はじめに
ヴェネクト株式会社のディレクター 小峰です。
今回の分析では”構文解析”を扱います。構文解析では、インプットした文章内で、各単語がどのような位置づけであるか、係り受け構造を得ることができます。係り受け構造を理解すれば、各単語の品詞(名詞や形容詞など)やどの単語に結びついているかを理解することができます。
構文解析については、下記の記事で詳細をご確認ください。
【入門編】自然言語処理(NLP)とは | 意味・仕組み・活用例・課題
https://ledge.ai/nlp/
今回の構文解析の目的設定
今回の分析の目的として、下記の2者を設定します。
- 関心のあるエンティティが、文章中でどのような言及をされているか
-
関心のあるエンティティが、どのような点を評価されているか
両者に対し、エンティティ解析結果と紐付けを行います。
その結果、関心のあるエンティティが、文章中でどのような言及・評価されているか、分析できるようにすることがゴールになります。
プログラム実行環境
今回はPythonを利用します。Versionは3.7を採用します。
先に必要なPackageを書き出すと下記の通りになります。
# DataFrame変数を処理に活用するため、Importします
import pandas as pd
import numpy as np
# Excelで取得したデータを処理するため、Importします
import xlrd
# 以下はGCPに接続し、APIでやり取りをするため、各種GCP関連のPackageをImportします
from google.cloud import language_v1
import os
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from googleapiclient import discovery
from google.cloud import storage
GCPの「Natural Language API」の利用
また、自然言語処理はGCPの「Natural Language API」を利用します。そのため、GCPのプロジェクトを立ち上げ、課金を有効にし、API利用の認証取得と「Natural Language API」の有効化が必要です。
実際の設定方法ですが、公式のHelpを参考にしてください。
GCP|すべてのクイックスタート
https://cloud.google.com/natural-language/docs/quickstarts?hl=ja
GCP|クイックスタート: Natural Language API の設定
https://cloud.google.com/natural-language/docs/setup?hl=ja
インプットするデータ
取得データの解説
サンプルとして、レビューサイトに記載されている、化粧品の商品レビューを対象にします。レビュー文章だけでなく、レビュー記入者の名前とレビューが記入された日付を取得します。レビューが記載されたExcelをPythonで読み込み、PandasのData Frame変数に変換し、分析を実行します。

インプットに向けた加工
エンティティ分析はレビュー文1つずつ実行します。そのため、Excelからデータを読み取り、レビューの一覧を格納したData Frame変数を、レビュー1文づつに分解します。成果物を扱いやすくするために、Dict変数を採用します。Keyにレビュー記入者の名前とレビューが記載された日付を設定し、各レビューをユニークに識別できるようにし、Valueにレビュー文を導入します。
下記のScriptを実行し、インプットするDict変数を得ます。
Reviews = {}
for DF in ListOfReviews:
for Index, Row in DF.iterrows():
R = Row["内容"]
R = R.replace('\n', '')#改行文字\nを削除する
R = R.replace('\u3000', '')
I = Index
Reviews[I] = R
Reviews
サンプルコード
サンプルコード例
最初にサンプルコードを掲載し、その後処理内容を解説します。
※エンティティ分析や感情分析よりも、少し複雑になります。
#構文解析の処理内容を定義した関数を作成する
def SyntaxStructure(Input):
# GCPのAPIと連携し自然言語解析結果を受けるインスタンスを定義する
Client = language_v1.LanguageServiceClient()
#解析対象の言語特性を定義する
Type = language_v1.Document.Type.PLAIN_TEXT
Language = "ja"
Encoding_type = language_v1.EncodingType.UTF8
#各レビュー毎のEntityとExpressionの構成を格納したDictionary変数を定義し、その内部に処理結果を格納する
Relationship = {}
#各レビューに対し処理を実行する
for Key, Value in zip(Input.keys(), Input.values()):
#分析対象のレビューを取得し、UTF-8に変換した上で解析処理を行う
Text = Value.encode('utf-8')
Document = {"content":Text , "type_": Type, "language": Language}
Response = Client.analyze_syntax(request = {'document': Document, 'encoding_type': Encoding_type})
#分析結果を整理し、DataFrameとして格納する
##DependencyEdgeの係り受け構造を判断するために、LocationNumberを定義する
###当初はLocationNumberは0から開始する
LocationNumber = 0
####係り受け構造の要素を格納するためのList変数を定義する
TokenList = []
for Token in Response.tokens:
##APIからのJSONレスポンスを分解し各種変数として定義する
###Contentは対象のKWを示す、Entityと結合させる際の条件に利用する
TokenText = Token.text
Content = format(TokenText.content)
###TagはKWの品詞を示す、必要なKWを判断するために利用する
PartOfSpeech = Token.part_of_speech
Tag = format(
language_v1.PartOfSpeech.Tag(PartOfSpeech.tag).name
)
###Properは固有名詞かどうかを記述する、基本的にあまり利用しない
Proper = format(
language_v1.PartOfSpeech.Proper(PartOfSpeech.proper).name
)
###DependencyEdgeは係り受け構造を示すため最も重要である
DependencyEdge = Token.dependency_edge
####LocationNumberは対象のKWが文章中のどの位置にいるかを示す、係り受けの参照に利用する
####HeadTokenIndexは係り受け先のKWがどのLocationNumberに対応するかを示す、係り受けの参照に利用する
####DependencyLabelは係り受け構造のタイプを示す、ただし活用難易度が高いため、当初は利用しない
HeadTokenIndex = format(DependencyEdge.head_token_index)
DependencyLabel = format(
language_v1.DependencyEdge.Label(DependencyEdge.label).name
)
####Lemmaの役割は不明である、おそらく日本語では機能しないので利用しない
Lemma = format(Token.lemma)
###格納用にToken単位でData Frame変数を定義する
####結合できるように、元のDFの情報も付与する
SyntaxTokenResult = pd.DataFrame.from_dict({
"Date":Key[0],
"ReviewerName":Key[1],
"BrandName":Key[2],
"ReputationFromReviewer":Key[3],
"Age":Key[4],
"SkinCondition":Key[5],
"Review":Value,
"Content":Content,
"Tag":Tag,
"Proper":Proper,
"LocationNumber":LocationNumber,
"HeadTokenIndex":HeadTokenIndex,
"DependencyLabel":DependencyLabel,
"Lemma":Lemma
},
orient="index").T
###SyntaxTokenResultをTokenListに格納する
TokenList.append(SyntaxTokenResult)
#LocationNumberの繰り上げを行う
LocationNumber += 1
##Token単位での係り受け構造のDFをレビュー単位で結合する
SyntaxReviewResult = pd.concat(TokenList)
##SyntaxReviewResultの各列のデータ型を設定する
SyntaxReviewResult = SyntaxReviewResult.astype({
"Date":"object",
"ReviewerName":"object",
"BrandName":"object",
"ReputationFromReviewer":"int",
"Age":"object",
"SkinCondition":"object",
"Review":"object",
"Content":"object",
"Tag":"object",
"Proper":"object",
"LocationNumber":"object",
"HeadTokenIndex":"object",
"DependencyLabel":"object",
"Lemma":"object"
})
#対象のレビュー内に含まれるEntityの一覧をList変数の形式で取得する
EntityList = Entities[Key]
#最終的な結果はDictionary変数で出力する、KeyにEntityを設定し、ValueにExpressionを出力する
EntityExpression = {}
#レビュー内のEntity毎に処理を実行する
for Entity in EntityList:
#特殊文字を含むのであれば、検索時にエラーが生じるため、処理を行わない
if re.compile(r'\(|\)|\.|\^|\$|\*|\+|\?|\{|\}|\[|\[|\\').search(Entity):
None
else:
#各Entity毎の処理結果を格納するためのDict変数を定義する
SyntaxDictionary_PerEntities = {}
#該当のEntityをContentとして持つSyntaxReviewResultの行を取得する
##Entityの文字数に応じて処理を変える
Length = len(Entity)
if Length <= 3:
ContentDF = SyntaxReviewResult.query(
"(Content.str.contains(@Entity))",
engine='python')
elif Length <= 5:
a = Entity[0:3]
b = Entity[-4:-1]
ContentDF = SyntaxReviewResult.query(
"(Content.str.contains(@Entity))|(Content.str.contains(@a))|(Content.str.contains(@b))",
engine='python')
elif Length <= 7:
a = Entity[0:4]
b = Entity[-5:-1]
ContentDF = SyntaxReviewResult.query(
"(Content.str.contains(@Entity))|(Content.str.contains(@a))|(Content.str.contains(@b))",
engine='python')
elif Length <= 9:
a = Entity[0:5]
b = Entity[-6:-1]
ContentDF = SyntaxReviewResult.query(
"(Content.str.contains(@Entity))|(Content.str.contains(@a))|(Content.str.contains(@b))",
engine='python')
else:
a = Entity[0:6]
b = Entity[-7:-1]
ContentDF = SyntaxReviewResult.query(
"(Content.str.contains(@Entity))|(Content.str.contains(@a))|(Content.str.contains(@b))",
engine='python')
#もしもEntityと合致するKWが無ければ行は取得できない、その場合は以下の処理を実行しない
if ContentDF.empty:
None
else:
#ここでEntityが複数行とマッチする可能性を考慮しfor構文で1行づつ処理を行う実装にする
for Index, Row in ContentDF.iterrows():
#最初にSyntaxDictionary_PerEntitiesにマッチしたKWを登録する
KWLocation = Row["LocationNumber"]
SyntaxDictionary_PerEntities[KWLocation] = Row["Content"]
#次に前に連なるKWを取得する
##基本的に対象KWに対する、前の文章すべてを対象にする
for i in range(KWLocation):
##1つ前のKWのLocationNumberを取得する
Location = int(KWLocation - i - 1)
###レビュー文頭に達したら処理をやめる
if Location < 0:
break
else:
CDF = SyntaxReviewResult[SyntaxReviewResult["LocationNumber"] == Location]
Word = CDF.loc[0,"Content"]
###句読点を取得すれば処理をやめる
if re.compile(r'。|\!|\?|!|?').search(Word):
break
else:
SyntaxDictionary_PerEntities[Location] = Word
#最後に後ろに連なるKWを取得する
##基本的に対象KWに対する、後ろの文章すべてを対象にする
for i in range(888):
##1つ前のKWのLocationNumberを取得する
Location = int(KWLocation + i + 1)
###レビュー文末に達したら処理をやめる
if Location >= len(SyntaxReviewResult):
break
else:
CDF = SyntaxReviewResult[SyntaxReviewResult["LocationNumber"] == Location]
Word = CDF.loc[0,"Content"]
###句読点を取得すれば処理をやめる
if re.compile(r'。|\!|\?|!|?').search(Word):
break
else:
SyntaxDictionary_PerEntities[Location] = Word
#単語の出現順で文章を並び替え、Entityが出現する表現を取得する
Expression = ""
SyntaxDictionary_Order = sorted(SyntaxDictionary_PerEntities.items())
for i in SyntaxDictionary_Order:
Word = i[1]
Expression += Word
#EntityとExpressionをDictionary変数の要素として出力する
EntityExpression[Entity] = Expression
#各レビュー毎のEntityとExpressionの組み合わせを格納したDictionary変数を、最終出力用のDictionary変数に出力する
Relationship[Key] = EntityExpression
#最終的な結果として、KeyにEntityを設定し、ValueにExpressionを設定したDictionary変数を出力する
return Relationship
解説
最初に、いつものように自然言語解析結果を受けるためのインスタンスをClientとして定義しています。
Client設定
Type、Language、Encoding_typeは分析対象の文章の言語特性を定義します。
- Type
文章の種別を定義します。PLAIN_TEXT以外にも、HTMLも定義可能です。 - Language
分析対象の言語です。日本語なのでJaを選択します。 - Encoding_type
文字コードです。今回はUTF-8を採用しています。UTF-16とUTF-32にも対応します。
GCP|Natural Language API|Natural Language API の基本
https://cloud.google.com/natural-language/docs/basics?hl=ja
#解析対象の言語特性を定義する
Type = language_v1.Document.Type.PLAIN_TEXT
Language = "ja"
Encoding_type = language_v1.EncodingType.UTF8
結果の一次格納用のDict変数
分析対象の文章と、構文解析結果を紐付けて格納するために、RelationshipというDict変数を定義し、両者を関連付けて格納していきます。
#各レビュー毎のEntityとExpressionの構成を格納したDictionary変数を定義し、その内部に処理結果を格納する
Relationship = {}
構文解析処理の実行
Client.analyze_syntaxで構文解析を実行します。入力するのは、documentに分析対象の文章を設定し、encoding_type に文字コードを定義します。
for文を採用し、レビュー単位で処理を実行します。
# 各レビューに対し処理を実行する
for Key, Value in zip(Input.keys(), Input.values()):
#分析対象のレビューを取得し、UTF-8に変換した上で解析処理を行う
Text = Value.encode('utf-8')
Document = {"content":Text , "type_": Type, "language": Language}
Response = Client.analyze_syntax(request = {'document': Document, 'encoding_type': Encoding_type})
構文解析結果の解釈
構文解析結果ですが、下記のような形式で返されます。
※エンティティ分析や感情分析よりも、複雑になります。
概要
全体的な概要ですが、下記のように"sentense"と"tokens"の2者で構成されるレスポンスになります。
{
"sentences": [
... Array of sentences with sentence information
],
"tokens": [
... Array of tokens with token information
]
}
Sentense
sentenseは下記のように、文章から一文(センテンス)を切り分けてくれます。
{
"sentences": [
{
"text": {
"content": "Four score and seven years ago our fathers brought forth on
this continent a new nation, conceived in liberty and
dedicated to the proposition that all men are created
equal.",
"beginOffset": 0
}
},
{
"text": {
"content": "Now we are engaged in a great civil war, testing whether
that nation or any nation so conceived and so dedicated can
long endure.",
"beginOffset": 175
}
},
...
...
{
"text": {
"content": "It is rather for us to be here dedicated to the great task
remaining before us--that from these honored dead we take
increased devotion to that cause for which they gave the
last full measure of devotion--that we here highly resolve
that these dead shall not have died in vain, that this
nation under God shall have a new birth of freedom, and that
government of the people, by the people, for the people
shall not perish from the earth.",
"beginOffset": 1002
}
}
],
"language": "en"
}
文章を切り分けることで、必要な文章だけ抜き出したり、エンティティ解析や感情分析を行いやすくするなど、前処理に活用できます。
ただし、今回の分析では、係り受け構造の解明を重視するため、利用しません。
Tokens
tokensは下記のように、単語ごとに切り出し、係り受け構造を示してくれます。
"tokens": [
{
"text": {
"content": "The",
"beginOffset": 4
},
"partOfSpeech": {
"tag": "DET",
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "DET"
},
"lemma": "The"
},
{
"text": {
"content": "only",
"beginOffset": 8
},
"partOfSpeech": {
"tag": "ADJ",
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "AMOD"
},
"lemma": "only"
},
{
"text": {
"content": "thing",
"beginOffset": 13
},
"partOfSpeech": {
"tag": "NOUN",
"number": "SINGULAR",
},
"dependencyEdge": {
"headTokenIndex": 7,
"label": "NSUBJ"
},
"lemma": "thing"
},
{
"text": {
"content": "we",
"beginOffset": 19
},
"partOfSpeech": {
"tag": "PRON",
"case": "NOMINATIVE",
"number": "PLURAL",
"person": "FIRST",
},
"dependencyEdge": {
"headTokenIndex": 4,
"label": "NSUBJ"
},
"lemma": "we"
},
{
"text": {
"content": "have",
"beginOffset": 22
},
"partOfSpeech": {
"tag": "VERB",
"mood": "INDICATIVE",
"tense": "PRESENT",
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "RCMOD"
},
"lemma": "have"
},
{
"text": {
"content": "to",
"beginOffset": 27
},
"partOfSpeech": {
"tag": "PRT",
},
"dependencyEdge": {
"headTokenIndex": 6,
"label": "AUX"
},
"lemma": "to"
},
{
"text": {
"content": "fear",
"beginOffset": 30
},
"partOfSpeech": {
"tag": "VERB",
},
"dependencyEdge": {
"headTokenIndex": 4,
"label": "XCOMP"
},
"lemma": "fear"
},
{
"text": {
"content": "is",
"beginOffset": 35
},
"partOfSpeech": {
"tag": "VERB",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"tense": "PRESENT",
},
"dependencyEdge": {
"headTokenIndex": 7,
"label": "ROOT"
},
"lemma": "be"
},
{
"text": {
"content": "fear",
"beginOffset": 38
},
"partOfSpeech": {
"tag": "NOUN",
"number": "SINGULAR",
},
"dependencyEdge": {
"headTokenIndex": 7,
"label": "ATTR"
},
"lemma": "fear"
},
{
"text": {
"content": "itself",
"beginOffset": 43
},
"partOfSpeech": {
"tag": "PRON",
"case": "ACCUSATIVE",
"gender": "NEUTER",
"number": "SINGULAR",
"person": "THIRD",
},
"dependencyEdge": {
"headTokenIndex": 8,
"label": "NN"
},
"lemma": "itself"
},
{
"text": {
"content": ".",
"beginOffset": 49
},
"partOfSpeech": {
"tag": "PRON",
"case": "ACCUSATIVE",
"gender": "NEUTER",
"number": "SINGULAR",
"person": "THIRD",
},
"dependencyEdge": {
"headTokenIndex": 8,
"label": "NN"
},
"lemma": "itself"
},
{
"text": {
"content": ".",
"beginOffset": 49
},
"partOfSpeech": {
"tag": "PUNCT",
},
"dependencyEdge": {
"headTokenIndex": 7,
"label": "P"
},
"lemma": "."
}
],
要素として、下記を含んでいます。
-
text
-
Context
取得した文章中の表現になります。こちらは、GCPの欠点になりますが、エンティティ解析で取得するEntityと必ずしも一致しないため注意してください。 -
beginOffset
対象のContextが文章中で出現する位置を示します。(開始番号は0になります)
-
Context
-
partOfSpeech
-
partOfSpeech
対象のContextの"品詞"を示します。形態素解析の結果を示します。
-
partOfSpeech
-
lemma
対象のContextの基本型を表示します。ただし、現時点では、日本語では結果が表示されないため、今回は利用しません。 -
dependencyEdge
- 対象のContextが、どの要素の内容を受けているか、係り受け構造を示します。(例えば、「移すくしい花だ」という文章で、「美しい」をContextとしてみた場合、親に当たるのは「花」になります。)その親のbeginOfOffsetを示します。
形態素解析結果については、下記の公式Helpにてご確認ください。
GCP|Cloud Natural Language|形態論と依存関係ツリー
https://cloud.google.com/natural-language/docs/morphology?hl=ja
レビュー単位での分析結果の格納
取得した分析結果を、活用しやすいように格納する処理に移ります。
for文での実行
まず、Tokens単位での係り受け解析結果を格納するためのList変数を定義します。
また、Tokens内のすべての要素を処理するために、for文を採用します。
ここで定義するLocationNumberですが、次の処理で取得するContentが文章中で何番目に出現するか、取得するために利用します。
# 分析結果を整理し、DataFrameとして格納する
## DependencyEdgeの係り受け構造を判断するために、LocationNumberを定義する
### 当初はLocationNumberは0から開始する
LocationNumber = 0
#### 係り受け構造の要素を格納するためのList変数を定義する
TokenList = []
for Token in Response.tokens:
Contentの取得
今回は、文章中のKW単位で、構文解析結果を取得することが目的のため、分析結果のJson内からtokenへと進みます。
構文解析の各Contentを、下記のような、format化処理により、解析結果を取得します。
結果、対象のKWをContentとして取得できます。
## APIからのJSONレスポンスを分解し各種変数として定義する
### Contentは対象のKWを示す、Entityと結合させる際の条件に利用する
TokenText = Token.text
Content = format(TokenText.content)
形態素解析結果の取得
次に、形態素解析の解析結果を、取得し適切に格納する処理に移ります。
対象のContextの品詞を得ることが目標になります。
下記のformat処理を採用すれば、分かりやすい形式で品詞を得ることができます。
### TagはKWの品詞を示す、必要なKWを判断するために利用する
PartOfSpeech = Token.part_of_speech
Tag = format(
language_v1.PartOfSpeech.Tag(PartOfSpeech.tag).name
)
### Properは固有名詞かどうかを記述する、基本的にあまり利用しない
Proper = format(
language_v1.PartOfSpeech.Proper(PartOfSpeech.proper).name
)
係り受け構造の取得
最後に係り受け構造を取得します。
下記のようなformat処理を採用すれば、分かりやすい形式で係り受け構造を取得できます。
### DependencyEdgeは係り受け構造を示すため最も重要である
DependencyEdge = Token.dependency_edge
#### LocationNumberは対象のKWが文章中のどの位置にいるかを示す、係り受けの参照に利用する
#### HeadTokenIndexは係り受け先のKWがどのLocationNumberに対応するかを示す、係り受けの参照に利用する
#### DependencyLabelは係り受け構造のタイプを示す、ただし活用難易度が高いため、当初は利用しない
HeadTokenIndex = format(DependencyEdge.head_token_index)
DependencyLabel = format(
language_v1.DependencyEdge.Label(DependencyEdge.label).name
)
結果をDataFrame変数に格納する
その結果を、元の文章と紐付けが出来るように、分析対象のレビューと関連付ける形でDataFrame変数として格納します。
説明が遅くなりましたが、Location Numberは一文(Sentence)単位での位置を割り振っている番号になります。
### 格納用にToken単位でData Frame変数を定義する
#### 結合できるように、元のDFの情報も付与する
SyntaxTokenResult = pd.DataFrame.from_dict({
"Date":Key[0],
"ReviewerName":Key[1],
"BrandName":Key[2],
"ReputationFromReviewer":Key[3],
"Age":Key[4],
"SkinCondition":Key[5],
"Review":Value,
"Content":Content,
"Tag":Tag,
"Proper":Proper,
"LocationNumber":LocationNumber,
"HeadTokenIndex":HeadTokenIndex,
"DependencyLabel":DependencyLabel,
"Lemma":Lemma
},
orient="index").T
Content別の処理完了時に結果を格納する
これまでの処理は、Context単位で実行しています。
最初に記述しているToken単位でfor構文を回しているイメージです。
次のContentに向けた処理に移る前に、結果を格納するDataFrame変数をListに追加し、LocationNumberに1を足します。
### SyntaxTokenResultをTokenListに格納する
TokenList.append(SyntaxTokenResult)
# LocationNumberの繰り上げを行う
LocationNumber += 1
レビュー単位で処理完了時に、結果を結合し一本化する
レビュー単位で処理が完了すれば、Content単位で作成したDataFrame変数を縦結合することで、レビュー単位で、構文解析結果を格納したDataFrame変数を得ます。
念の為、変数型を定義しておきます。
## Token単位での係り受け構造のDFをレビュー単位で結合する
SyntaxReviewResult = pd.concat(TokenList)
## SyntaxReviewResultの各列のデータ型を設定する
SyntaxReviewResult = SyntaxReviewResult.astype({
"Date":"object",
"ReviewerName":"object",
"BrandName":"object",
"ReputationFromReviewer":"int",
"Age":"object",
"SkinCondition":"object",
"Review":"object",
"Content":"object",
"Tag":"object",
"Proper":"object",
"LocationNumber":"object",
"HeadTokenIndex":"object",
"DependencyLabel":"object",
"Lemma":"object"
})
いったん以上で、文章(レビュー)単位で構文解析結果を取得する処理は完了します。
エンティティ分析結果と結合する
続けて、エンティティ分析結果と結合する処理に移ります。
エンティティ分析結果の取得
エンティティと紐付けに関心があるので、第2回目の記事で実行したエンティティ分析結果を利用します。
# 対象のレビュー内に含まれるEntityの一覧をList変数の形式で取得する
EntityList = Entities[Key]
# 最終的な結果はDictionary変数で出力する、KeyにEntityを設定し、ValueにExpressionを出力する
EntityExpression = {}
エンティティ分析結果との結合
前に書きましたとおり、構文解析の結果取得するContentとエンティティ分析の結果取得するエンティティは必ずしも切り出し方が一致するわけではありません。
そのため、文字数に応じて、一部の文字を切り出し、その切り出した文字列を含んでいるかどうかによって、結合が行われるように処理をします。
下記のような切り出し方をしています。
- 3文字以下
EntityとContentが一致する行を切り出す - 5文字以下
Entityの頭3文字か末尾3文字が一致する行を切り出す - 7文字以下
Entityの頭5文字か末尾5文字が一致する行を切り出す - それ以上
Entityの頭7文字か末尾7文字が一致する行を切り出す
結合は、下記のQuery関数を利用し、指定したContentの文字が含まれるかを条件に判別しています。
# 特殊文字を含むのであれば、検索時にエラーが生じるため、処理を行わない
if re.compile(r'\(|\)|\.|\^|\$|\*|\+|\?|\{|\}|\[|\[|\\').search(Entity):
None
else:
#各Entity毎の処理結果を格納するためのDict変数を定義する
SyntaxDictionary_PerEntities = {}
#該当のEntityをContentとして持つSyntaxReviewResultの行を取得する
##Entityの文字数に応じて処理を変える
Length = len(Entity)
if Length <= 3:
ContentDF = SyntaxReviewResult.query(
"(Content.str.contains(@Entity))",
engine='python')
elif Length <= 5:
a = Entity[0:3]
b = Entity[-4:-1]
ContentDF = SyntaxReviewResult.query(
"(Content.str.contains(@Entity))|(Content.str.contains(@a))|(Content.str.contains(@b))",
engine='python')
elif Length <= 7:
a = Entity[0:4]
b = Entity[-5:-1]
ContentDF = SyntaxReviewResult.query(
"(Content.str.contains(@Entity))|(Content.str.contains(@a))|(Content.str.contains(@b))",
engine='python')
elif Length <= 9:
a = Entity[0:5]
b = Entity[-6:-1]
ContentDF = SyntaxReviewResult.query(
"(Content.str.contains(@Entity))|(Content.str.contains(@a))|(Content.str.contains(@b))",
engine='python')
else:
a = Entity[0:6]
b = Entity[-7:-1]
ContentDF = SyntaxReviewResult.query(
"(Content.str.contains(@Entity))|(Content.str.contains(@a))|(Content.str.contains(@b))",
engine='python')
該当する文章の取得
次に、該当するEntityが登場する文章を取得する処理を記述しています。
日本語を想定しているため、シンプルに**句点(。)か感嘆詞(!)か疑問詞(?)の間の文章を取得する処理を採用しています。
# もしもEntityと合致するKWが無ければ行は取得できない、その場合は以下の処理を実行しない
if ContentDF.empty:
None
else:
# ここでEntityが複数行とマッチする可能性を考慮しfor構文で1行づつ処理を行う実装にする
for Index, Row in ContentDF.iterrows():
# 最初にSyntaxDictionary_PerEntitiesにマッチしたKWを登録する
KWLocation = Row["LocationNumber"]
SyntaxDictionary_PerEntities[KWLocation] = Row["Content"]
# 次に前に連なるKWを取得する
## 基本的に対象KWに対する、前の文章すべてを対象にする
for i in range(KWLocation):
## 1つ前のKWのLocationNumberを取得する
Location = int(KWLocation - i - 1)
### レビュー文頭に達したら処理をやめる
if Location < 0:
break
else:
CDF = SyntaxReviewResult[SyntaxReviewResult["LocationNumber"] == Location]
Word = CDF.loc[0,"Content"]
### 句読点を取得すれば処理をやめる
if re.compile(r'。|\!|\?|!|?').search(Word):
break
else:
SyntaxDictionary_PerEntities[Location] = Word
# 最後に後ろに連なるKWを取得する
## 基本的に対象KWに対する、後ろの文章すべてを対象にする
for i in range(888):
## 1つ前のKWのLocationNumberを取得する
Location = int(KWLocation + i + 1)
### レビュー文末に達したら処理をやめる
if Location >= len(SyntaxReviewResult):
break
else:
CDF = SyntaxReviewResult[SyntaxReviewResult["LocationNumber"] == Location]
Word = CDF.loc[0,"Content"]
### 句読点を取得すれば処理をやめる
if re.compile(r'。|\!|\?|!|?').search(Word):
break
else:
SyntaxDictionary_PerEntities[Location] = Word
# 単語の出現順で文章を並び替え、Entityが出現する表現を取得する
Expression = ""
SyntaxDictionary_Order = sorted(SyntaxDictionary_PerEntities.items())
for i in SyntaxDictionary_Order:
Word = i[1]
Expression += Word
# EntityとExpressionをDictionary変数の要素として出力する
EntityExpression[Entity] = Expression
結合処理結果をDict変数として格納する
分析結果を一度、Dict変数として格納します。
Keyにレビュー情報(レビュワー名や投稿日時、対象商品など)、Valueに各Entityに対しその文言が含まれる文章を格納した子Dict変数を格納しています。子Dict変数のKeyがEntityで、Valueが取得した文章です。
その結果を返すことで、エンティティ分析と構文解析の結果を結びつけたDict変数が得られます。
# 各レビュー毎のEntityとExpressionの組み合わせを格納したDictionary変数を、最終出力用のDictionary変数に出力する
Relationship[Key] = EntityExpression
# 最終的な結果として、KeyにEntityを設定し、ValueにExpressionを設定したDictionary変数を出力する
return Relationship
結果得られる成果物ですが、下記がイメージになります。

活用|エンティティ分析結果と結合する
構文解析結果をDataFrame変数として出力する
取得した結果を、下記の処理を実行し、DataFrame変数として出力します。
主キーはエンティティになり、そのエンティティが含まれるレビューの情報(レビュー日やレビュワー名など)と対象のエンティティが含まれる文章を出力します。
## レビュー単位でEntityとExpressionの組み合わせを格納するためのList変数を定義する
ReviewEntityExpressionList = []
# レビューごとに、EntityとExpressionの組み合わせを取得する
for Key, Value in Syntax.items():
# 各レビュー内におけるEntityとExpressionの組み合わせをData Frame変数化する
## 格納用のList変数を定義する
EntityExpressionList = []
for Entity, Expression in Value.items():
# Emtity毎にData Frame変数を作成し、すべての作成が終わった後に結合する
## Entity毎にData Frame変数を作成する
EntityExpression_PerEntity = pd.DataFrame.from_dict({
"Date":Key[0],
"ReviewerName":Key[1],
"BrandName":Key[2],
"ReputationFromReviewer":Key[3],
"Age":Key[4],
"SkinCondition":Key[5],
"EntityName":Entity,
"EntityExpression":Expression
},
orient="index").T
## 一時的にList変数に格納する
EntityExpressionList.append(EntityExpression_PerEntity)
try:
## レビュー毎にEntityとExpressionの組み合わせを格納したData Frame変数を定義する
EntityExpression_PerEntity = pd.concat(EntityExpressionList)
## 一時的にList変数に格納する
ReviewEntityExpressionList.append(EntityExpression_PerEntity)
except ValueError:
None
# レビュー毎の処理結果を最終的に結合することで、目的であるEntityとExpressionの組み合わせをまとめたData Frame変数を得る
RelationshipEntityExpression = pd.concat(ReviewEntityExpressionList)
RelationshipEntityExpression
この段階での成果物は下記のようになります。
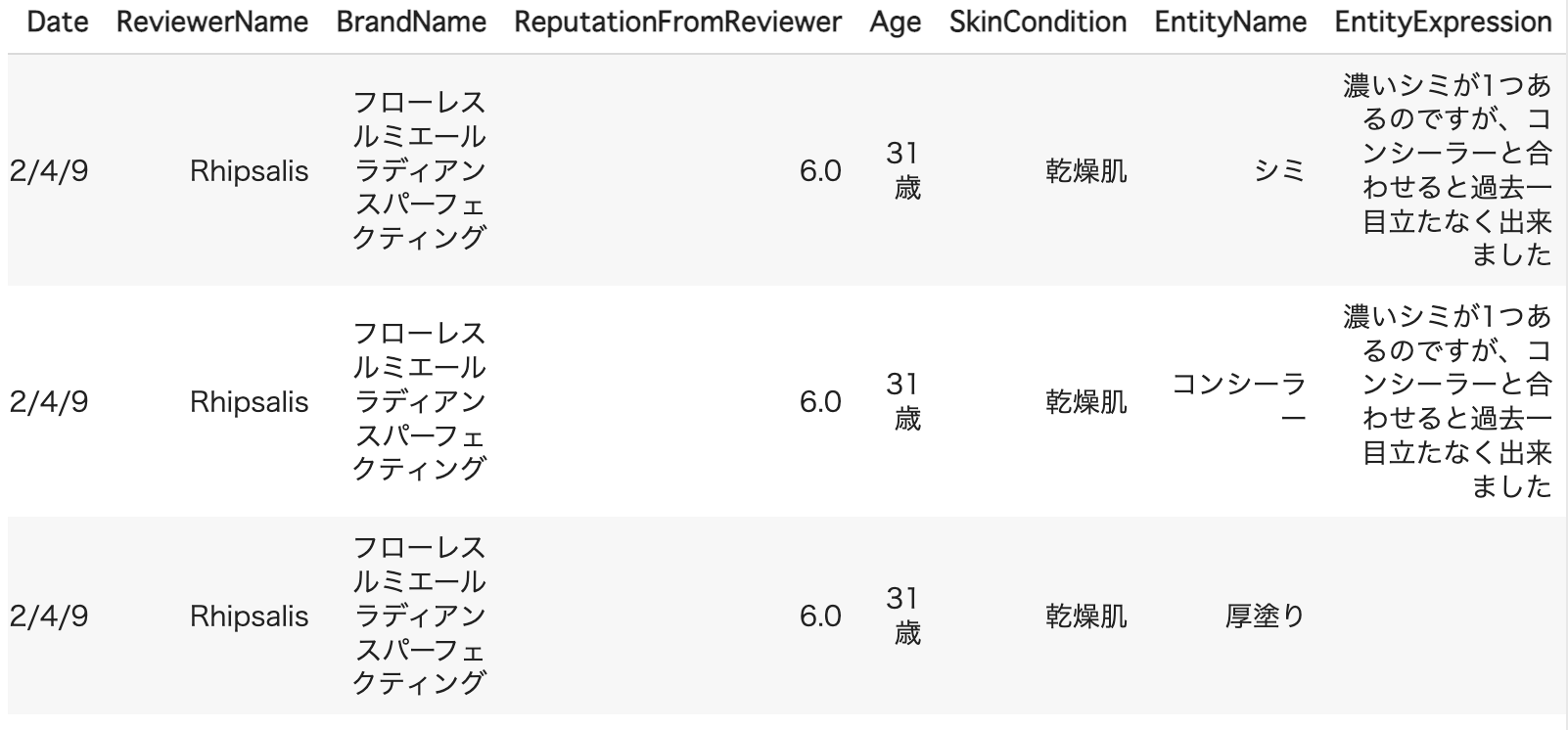
結果、Entityに対し、文章中での表現と紐付けることができたため、分析過程で関心があるエンティティを見つけた際に、実際にどのように言及しているかを確認できます。
弊社で利用する一例ですが、例えば対象のエンティティはかなりポジティブに言及されているか、レビュワーはEntityをどのように評価し、どのような点を評価しているか確認することが出来るのが利点になります。
エンティティ分析結果と結合する
その結果を第2回目のエンティティ分析結果と結合する処理を実行します。
レビューに関する情報(レビュー日やレビュワー名など)とエンティティ名を結合キーに設定します。
# 構文解析の結果を、元のData Frameと結合する
Result = pd.merge(
EntityEmotion, RelationshipEntityExpression,
how="inner",
on=["Date", "ReviewerName", "BrandName", "ReputationFromReviewer", "Age", "SkinCondition", "EntityName"]
)
Result
最後に重複行を省く処理を実装するとより分かりやすくなります。
Duplicated = Result.drop_duplicates(
subset=["Date", "ReviewerName", "BrandName", "ReputationFromReviewer", "Age", "SkinCondition", "EntityName"]
)
Duplicated
結果、エンティティ分析結果と構文解析の結果を紐付けることができました。
関心のあるエンティティがレビュー文章中でどのように言及されているか、エンティティ分析結果と紐付けることができました。関心のあるエンティティがどのように評価されているか、どのような点が評価されているか、判断する上で非常に有益です。
どのように活用できるか
繰り返しになりますが、弊社では主にエンティティ分析と関連付けて処理をしています。
関心のあるエンティティがどのように評価されているか、どのような点が評価されているか、分析するために処理を実行しています。
まだ、弊社では経験不足なため、今回は採用していませんが、品詞分析を効果的に活用することで、下記のような処理も出来ると思います。
-
どのように評価されているか
形容詞や形容動詞を抜き出して評価する -
どのように評価・利用しているか
動詞を中心に抜き出して評価する
上記の考え方はマーケティング分野だけでなく、言語入力型のエンジンでも有効です。ユーザーが文章や口頭で話した内容を機械が読み取り処理を行う場合、構文解析結果、特に形態素解析の結果を活用することで、指示内容をより正確に理解できることにつながります。
次回について
全4回の記事を投稿しておりますので、下記リンクから参照ください