概要
ランダムフォレストを使った予測の精度に関する記事はよく出てくるがモデルのサイズや学習時・予測時の時間について載っている記事が見当たらなかったので比較してみた。
今回はscikit-learnに入っているbostonデータ(レコード数:506、カラム数:13)を使って学習・予測を行う。
RandomForestでよく扱われるパラメータのn_estimators(木の数)とmax_depth(最大の木の深さ)、レコード数を変化させて測定した。
なお、レコード数をn=506, 5060, 50600と元々の件数から増やしているが、かさ増しする際には各値をランダムに10%増減させて極力重複データを作らないようにしている。
モデルのサイズ
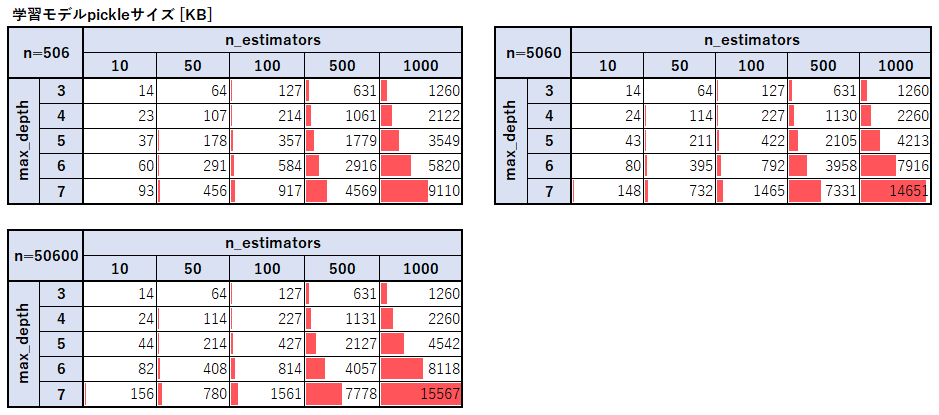
ランダムフォレストの木の数とモデルのサイズは単純に比例していることがわかる。
最大の木の深さとモデルサイズに関しては深さが1つ大きくなるごとにおよそ1.5倍~2倍になっていることが分かった。
これは二分木の最大深さが1つ深くなるごとにノードの数が高々2倍になることと、レコード数が多くなるほど分岐が増えることからも予想できる。
モデル作成時の処理時間
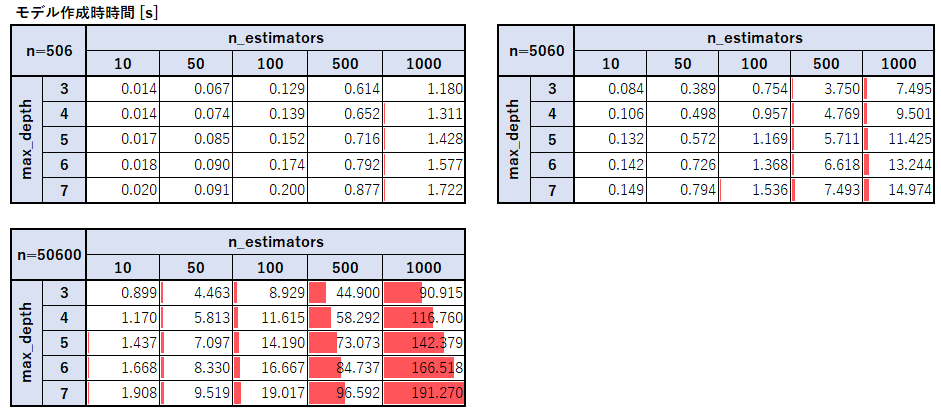
モデル作成の処理時間に関しては木の数、最大深さ、学習データサイズそれぞれに対して比例しているようだ。
予測時の処理時間
予測時はn=5060で作成した学習モデルを使用し、predict関数を使ってデータを予測する際の時間を計測した。
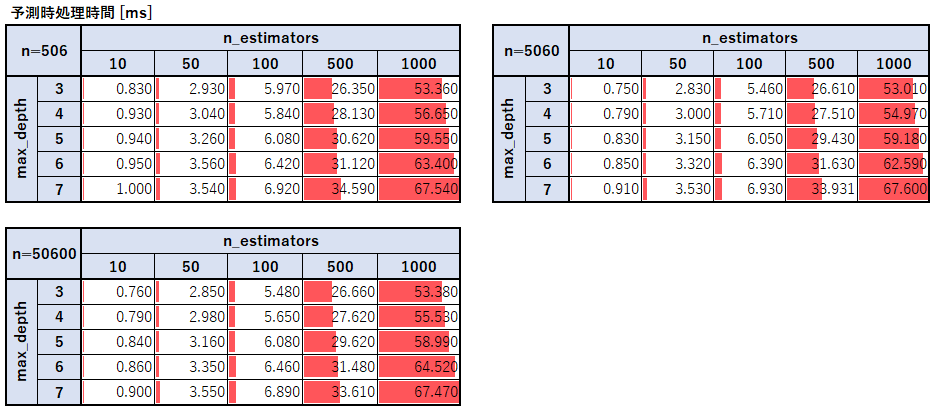
予測時の処理時間に関しても木の数と木の深さに対して処理時間は比例していることがわかる。
一方で意外なことに予測をさせるレコード数に関しては一切増加せず、試しに1億データ程で予測を行っても処理時間は変わらなかった。
最後に
本当はカラム数も変化させたかったがうまいやり方が見つからなかったので今回はスルーした。
この結果は当然データの傾向よっても変わってくると思うので参考までにしてほしい。