2022年1月11日~4月11日の3カ月の間、Aidemy機械学習マスターコースを受講。
その締めくくりとして「CNNを使用した手書き文字認識」コードを作成しました。
機械学習もプログラミングも全くの無知でしたが、3カ月頑張った集大成です。
~「業務で使用しているタクシー領収書」の金額部分の文字認識~
【結論】
まず初めに結論から。
学習の性能自体はよかったのですが、予測は全くダメでした。
金額部分の切り取りが固定されているため、数字部分が切れたり、
罫線などのノイズが多く残ったせいかと思います。
( ⇒ 前処理がうまくいっていない )
このままでは使い物になりません。
Aidemy終了後も性能向上を目指します!
【はじめに】
-
今までの業務の流れ
タクシー使用後、領収書に金額を記入(もちろん手書き)。
使用済みタクシー領収書を保管し、
月単位で「日ごと」に集計して請求処理をする。
枚数的には、10枚/日 × 1か月くらい。 -
手書き文字認識アプリが開発できれば…
タクシー領収書を社給スマホで撮影、所定のフォルダにアップする。
それらの金額部分を抜き取り、「日ごと」でエクセルに保存、月単位で集計する。
ここまでがプログラミング。
その後の請求処理のみを人間が行う、というのが目標。
参考サイト
[薬剤師のプログラミング学習日記]
(https://www.yakupro.info/entry/handwritten-digit-recognition)
【考え方、進め方】
MNISTの画像データを学習に使用。
どれだけ、タクシー領収書の金額部分の画像が、
MNISTの画像データに近づけるかがキーポイント。
今回は日にちと高速料金(普通料金とは別欄に記載)は考えず、
普通料金のみを認識させる。
業務上、読み込む領収書の全体画像は割愛させていただきます。
① 画像を読み込み、金額部分を抜き取る
② 罫線などをできるだけ目立たなくする前処理
③ 金額を一桁ずつ切り出し
④ 色々前処理し、MNISTの画像データに揃える
⑤ CNNで学習
⑥ ④を⑤で予測させる
⑦ ⑥をエクセルに出力
【実行環境の情報】
- Google colaboratory
【ファイル構造】
- テスト画像10枚をocrフォルダに格納しておく
├<MyDrive>
└<aidemy>
├<ocr> ♯画像格納フォルダ
│ ├IMG_0200.jpg
│ ├IMG_0201.jpg
│ ├IMG_0204.jpg
│ ├IMG_0203.jpg
│ ├IMG_0202.jpg
│ ├IMG_0199.jpg
│ ├IMG_0206.jpg
│ ├IMG_0198.jpg
│ ├IMG_0205.jpg
│ └IMG_0207.jpg
├finalized_model.sav ♯モデルSAVE
└model ♯本ブログで紹介するコード
【実際のコード】
① 画像読み込み、切り取り
# MyDriveからJPEGファイルを読み込み
files = glob.glob("/content/drive/MyDrive/aidemy/ocr/*.jpg")
height_resize = 4032 # 変更後の画像高
width_resize = 3024 # 変更後の画像幅
img_all = []
# フォルダ内の画像を取得し、3024×4032にリサイズ
for file in files:
print(file)
img = cv2.imread(file)
img_0 = cv2.resize(img,dsize=(width_resize,height_resize))
#左回転
img2 = cv2.rotate(img_0,cv2.ROTATE_90_COUNTERCLOCKWISE)
img_all.append(img2)
img_all_cut=[]
for i in img_all:
# img[top : bottom, left : right]
# 大まかな切り出し
i = i[2450: 2900, 1750: 2750]
img_all_cut.append(i)
~反省点・改善点~
1.スマホで領収書を画角いっぱいにして撮影しています。
当たり前ですが、同じ条件で撮影するのは難しいので、
切り出し位置を固定してしまうと切り取った画像はバラバラ…
どこか目印を決めて、そこの基準点から画像を取得したかった。
② 罫線などをできるだけ目立たなくする前処理
#罫線などの削除
img_thre = []
for i in img_all_cut:
ret,img4 = cv2.threshold(i,50,255,cv2.THRESH_BINARY_INV)
im_gray = cv2.cvtColor(img4, cv2.COLOR_BGR2GRAY)
im_blur1 = cv2.GaussianBlur(im_gray, (11, 11), 0)
im_inv = cv2.threshold(im_blur1, 150, 255, cv2.THRESH_BINARY_INV)[1]
img_thre.append(im_inv)
領収書は白色(薄いピンク)、青色の罫線、手書き金額は黒文字。
どうにかして文字のみを取得したいと思いました。
まず2値化で金額部分を浮き上がらせて、ぼかして、また浮き上がらせて…
様々な関数を使って、全体的に良くなったのが上記コードです。
~反省点・改善点~
2.値や関数の増減を次々と変える → plt.imshow()で確認
という作業を黙々と行いました。
「様々な関数を試す関数」や「ぼかし具合や閾値を試す関数」
などを作成できたら、もっと楽にできたかな、と思います。
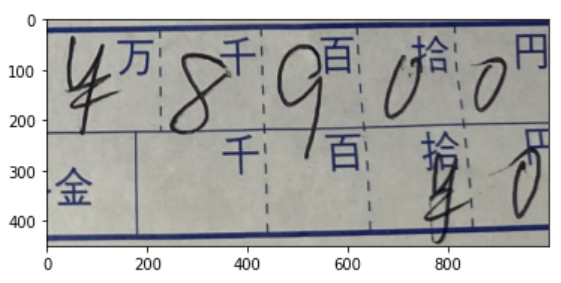
③ 金額を一桁ずつ切り出し
# 金額切り出し、img[top : bottom, left : right]、複数取得リストを作成
# 普通料金
# 画像から 万,千,百,拾,円の数字の切り出しを行う
left=[x for x in range(0,1000,200)] #[0, 200, 400, 600, 800]
right=[y for y in range(200,1200,200)] #[200, 400, 600, 800, 1000]
img_cut = []
for i in range(len(img_thre)):
for x,y in zip(left,right):
cut_img = img_thre[i][0:250, x:y]
img_cut.append(cut_img)
読み込んだJPEGを固定値で切り取っていきます。
画角が固定していればいい方法です![]()
④ 色々前処理し、MNISTの画像データに揃える
# 画像をグレースケールで読み込み→平滑化(ぼかし)→2値化→輪郭抽出
img_cut_2 = []
for i in img_cut :
img_blur1 = cv2.GaussianBlur(i, (11, 11), 0)
dst = cv2.medianBlur(img_blur1, ksize=3)
img6 = cv2.threshold(dst, 250, 255, cv2.THRESH_BINARY_INV)[1]
dst2 = cv2.medianBlur(img6, ksize=3)
imgnp = dst2[:, :, np.newaxis ]
img7 = cv2.cvtColor(imgnp, cv2.IMREAD_GRAYSCALE)
img_cut_2.append(img7)
plt.imshow(img_cut_2[1]) #下記画像
# ----- モルフォロジー変換 -----
tmp_img = []
for i in img_cut_2:
tmp_img1 = morph_transformation(i)
tmp_img.append(tmp_img1)
img_last = []
for i in tmp_img:
img9 = cv2.resize(i, dsize=(28,28))
img_last.append(img9)
② 同様、ぼかし、2値化、輪郭抽出と様々試した結果です。
やはり関数作っておけば良かった…
最後にMNIST画像に揃えるため、28×28にリサイズしています。

⑤ CNNで学習
import os
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.layers import Flatten, Dense, Dropout
from tensorflow.keras.callbacks import TensorBoard, EarlyStopping
import pickle
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator
def cnn(input_shape, num_classes):
model = Sequential()
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.3))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(num_classes, activation='softmax'))
model.summary()
return model
def preprocess(data, label_data= False, num_classes=10):
if label_data:
# 教師ラベルをone-hotベクトルに変換する
data = tf.keras.utils.to_categorical(data, num_classes)
else:
data = data.astype('float32')
data /= 255
return data
if __name__ == '__main__':
IMAGE_SHAPE = (28, 28, 1) # MNIST画像フォーマット. 28x28ピクセルのグレースケール画像
NUM_CLASSES = 10 # 出力は0~9の10クラス
log_dir = os.path.join(os.getcwd(), 'logdir')
if os.path.exists(log_dir):
import shutil
shutil.rmtree(log_dir)
os.mkdir(log_dir)
# CNNモデルの構築
model = cnn(IMAGE_SHAPE, NUM_CLASSES)
# MNISTデータセットのロードと前処理
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train.reshape((60000, 28, 28, 1)), x_test.reshape((10000, 28, 28, 1))
x_train, x_test = [preprocess(d) for d in [x_train, x_test]]
y_train, y_test = [preprocess(d, label_data=True) for d in [y_train, y_test]]
# モデルのコンパイルと学習
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
#画像に変換を適用する※1
train_gen = ImageDataGenerator(rotation_range = 11, #回転
width_shift_range = 0.3, #左右平行移動
shear_range = 1, #せん断
height_shift_range = 0.3, #上下平行移動
zoom_range = 0.3) #拡大縮小
test_gen = ImageDataGenerator()
training_set = train_gen.flow(x_train,y_train,batch_size = 64)
test_set = train_gen.flow(x_test,y_test,batch_size = 64)
history = model.fit_generator(training_set,
steps_per_epoch = 60000 // 64,
validation_data = test_set,
validation_steps = 10000 // 64, epochs
= 5)
# テストデータを使って精度を検証
score = model.evaluate(x_test, y_test, verbose=0)
print("Test loss: ", score[0])
print("Test accuracy: ", score[1])
注1. 初めは、MNISTの画像データのみで学習させました。
# モデルのコンパイルと学習
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# MNISTのみのmodel.fit
model.fit(x_train, y_train, batch_size=128, epochs=5, validation_split=0.2,
callbacks=[TensorBoard(log_dir=log_dir),
EarlyStopping(monitor='val_loss', patience=2, verbose=0, mode='auto')],
verbose=1)
そのときの結果です。
Test loss: 0.02938392385840416
Test accuracy: 0.9894999861717224
これでもいいのですが、
本コードで行った前処理画像にはノイズが多く、
MNISTだけでは足りないと判断しました。
なので、ImageDataGenerator関数を使用します。
参考サイト
[Image Processing for MNIST using Keras]
(https://medium.datadriveninvestor.com/image-processing-for-mnist-using-keras-f9a1021f6ef0)
回転、左右上下へ移行移動、せん断、拡大縮小
様々な数値を入れて学んでもらいました。
結果は…
Test loss: 0.04297330975532532
Test accuracy: 0.9854999780654907
なんと、MNISTのみのデータで学んだのとほぼ同じです!
ただ予測結果には差が出ました。
ちなみに…
CNNを選択したのは、aidemyの「教師あり学習(分類)」の添削課題に、
「手書き数字の認識・分類をするための学習器をより高い精度で作り、
与えられるデータ(MNIST)に対して手法を選び、
ハイパーパラメーターを調整して学習能力の高い学習器を作ってください。」
という課題から、ロジステック回帰、線形SVC、非線形SVM、決定木、
ランダムフォレスト、k-NNの6種類の中から 一番評価の高い手法とパラメーター
とその値 を出力した結果と、画像に対して認識率の高い結果を出す
ディープラーニングを行うCNNを比べて、僅差でCNNがよかったので、CNNとしました。
aidemy課題の結果:
学習モデル:SVC,
パラメーター:
{'C':10,'decision_function_shape':'ovr','kernel':'rbf','random_state':42}
ベストスコア: 0.9888888888888889
また、エポック数ごとの損失関数と正解率のグラフも作成しました。
参考サイト:
[ニューラルネットワークの学習過程を可視化してみよう]
(https://rightcode.co.jp/blog/information-technology/neural-network-learning-visualization)
# 学習の様子を可視化する
metrics = ['loss', 'accuracy'] # 使用する評価関数を指定
plt.figure(figsize=(10, 5)) # グラフを表示するスペースを用意
for i in range(len(metrics)):
metric = metrics[i]
plt.subplot(1, 2, i+1) # figureを1×2のスペースに分け、i+1番目のスペースを使う
plt.title(metric) # グラフのタイトルを表示
plt_train = history.history[metric] # historyから訓練データの評価を取り出す
plt_test = history.history['val_' + metric] # historyからテストデータの評価を取り出す
plt.plot(plt_train, label='training') # 訓練データの評価をグラフにプロット
plt.plot(plt_test, label='test') # テストデータの評価をグラフにプロット
plt.legend() # ラベルの表示
plt.show() # グラフの表示

学習の度に、損失値が低くなり、正解率が高くなるのがわかります。
可視化されると感覚的につかみやすくなりますね。
⑥ ④を⑤で予測させる
# 予測と表示
fig = plt.figure(figsize=(10, 10))
fig.tight_layout()
img_pred = []
for i, img in enumerate(img_last):
plt.subplot(10, 5, i+1)
tmp10 = img[np.newaxis, :, :, 1]
y=model.predict(tmp10)
pred = np.argmax(y)
img_pred.append(pred)
plt.imshow(img, cmap=plt.cm.gray_r, interpolation='nearest')
plt.axis('off')
plt.subplots_adjust(wspace=1, hspace=1)
plt.title('y_pred: {}'.format(pred))
plt.show()
np.savetxt('predict.csv', img_pred, delimiter=',')

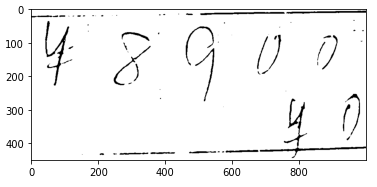
※「y_pred:数値」は予測した数値、下の画像は切り取った画像です。
¥マークは、学習させていないので、今回は無視です(汗)
たまにうまくいきませんが、今回の予測は合ってます!
他にも、

最後の0はほぼ切れているのに、0と正しく認識できています。
これがおそらくImageDataGenerator関数のおかげかと思います。
そのほかも一部ですが、無茶な数字も認識してくれました。

NG集

40数字中21数字のみ当たりました![]()
50%では業務にはとても使えません。
ちなみに、MNISTのみだけで学習させた結果がこちらです。


40数字中5数字のみ当たりました…
MNISTデータセットにおいては、CNNを使うと現在は99%以上の精度で分類できるので、
やはり前処理の結果がダメだということです。
今後もノイズ成分の除去で、予測性能の向上を目指すとともに、
高速料金、日付取得にもチャレンジしていきたいです!
【最後に】
なにもかも初体験な3カ月でした。
Pythonも、夜間や土日返上の勉強も、AIや機械学習に関する本の熟読も…
機械学習はマスターできたか不安ですが、それらに関する知識は得られたと自負しております。
データサイエンティストに憧れての受講がきっかけでしたが、
データサイエンティストにはなれなくても、
データサイエンティストと現場をつなぐ
「データサイエンスを理解しているビジネスパーソン」
にはなれたのではないかな、と思います。