STマイクロエレクトロニクス株式会社(STマイクロ)が提供しているAIキットを使用して、機械学習による画像分類を試した記事「STM32H747I-DISC0を用いたAI画像分類」のニューラルネットワーク(NN)モデル作成部分をまとめた備忘録です。
STM32H747I-DISC0ボードとB-CAMS-OWVカメラを使い、撮影した果物がオレンジかバナナかを分類できるように、NNモデルを作成しました。
機械学習もPythonも初めてだったので、忘れないように記録したものです。理解できていないところもあるので、間違っている点などがあればご指摘下さい。
準備
以下のソフト構成でNNモデルを作成しました。
・Anaconda3(2021.11)
・Jupyter Notebook 6.4.3
・keras 2.3.1
・numpy 1.19.2
・python 3.6
・tensorflow 2.1.0
Anaconda3以外は、Anaconda Navigatorからインストールしました。pythonのバージョンはtensorflowとの関係で3.6に下げています。インストールの詳細は割愛します。
データの収集
学習用画像として、オレンジの画像10枚とバナナの画像10枚をフリー写真素材からダウンロードしました。
評価用画像として、オレンジの画像5枚とバナナの画像5枚をフリー写真素材からダウンロードしました。
オレンジとバナナという分類しやすい物にしたので、データ収集はかなりサボりました。
コードの作成
コードの作成にはJupyter Notebookを使用しました。
必要なモジュールのインポート
オレンジとバナナを分類するNNモデルを作成するのに、必要なモジュールをインポートします。
1. import os
2. import tensorflow
3. import keras
4. import numpy as np
5. %matplotlib inline
6. import matplotlib.pyplot as plt
7. from PIL import Image
8. from keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout
画像の読み込み
収集した学習用画像を読み込み、kerasで扱えるようにnumpy配列に変換します。
10. imsize = 224
11. num = 0
12. # 画像を格納するnumpy配列をゼロ初期化
13. image_datas = np.zeros((20, imsize, imsize, 3), dtype=np.int)
14.
15. # オレンジ
16. fruit_num = os.listdir("./dataset/orange/")
17. for fn in fruit_num:
18. image = Image.open("./dataset/orange/" + fn)
19. reimage = image.resize((imsize, imsize))
20. image_datas[num] = np.array(reimage)
21. num += 1
22. # バナナ
23. fruit_num = os.listdir("./dataset/banana/")
24. for fn in fruit_num:
25. image = Image.open("./dataset/banana/" + fn)
26. reimage = image.resize((imsize, imsize))
27. image_datas[num] = np.array(reimage)
28. num += 1
29.
30. # 正解データを作成
31. ans_datas = np.array([0,0,0,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1])
32.
33. # 確認のため配列を内容を表示
34. fig, ax = plt.subplots(2, 10, figsize=(25, 4))
35. for i in range(2):
36. for j in range(10):
37. ax[i][j].imshow(image_datas[i*10+j])
10行目は入力画像のサイズを設定しています。NNモデルを取り込むSTマイクロのfood detectionデモで使用するプログラムが224x224のカラー画像を入力画像フォーマットとしているため、画像サイズを合わせています。
15-28行目でファイルから画像を読み込み、オレンジの画像10枚とバナナの画像10枚の順で、image_datas配列に入れます。
31行目でオレンジが0、バナナが1の正解データを作成します。
同様に評価用画像も、test1_datasというnumpy配列に変換します。
39. num = 0
40. # 画像を格納するnumpy配列をゼロ初期化
41. test1_datas = np.zeros((10, imsize, imsize, 3), dtype=np.int)
42.
43. # 評価用画像
44. fruit_num = os.listdir("./dataset/test1/")
45. for fn in fruit_num:
46. image = Image.open("./dataset/test1/" + fn)
47. reimage = image.resize((imsize, imsize))
48. test1_datas[num] = np.array(reimage)
49. num += 1
50.
51. # 正解データ作成
52. test1_ans = np.array([1, 1, 1, 0, 1, 1, 0, 0, 0, 0])
53.
54. # 確認のため配列を内容を表示
55. fig, ax = plt.subplots(1, 10, figsize=(25, 4))
56. for j in range(10):
57. ax[j].imshow(test1_datas[j])
モデルの構築
画像分類に適していると言われる畳み込みニューラルネットワーク(CNN)層、プーリング層、全結合層を使用したモデルを構築します。注意として、ここでのモデル構築がNNモデルのサイズに影響するので、STM32H747I-DISC0ボードのflashに収めるためサイズが大きくならないように構築する必要があります。
59. # シーケンシャルモデルを選択
60. model = keras.models.Sequential()
61. # 入力データ量削減
62. model.add(MaxPooling2D(pool_size=(2, 2), input_shape=(imsize, imsize, 3)))
63. model.add(Conv2D(16, (3, 3), strides=(2, 2), activation='relu'))
64. model.add(MaxPooling2D(pool_size=(2, 2)))
65. model.add(Conv2D(16, (3, 3), strides=(2, 2), activation='relu'))
66. model.add(MaxPooling2D(pool_size=(2, 2)))
67. model.add(Flatten())
68. model.add(Dense(256, activation='relu'))
69. model.add(Dropout(0.2))
70. # 出力はオレンジとバナナの2つ、活性化関数はsoftmax
71. model.add(Dense(2, activation='softmax'))
72. model.compile(optimizer='adam',loss='sparse_categorical_crossentropy', metrics=['accuracy'])
73. model.summary()
kerasのシーケンスモデルを使用します。最初に62行目で入力データ量を削減してサイズが大きくならないようにしています。63行目から66行目で、CNN層とプーリング層を2回重ねています。CNN層ではサイズを抑止するためにstridesを指定して小さくしています。68行目で全結合層を行い、71行目で分類系の出力層に適していると言われるsoftmax活性化関数を指定して、オレンジとバナナの2種類を出力するようにしています。
72行目でオプティマイザー、損失関数、評価関数を指定しますが、勉強不足のためSTマイクロのfood detectionデモで指定しているものをそのまま使っています。ただし、正解データをOne-hot表現にしていないため"categorical_crossentropy"ではなく、"sparse_categorical_crossentropy"にしています。
73行目で以下のサマリーが表示されます。
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
max_pooling2d_1 (MaxPooling2 (None, 112, 112, 3) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 55, 55, 16) 448
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 27, 27, 16) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 13, 13, 16) 2320
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 6, 6, 16) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 576) 0
_________________________________________________________________
dense_1 (Dense) (None, 256) 147712
_________________________________________________________________
dropout_1 (Dropout) (None, 256) 0
_________________________________________________________________
dense_2 (Dense) (None, 2) 514
=================================================================
Total params: 150,994
Trainable params: 150,994
Non-trainable params: 0
モデルの学習
画像データを正規化して、batch_sizeは2として20回学習するように指定します。分類しやすいため直ぐに収束するので20回にしています。
75. image_datas, test1_datas = image_datas / 255.0, test1_datas / 255.0
76. history = model.fit(image_datas, ans_datas, epochs=20, batch_size=2,
77. validation_data=(test1_datas, test1_ans))
学習の結果
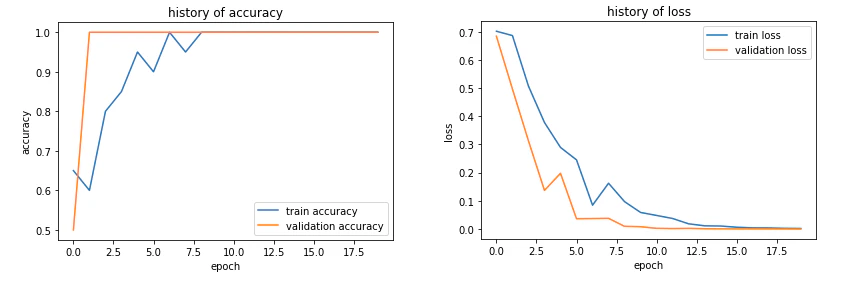
学習の結果をaccuracyとlossの推移をグラフで表示します。
79. plt.title("history of accuracy")
80. plt.xlabel("epoch")
81. plt.ylabel("accuracy")
82. plt.plot(history.history["accuracy"], label='train accuracy')
83. plt.plot(history.history["val_accuracy"], label='validation accuracy')
84. plt.legend()
85. plt.show()
86.
87. plt.title("history of loss")
88. plt.xlabel("epoch")
89. plt.ylabel("loss")
90. plt.plot(history.history["loss"], label="train loss")
91. plt.plot(history.history["val_loss"], label="validation loss")
92. plt.legend()
93. plt.show()
accuracyは1へ、lossは0へ収束しているのが分かります。
ファイルに保存
kerasのh5形式でファイルに保存します。
95. model.save("fruit_qiita.h5")
作成したNNモデルをボードへ
作成したNNモデルをSTM32H747I-DISC0ボードに焼き込み、撮影した果物がオレンジかバナナかを分類できるようにしていきます。そちらの記事は「STM32H747I-DISC0を用いたAI画像分類」を参照して下さい。