はじめに
昨今のAI 事情からVMware としてもAI に関連する製品アップデートを多数していて、その1つが今回ご紹介するVMware Greenplum です。歴史としては長い製品ですが、様々な買収を経て、様々なブランドの変更を経て、今はTanzu ファミリーの一員となっています。一言でいうとスケーラビリティの高いPostgreSQL なのですが、AI 周りの機能の追加がされており、改めてVMware としても力を入れている製品になります。
本記事では、アーキテクチャや実画面を見ながら、Greenplum がどういうものなのかを簡単にご紹介します。なお、Greenplum はOSS 版と商用版が提供されており、本記事では商用版を前提としますが、OSS 版と基本的な機能は変わりません。
Greenplum の概要
概要については下記のブログで非常によくまとまっているのでご一読ください。
https://blogs.vmware.com/vmware-japan/2023/07/big-data-and-attack-on-greenplum.html
Greenplum は大きく分けて2種類のコンポーネントから構成されています。1 つがマスター(Greenplum7 ではコーディネーターと呼ばれています)と呼ばれるコンポーネントで、ここにはGreenplum のメタデータを格納したり、SQL クエリのプランニングや実行をしたりします。もう1 つがセグメントと呼ばれるコンポーネントで、ここにはGreenplum の実際のデータが格納されます。
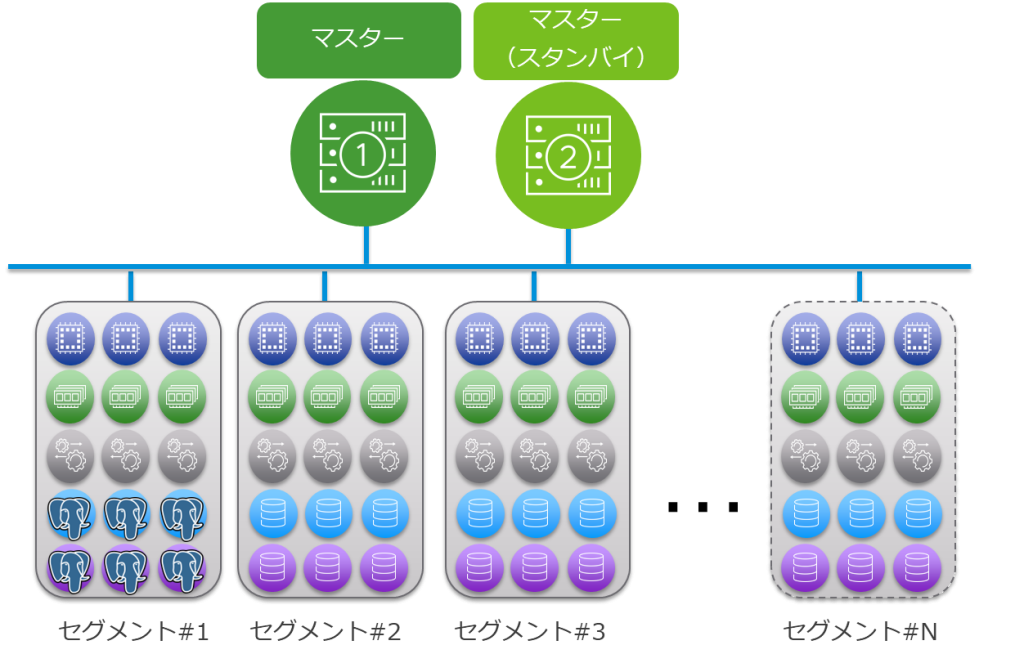
ユーザーはマスターに対してSQL クエリを発行することで、Greenplum に対してクエリを実行します。マスターはクエリを受け取ると、セグメントホストに対してクエリを分散実行します。セグメントはクエリを受け取ると、自身が保持しているデータに対してクエリを実行し、結果をマスターに返します。マスターはセグメントからの結果を受け取り、最終的な結果をユーザーに返します。なお、マスター(スタンバイ)はその名の通りマスターを冗長構成にした場合のコンポーネントです。
実際にデプロイする場合は、可用性やスケーラビリティを考慮したうえで冗長構成やセグメントの台数を決めるわけですが、デプロイをちょっと試してみたい、ということであれば、マスターは1 台、セグメントも1 台から構成できます。しかしながら、セグメントが1 台だと、Greenplum の特徴である並列処理が体験できないので、最低でも2 台以上はデプロイすることをお勧めします。
ちなみに、従来のGreenplum では、データベースに書き込んだデータの冗長化を、Greenplum のレイヤで実現していました。つまり、セグメント1 つに対して、もう1つの冗長化用のセグメントが必要でした。Greenplum を物理サーバーで構成することも多かったため、結果的に必要なリソースが大きくなり、大規模な構成になりがちでした。
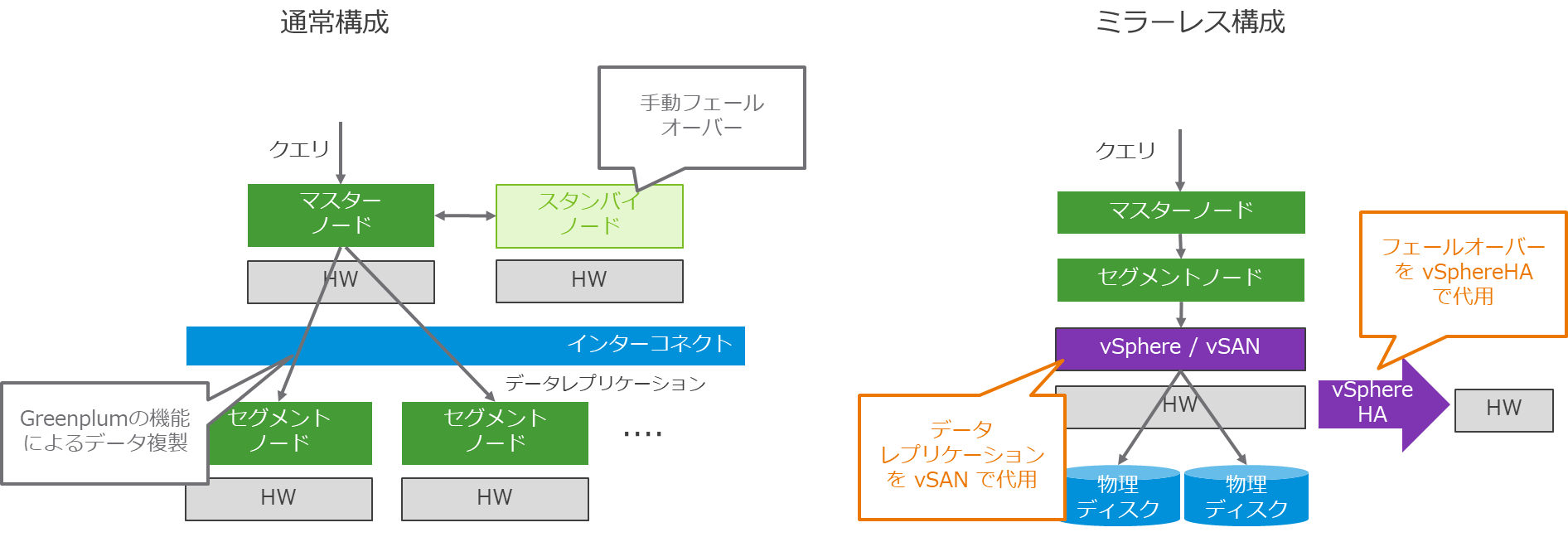
Greenplum 6.21 からサポートされたミラーレス構成は、vSphere とvSAN を活用して、仮想化の機能を活用しながら、より柔軟かつ少ないリソースで構成できるようになりました。
つまり、vSphere のHA の機能を活用することで、ハードウェア障害等でマスターやセグメントがダウンした場合には自動的に別ホストでそれらを再起動することができます。また、vSAN の機能を活用することで、データをセグメントホストのGreenplum のレイヤではなくストレージのレイヤで、すなわちvSAN のストレージポリシーで自動的なデータの冗長化を実現できます。冗長化のためにセグメントを二重化する必要がないため、VMware のサーバーとストレージの仮想化の強みを生かしながら、より広範囲のお客様のニーズを満たすことができるようになりました。
デプロイ方法
下記ドキュメントをご参照ください。
Greenplum7:
https://docs.vmware.com/en/VMware-Greenplum/7/greenplum-database/install_guide-install_gpdb.html
Greenplum6:
https://docs.vmware.com/en/VMware-Greenplum/6/greenplum-database/vsphere-index.html
vSphere 上にデプロイすることを前提に考えると、Greenplum6 とGreenplum7 はデプロイ方法が大きく異なります。Greenplum6 の場合はかなり構成が全体的にFix されていたというか、OVA を使ったインストール方法になるのですが(実は以前はいろいろ手順を踏んだうえで最終的にTerraform を使ってデプロイしていました)、Grenplum7 ではvSphere と疎結合になり、パッケージマネージャを使ったより一般的なインストール方法になりました。本記事を書くうえでは諸々の都合上Greenplum6 を使っていますが、AI 系の拡張、例えばpgvector やpostgresml のサポートがGreenplum7 でのみサポートとなるため、今から構築するのであればGreenplum7 をお勧めします。
補足 gpssh について
Greenplum の大きな特徴は複数のセグメントが集まって1 つのPostgreSQL DB を構成していることにあり、それゆえに例えばパッケージをすべてのセグメントでインストールするなど、各セグメントの整合性を取ることが重要です。その中核の仕組みがgpssh なのですが、これは要するにssh をgreenplum の各セグメントホストで同時に実行するというものです。下記スクリーンショットのように、gpssh で各セグメント同時にecho hostname を実行するといった感じです。
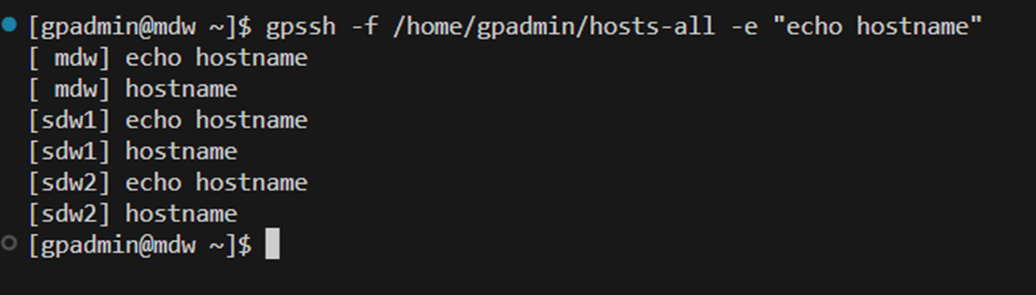
gpssh は基本的なコマンドなのと、インストール後の動作確認など色々用途があるため、概念を事前に把握しておくと役に立ちます。ちなみに実装は下記リンク先にあります。
https://github.com/greenplum-db/gpdb/blob/main/gpMgmt/bin/gpssh
Greenplum にデータを入れてみよう
さて、デプロイが完了したら実際にデータベースを操作してみましょう。マスターにログイン後、下記コマンドでGreenplum に接続します。
psql postgres
テーブルを作成します。
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR(50),
price DECIMAL(10, 2),
category VARCHAR(50)
);
任意のデータを作成します。ここでは、スーパーマーケットの売り物を想定してデータを作成してみました。
INSERT INTO products (product_id, product_name, price, category)
VALUES (1, 'りんご', 150, '果物'),
(2, 'バナナ', 100, '果物'),
(3, 'みかん', 200, '果物'),
(4, 'ピーマン', 100, '野菜'),
(5, 'キャベツ', 200, '野菜'),
(6, 'トイレットペーパー', 300, '日用品'),
(7, 'メロン', 1000, '果物'),
(8, '洗剤', 200, '日用品'),
(9, 'もやし', 30, '野菜'),
(10, 'ごみ袋', 200, '日用品');
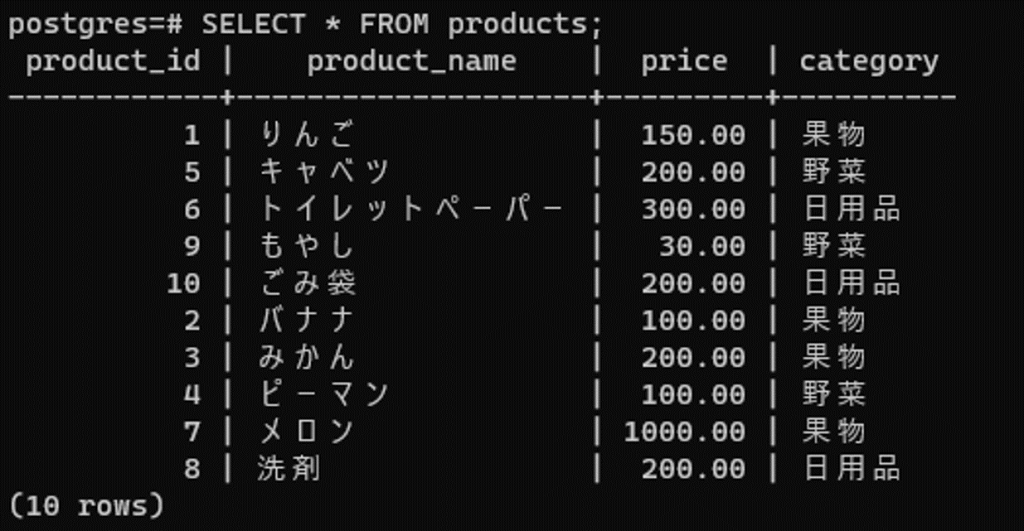
作成したテーブルとデータを表示します。
SELECT * FROM products;
Greenplum は自動的にセグメント間でデータを分散させますが、あるデータがどのセグメントにあるかはgp_segment_id を確認することで分かります。
SELECT gp_segment_id, product_id, product_name, price, category
FROM products;
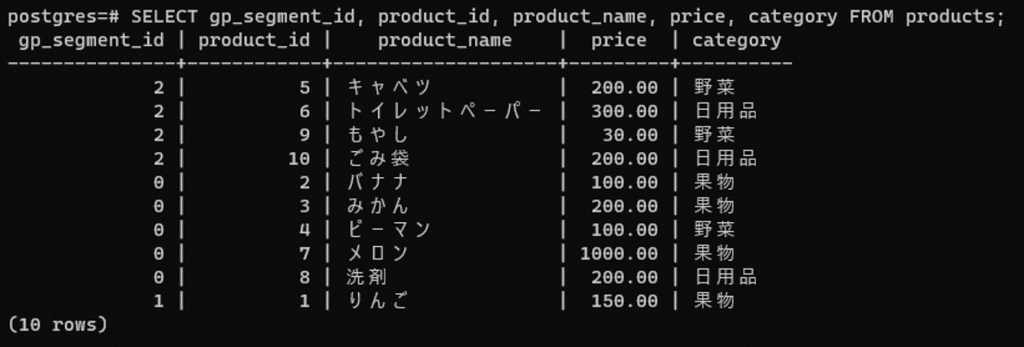
このスクリーンショットからは、gp_segment_id=0 (sdw1) にバナナ、みかん、ピーマン、メロン、洗剤のデータが、gp_segment_id=1 (sdw2) にりんごのデータが、gp_segment_id=2 (sdw3) にキャベツ、トイレットペーパー、もやし、ごみ袋のデータが格納されていることが分かります。
テーブルを削除します。
DROP TABLE products;
さて、次にカテゴリでデータを分散させてみます。ポイントはDISTRIBUTED BY (category) 句で、これはGreenplum 特有の表記となりますが、その名の通りcategory に基づいてデータを分散させるという宣言になります。つまり、ここではcategory として果物、野菜、日用品がありますが(メロンが果物か野菜かについてはここでは議論しません)、そのcategory が同じであれば、同じセグメントに配置する、ということになります。この分散設定がキモで、連結などの処理が高頻度で発生するデータ同士はなるべく同じホストに配置する、などの工夫をすることでクエリのパフォーマンスを上げることができます。
CREATE TABLE products (
product_id INT,
product_name VARCHAR(50),
price DECIMAL(10,2),
category VARCHAR(50)
) DISTRIBUTED BY (category);
INSERT INTO products (product_id, product_name, price, category)
VALUES (1, 'りんご', 150, '果物'),
(2, 'バナナ', 100, '果物'),
(3, 'みかん', 200, '果物'),
(4, 'ピーマン', 100, '野菜'),
(5, 'キャベツ', 200, '野菜'),
(6, 'トイレットペーパー', 300, '日用品'),
(7, 'メロン', 1000, '果物'),
(8, '洗剤', 200, '日用品'),
(9, 'もやし', 30, '野菜'),
(10, 'ごみ袋', 200, '日用品');
同様にデータの配置を確認してみます。
SELECT gp_segment_id, product_id, product_name, price, category
FROM products;
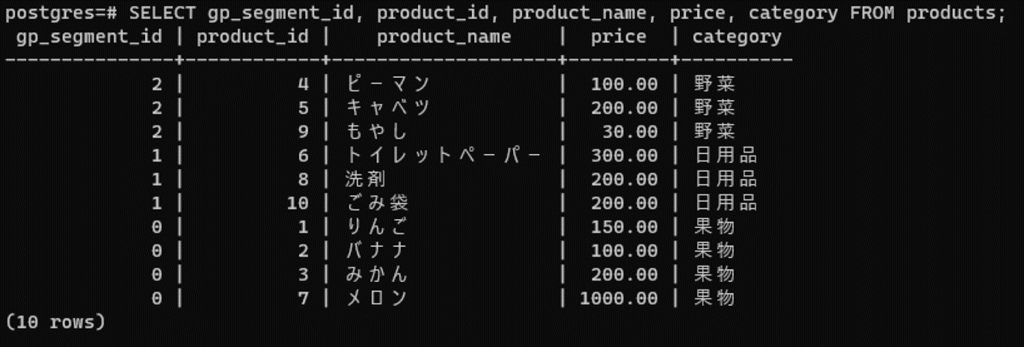
今度は果物カテゴリに属するデータがすべてsdw1 に、日用品カテゴリがsdw2 に、野菜カテゴリがsdw3 に格納されていることが分かります)。最初に指定した通り、カテゴリでデータを分散させることができました。
最後にテーブルを削除します。
DROP TABLE products;
以上でGreenplum の基本的な仕組みはご理解いただけたでしょうか。ここでは、マスターからクエリを発行し、実際にセグメント間でデータが確かに分散されて書き込みされていることを確認しました。
まとめ
本記事では、アーキテクチャや実画面を見ながら、Greenplum がどういうものなのかを簡単にご紹介することで、実際にどのように並列処理が実装されているかの感覚を掴んでもらうことを目的としました。次のステップとしては、実際に様々な拡張、例えばpgvector やpostgresml を使ってRAG システムを作ってみるのも面白いかもしれません。ちなみにもしpostgresml だけを試したい場合は、実は下記から無償で簡単に試すことができます。
話がそれましたが、生成AI ブームの中、企業としての価値の差別化のためにますますデータは重要になってきています。VMware としてはTanzu data Services として様々なデータ戦略を用意しています。それらはすべてOSS をベースとして+α の価値を提供しているため、OSS 版をまずは触っていただき、興味を持った場合は製品版を調べてみるのもよいのではないでしょうか。