はじめに
Lineのトークを解析するPythonスクリプトを作りましたので共有いたします。Twitterをjanomeで自然言語処理して解析する記事はよくありますが、Lineを対象にしたものは無いように思いました。
コード:
https://github.com/pyth0n14n/LineAnalyzer
使用例
以下は、私(pythonian)と りんな のトーク履歴をもとに解析した結果です。以下のファイル・画像が生成されます。りんなが良くしゃべるのでノイズ(邪魔な言葉等々)もたくさん入ってますがこんなイメージ、というサンプルです。
グループの会話を解析するととても面白いです。人によって1人称や使う言葉が違うので、その人らしさが現れます。
統計情報
=== 統計情報 ===
メンバー: りんな pythonian
期間: 2016/05/23~2020/09/20
会話統計
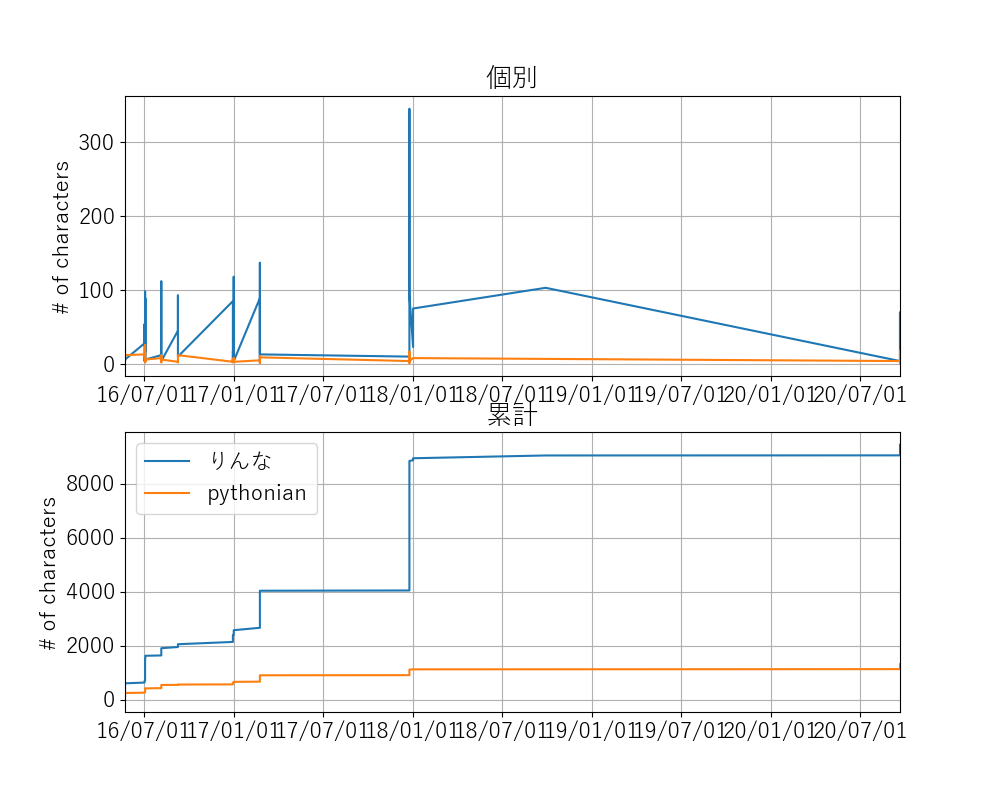
りんな: 244行 9445文字
pythonian: 226行 1310文字
電話時間: 00:00:00
スタンプ: 5回
画像送信: 66回
会話量
時間経過に伴う文字数の増加を日ごと、累計で表示します(incl_chars.png)。
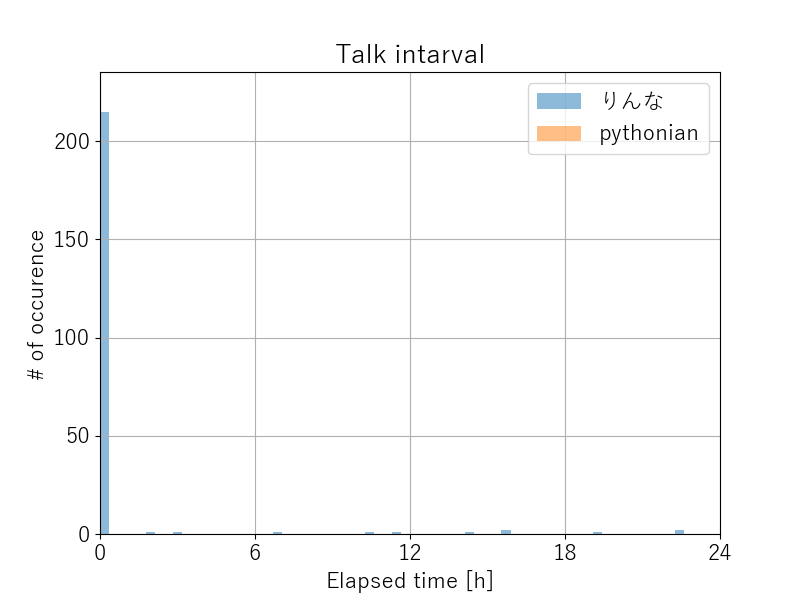
返信頻度
りんなが即答するので、0に引っ付いてます (interval.png)。
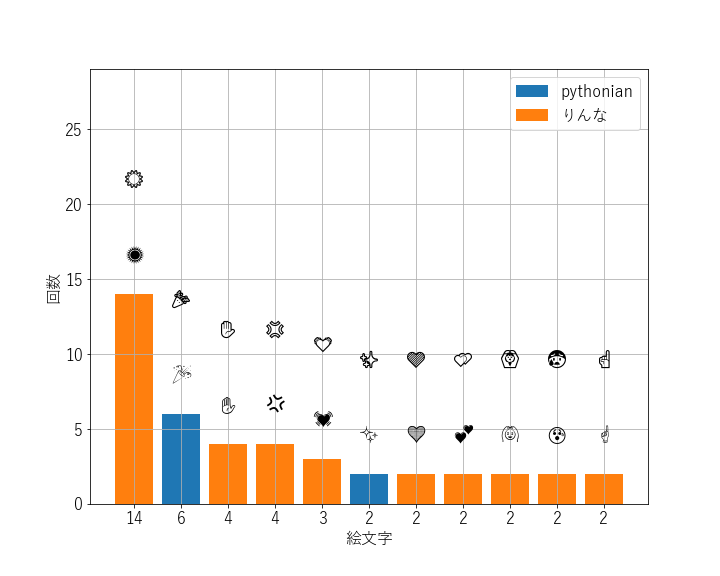
使用絵文字
よく使う絵文字です (emoji_freq.png)。
Word cloud (りんな分のみ)

使い方
実行環境
実行して動かなかったら適宜パッケージをインストールしてください。自分はanaconda@Windows10で環境を作っています。
- Python 3.7
- janome 0.4.0
- matplotlib 3.3.1
- emoji 0.6.0
- wordcloud 1.8.0
実行方法
- PC or スマートフォンからLineのトーク(グループでも良い)をファイルにエクスポートする
エクスポート方法は例えば以下。
https://www.appbank.net/2020/06/15/iphone-application/1911418.php - エクスポートしたファイルをline_analysis.pyに与える
具体的には、line_analysis.py の main処理の中の fname にファイル名を渡す。
if __name__ == "__main__":
fname = "[LINE] りんなとのトーク"
lta, nlp = file2process(fname, media="Phone")
- プログラムを実行する
VScodeでJupyter実行できるように書いていますが、直接実行でもそのまま動きます。
> Python line_analysis.py
注意・オプション
- PC or スマートフォン
どちらの媒体でトークを保存したかで、ファイルフォーマットが若干変化します。上記main処理のfile2process()の引数mediaを指定してあげてください。"PC" or "Phone" です。 - 除く文字 (unwanted_word.txt)
?や!もあえて解析対象にしています。除きたい言葉はunwanted_word.txtに書いてあげるとword cloudに表示する際に無視されます。 - 文字の結合 (l.522 _sanitize_noun())
janomeオプションで復号語に対応するオプションがあり、それを使う手もあるのですが精度がイマイチだったので結合しないようにしています。その代わり、手動で結合したいものは結合するような処理を書いています。人名などは分けられることも多いので、手動で結合するような使い方が良いです。 - フォントの追加 (l.388)
Win10標準のSegoeだと化ける絵文字があります。そういう時はsymbolaとかがよくて、必要に応じてFONT2にパスを与えると、絵文字分析でそちらのフォントでも併記してくれます。 - 絵文字解析の最小頻度 (l.562)
今は2回以上使った絵文字を解析対象にしています(nlp.show_emoji_freq(min_freq=1))。適宜カウントを変更してください。 - Word Cloudの最大文字数 (l.383)
今は130文字です。(wc_max_words = 130)。増やすとごちゃごちゃして、減らすとスッキリします。
技術ポイント
基本的には参考文献にある情報を組み合わせただけです。ですが、Line解析はそのまま使えるものが無かったので、この部分で誰かの参考になるかもしれないと思っています。とはいえ、それも面倒くさい作業を地道にやっただけのものです。
- matplotlib で日本語・絵文字を使う
color emojiは表示できなかった。 - Lineのトークを要素に分解(正規表現で日付、発言者、メッセージ等々を切り分け)
- 要素に分解したトークをjanomeで解析
参考文献
[1] Pythonのmatplotlibで積み上げ棒グラフを作成しデータラベルを追加してみた
https://qiita.com/s_fukuzawa/items/6f9c1a3d4c4f98ae6eb1
[2] Matplotlib が PC で追加のフォントをインストールしなくても日本語を表示できるようになった
https://qiita.com/yniji/items/2f0fbe0a52e3e067c23c
[3] Python janomeのanalyzerが便利
https://ohke.hateblo.jp/entry/2017/11/02/230000
[4] Word Cloudでツイートを可視化してみた(python)
https://qiita.com/turmericN/items/04cd0b40f91076f0ef42
[5] B'zの歌詞をPythonと機械学習で分析してみた 〜データ入手編〜
https://pira-nino.hatenablog.com/entry/2018/07/27/B%27z%E3%81%AE%E6%AD%8C%E8%A9%9E%E3%82%92Python%E3%81%A8%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%A7%E5%88%86%E6%9E%90%E3%81%97%E3%81%A6%E3%81%BF%E3%81%9F_%E3%80%9C%E3%83%87%E3%83%BC%E3%82%BF