概要
みなさん、深層学習をやっていますか?おそらく多くの方はPython環境でPyTorchやTensorFlow, Jaxなどを使われているかと思います。
しかし、Python環境では型システムがどうしても外部ライブラリに頼ることになってしまったり、パッケージマネージャもpip以外のものだと別途自分で用意する必要があったりと不便さが残ることがあるかと思います。
そこで私は、Rustで深層学習ができたら全てが解決するのにと思い立って、深層学習フレームワークの開発を始めました。
Rustの強みとしては以下のようなものが挙げられます。
- 強力なパッケージマネージャーが標準でついてくる
- インターフェース(trait)と構造体に対するメソッドの実装などという関数形とオブジェクト指向の良いとこどり
- 所有権システムにより安全なコードが書きやすい
外にもあげようとするとキリがないですが、これだけでも非常に魅力的な言語だというのがわかると思います。
設計
基本的な設計はtinygradやluminalを参考に、最小限の種類のオペレータの組み合わせで多くの処理を表現する方針を取ろうと思います。
抽象構文木の設計
抽象構文木(AST)を表現するための構造体を定義します。具体的にはRustのenumのフィールドにBoxを持たせることによって、Rustらしい自然な構文で自己参照構造体(Cで言うとどちらかというとユニオンに近いけど)を定義できます。
pub enum AstNode {
Var(String),// 変数ノード
// 二項演算子
Add(Box<AstNode>, Box<AstNode>),
Mul(Box<AstNode>, Box<AstNode>),
Max(Box<AstNode>, Box<AstNode>),
// 単項演算子
Neg(Box<AstNode>),
Recip(Box<AstNode>),
Sin(Box<AstNode>),
Sqrt(Box<AstNode>),
Exp2(Box<AstNode>),
Log2(Box<AstNode>),
...
// 他にもいくつかの演算子を実装する
}
ここで、あえてSub(減算)やDiv(除算)を実装せずに、a - b の処理を add(a, neg(b))のように表現することで、徹底的に演算子の種類を減らします。演算子の数を減らすことは後述のRendererの種類を増やす際にコードを書く量を減らすことに直結し、迅速な対応プラットフォームの追加が実現できます。
グラフ構造の設計
グラフ構造はtinygradを参考に、子ノードをRc<T>型を使って表現します。
#[derive(Debug, Clone)]
pub struct Graph {
inputs: HashMap<String, Weak<GraphNodeData>>, // Rcの参照カウントに影響を与えないために、Weak参照で保持する。
outputs: BTreeMap<String, GraphNode>, // BTreeMapでキー順にソートされた順序を保証
shape_var_defaults: HashMap<String, isize>, // 動的shape変数のデフォルト値(必須)
}
#[derive(Debug, Clone)]
pub struct GraphNodeData {
pub dtype: DType,
pub op: GraphOp,
pub src: Vec<GraphNode>, // 入力ノード
pub view: View,
}
ShapeとView
Shapeは、テンソル(多次元配列)の形状のことであり、どの次元に幾つの要素があるかを表します。
ViewはtinygradのShapeTrackerを参考に、各軸の添え字からメモリオフセットへの変換を行う数式を構文木で表現する形で実装します。
これにより、転置(transpose)処理や要素の複製(repeat)、あるいは反転処理(flip)などをView操作のみで表現でき、時差紙のメモリ読み書きのコストが発生しないため、パフォーマンスへの影響を最小限にできます。
計算式はAstNodeの機能制限バージョンのような実装になります。
#[derive(Debug, Clone, PartialEq, Eq, Hash)]
pub enum Expr {
// 定数と変数
Const(isize),
Var(String),
// 算術演算
Add(Box<Self>, Box<Self>),
Sub(Box<Self>, Box<Self>),
Mul(Box<Self>, Box<Self>),
Div(Box<Self>, Box<Self>),
Rem(Box<Self>, Box<Self>),
}
冗長になるのでここには載せませんが、AstNodeへ変換する処理も実装しています。
そしてこれを組み合わせてView型を作ります。
#[derive(Debug, Clone, PartialEq, Eq, Hash)]
pub enum View {
// 線形な処理で表現可能な場合
Linear {
shape: Vec<Expr>, // 論理的なテンソルのサイズ
strides: Vec<Expr>, // 各次元の添え字の係数
offset: Expr, // オフセット
},
// TODO: 非線形な場合の処理を実装する
}
とりあえず線形な(添え字の値の線型結合で表せる)もののみをサポートすることにします。これだけでも、先述した複製や反転などの処理を実現可能です。
Lowererの設計
このプロジェクトの目的は、計算グラフ(computational graph)から最適化されたカーネルのソースコードを吐き出すコンパイラを作ることです。しかし、計算グラフは有向非循環グラフで、吐き出したいソースコードは木構造を持っており、本質的に異なるものです。
故に、グラフ構造をソースコードに対応する抽象構文木(AST)に変換する処理(lowering)が必要になります。
とりあえず計算する順番を把握したいので、Kahnのアルゴリズム(トポロジカルソートの変種)によって並列計算可能なグループにノードを分割し、先に計算できる順番にASTに変換するという処理を行なっています。
レンダリングとコンパイルパイプラインの設計
ASTのままソースコードを直接実行することはできません。GPU、CPUなどのデバイスの種類に関わらず、コンパイラは文字列として表現されたコードを解釈してバイナリを生成するのが一般的です。そこで、ASTを実際に実行可能なソースコード(文字列)に変換するRenderer、そしてそれをバイナリに変換するCompiler、コンパイル済みのバイナリを扱うKernelトレイトを実行し、各プラットフォーム毎にトレイト実装を生やす設計にします。
pub trait Renderer {
type CodeRepr;
type Option;
fn render(&self, program: &crate::ast::AstNode) -> Self::CodeRepr;
fn is_available(&self) -> bool;
fn with_option(&mut self, _option: Self::Option) {} // default implementation is "do nothing".
}
pub trait Compiler {
type CodeRepr;
type Buffer: Buffer;
type Kernel: Kernel<Buffer = Self::Buffer>;
type Option;
fn new() -> Self;
fn is_available(&self) -> bool;
fn with_option(&mut self, _option: Self::Option) {} // default implementation is "do nothing".
fn compile(&mut self, code: &Self::CodeRepr) -> Self::Kernel;
fn create_buffer(&self, shape: Vec<usize>, element_size: usize) -> Self::Buffer;
}
pub trait Kernel {
type Buffer: Buffer;
fn signature(&self) -> KernelSignature;
// QueryBuilderを作成してメソッドチェーンでクエリを構築
fn query(&self) -> QueryBuilder<'_, Self>
where
Self: Sized,
{
QueryBuilder::new(self)
}
}
また、Kernelに渡すアクセラレータ上のデータ、およびその集まりをそれぞれBuffer, Queryとして抽象化します。
pub trait Buffer {
// バッファの形状を取得
fn shape(&self) -> Vec<usize>;
// バッファの要素の型を取得
fn dtype(&self) -> crate::ast::DType;
// バッファの内容をバイト列として取得
fn to_bytes(&self) -> Vec<u8>;
// バイト列からバッファに書き込み
#[allow(clippy::wrong_self_convention)]
fn from_bytes(&mut self, bytes: &[u8]) -> Result<(), String>;
// バッファの総バイト数を取得
fn byte_len(&self) -> usize;
}
// カーネルへの指示をまとめる構造体
#[derive(Debug)]
pub struct Query<'a, B: Buffer> {
pub inputs: HashMap<String, &'a B>, // inputsは読み取り専用なので借用
pub outputs: HashMap<String, B>, // outputsは書き込み対象
pub shape_vars: HashMap<String, isize>, // 動的shape変数の値
}
最適化
また、高速に動作するカーネルを生成するために、グラフとAST、それぞれの段階で最適化が必要になります。こちらの記事でも紹介されていますが、最適化の例として以下のようなものが挙げられます。
グラフレベルでの最適化
- 要素ごと(element-wise)の演算ノードの融合: 一回のループ/カーネルにまとめることでメモリの読み書き回数を減らす
- 要素ごとの演算ノードと縮約演算(reduce)ノードの融合: 演算と縮約を一回のループにまとめることができる
- View変更ノード同士が連続する場合一つにまとめる
ASTレベルでの最適化
- 不要な演算の削除:
a + 0->a,a * 1->aのように意味のない演算を除去する - ループ展開とタイル化
- ループの順序入れ替え(メモリ上に連続した値であればコンパイラの自動ベクトル化の余地がある)
最適化の流れ
最適化は候補を提案するSuggesterと提案された候補を評価するCostEstimatorを使ってビームサーチを行い、最終的にコストが低くなる候補を最適化の結果として採用します。
可視化ツール
しかし、CUI環境では最適化の流れを見るのは非常に面倒です。特にグラフ構造はCUI上で描画するのは困難であり、可視化ツールがあった方が良いです。そのためegui, egui-snarlを使ってグラフ構造とその最適化の流れの可視化ツールを作成しました。
見た目はこんな感じです。
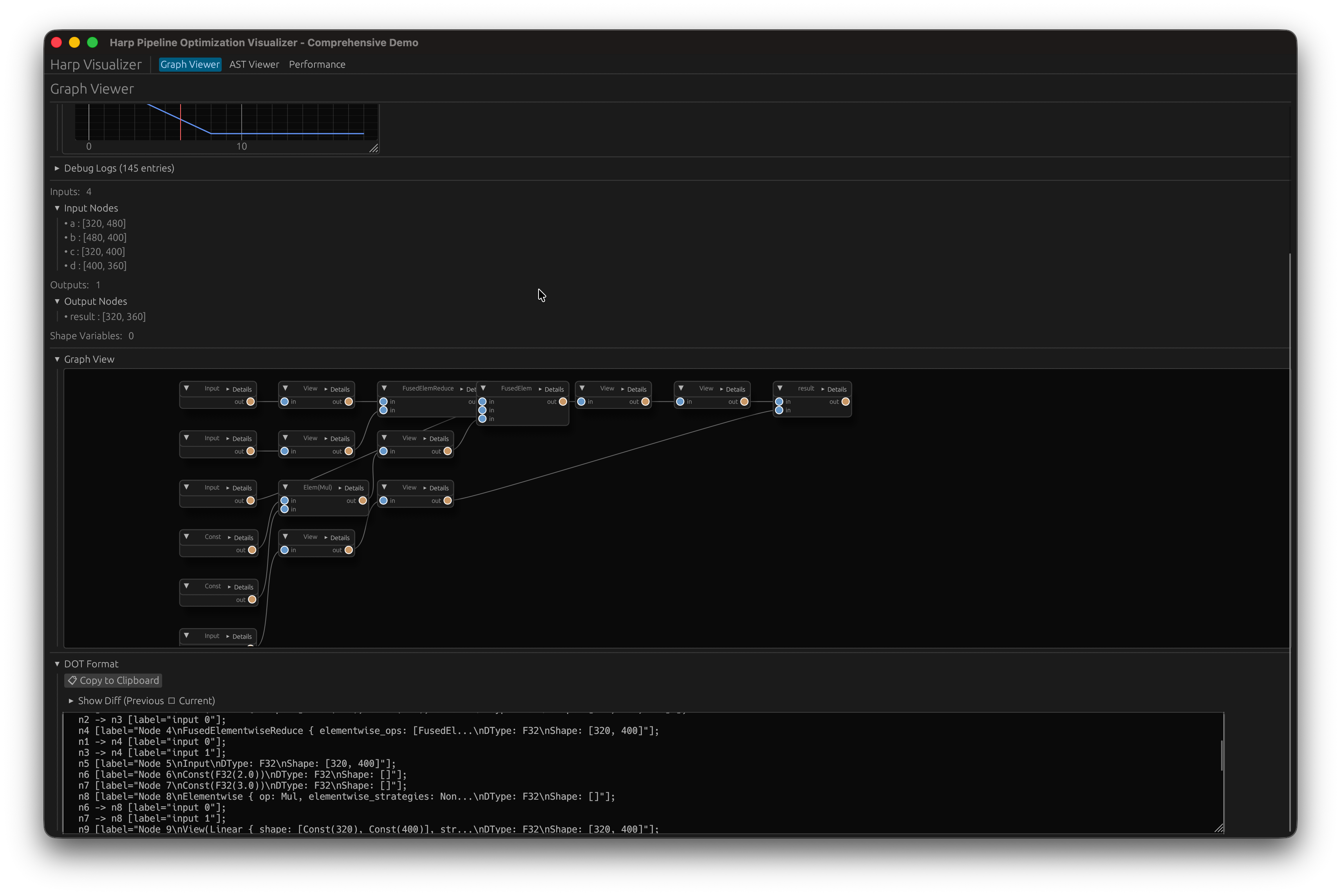
まずグラフの最適化が行われて
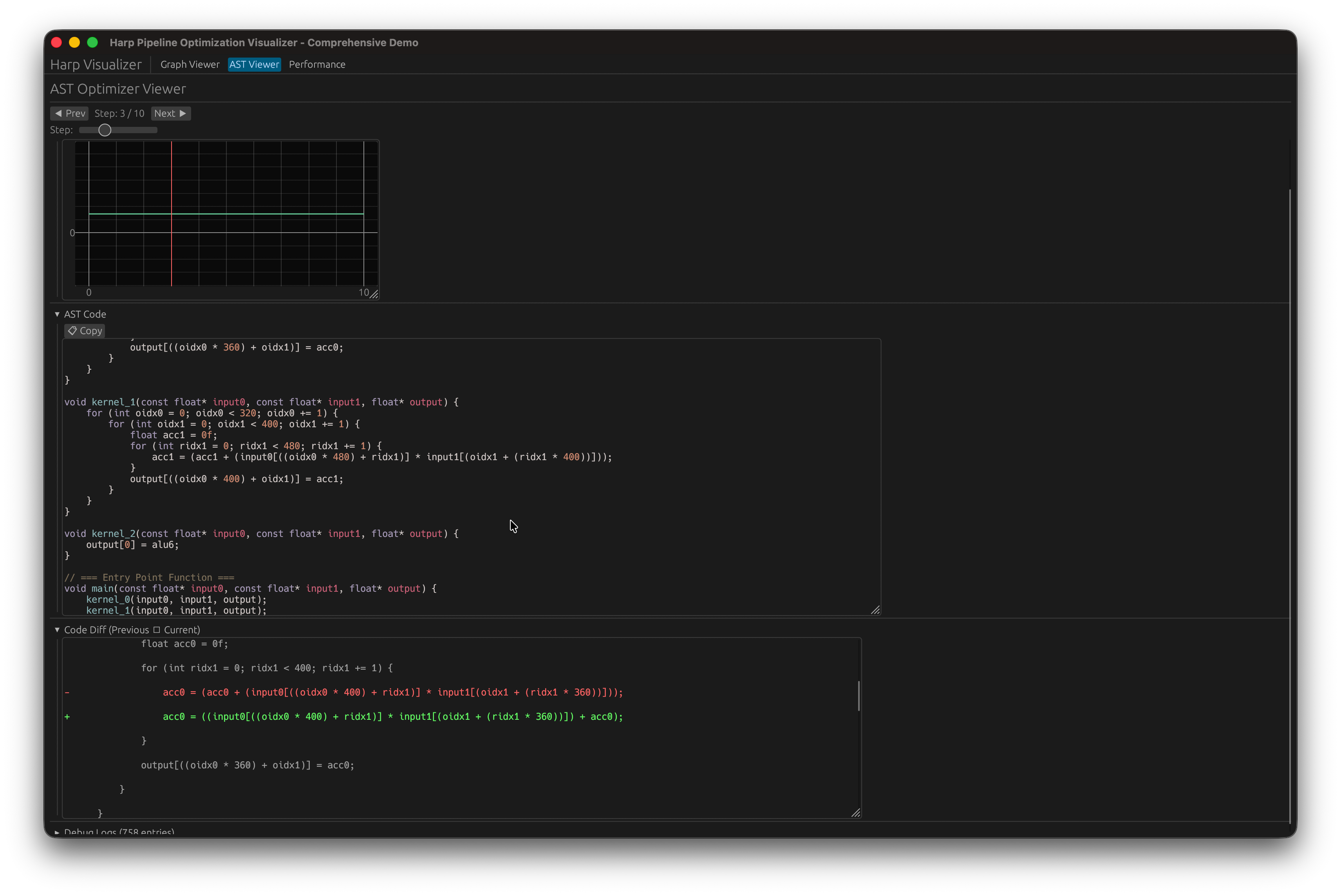
その後ASTの最適化が実行される、という二段階のアプローチを採用しています。
最適化フローの統合
現在の実装では、最適化フローは
- グラフ最適化
- Lowering
- AST最適化
の三段階に明示的に分割されています。
目的が分かれていてわかりやすい反面、それぞれのステップの最適化を相互作用させることはほとんどできません。
グラフの最適化の段階ではASTの最適化による影響を考慮することができないのです。
そこで、これらの最適化処理を統合することを考えました。
グラフ最適化とLowererの統合
グラフの一部として任意のASTを埋め込めるCustomノードを作ります。
pub enum GraphOp
{
...
Custom(AstNode>),
...
}
これによって、グラフの一部だけをloweringした状態を表現できるようになるため、グラフ最適化にLoweringを統合することができます。
グラフ最適化とAST最適化の統合
AST最適化の処理も同様に、Customノードの中にあるASTに対してこれまでのAST最適化を提案するようにしてしまえば、グラフ最適化の枠組みの中で、ASTを最適化することができます。
統合の結果
これらの統合処理により、単一の最適化フローで最終的なASTを得ることができ、Graph最適化, Lowering, AST最適化 の隔たりを超えて最適化処理の相互作用が可能になりました。動作原理としてはtinygradのそれに近いはずです。
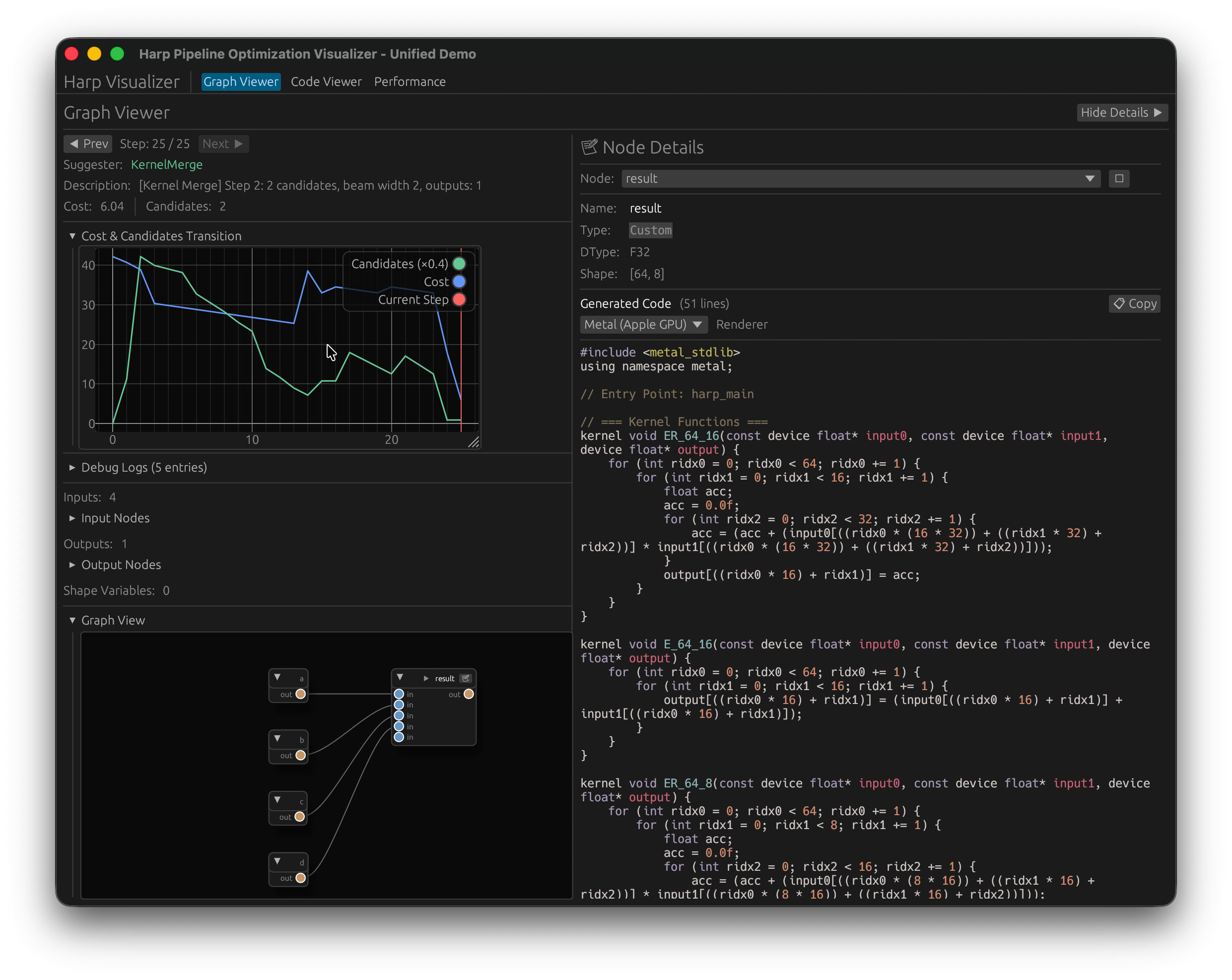
最終的にコード全体が一つのノードに融合される
最終的な成果物
今回制作したコンパイラはGitHubで公開しています。興味がある方は是非覗いてみてください。