はじめに
これまでGoogle Colab(Python)野球データ分析をする時、pandasでゴリゴリ処理していました。でも最近「DuckDB」というものを知って、ColabでもSQLが使えることを知りました。
試しに以前書いた大谷翔平の打撃分析コード(23セル)をSQL版に書き直してみたら、6セルまで削減できました。思ったより使いやすかったので記録を残しておきます。
環境
- Google Colab(無料版)
- Python 3.10
- pybaseball(野球データ取得)
- DuckDB(SQLエンジン)
インストールは簡単です:
!pip install pybaseball duckdb
これまでのpandasコード
大谷翔平の2022年打撃データを分析する時、試行錯誤しながら書いていたら23セルになっていました。
元のnotebookの問題点:
- データ抽出を何度も書き直し
-
isin()と~isin()の組み合わせが読みづらい - グラフ関数を7回も書き直している
- 型変換やNULL処理が散らばっている
正直、試行錯誤の履歴が全部残ったまま放置していました。
例えば、ヒットとアウトを分類する部分:
# 大谷翔平のデータ抽出
df_ohtani = df[df['batter'] == 660271]
# ヒットイベントの定義
hit_events = ['home_run', 'double', 'triple', 'single']
# ヒット抽出
df_ohtani_hits = df_ohtani[df_ohtani['events'].isin(hit_events)].dropna(subset=['hc_x', 'hc_y'])
# アウト抽出(ヒット以外)
df_ohtani_others = df_ohtani[~df_ohtani['events'].isin(hit_events)].dropna(subset=['hc_x', 'hc_y'])
動くには動くんですが、~(否定)やdropnaが入ると見づらくなります。
DuckDB SQLで書き直してみた
試行錯誤の履歴を整理するついでに、SQLで書き直してみました。
同じ処理をSQLで書くと、1つのクエリで完結します:
import duckdb
con = duckdb.connect()
# ヒット抽出(SQL)
df_ohtani_hits = con.execute("""
SELECT *
FROM df
WHERE batter = 660271
AND events IN ('home_run', 'double', 'triple', 'single')
AND hc_x IS NOT NULL
AND hc_y IS NOT NULL
""").df()
# アウト抽出(SQL)
df_ohtani_others = con.execute("""
SELECT *
FROM df
WHERE batter = 660271
AND events NOT IN ('home_run', 'double', 'triple', 'single')
AND hc_x IS NOT NULL
AND hc_y IS NOT NULL
""").df()
これだけです。dropnaも~も不要。WHERE句で条件を並べるだけ。
結果:23セル → 6セルに削減
良かった点
1. コード量が減った
- 元: 23セル(試行錯誤の履歴込み)
- SQL版: 6セル
グラフ描画関数を7回も書き直していたのが、1回で済みました。
2. 意図が明確
WHERE句で条件を並べるだけなので、「何をしているか」が一目でわかります。
-- これは明らか
WHERE events IN ('home_run', 'double', 'triple', 'single')
AND hc_x IS NOT NULL
-- pandas版はこう
df[df['events'].isin([...])].dropna(subset=[...])
3. pandasのDataFrameをそのまま使える
DuckDBの便利なところは、既存のpandasのDataFrameを直接クエリできることです。わざわざDBにインポートする必要がありません。
# dfはpandas DataFrame
result = con.execute("SELECT * FROM df WHERE ...").df()
打球のヒートマップ
SQLで抽出したデータを、元のnotebookと同じようにヒートマップで可視化します。
def plot_hit_vs_out(outs, hits):
# Y座標を反転
outs['hc_y'] = -outs['hc_y']
hits['hc_y'] = -hits['hc_y']
fig, axs = plt.subplots(1, 2, figsize=(20, 10))
# ファウルライン描画
def draw_foul_lines(ax):
ax.plot([125, 250], [-210, -85], 'k-', lw=3)
ax.plot([125, 0], [-210, -85], 'k-', lw=3)
# アウト
sns.histplot(data=outs, x='hc_x', y='hc_y', cmap="coolwarm",
cbar=True, ax=axs[0], binwidth=10)
axs[0].set_title('Outs')
draw_foul_lines(axs[0])
# ヒット
sns.histplot(data=hits, x='hc_x', y='hc_y', cmap="coolwarm",
cbar=True, ax=axs[1], binwidth=10)
axs[1].set_title('Hits')
draw_foul_lines(axs[1])
plt.show()
plot_hit_vs_out(df_ohtani_others, df_ohtani_hits)
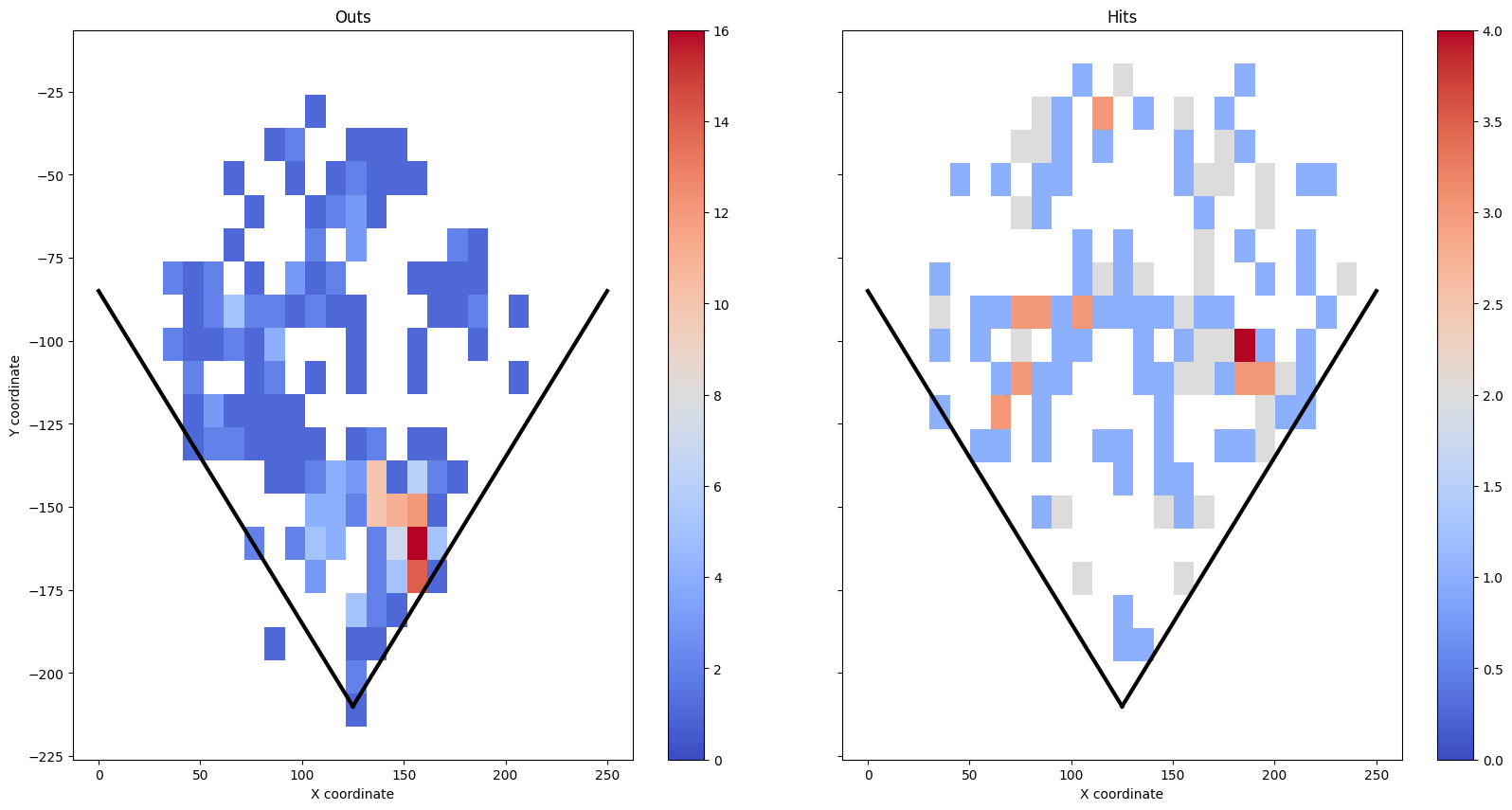
この可視化から、大谷選手の打球(ヒット&アウト)が1-2塁間に集中していることがわかります。これが内野の「大谷シフト」の根拠になっていたのかもですね。
※逆に大谷シフトのせいで、アウトが多くなっていたとも言える
今はシフトルールから、大量に内野手を1-2塁間に置けないけど。
注意点
NULLの扱い
座標データ(hc_x, hc_y)にNULLが含まれているので、WHERE句で除外します。
WHERE hc_x IS NOT NULL
AND hc_y IS NOT NULL
pandasのdropna()と同じ役割ですが、SQLの方が明示的です。
まとめ
Google ColabでDuckDB使ってみたら、思ったより便利でした。
削減効果:
- セル数: 23 → 6(約75%削減)
- コードの見通しが良くなった
- 試行錯誤が減った
元のnotebookは正直グチャグチャでしたが、SQL化するついでに整理できて良かったです。
DuckDBの良いところ:
- インストールが簡単(
pip install duckdbだけ) - 既存のDataFrameをそのまま使える
- WHERE句で条件を並べるだけ
- pandas版と同じグラフが描ける
これを機に、今まで行っていた野球データ分析もSQL化してみようと思います。