目次
- 背景
- TL;DR
- 使用した技術
- 手順アウトライン
- 手順詳細
- 実用性
1. 背景
- ある日、友人が「東京23区の図書館にあるCDを一気に検索したい」と言った。
- 書籍を検索するサイトはあるけどCDを検索するのはなかった。
- 「無いなら作ればええやん」
- ついでに当時WEBクローラーが気になっていたのでとりあえず使ってみた。
- ついでについでにReactも勉強したばかりだったので使ってみた。
2. TL;DR
15秒位のgifだよ

3. 使用した技術
- node.js (v8.10.0)
- express (v4.16.4) - node.jsのフレームワークを利用するためのパッケージ
- superagent (v4.0.0-beta.5) - クライアントサイドのHTTPリクエストライブラリのパッケージ
- cheerio-httpcli (v0.7.3) - WebスクレイピングをjQueryライクな文法で操作できるパッケージ
- create-react-app (v1.5.2) - Reactアプリの土台を簡単に作れるパッケージ
4. 手順アウトライン
- 調査
- cheerio-httpcliの調査
- 図書館の調査
- 開発
- プロジェクトの土台を作成
- 画面の作成
- WEBクローラーロジックの作成
5. 手順詳細
1. 調査
1-1. cheerio-httpcliの調査
- jQueryみたいな感じで要素の情報が取得できるので初心者の私でも使いやすそうだと思った。
- JavaScript初心者でも、非同期処理を気にせずにかける。
- Form入力もSubmit処理もできる。
- JavaScriptで行われるページ遷移などはできない。
-
若干クロールスピードが遅いと感じた。
- ページ遷移はできるだけ避けるべき。
- 起動できるのはシングルインスタンスのみ、誰かがクロール中だと他の人はクロールが終わるまで待たないといけない。
- 初めて遊んでみたときのコードがあったで以下に示す。
- 詳しい処理を知りたい場合はhttps://www.npmjs.com/package/cheerio-httpcli を見る。
.cheerio-practice.js
// cheerio-httpcliのインポート
const cheerio = require('cheerio-httpcli');
// 同期的にページ情報の取得
const searchOptionPage = cheerio.fetchSync('www.searchOption.com');
// 取得したページ情報オブジェクトの$要素
let $ = searchOptionPage.$;
// $に必要な要素のセレクタを文字列として渡すと要素を取得できる
// 例として検索ページのform要素を取得し、cheerio-httpcliが提供するfield関数でform fieldに検索オプションを入力することができる
$('<formSelector>').field({<inputFieldName>: <value>, ...});
// formのsubmitボタンのセレクタをクリックする関数clickSyncを使用し、遷移先の検索結果表示ページを同期的に取得
const resultPage = $('<submitButtonSelector>').clickSync();
// 取得したページ情報オブジェクトの$要素
$ = resultPage.$;
// 取得したい情報を持つセレクタを引数に渡す。
// 複数セレクタに当てはまる場合、配列として返ってくる。
// この例では、URLがほしいので、<a>要素のタグか何かのセレクタを渡し、結果として返ってきた要素配列からURLの情報だけを引っ張ってくる
const resultUrlArray = $('<targetUrlSelector>').map(ele => $(ele).url() );
// 取得した配列を出力
console.log(resultUrlArray);
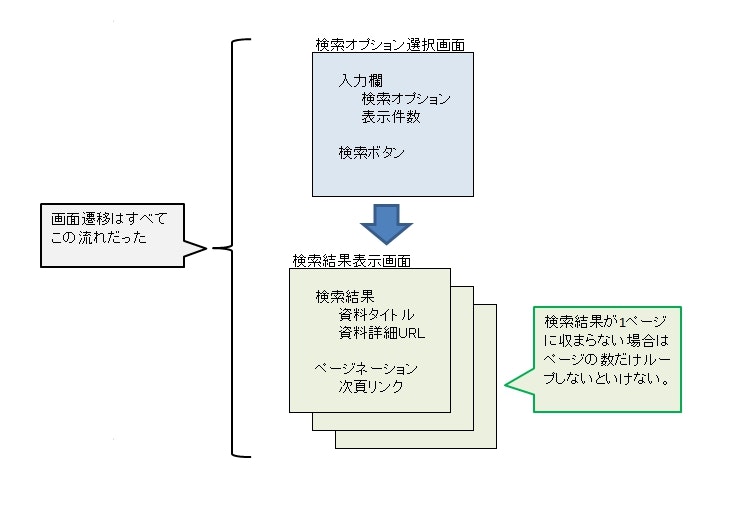
1-2. 図書館の調査
汎用的なコードでcheerio-httpcliを使えるようにするために、東京23区の図書館に関して以下の事柄を調査した。
- 図書館の検索画面はcheerio-httpcliを使って検索し、画面遷移できるようなものか?(JavaScript使っている場合は遷移はできないため)
- 図書館のサイトで検索するのに共通するものはなにか(ページの遷移、form要素の中身、検索結果のCDのタイトル/詳細URL)?
- WEBクローラーが図書館のサイトで処理を進めるために必要な要素のセレクタはなにか(ここを調べるのが大変だった)。
結果、以下の図のようにまとめることができた(各図書館についてのセレクタ情報はJSONファイルにまとめる)。
2. 開発
2-1. プロジェクトの土台の作成
- ここで
create-react-appお兄さんにプロジェクトの土台を作成してもらう。 - その後に
express,superagent,cheerio-httpcliをインストールする。
ターミナル
$ create-react-app tokyo-library-crawler # reactアプリ開発の土台を含んだディレクトリを作成してくれる
$ cd tokyo-library-crawler # できたディレクトリに移動
$ npm i --save express superagent cheerio-httpcli # 必要なパッケージのインストール
これで土台は出来上がり!
2-2. 画面の作成
依頼主の友人に相談しながら画面を考えた。結果以下のような条件に落ち着いた。
- 使用する端末はPCのみ、ブラウザはChromeは基本Chrome。
- LIKE検索ができるキーワード入力欄がほしい。
- キーワードがCDのタイトルを指すのか、アーティストを指すのかを選べるようにしたい。
- WEBクローラーが遅い(調査時に発覚)のであれば…
- どの区の図書館を調べるかをこちらで絞れるようにしたい。
- CDの貸出可否状態は表示しなくてよい(調べるためにWEBクローラーが余計にページ遷移しなければならないため)、ただそれがわかるURLを配置してほしい。
- 検索結果は表にして、以下の情報を並べれば良い。
- 資料がある図書館の区名
- CDのタイトル
- CDのアーティスト
- CDの貸出可否がわかるURL
- デザインはおまかせ
上記を踏まえて、以下のようなコンポーネント構想を考えた。
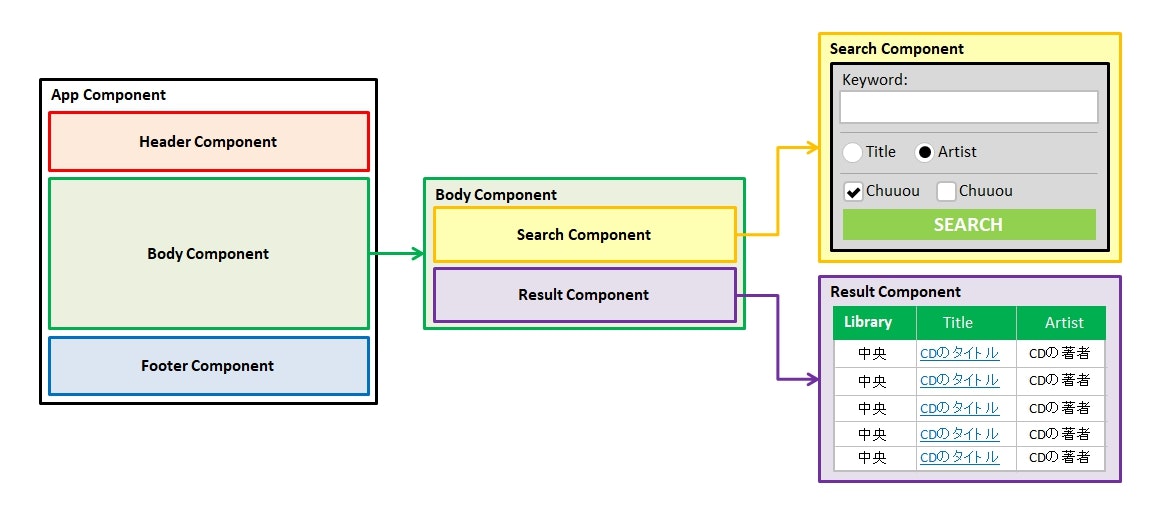
細かいところはさておき、あとはこれでロジックを書くだけになった。
2-3. WEBクローラーロジックの作成
ここまでくればやることはそう難しくなく、以下に絞られる。
- クライアント側でSEARCHボタンが押されたら、superagentでPOSTリクエストを投げる。
- サーバ側でexpressのルーティングでPOSTリクエストを受け取れば、WEBクローラーを起動し、必要な情報をかき集め、クライアントに返す。
6. 実用性
- 結論から言ってこのアプリケーションは実用性が低いと言える。理由として以下が挙げられる。
- クロールスピードが遅い。
- cheerio-httpcliはシングルインスタンスなので、誰かがクロールしてると他の人は何もできない。
- 図書館のサイトによっては、取得した先のURLはクッキーがないと見れないようになっているので、貸出可否を見ることができない。
- 東京23区中、情報を取得できたのが7区。その7区のうち、上記により、ちゃんと情報が見れるのは4区ほど…
- 完成してから「robots.txt」の存在に気づく。7区のうち5区は検索と結果表示ページをDisallowしてた。残りの2つはrobots.txtがなかった。
この「robots.txt」を知らなかったのは自分でもかなり大きい。シングルインスタンスで、かつページ遷移を極力抑えてることからサイトに負荷をかけるようなリクエスト数ではないと思っているが…念のためにサイトはサイトは閉鎖するべきか…
「もっと調査するべきでした。」と思った個人プロジェクトでした。てへぺろ