はじめに
本記事では、ローカルでLLMサービスを稼働させる、より正確には、ローカル環境にLLMのAPIエンドポイントを構築して利用する際に考慮すべきポイントを整理することを目的としています。複数名での利用を想定してAPI利用としています。NVIDIAの
エンタープライズサーバー向けやプロフェッショナルワークステーション向けには、1枚で100GB以上のGPUメモリを搭載した製品があり、さらに複数枚構成も可能です。そのようなハイエンド構成を選択できる方にとって、本記事の内容はあまり参考にならないかもしれません。
モデル
ローカルLLMを実現する上では、市場で入手可能なGPUのメモリ容量が実質的な制約となるため、この条件をふまえて各種要素を選定する必要があります。詳しくはハードウェアのセクションにGPUメモリ量も含めた比較表を記載しています。またローカル環境での利用という前提からサイズを小さくしたいため、量子化モデルを前提に解説します。
モデルとGPUメモリの関係
一般論としてパラメータ数が大きいモデルほど高い性能が期待できます。しかし同時に、パラメータ数の増加は、GPUメモリ要件を押し上げます。
ここではollamaのQwen2.5を例に、必要がGPUメモリ量を概算で確認します。ハードウェアのセクションにパフォーマンス比較結果がありますが、そこで採用されているため、Qwen2.5にて比較しています。
次の図の通り、qwen2.5:14bで9.0GB、一つ上のqwen2.5:32bですと20GBのGPUメモリを消費します。さらに一番上のqwen2.5:72bでは48GBのGPUメモリをモデルのロードに必要とします。

コンシュマー製品では、専用GPUメモリ32GBが一般的な上限であり、パラメータ数 32bクラスのモデルが実質的に利用できる最大サイズとなります。これより大きなサイズのモデルを利用する場合、エンタープライズ向けGPUを導入する、CPUとGPUがメモリを共有するアーキテクチャを採用する、という選択肢が一般的になります。複数GPUを用いる構成も技術的には可能ですが、現実的な選択肢ではありません。
本記事では、ハードウェアのセクションにて、メモリ共有型についても調査した結果を紹介します。メモリ共有型を選べば、128GBのメモリを選択でき、GPUメモリ不足を回避できます。Apple SiliconとAMD Ryzen AI Max+ 395がCPUとGPUでメモリを共有するアーキテクチャを採用した製品として挙げられます。またNVIDIAからも古くはJetsonシリーズ、最新だとDGX Sparkが挙げられます。
モデルとGPUメモリの関係(少しだけ深掘り)
GPUメモリ容量は、単にモデルを起動できれば良いというわけではなく、推論を実用的に行うために必要な周辺メモリ要素を考慮する必要があります。本記事では、LocalLLM.inのVRAM Calculator for Local Open Source LLMsというツールを使って紹介します。
- Model Weights: モデルの重み本体。パラメータ数と量子化方式に依存
- System Overhead: CUDAランタイムバッファやフレームワークが必要とする管理領域
- Scratchpad Memory: 推論時の中間テンソルを保持する一時作業領域
- KV Cache: モデルのサイズ、コンテキスト長、バッチ数(同時に処理する数)にほぼ比例します
OpenAI gpt-oss-20bは、20bパラメータ、MXFP4(Mixed FP4 Quantization)で最大コンテキスト長131,072をサポートしています。OpenAIの記事では16GBのGPUメモリで動作と書いてあります。ただし、モデルの起動に必要なメモリ容量と、実用として利用するという場合には、差異があります。具体的には、コンテキスト長とバッチ数が重要となります。
必要とするGPUメモリを検討する際の例となります。
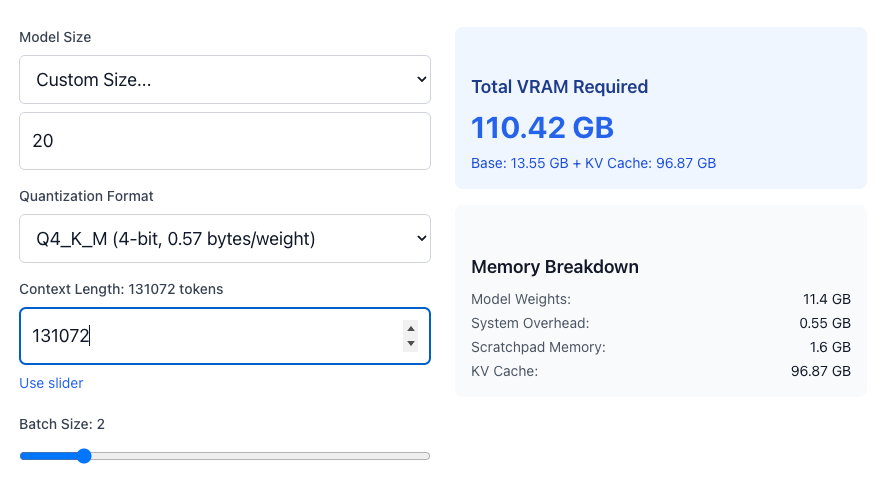
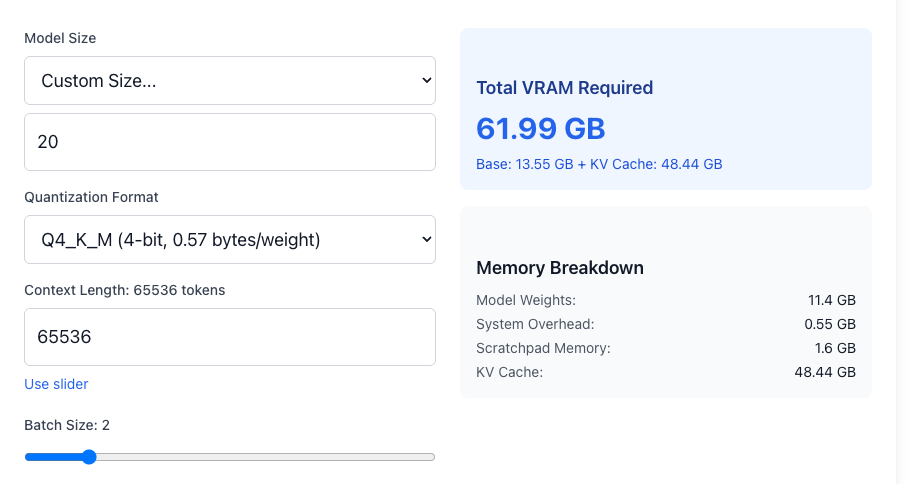
gpt-oss-20bは、Model Weightsで16GBであっても、KV Cacheはコンテキスト長をモデルの最大である131,072とすると、約48GBのGPUメモリを必要とします。Batch Sizeを増やして2とすると必要となるKV Cacheも倍の約96GBとなります。コンテキスト長を半分の65,536とすると、KV CacheはBatch size 1の時に約24GB、Batch size 2の時に約48GBとなります。
20b、Q4_K_M、コンテキスト長 131072、Batch Size 2の場合 (MXFP4ではないため、合計値は不正確)
20b、Q4_K_M、コンテキスト長 65536、Batch Size 2の場合 (MXFP4ではないため、合計値は不正確)
上記の通り、必要となるGPUメモリ量はモデル自体と利用方法を考慮して選定する必要があります。
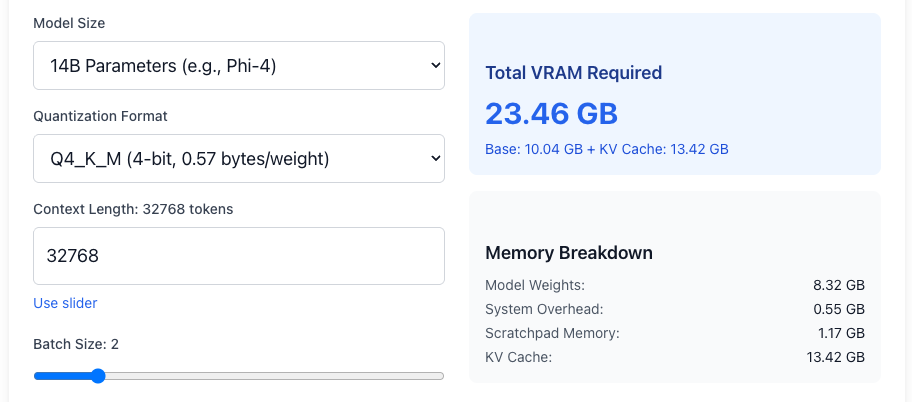
次の4つの図は、14b Q4_K_Mのモデルにおいての比較です。コンテキスト長が65536、Batch Size 1の場合、約24GBのGPUメモリ量を必要とします。
14b、Q4_K_M、コンテキスト長 65536、Batch size 1の場合

14b、Q4_K_M、コンテキスト長、32768、Batch size 2の場合
14b、Q4_K_M、コンテキスト長 32768、Batch size 2の場合
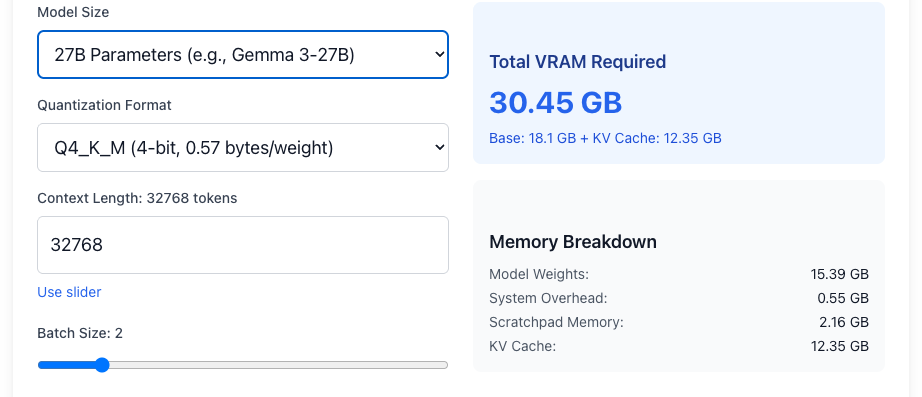
14b、Q4_K_M、コンテキスト長 32768、Batch size 2の場合
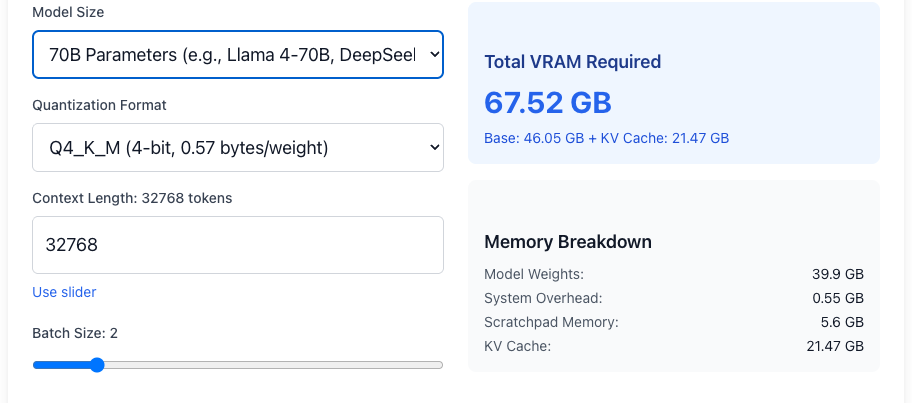
GPUメモリ24GB〜32GBの環境では、14b〜27bのモデルにて、コンテキスト長を抑え、Batch Sizeが2程度が現実的な利用条件となります。より大きなモデルを使いたい場合は、ハードウェアのセクションで紹介している共有メモリ型アーキテクチャを採用したハードウェアを検討する、もしくはエンタープライズ向けGPUを検討することになります。
ハードウェア
本記事ではローカルでLLM環境を構築するにあたり、100万円以内で現実的に購入できるハードウェアを対象として情報を整理しています。現実的な選択肢として、次の表が選択肢になります。Mac Studio M3 Ultraでは256GB/512GBメモリ構成なども選択も選べますが、100万円を大きく超えるため今回は対象外としまし。(2025年12月時点)
GPU共有メモリ構成は、CPUとGPUが同じメモリ領域を利用します。LLMサービスを起動させるには両方のメモリが重要になるため、共有メモリ構成の場合、差し引いて考える必要があります。
| メーカー | GPUメモリ | コメント | 費用感 | |
| NVIDIA | GeForce RTX 50シリーズ | 8GB - 32GB | ゲーミング デスクトップPC向けGPU | RTX 5090 GPUのみで45万円前後が最安価格帯 |
| NVIDIA | GeForce RTX Laptop 50シリーズ | 8GB - 24GB | ゲーミング ノートPC向けGPU | RTX 5090ラップトップ搭載ゲーミング ノートPCの最安値が55万円程度 |
| NVIDIA | Jetson Orin | 4GB - 64GB | 共有メモリ | SWITCH SCIENCEにてJetson AGX Orin 64GBが41万円程度 |
| NVIDIA | DGX Spark | 128GB | 共有メモリ | アプライドネットにて最安値が55万円程度 |
| AMD | Ryzen Al Max+ 395 | 64GB - 128GB | 共有メモリ | GMKtec EVO-X2の最安値が41万円程度 |
| Apple | Mac Studio M4 Max | 64GB - 128GB | 共有メモリ | 58.38万円 |
パラメータ数8b/14bのモデルを使ったハードウェア性能比較
同じモデルを使用した性能比較を公開しているLocalStore.aiにてLlama 3.1 8b、Qwen2.5 14bの比較結果をグラフ化したのが次の図です。上記ハードウェアに近いものを選択してグラフを作ってみました。量子化前提で考えるとLlama 3.1 8Bは約4.9GB、Qwen2.5 14Bは約9.0GBのGPUメモリが最低限必要となります。
Llama 3.1 8B Instruct Q4_K_Midiumを用いた比較結果
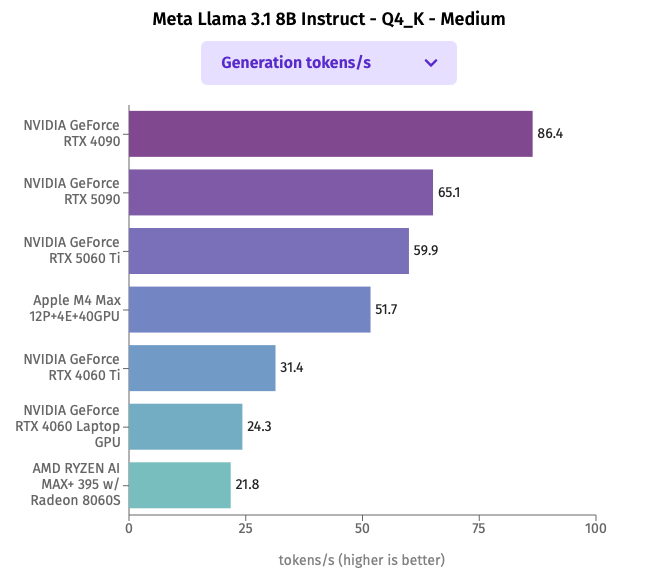
Qwen2.5 14B Instruct Q4_K_Midiumを用いた比較結果
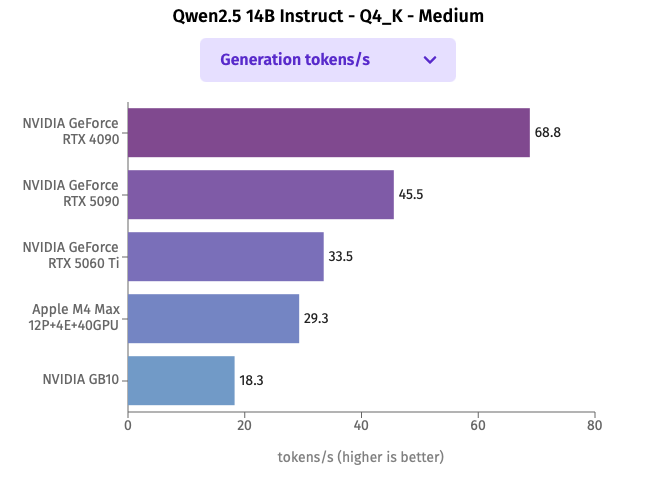
速度を優先する必要があり、パラメータ数14b程度のモデルで期待する結果を得られている場合は、NVIDIA GeForce RTX 4090またはRTX 5090が最適な選択肢となります。
ハードウェア比較の参考情報
他にも次のサイトにて比較情報が充実していました。
- ローカルLLM向けPC比較早見表/日本語ページが上記ハードウェアの情報を広くカバーしています
- PC Watch/やっと来たぜ卓上AIスパコン「ASUS ASCENT GX10」!気になる性能はどう?/日本語ページはわかりやすくASUS ASCENT GB10 (NVIDIA DGX Spark相当)とApple M4 Max 128GBを比較しています
- The Best GPUs for Local LLM Inference in 2025/英語ページではハードウェアパフォーマンス比較以外にもモデルのパラメータサイズごとに必要となるGPUメモリ量などの計算や比較表があります
まとめ
速度を重視する場合は、NVIDIA GeForce RTXが最適解となります。ただし、GPUメモリは最大32GBとなるため、実質的に扱えるモデルのパラメータ数は14b程度が上限となります。一方、速度よりも精度を求めるということであれば、パラメータ数が27b、32b、70b程度のモデルを選ぶことを検討することになります。その際は、Apple Studio M4 MaxやNVIDIA DGX Sparkを選択することになります。しかし推論速度ではRTXに及びません。
いずれにしても、利用シーンに必要なコンテキスト長とBatch size、速度、回答品質を考慮してハードウェアを選択する必要があります。
[補足]LLM Serving
LLMをローカルで構築する場合、ハードウェアの種類に応じて適したLLM Servingフレームワークがあります。まず「ローカルで簡単に動かしたい」という目的であれば、ollamaが最も手軽です。Windows/Linux/MacOSのすべてに対応し、モデル管理やAPI提供が標準で組み込まれています。
それ他の選択肢としては、以下があります。
- llama.cpp:軽量・マルチプラットフォーム(CPU / NVIDIA / Apple GPU)。OpenAI 互換 API モードあり
- vLLM:NVIDIA GPU 前提の高性能 Serving。OpenAI 互換 API を標準提供
- MLX-LM:Apple Silicon 専用(Metal / MLX)で最適化された Serving
API をサポートしている点では上記はいずれも対応しています。ただし、MLX-LM の API サーバは現時点では本番利用は推奨されていません。