はじめに
弊社(VENECT株式会社)では、毎年SNSやECに関するアンケートを実施し、その集計結果をもとにスライド資料をPowerPointで作成してきました。今年度、そのCSVファイル形式のアンケートデータをLooker Studioでグラフ化するプロジェクトをインターンメンバーで実施しましたので、3回の記事に分けてトピックを紹介します。
今回の記事では、CSVファイル形式のアンケートデータをLooker Studioでグラフ化するまでの流れを紹介します。
関連記事
背景
前述の通り、昨年まではアンケート結果をPowerPointを使用してスライド資料として作成してきました。この方法は、特定の年のデータを分析する上では便利ですが、年度ごとの比較や異なるアンケート項目間の比較が必要な場合に限界がありました。
従来の方法では、過去のアンケート結果と最新のデータを比較するために、異なる年度のスライドを開いて手動で並べて比較する必要があり、効率的ではありませんでした。
そこで、BigQueryを利用してアンケートデータを一元管理し、Looker Studioと連携してデータの可視化を行うことにしました。
新しいデータ管理方法のメリット
- 年度間の比較が容易:過去のデータと最新のデータを同じ画面で瞬時に比較できるようになります。
- 柔軟な分析:異なるアンケート項目をクロス集計したり、特定の項目に絞って分析することが可能です。
- 最新データの可視化:アンケート結果が更新され次第、Looker Studioでのグラフも自動的に更新されるため、常に最新の情報を元に意思決定が行えます。
このデータ管理の改善により、私たちは今まで以上に効率的で柔軟な分析が可能になり、より有益な情報を得られるようになりました。
以下は実際に作成したグラフです。 このグラフでは、年代を選択することで、その年代のSNS利用率を年度ごとに比較できます。

アンケートデータについて
アンケートの種類
アンケートには以下の種類があります。これに応じて適切にデータを管理します。
- Single Answer(単一選択)
- Multiple Answer(複数選択)
- Matrix Single Answer(行列型の単一選択)
- Matrix Multiple Answer(行列型の複数選択)
生データサンプル
以下は、実際に使用された設問と回答のデータサンプルです。
設問サンプルデータ
| Q4 | MA | 普段使用するアプリケーションを選択して下さい |
|---|---|---|
| q4c1 | 1 | LINE |
| q4s2 | 2 | |
| q4s3 | 3 |
| Q5 | MA | 投稿するアプリケーションを選択して下さい |
|---|---|---|
| q5c1 | 1 | LINE |
| q5s2 | 2 | |
| q5s3 | 3 |
回答サンプルデータ
IDは回答者を識別するための値です。
| ID | q4s1 | q4s2 | q4s3 | q5s1 | q5s2 | q5s3 |
|---|---|---|---|---|---|---|
| 001 | 1 | 1 | 1 | 0 | 1 | 1 |
| 002 | 1 | 1 | 0 | 0 | 0 | 1 |
アンケートデータの課題
弊社で活用しているWebアンケートサービスでは上述のようなアンケートデータが取得できるのですが、Looker Studioによる可視化・分析にあたって以下のような課題がありました。
-
グラフ化の制約
Looker Studioでは、回答者のデータが上記の回答サンプルデータのように横並び(回答者毎に1行でまとめられた形式)になっていると、クロス集計や複雑な分析が難しくなります。そのため、私はアンピボットすることでデータを縦型に変換する必要があると考えました。 -
設問番号の変更
同じ設問内容であっても設問番号が年によって変わることがあるため、データをBigQueryにアップロードする際に整合性を合わせる必要があります。 -
選択肢の変更
例えば、前年の選択肢に「Twitter」が含まれていたものが、今年から「X」に変わるといったケースがあります。
データの変換方法
毎年実施するアンケートデータを分析しやすくするため、データを横並びから縦並びに変換します。さらに、選択肢の重複を避けるためのマスターテーブルを作成します。これにより、年度や設問の変更に柔軟に対応しつつ、データを整理することができます。
重複データの管理とマスターテーブル
以下の図は、設問、選択肢、回答を管理するために設計したマスターテーブルのER図です。

(左図:設問、選択肢のマスターテーブル 右図:回答のマスターテーブル)
ER図の具体的な説明
上図(ER図)のように、選択肢や回答データをマスターテーブルで整理することで、データの管理が容易になります。設問や選択肢のマスターテーブルにおけるIDは独自のIDであり、アンケート実施時の設問番号や選択肢番号とは異なる場合があるため、これらの番号は別のテーブルで管理します。また、設問と選択肢の関係を保持するテーブルも用意します。回答のマスターテーブルでは、回答者IDと設問、選択肢、回答に対応する独自のIDを管理します。
上記の設問サンプルデータでは、同じ「LINE」が設問4と設問5の両方に登場しています。
- 設問4では「q4c1」
- 設問5では「q5c1」
このような重複があると管理が複雑になります。そこで、選択肢をマスターテーブルにまとめることで、データの冗長性を解消し、管理が容易になります。
マスターテーブル例
- 設問マスターテーブル
| q_id | format | question_text |
|---|---|---|
| 4 | MA | 普段使用するアプリケーションを選択して下さい |
| 5 | MA | 投稿するアプリケーションを選択して下さい |
- 選択肢マスターテーブル
| c_id | choice_text |
|---|---|
| 1 | LINE |
| 2 | |
| 3 |
- 回答マスターテーブル
| id | q_id | c_id | answer | answer_text |
|---|---|---|---|---|
| 001 | 4 | 1 | 1 | LINE |
| 002 | 4 | 1 | 1 | LINE |
| 001 | 4 | 2 | 1 | |
| 002 | 4 | 2 | 1 | |
| 001 | 4 | 3 | 1 | |
| 002 | 4 | 3 | 0 | |
| 001 | 5 | 1 | 0 | LINE |
| 002 | 5 | 1 | 0 | LINE |
| 001 | 5 | 2 | 1 | |
| 002 | 5 | 2 | 0 | |
| 001 | 5 | 3 | 1 | |
| 002 | 5 | 3 | 1 |
このように、設問マスターテーブル、選択肢マスターテーブル、および回答マスターテーブルを作成することで、データの冗長性を排除し、管理が容易になります。また、answer_textカラムを追加することで、Looker Studioでのフィルタリングや編集が簡単になります。
さらに、設問番号の変更は手作業で対応が必要です。たとえば、前年の「普段使用するアプリケーション」が設問4だったものが、今年は設問5に変更される場合があります。このような場合、自動変換だけでなく、スプレッドシートでのマスター確認作業を取り入れることで、より正確に対応します。
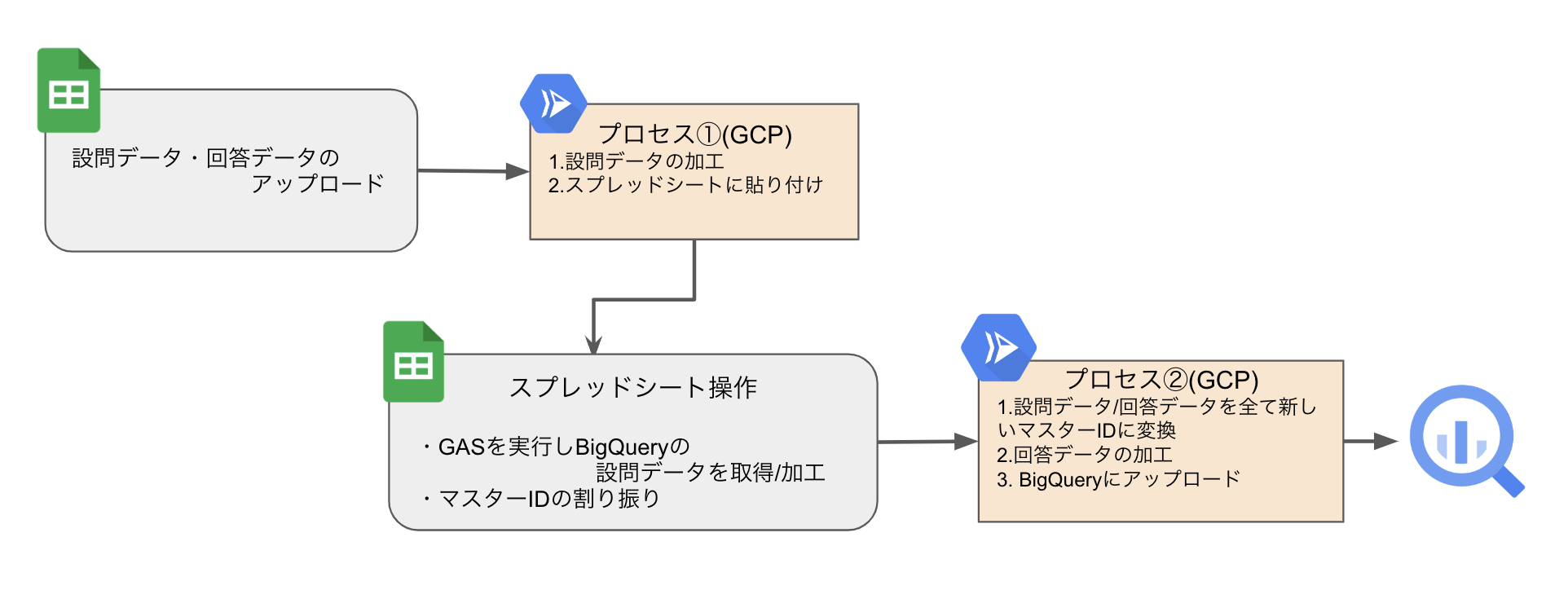
ワークフロー
大まかなデータ処理の流れは以下の通りです。
- CSVファイルからデータを取得
- データ加工・マスターテーブル化
-
スプレッドシートに出力し、マスターID(
q_id)の確認・修正 - BigQueryにデータをアップロード
- Looker Studioでグラフ表示
アップロードとデータ加工の詳細
以下は、上記のワークフローを細かく説明したものです。Google Apps Script(GAS)とGoogle Cloudを用いた、アンケートデータの自動アップロードおよびデータ変換のワークフローです。
-
GASを使用したデータのアップロード
スプレッドシートから設問データや回答データを、Google Cloud Storage(GCS)にアップロードします。 -
Cloud Functionsでのデータ加工
アップロード後、GASがCloud Functionsを呼び出し、設問データの加工が行われます(例:重複削除やデータフォーマットの調整) -
BigQueryから過去の設問データを取得
BigQueryに保存された過去の設問データが取得され、最新のアンケートデータと比較されます。 -
マスターIDの割り振り
4.1. 選択肢・設問文の一致確認
過去のデータと新しいデータが完全一致するか確認し、一致する選択肢や設問文はデータベースの適したマスターIDを振ります。4.2. 一致しないデータの手動確認
完全に一致しない選択肢や設問文は人間が手動で確認し、対応します。過去に存在しない新しい選択肢や設問には、新しいマスターIDが割り振られます。 -
GASによるデータ変換
GASが再びCloud Functionsをトリガーし、設問データと回答データの全てのデータに割り振られたマスターIDに変換され、回答データは横一列のフォーマットから縦一列に変換されます。 -
BigQueryにデータをアップロード
最終的に、変換されたデータがBigQueryにアップロードされ、Looker Studioでの視覚化に利用されます。
以下はワークフローを可視化した図です。
終わりに
本記事では、CSV形式のアンケートデータをLooker Studioでグラフ化するためのワークフローを紹介しました。BigQueryを用いたデータの一元管理と、Looker Studioでのリアルタイム可視化によって、柔軟で効率的なデータ分析が可能になりました。
特に、一人の回答が横一列に並んでいる場合、クロス集計や高度なグラフ化が難しくなるため、データを縦型に変換することで柔軟性が向上しました。これにより、行数は増えるものの、より詳細な分析ができるようになっています。
また、毎年のアンケート設問や選択肢の変更に対しても、マスターテーブルを利用することで対応しやすくなり、データ管理の負担を軽減することが確認できました。この仕組みにより、継続的なデータの管理が容易になり、迅速で正確な意思決定を支える基盤を整えることができます。
次回の記事では、GASを使ったBigQueryの処理やCloud Storageへのファイルアップロードの具体的な実装について解説する予定ですので、ぜひご覧ください。
関連記事