目的
概要
ヴェネクト株式会社のディレクター 小峰です。
今回の記事では、Google SpreadsheetのデータをPythonで取得する方法をご紹介します。
VENECT内での活用事例を踏まえつつ、下記の要素を説明します。
- どのPackageを利用すべきか
- アカウント認証をどのように行うか
- Google Spreadsheetのデータをどう取得するか
- 活用しやすいようにDataFrame変数に加工する
利用例
Google Spreadsheetに記載される情報をBigQueryに送信するために利用しています。担当者が手動で入力・管理したい情報をGoogle Spreadsheetのテンプレートで管理し、PythonのアプリケーションでBigQueryに送信しています。そのデータをシステム側で処理し、必要なデータに加工しています。
プログラム実行環境
利用するPackage
Google Spreadsheetのデータにアクセスするために、gspread というPackageを利用してデータ取得を行っています。Google公式が提供しているPackageよりも必要なデータにアクセスする処理がシンプルなので、こちらをおすすめします。
インストール方法
pipで配布されていますので、下記のコマンドをコマンドプロンプト(MS)やターミナル(MAC)で実行すれば取得することができます。
pip install gspread
API利用前の準備
GCPAuth情報の取得方法
Spreadsheet APIですが、GCPのAuth情報が必須になります。そのため、GCPのAuth情報を取得するための手順を記載します。
GCPのプロジェクトを作成する
作成手順は下記の公式Helpをご確認ください
GCP|プロジェクトの作成と管理
https://cloud.google.com/resource-manager/docs/creating-managing-projects?hl=ja
API接続用の認証取得
APIでリクエストを行う際に、GCP認証用のJsonファイルが必要になります。GCPのプロジェクトを作成後、下記の手順で認証用Jsonファイルを取得できます。
-
ページ左側のメニューから「APIとサービス」>「認証情報」を選択する
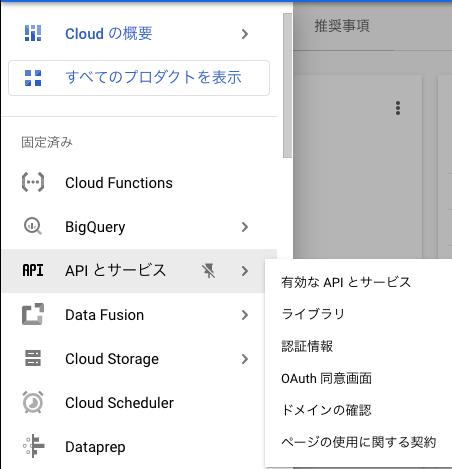
-
認証情報ページが表示されるので、ページ上部の「+ 認証情報を作成」を選択する。次にサービスアカウントを選択する
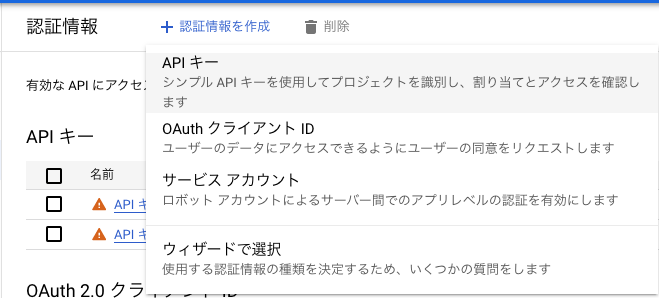
-
必要項目を設定後、「完了」ボタンを押す
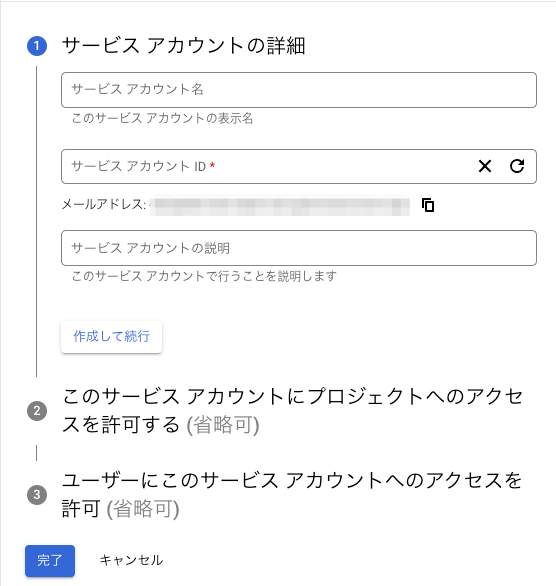
-
「サービスアカウント」の項目にある作成したアカウントを選択する
-
ページ上部のメニューにある「キー」を選択し、「鍵を追加」を選ぶ
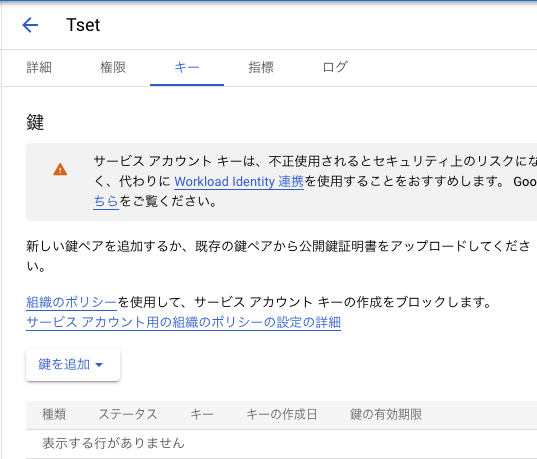
-
「JSON」形式を選択し作成、作成が完了すればAuth情報を記載するJSONファイルをダウンロードできる

結果、認証情報を記載したJsonが得られるため、管理しやすい場所で保管してください。
APIの有効化
SpreadsheetのAPI利用には、GCPの側で下記の2つのAPIを有効化する必要があります。
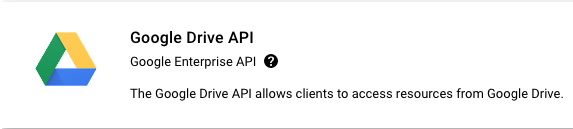
- Google Drive API
- Google Sheets API
設定方法ですが、下記の手順です。
-
「APIとサービス」>「有効なAPIとサービス」から有効化APIの選択画面に遷移する
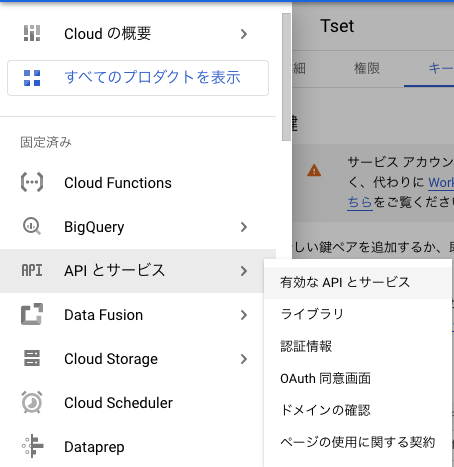
-
ページ上部の「+ APIとサービスの有効化」を選択する
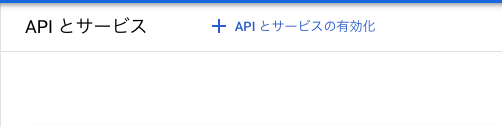
-
APIライブラリに遷移するため、上記の2つのAPIを検索し、有効化する

対象SpreadsheetにAPIアクセスを許可する
APIによるスプレッドシートへのアクセスですが、 CGCPAuth情報の取得方法 で取得したJsonファイルに記載されるGoogleアカウントより行われます。
認証用のJsonファイルを確認し Client_email の項目に記載されるGmailアカウントをコピーしてください。
その後、APIでアクセスさせたいGoogle Spfreadsheetを開き、下記の手順で対象のアカウントに権限を付与してください。
-
右上の「共有」ボタンを押す

-
「ユーザーやグループを追加」の欄に該当のGamilアカウントを貼り付ける

-
権限を「編集者」にし「送信ボタンを押す」
上記で、APIを利用するための準備は完了になります。
サンプルコード
次にPythonを利用してGoogle Spreadsheetの情報を取得するサンプルコードを記載します。
利用するPackage
今回の処理では、下記のPackageを利用します。
import pandas as pd
import numpy as np
import gspread
from oauth2client.service_account import ServiceAccountCredentials
import pytz
from google.cloud import storage
import os
Packageの解説をします。
-
Pandas
取得したGoogle Spreadsheetの データをDataFrame変数に加工するために利用します
その結果、不要列と不要行の削除・列単位でのデータの加工など、実用的な処理を行うことができます
VENECTでは、一度DataFrame変数に加工し適切な処理をした上でBigQueryに送信し業務に活用します。
DataFrame変数に加工することでTable形式への変換もスムーズに進みます -
Numpy
numpyに組み込まれている関数を利用します
-
gspread
今回のGoogle SpreadSheetのデータ取得の核となるPackageです
データ取得・データの変換まで一括で行ってくれるためかなり利便性が高いです- ※Google公式のPackageを採用しても処理は可能ですが、gspreadの方がシンプルで使いやすいです
-
ServiceAccountCredentials
GCPの認証に利用します -
Storage
GCPの認証に利用します
-
OS
環境変数に認証用アカウントを設定するために利用します
認証情報の設定
下記がサンプルコードになります。
Auth = 認証用のJsonファイルのPath
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = Auth
storage_client = storage.Client()
buckets = list(storage_client.list_buckets())
scope = ['https://spreadsheets.google.com/feeds','https://www.googleapis.com/auth/drive']
credentials = ServiceAccountCredentials.from_json_keyfile_name(Auth, scope)
Client = gspread.authorize(credentials)
Client変数にGoogle Spreadsheetの接続情報が格納されます。
Google Spreadsheetの情報を取得する
先にサンプルコードを記載します。gspreadを利用することでかなりシンプルに取得できます。
CASE1|シート内のすべてのセルから情報を取得する
SpreadSheet = Client.open_by_key(”Google Spreadsheetのキー”)
RawData = SpreadSheet.worksheet("シート名"])
Data = pd.DataFrame(RawData.get_all_values())
上記3行だけで、対象シートの情報を取得しData Frame変数に内容を格納できます。
1行目で対象のGoogle Spreadsheetに接続します。
キー番号は、対象シートのURLに記載されていますので、そちらから取得してください。
https://docs.google.com/spreadsheets/d/”ID番号”/edit#gid=0
2行目で対象のシートに接続します。
3行目で対象シートのすべてのセルの情報を取得します。
この際に、下記のように2重のList変数で情報を取得します。
[
[1行目の要素(セル毎にList要素として出力する)]
[2行目の要素(セル毎にList要素として出力する)]
…..
]
一旦、細かい加工を先送りにし、DataFrame変数として定義します。(DataFrame変数に変形した方が、加工をしやすいため)
CASE2|特定のセルを指定し情報を取得する
サンプルは下記です。
SpreadSheet = Client.open_by_key(Json["SPREADSHEET_KEY"])
RawData = SpreadSheet.worksheet(Json["WorkSheet"])
Val = RawData.acell('B1').value
サンプルとして B1 を記載していますが、AI Notion形式で特定セルを指定することで情報を取得できます。
AI Notion
-
Spread Sheet API Overview
https://developers.google.com/sheets/api/guides/concepts#a1_notation -
シンプルな解説
- 以下の文法で記載します
- シート名!セル位置
- 例|sheet1|A1
-
レンジには対応していないことに注意してください。
- sheet1|A1:Z100 のように範囲指定はできません。
- レンジで情報を取得したい場合、 シート内のデータをすべて取得し、DataFrame変数での条件抽出を活用し、必要な情報にだけ取得する 処理で対処してください。
他にもシート作成やセル値の代入もgspreadは可能です。
詳細は下記の公式Helpよりご確認ください。
-
MIT|gspread
https://docs.gspread.org/en/v5.4.0/index.html
情報を加工する
以下は、不要かもしれませんが弊社で採用している加工処理を紹介します。
1行目をColumn名にする
Data.columns = list(Data.iloc[0])
Data = Data.drop(0, axis=0)
Data = Data.reset_index(drop=True)
「シート内のすべてのセルから情報を取得する」で取得したData Frame変数を対象にします。1行目をColumn名に設定し削除しています。合わせて自動設定されるIndexも削除します。
空白行を削除する
Data = Data[Data["列名"]] != 0]
Data = Data[Data["C列名"] != "0"]
Data = Data[Data["列名"]] != ""]
Data = Data[Data["列名"]] != "-"]
Data = Data.dropna(
subset=[Json["列名"]],
axis=0
)
指定した列の値が、空白や0である場合、削除する処理を行っています。
数値列内の0や空白, Nanを"-"で置換する
for Column in ["列名のリスト"]:
for i in ["", "0", 0, "Nan", "None", "-", " ", " ", " ", " "]:
Data[Column] = Data[Column].fillna(0)
Data[Column] = Data[Column].replace(i, 0)
nanを0で置換しています。
BigQueryに送信する場合、nanは文字列判定されるエラーを誘発するため、本工程はかなり重要です。
データ型を定義する
Data = Data.astype(
"データ型を指定するDict"]
)
指定したDict変数に従い型変換をします。
必須ではないですが、BigQueryにデータ送信するため、エラー回避のため、DataFrame変数の各列のデータ型を定義しています。
以上となります。お読みいただきありがとうございました。