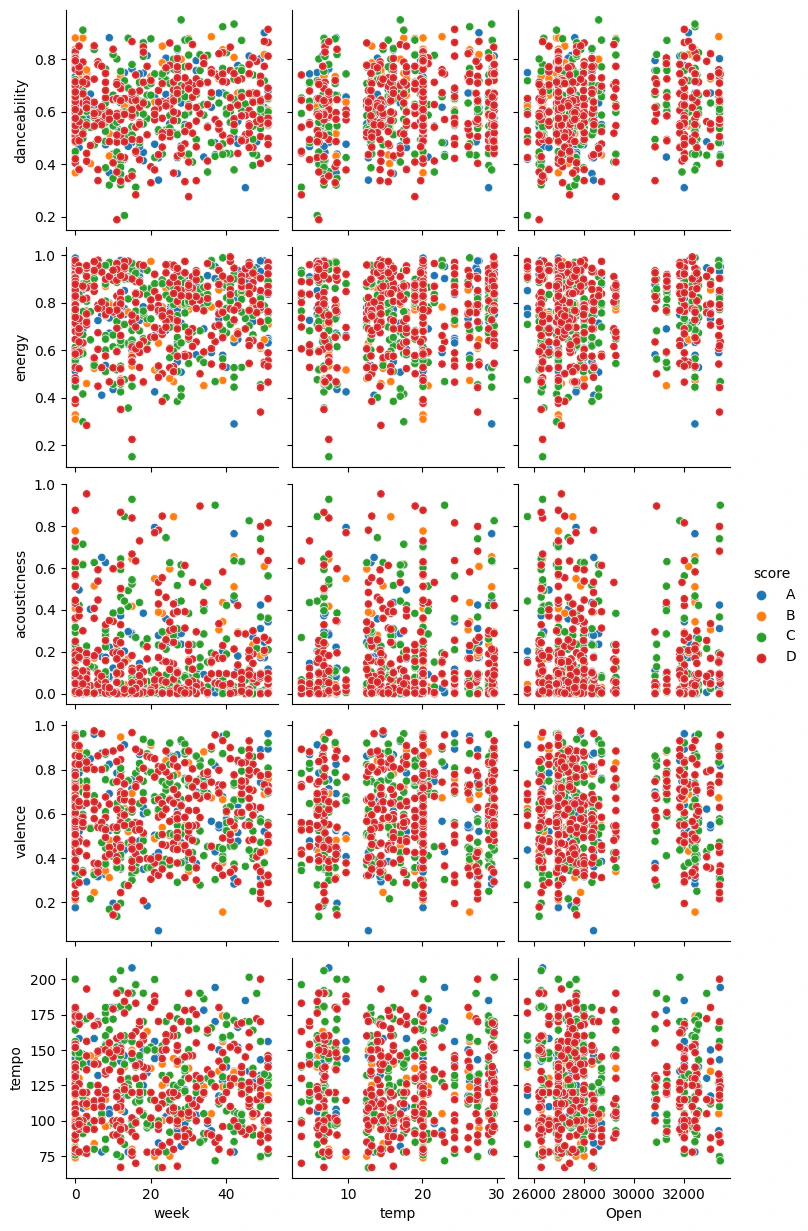
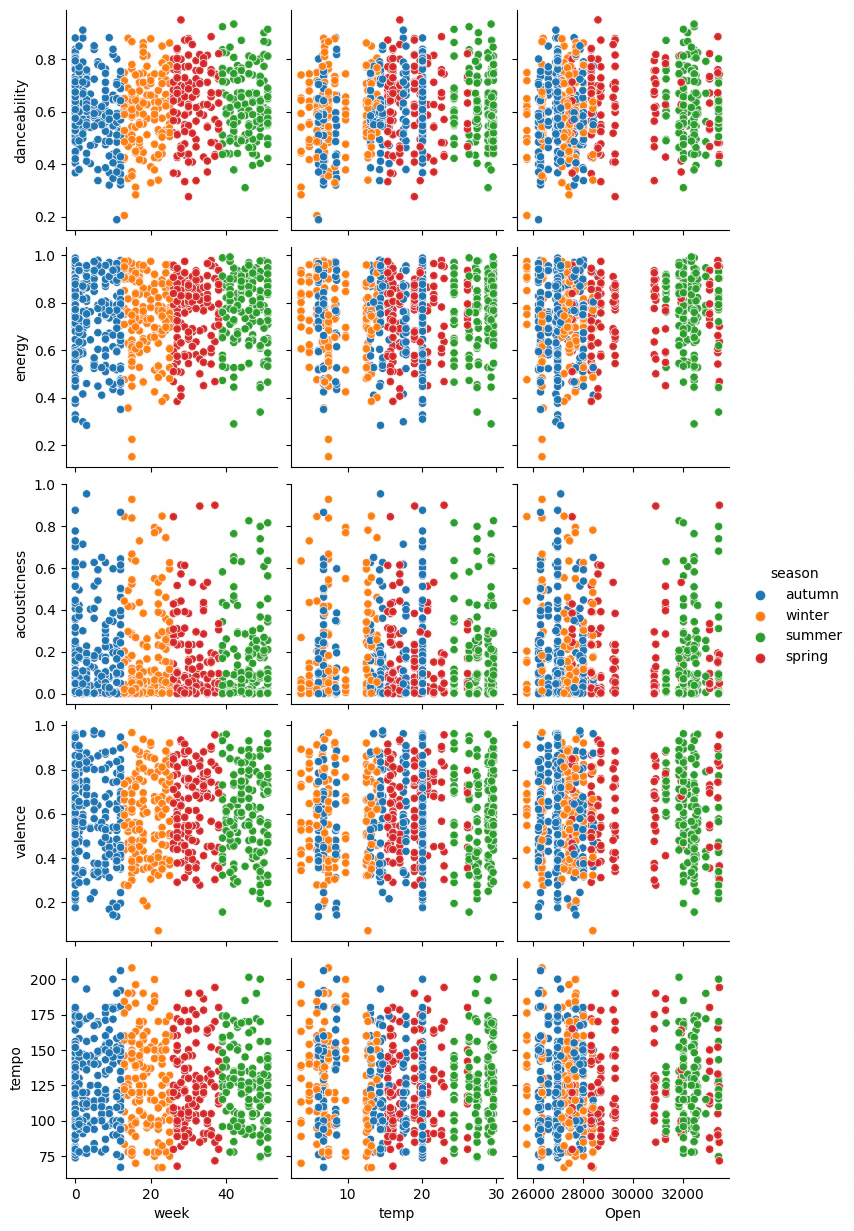
- danceabilityは0.4以上が好まれている
- energyもdanceability同様0.4以上
- どちらかというと激しい曲調が好まれているようだ
- 季節的には秋〜冬にかけてdanceabilityが減少、その後増加する傾向があるが気温との相関ではなさそう→曲提供側として冬曲はおとなしめの曲を出す傾向にあるから?
- valenceはそこまで相関がないが0.2以上、どちらかといえば陽気寄り
- tempoもばらつきがあるが、150程度が多いか
'temp''Open'で空白地帯があるのが気になったため確認します。
fig = plt.figure(figsize=(16,5))
#気温と株価をヒストグラムで確認
ax1 = fig.add_subplot(1,3,1)
ax1.hist(temp_w_df['temp'])
ax1.set_title('temperature')
ax2 = fig.add_subplot(1,3,2)
ax2.hist(stk_cor_df['Open'])
ax2.set_title('stock')
#modeを棒グラフで確認
ax3 = fig.add_subplot(1,3,3)
ax3 = sns.countplot(x='mode',data=chart_an_df)
ax3.set_title('mode')
plt.show()
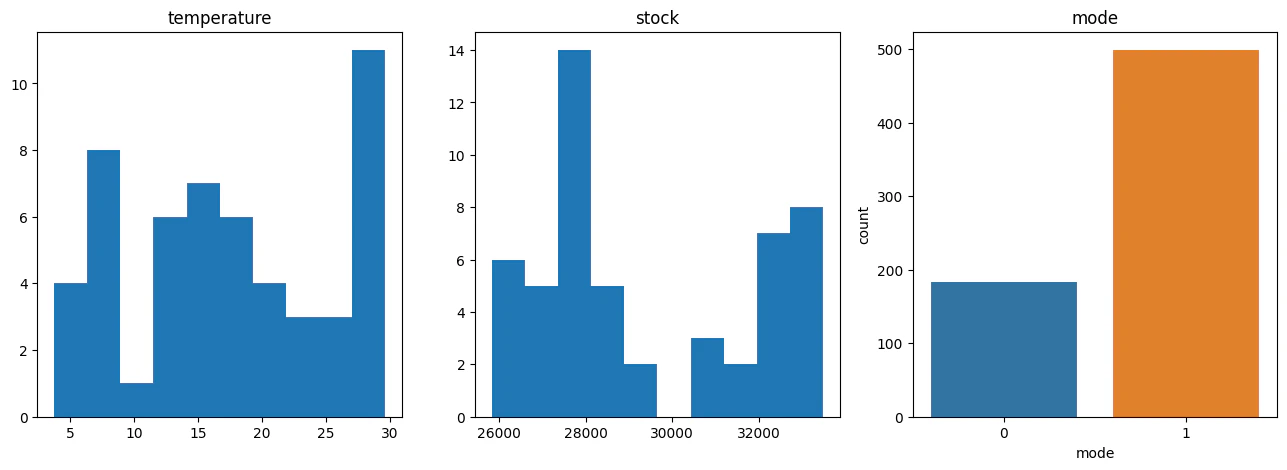
- 長調・短調で言えば長調の方が圧倒的に多い
- 株価の空白地帯は日経平均30,000円の時期がなかったため
- 気温で空白地帯ができているのは、気温10℃付近の時期が少なかったため
ということが読み取れます。
散布図自体がちょっと見辛いのでAB群(チャート50位内)に限定して再度見てみます。
#'score'がA・Bのみを抽出
chart_anab_df = chart_an_df[chart_an_df['score'].isin(['A','B'])]
sns.pairplot(chart_anab_df,
x_vars = ['week','temp','Open'],
y_vars = ['danceability','energy','acousticness','valence','tempo'],
hue = 'score')
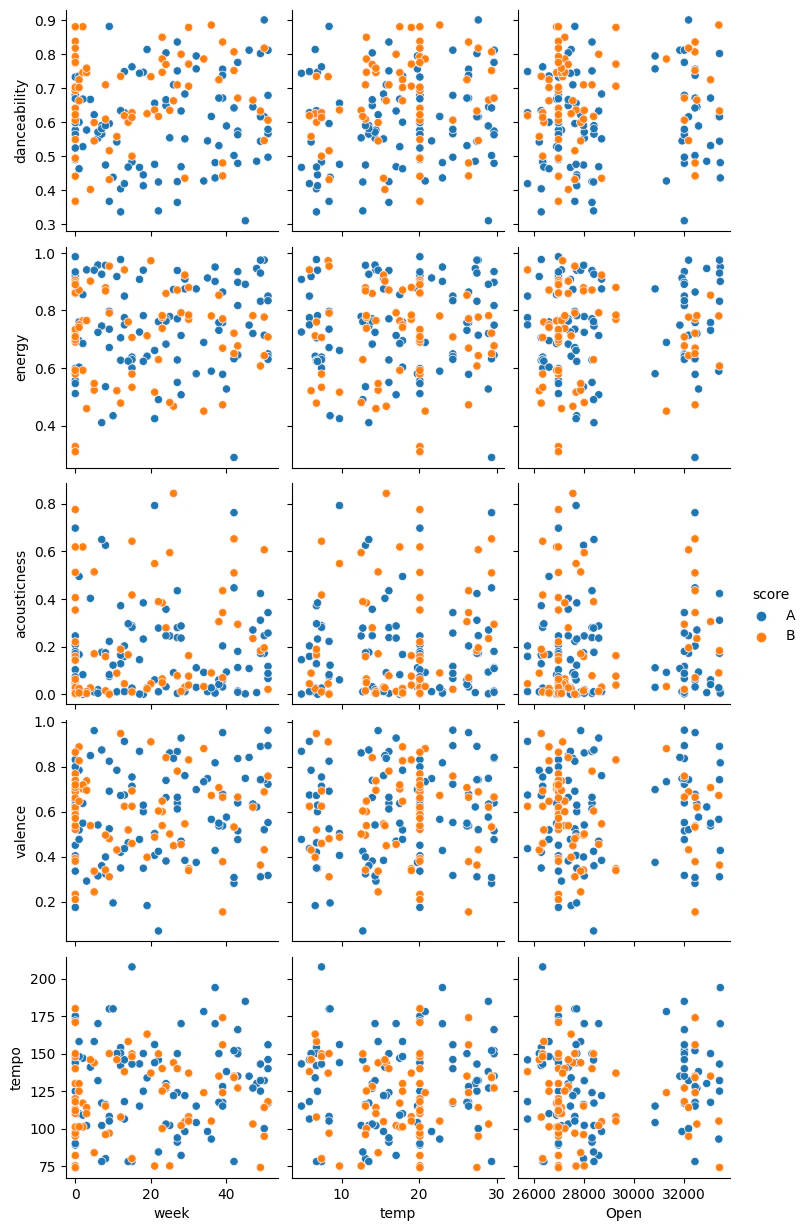
- 0週の集中は省いた方が良さそうです。(データ取得開始日のため、どうしても曲数が集中する)
- dansability,energyが週数を重ねるにつれて緩く右肩あがりになっている。気温上昇にも相関していそう。
- valenceもごく緩く相関しているかな。
- tempoは株価と緩く相関していそう。
- acousticnessは、dansabilityやenergyと負の相関にあるのは間違いなさそうなので省く
教師データとして整えていきます。
#使わない列の削除
chart_ancor_df = chart_an_df.drop(['Unnamed: 0','key','loudness','speechiness',
'instrumentalness','liveness','type','id','uri',
'track_href','analysis_url','duration_ms',
'time_signature','Date','acousticness'],axis=1)
#0週のデータを削除=0週のデータ以外を抽出
chart_ancor_df = chart_ancor_df[chart_ancor_df['week'] != 0]
chart_ancor_df = chart_ancor_df.drop(['week'],axis=1)
#次の段階でstr型が使えなかったので数値に変更します
chart_ancor_df = chart_ancor_df.replace({'spring':1,'summer':2,'autumn':3,'winter':4})
chart_ancor_df = chart_ancor_df.replace({'A':4,'B':3,'C':2,'D':1})
print(chart_ancor_df)
danceability energy mode valence tempo score season temp \
1 0.649 0.683 1 0.381 130.000 4 4 13.957143
2 0.574 0.935 1 0.836 166.008 4 2 29.628571
3 0.577 0.941 1 0.292 101.921 4 3 14.428571
4 0.566 0.850 0 0.722 117.048 4 2 24.328571
5 0.425 0.939 1 0.638 150.015 4 1 16.100000
.. ... ... ... ... ... ... ... ...
676 0.675 0.747 1 0.481 119.975 1 4 7.428571
677 0.637 0.485 1 0.403 109.035 1 4 12.742857
678 0.486 0.766 1 0.417 154.992 1 3 8.400000
680 0.672 0.541 1 0.453 151.985 1 1 22.642857
681 0.707 0.500 1 0.583 129.970 1 1 19.028571
Open
1 27368.62
2 32019.06
3 27097.38
4 32018.64
5 28321.54
.. ...
676 26346.69
677 28385.29
678 27633.96
680 33399.15
681 30909.61
[596 rows x 9 columns]
これで準備ができました。
いよいよ機械学習していきます。
機械学習
今回は最終的に『様々なパラメータを持つ楽曲の』『順位を予想する』ため、分類問題が得意なランダムフォレストを使用したいと思います。
目的変数を'score'、説明変数をそれ以外とします。
ランダムフォレスト
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
#カラム名の表示
print(chart_ancor_df.columns.values)
#学習用とテスト用にデータを分割
train_X = chart_ancor_df.drop(['score'],axis=1)
train_y = chart_ancor_df['score']
(train_X,test_X,train_y,test_y) = train_test_split(train_X,train_y,test_size=0.3,random_state=42)
random_forest = RandomForestClassifier(max_depth=10,n_estimators=15, random_state=42)
random_forest.fit(train_X, train_y)
#特徴量の重要度
print(random_forest.feature_importances_)
y_pred = random_forest.predict(test_X)
trainaccuracy_random_forest = random_forest.score(train_X, train_y)
#精度
print('TrainAccuracy:{}'.format(trainaccuracy_random_forest))
accuracy_random_forest = accuracy_score(test_y, y_pred)
print('Accuracy:{}'.format(accuracy_random_forest))
[0.17076721 0.18475234 0.02893315 0.17395332 0.18158803 0.0349908
0.10950091 0.11551425]
TrainAccuracy:0.920863309352518
Accuracy:0.3743016759776536
4割…?
かなり精度が低い
ハイパーパラメータを調整してもこれ以上にはなりませんでした。
特徴量の重要度を見るに、'mode'と'season'はあまり影響しないことがわかりました、が、如何せん精度が低い。
一旦心が折れましたが、精度を上げるにはと思考します。
仮説:データ整理の際に危惧していた通り、データ数が少ないのでは。
リトライ
重複データありで作り直します(chart_all_df)
#謎の'Unnamed: 0'ができていたので一緒にdrop
chart_all_df = weekly_all_df.drop(['Unnamed: 0','rank','artist_names','track_name','source',
'peak_rank','previous_rank','weeks_on_chart','streams'],axis=1)
#各楽曲のパラメータは重複なしデータを作る際に取得しているので、それを利用して左外部結合します
#spotifyAPIから全部取得しようとしたら制限かかりました。10,400件だもんな
chart_all_df = pd.merge(chart_all_df,chart_an_df,how='left',on='uri')
#'season'を最初から数字で振ります
conditions3 = [(chart_all_df['date'] <= 12),(chart_all_df['date'] <= 25),(chart_all_df['date'] <= 38)]
choices3 = [3,4,1]
chart_all_df['season'] = np.select(conditions3,choices3,default=2)
#'temp'を左外部結合
temp_w_df['key'] = temp_w_df.index
temp_w_df = temp_w_df.drop(['date'],axis=1)
chart_all_df = pd.merge(chart_all_df,temp_w_df,how='left',left_on='date',right_on='key')
#'Open'を左外部結合
chart_all_df = pd.merge(chart_all_df,stk_cor_df,how='left',left_on='date',right_on=stk_cor_df.index)
#不要な列削除(新しくできてる不要な列も一緒に)
chart_all_df = chart_all_df.drop(['uri','date','Unnamed: 0_x','key_x',
'loudness','speechiness','acousticness',
'instrumentalness','liveness','type','id',
'track_href','analysis_url','duration_ms',
'time_signature','key_y','Unnamed: 0_y','Date'],
axis=1)
#'score'を数値に
chart_all_df = chart_all_df.replace({'A':4,'B':3,'C':2,'D':1})
今までの積み重ねがあるので、サクッと作ることができました。
ランダムフォレストにデータを渡します。
print(chart_all_df.columns.values)
#別のセルで実行したのでtrain_X・train_yのままでいけたけど、本来は別名を当てるべき
train_X = chart_all_df.drop(['score'],axis=1)
train_y = chart_all_df['score']
(train_X,test_X,train_y,test_y) = train_test_split(train_X,train_y,test_size=0.3,random_state=42)
random_forest2 = RandomForestClassifier(max_depth=25,n_estimators=80, random_state=42)
random_forest2.fit(train_X, train_y)
print(random_forest2.feature_importances_)
y_pred = random_forest2.predict(test_X)
trainaccuracy_random_forest2 = random_forest2.score(train_X, train_y)
print('TrainAccuracy:{}'.format(trainaccuracy_random_forest2))
accuracy_random_forest2 = accuracy_score(test_y, y_pred)
print('Accuracy:{}'.format(accuracy_random_forest2))
['score' 'danceability' 'energy' 'mode' 'valence' 'tempo' 'season' 'temp'
'Open']
[0.17016471 0.16592873 0.01521319 0.16867085 0.16955531 0.05301018
0.13359326 0.12386376]
TrainAccuracy:1.0
Accuracy:0.8483974358974359
かなり精度が向上しました!やはりデータ数不足だったか…
'mode'があまり重要でないのは変わらずですが、'season'の重要度は少し上がりました。
前回の教師データでは、重複削除をした際に季節(週)で偏りが出てしまったのかもしれません。
検証
今回の教師データに入っていない、2023/10/5付の20位以内チャート(chart_test_df)で検証します。
気温22.4℃、株価30,994.67円、季節は秋
予測値で「4」が出れば正解です。
#chart_test_dfの作成 & データ整理
#20位以内のデータのみ抽出
pd1005_df = pd.read_csv('drive/My Drive/regional-jp-weekly-2023-10-05.csv')
test_df = pd1005_df[pd1005_df['rank'] <= 20]
#spotify APIより楽曲パラメータを取得
test_df['track_id'] = test_df['uri'].str.split(':',expand=True)[2]
chart_test_df = pd.DataFrame()
for track_id in test_df['track_id'] :
df2 = pd.DataFrame.from_dict(spotify.audio_features(track_id))
chart_test_df = pd.concat([chart_test_df,df2],ignore_index=True,axis=0)
#不要な列を削除
chart_test_df = chart_test_df.drop(['key','loudness','speechiness',
'instrumentalness','liveness','type','id','uri',
'track_href','analysis_url','duration_ms',
'acousticness','time_signature'],axis=1)
#季節・気温・株価を追加
chart_test_df['season'] = 3
chart_test_df['temp'] = 22.4
chart_test_df['Open'] = 30994.67
#'score'列は作りません
ねえ、今更気づいたんだけどこのドロップするリストを別口で作っておいたら良かったんじゃない?
反省点も見つかったところで、検証データを2回目のランダムフォレストに渡してみます。
y_pred = random_forest2.predict(chart_test_df)
print(y_pred)
[4 4 1 4 4 1 3 1 2 4 4 1 1 4 4 4 4 4 4 2]
12/20、6割は正解しています。
散布図で見た時にはびっくりするぐらい緩い相関だと思ったのですが、なんとかここまで漕ぎつけることができました。ランダムフォレストさんすごい!
(この結果を見て思いついた仮説④はアーティストの認知度との相関なのですが、今回は割愛させていただきます。)
ちなみに最初に作ったモデルだとこうなります。
y_pred = random_forest.predict(chart_test_df)
print(y_pred)
[1 1 2 1 1 1 4 1 1 1 1 1 4 1 4 2 4 1 4 1]
やはり精度が低い。データ数だったんでしょうね。
総括
ここに書いたミス等はごく一部で、実際はもっとトライ&エラーを繰り返しています。
今回の作成を経て、データクレンジングとデータ数の重要性に改めて気付くことができました。本番よりも事前準備が大事なのはどの仕事も一緒ですね。
また、こまめなバックアップやデータ自体の確認が必要だったり、色々な経験を得ました。諦めない心大事。
やってみたい事はまだまだあるので、自己研鑽を積んでいきたいと思います。
最後に。
0からのPythonでも、ここまでできるぞ!
と叫ばせていただき、筆を置かせていただきます。
ここまでお付き合いいただき、ありがとうございました。