はじめに
ヴェネクト株式会社のディレクター 小峰です。
今回の分析では”感情分析”を扱います。感情分析ではインプットした文章中に含まれる要素から、ポジティブ/ネガティブ、どちらの方向性で文章が書かれているかを判断します。
その結果は様々な分野に活用できます。例えば、オンラインでの問い合わせであれば、「これはポジティブ/ネガティブどちらの意見か」を事前に判断できるため、対応を迅速・効率的に行うことに活かせます。また、SNSのような社会の意見を広く収集できる場所から意見を収集する際は、「対象のトピックに対するポジティブ/ネガティブな意見の分布はどうか」を定量的に分析することができます。
プログラム実行環境
今回はPythonを利用します。Versionは3.7を採用します。
先に必要なPackageを書き出すと下記の通りになります。
# DataFrame変数を処理に活用するため、Importします
import pandas as pd
import numpy as np
# Excelで取得したデータを処理するため、Importします
import xlrd
# 以下はGCPに接続し、APIでやり取りをするため、各種GCP関連のPackageをImportします
from google.cloud import language_v1
import os
from googleapiclient.discovery import build
from google_auth_oauthlib.flow import InstalledAppFlow
from google.auth.transport.requests import Request
from google.oauth2.credentials import Credentials
from googleapiclient import discovery
from google.cloud import storage
GCPの「Natural Language API」の利用
また、自然言語処理はGCPの「Natural Language API」を利用します。そのため、GCPのプロジェクトを立ち上げ、課金を有効にし、API利用の認証取得と「Natural Language API」の有効化が必要です。
実際の設定方法ですが、公式のHelpを参考にしてください。
GCP|すべてのクイックスタート
https://cloud.google.com/natural-language/docs/quickstarts?hl=ja
GCP|クイックスタート: Natural Language API の設定
https://cloud.google.com/natural-language/docs/setup?hl=ja
インプットするデータ
取得データの解説
サンプルとして、レビューサイトに記載されている、化粧品の商品レビューを対象にします。レビュー文章だけでなく、レビュー記入者の名前とレビューが記入された日付を取得します。レビューが記載されたExcelをPythonで読み込み、PandasのData Frame変数に変換し、分析を実行します。

インプットに向けた加工
エンティティ分析はレビュー文1つずつ実行します。そのため、Excelからデータを読み取り、レビューの一覧を格納したData Frame変数を、レビュー1文づつに分解します。成果物を扱いやすくするために、Dict変数を採用します。Keyにレビュー記入者の名前とレビューが記載された日付を設定し、各レビューをユニークに識別できるようにし、Valueにレビュー文を導入します。
下記のScriptを実行し、インプットするDict変数を得ます。
Reviews = {}
for DF in ListOfReviews:
for Index, Row in DF.iterrows():
R = Row["内容"]
R = R.replace('\n', '')#改行文字\nを削除する
R = R.replace('\u3000', '')
I = Index
Reviews[I] = R
Reviews
サンプルコード
サンプルコード例
最初にサンプルコードを記載し、その後解説に移ります。
def AccomodateAnnotations(Input):
Dict = {}
Client = language_v1.LanguageServiceClient()
#各レビューに対し処理を実行する
for Key, Value in zip(Input.keys(), Input.values()):
#分析対象のレビューを取得し、UTF-8に変換した上で解析処理を行う
Text = Value
Document = language_v1.Document(content=Text, type_=language_v1.Document.Type.PLAIN_TEXT)
Response = Client.analyze_sentiment(request={'document': Document})
#各レビューの判別結果を取得し、分析結果をDict変数に格納する
#Keyはレビュー結果のIndexを指定し、Valueに判別結果を指定する
Annotation = Response.document_sentiment
Magnitude = Annotation.magnitude
Score = Annotation.score
Dict[Key] = {
"ReviewSentimentScore":Score,
"ReviewSentimentMagnitude":Magnitude
}
return Dict
解説
最初に、分析結果を格納するためにDict変数を定義します。入力した文章に設定したID番号をKeyに格納し、感情分析の結果をValueに設定することで、事後的に処理を容易にするためにDict変数を採用しています。
ClientはGoogleが提供するAPIのためのPackageを利用しインスタンスを生成するために宣言しています。
Document部分で、感情分析を行う文章を定義しています。パラメータcontextで分析対象の文章を定義し、パラメータtypeで分析対象は通常の文章であることを宣言します。
※通常の文章はPLAIN TEXTで対応します、それ以外にもHTMLも対応可能です。
GCP|Package Reference |Type
https://cloud.google.com/natural-language/docs/reference/rpc/google.cloud.language.v1#google.cloud.language.v1.Document.Type
API経由で分析対象の文書を送信し、結果を受け取る処理をanalyze_sentimentで実行します。入力したい文章の特性をdict変数で定義します。今回は特にオプションを利用せず、分析対象文書を指定するdocumentのみ定義しています。
感情分析の結果、下記のようなレスポンスがあります。
{
"documentSentiment": {
"score": 0.2,
"magnitude": 3.6
},
"language": "en",
"sentences": [
{
"text": {
"content": "Four score and seven years ago our fathers brought forth
on this continent a new nation, conceived in liberty and dedicated to
the proposition that all men are created equal.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.8,
"score": 0.8
}
},
...
}
文章に対する感情分析の結果は "documentSentiment" 内に格納されます。
結果は、"score"と"magnitude"の2者で示されます。それぞれ、公式のHelpから定義を引用します。
-
score
-1.0(ネガティブ)~1.0(ポジティブ)のスコアで感情が表されます。これは、テキストの全体的な感情の傾向に相当します。
Scoreは感情表現の方向性を示します。単純に、-1ほどネガティブな文章、1ほどポジティブな文章、0だと中立であるとみなして良いです。
-
magnitude
指定したテキストの全体的な感情の強度(ポジティブとネガティブの両方)が 0.0~+inf の値で示されます。score と違って、magnitude は正規化されていないため、テキスト内で感情(ポジティブとネガティブの両方)が表現されるたびにテキストの magnitude の値が増加します。そのため、長いテキスト ブロックで値が高くなる傾向があります。
magnitudeは感情表現の方向性を示します。magnitudeが高いほど、感情表現の頻度が高く、強い表現をされているとみなせます。
GCP|Natural Languageの基本|analyzeSentiment レスポンス
https://cloud.google.com/natural-language/docs/basics?hl=ja#interpreting_sentiment_analysis_values
その結果をDictに格納し、そのDictを返すことで処理を完了します。
分析結果の活用
最初に扱いやすくするために、DataFrame変数にまとめてみます。
DF_Annotation = pd.DataFrame(
Annotation.values(),
index = Annotation.keys()
)
DF_Annotation = DF_Annotation.reset_index()
DF_Annotation = DF_Annotation.rename(
columns={
"level_0":"Date",
"level_1":"ReviewerName",
"level_2":"BrandName",
"level_3":"ReputationFromReviewer",
"level_4":"Age",
"level_5":"SkinCondition"
}
)
DF_Annotation = DF_Annotation.astype({
"Date":"object",
"ReviewerName":"object",
"BrandName":"object",
"ReputationFromReviewer":"object",
"Age":"object",
"SkinCondition":"object",
"ReviewSentimentScore":"float128",
"ReviewSentimentMagnitude":"float128"
})
DF_Annotation
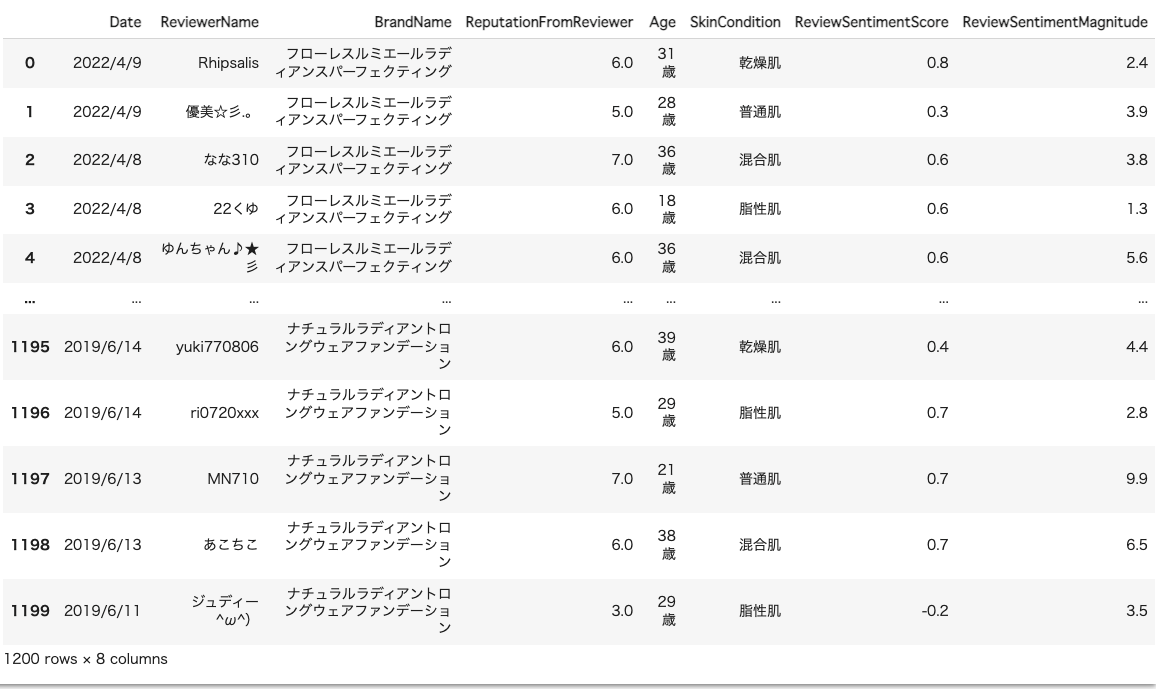
結果、レビューごとに、レビュワーの特性と、感情表現(方向性と強さ)を整理することができました。
下記はサンプルですが、感情表現ごとにカテゴリ分けすることもできます。
def JudgeAnnotation(DF):
if DF["ReviewSentimentMagnitude"] >= 3 and DF["ReviewSentimentScore"] >= 0.3:
return "ポジティブ"
elif DF["ReviewSentimentMagnitude"] >= 3 and DF["ReviewSentimentScore"] <= -0.3:
return "ネガティブ"
elif DF["ReviewSentimentMagnitude"] >= 3 and DF["ReviewSentimentScore"] > -0.3 and DF["ReviewSentimentScore"] < 0.3:
return "ポジティブ|ネガティブの両論を併記"
else:
return "感情的な表現を避ける"
DF_Annotation2 = DF_Annotation
DF_Annotation2["ReviewSentimentCategory"] = DF_Annotation2.apply(JudgeAnnotation, axis=1)
DF_Annotation2
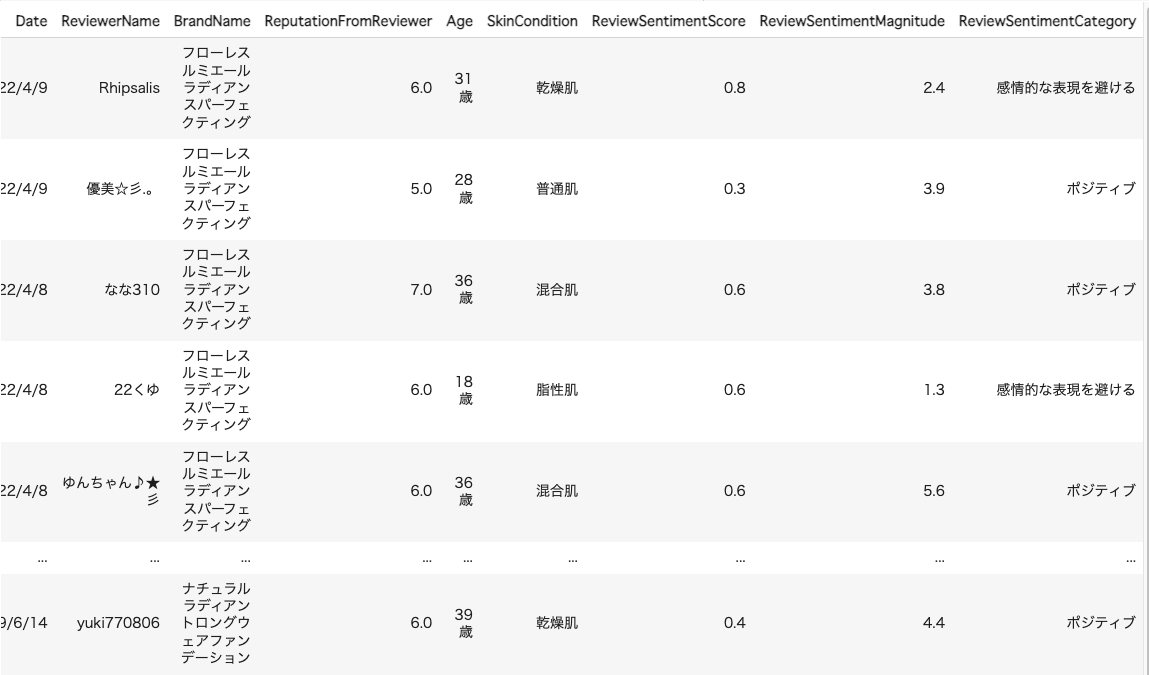
決定木など、カテゴリデータのほうが望ましい分析の際や、クライアント提出の際にわかりやすさを求められる場合などは、選択肢に入ると思います。
下記はサンプルですが、レビュー対象の商品に対し、平均的な感情表現のスコアや感情表現の強さをクロス集計に活かしています。
BrandPositiveNegative1 = pd.pivot_table(
ReviewSummary,
index = "BrandName",
values = ["ReputationFromReviewer", "ReviewSentimentScore", "ReviewSentimentMagnitude"],
aggfunc=np.mean
)
BrandPositiveNegative1
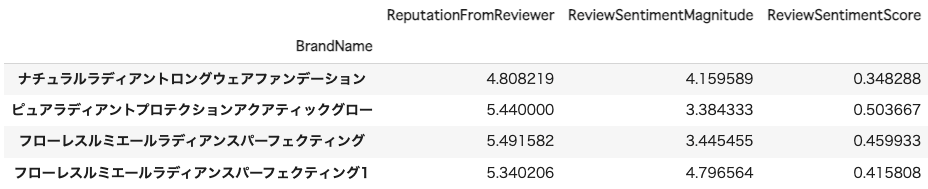
上記は非常にシンプルな例ですが、「投稿者の属性やタイミング、様々な条件」など、投稿に影響を与える可能性のある要素に対し、実際にどのような影響を与えるか、回帰分析によって相関性を調査することや、クロス集計やベイズ統計などにより分布の変化を取得することは、非常に有意義な分析になると思います。
どのように活用できるか
弊社では、投稿やコメント、レビューに対し、感情分析を利用して点数化しています。最後に述べたように、回帰分析やベイズ統計と組み合わせることで、どのような要素が投稿やコメント、レビューに対しポジティブ/ネガティブな影響を与えるか分析することができます。
それ以外にも、CRMや言語エンジンと組み合わせることで、投稿やコメント、レビューのポジティブ/ネガティブな記載内容に応じて、対応を変化させ、より効果的・効率的な対応を行うことにも活用できると思います。
次回について
全4回の記事を投稿しておりますので、下記リンクから参照ください