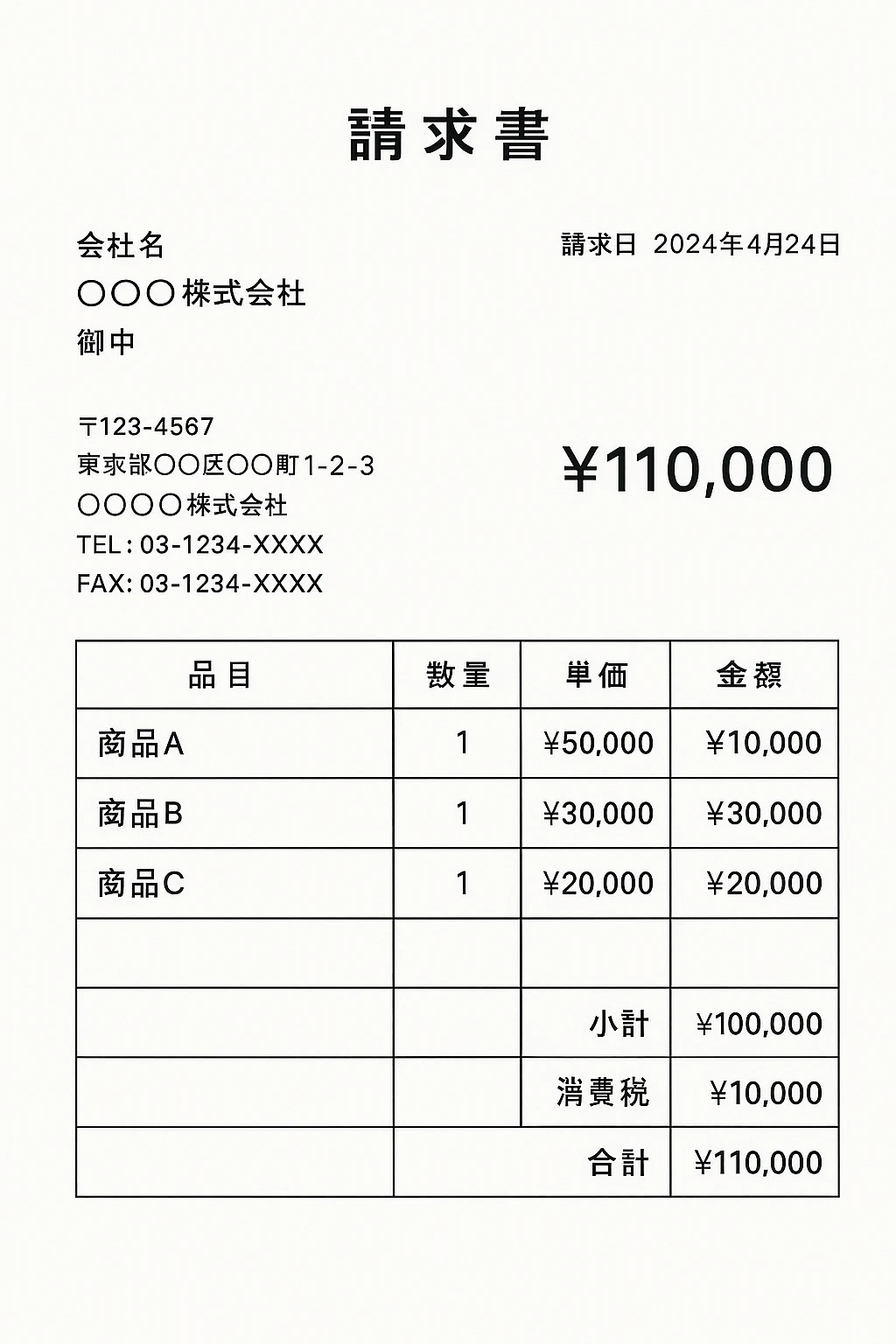
サンプルとして、ChatGPTで請求書作成しました。
これ使って、GASでOCRの勉強したいと思います。
GASのOCRの仕組みを考えて、PDF → グーグルドキュメント → スプレッドシート
の順序でやっています。
GASのOCRって、結局グーグルドキュメント経由してた気がするんで。たしか。たぶん。
GoogleドライブのPDF請求書を自動でスプレッドシート化する方法
完全無料 | コピペで使える | 初心者OK
📌 この記事で実現できること
✅ PDF請求書を自動でテキスト化(OCR)
✅ 必要なデータだけを抽出
✅ スプレッドシートに自動で記録
✅ エラーが起きても原因をすぐ特定
所要時間: 初回セットアップ15分、以降は完全自動
🎯 なぜ「段階的処理」なのか?
多くの人が「PDF → スプレッドシート」を一発で実現しようとして挫折します。
❌ 一気にやると...
- エラーが出た時、どこで失敗したか分からない
- PDFの読み取り?データ抽出?書き込み?
- デバッグに膨大な時間がかかる
✅ 段階的にやると...
- 各ステップで結果を目視確認できる
- エラー箇所を即座に特定できる
- 途中から再実行できる
- ファイルが残るので検証が容易
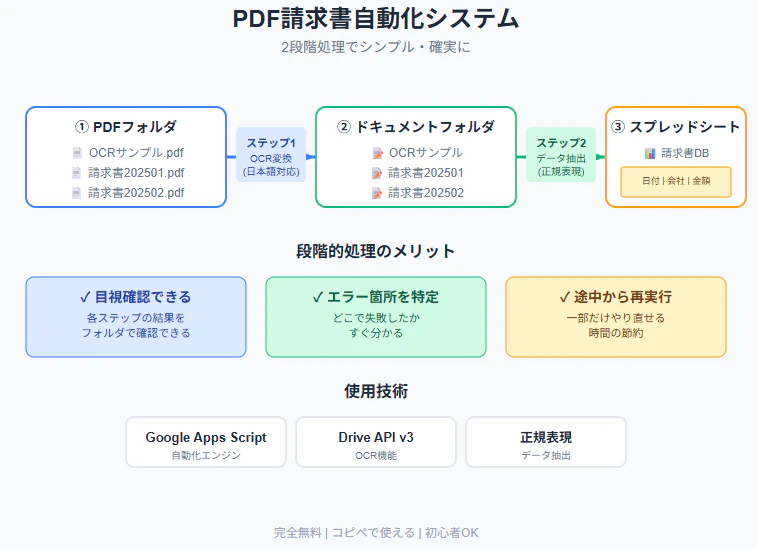
🔧 システム全体像
【メール受信】→ PDF自動保存(Gmail設定)
↓
【ステップ1】PDF → Googleドキュメント(OCR変換)
↓
【ステップ2】Googleドキュメント → スプレッドシート(データ抽出)
↓
【完成】構造化されたデータベース
📁 事前準備(5分)
1. フォルダ作成
Googleドライブで以下を作成:
-
PDFフォルダ(例:
invoices/pdf) -
ドキュメントフォルダ(例:
invoices/documents) -
スプレッドシート(例:
請求書データベース)
2. フォルダID・スプレッドシートIDを取得
フォルダIDの取得方法:
フォルダを開く → URLをコピー
https://drive.google.com/drive/folders/【ここがフォルダID】
スプレッドシートIDの取得方法:
スプレッドシートを開く → URLをコピー
https://docs.google.com/spreadsheets/d/【ここがスプレッドシートID】/edit
💡 メモしておいてください!コードに貼り付けます。
💻 ステップ1:PDF → Googleドキュメント変換
セットアップ
- script.google.com にアクセス
- 「新しいプロジェクト」作成
- 左側「サービス」→「+」→「Google Drive API」を追加
コード
function convertPDFsToGoogleDocs() {
// ⚠️ 自分のフォルダIDに書き換えてください
const sourceFolderId = 'YOUR_PDF_FOLDER_ID_HERE';
const destinationFolderId = 'YOUR_DOCUMENT_FOLDER_ID_HERE';
const sourceFolder = DriveApp.getFolderById(sourceFolderId);
const pdfFiles = sourceFolder.getFilesByType(MimeType.PDF);
let processedCount = 0;
let errorCount = 0;
Logger.log('変換を開始します...');
while (pdfFiles.hasNext()) {
const pdfFile = pdfFiles.next();
const fileName = pdfFile.getName();
try {
Logger.log(`処理中: ${fileName}`);
const pdfBlob = pdfFile.getBlob();
const docMetadata = {
name: fileName.replace(/\.pdf$/i, ''),
mimeType: MimeType.GOOGLE_DOCS,
parents: [destinationFolderId]
};
const options = {
ocr: true, // OCRを有効化
ocrLanguage: 'ja' // 日本語対応
};
const newDoc = Drive.Files.create(docMetadata, pdfBlob, options);
Logger.log(`✓ 完了: ${fileName}`);
processedCount++;
Utilities.sleep(2000); // API制限対策
} catch (error) {
Logger.log(`✗ エラー: ${fileName} - ${error}`);
errorCount++;
}
}
Logger.log(`処理完了: ${processedCount}件 / エラー: ${errorCount}件`);
}
実行
- 関数
convertPDFsToGoogleDocsを選択 - 「実行」ボタンをクリック
- 初回は権限の承認が必要
- ドキュメントフォルダを確認 → PDFが変換されていればOK!
🔍 重要:GAS OCRの仕組みを理解しよう
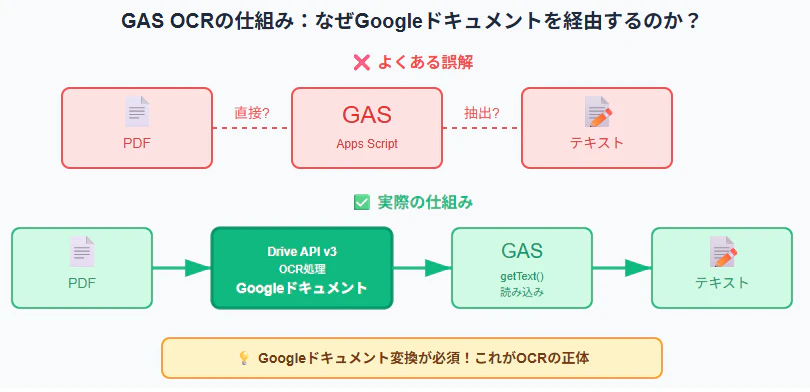
なぜGoogleドキュメントを経由するのか?
Google Apps ScriptでPDFを直接テキスト化することはできません。
Drive API v3の「PDFをGoogleドキュメントに変換する機能」を使うことで、OCR処理が行われます。
メリット
✅ 目視確認が可能
ドキュメントフォルダでOCR結果を直接確認できる
✅ 再利用性が高い
一度変換すれば、何度でも読み込める
✅ バックアップになる
PDFとドキュメントの両方が残る
📊 ステップ2:Googleドキュメント → スプレッドシート
コード
function extractInvoiceToSheet() {
// ⚠️ 自分のIDに書き換えてください
const docFolderId = 'YOUR_DOCUMENT_FOLDER_ID_HERE';
const spreadsheetId = 'YOUR_SPREADSHEET_ID_HERE';
const docFolder = DriveApp.getFolderById(docFolderId);
const allFiles = docFolder.getFiles();
const sheet = SpreadsheetApp.openById(spreadsheetId).getActiveSheet();
// ヘッダー行(初回のみ)
if (sheet.getLastRow() === 0) {
sheet.appendRow([
'ファイル名', '請求日', '宛先会社名', '請求元会社名',
'郵便番号', '住所', '電話番号', 'FAX',
'合計金額', '小計', '消費税',
'商品1_品名', '商品1_数量', '商品1_単価', '商品1_金額',
'商品2_品名', '商品2_数量', '商品2_単価', '商品2_金額',
'商品3_品名', '商品3_数量', '商品3_単価', '商品3_金額',
'処理日時'
]);
}
let processedCount = 0;
let errorCount = 0;
Logger.log('データ抽出を開始します...');
while (allFiles.hasNext()) {
const file = allFiles.next();
if (file.getMimeType() !== MimeType.GOOGLE_DOCS) {
continue;
}
try {
Logger.log(`処理中: ${file.getName()}`);
const doc = DocumentApp.openById(file.getId());
const text = doc.getBody().getText();
const data = extractInvoiceData(text);
sheet.appendRow([
file.getName(),
data.invoiceDate,
data.clientName,
data.companyName,
data.postalCode,
data.address,
data.tel,
data.fax,
data.totalAmount,
data.subtotal,
data.tax,
data.items[0]?.name || '',
data.items[0]?.quantity || '',
data.items[0]?.unitPrice || '',
data.items[0]?.amount || '',
data.items[1]?.name || '',
data.items[1]?.quantity || '',
data.items[1]?.unitPrice || '',
data.items[1]?.amount || '',
data.items[2]?.name || '',
data.items[2]?.quantity || '',
data.items[2]?.unitPrice || '',
data.items[2]?.amount || '',
new Date()
]);
Logger.log(`✓ 完了: ${file.getName()}`);
processedCount++;
} catch (error) {
Logger.log(`✗ エラー: ${file.getName()} - ${error}`);
errorCount++;
}
}
Logger.log(`処理完了: ${processedCount}件 / エラー: ${errorCount}件`);
}
// データ抽出関数
function extractInvoiceData(text) {
if (!text) {
return {
invoiceDate: '', clientName: '', companyName: '',
postalCode: '', address: '', tel: '', fax: '',
totalAmount: '', subtotal: '', tax: '', items: []
};
}
const data = {
invoiceDate: '', clientName: '', companyName: '',
postalCode: '', address: '', tel: '', fax: '',
totalAmount: '', subtotal: '', tax: '', items: []
};
// 請求日
const dateMatch = text.match(/請求日\s*(\d{4})年(\d{1,2})月(\d{1,2})日/);
if (dateMatch) {
data.invoiceDate = `${dateMatch[1]}-${dateMatch[2].padStart(2, '0')}-${dateMatch[3].padStart(2, '0')}`;
}
// 宛先会社名
const clientMatch = text.match(/会社名\s+(.+?)\s+御中/);
if (clientMatch) {
data.clientName = clientMatch[1].trim();
}
// 郵便番号
const postalMatch = text.match(/T(\d{3}-\d{4})/);
if (postalMatch) {
data.postalCode = postalMatch[1];
}
// 住所
const addressMatch = text.match(/T\d{3}-\d{4}\s+請求書\s+(.+?)\s+[○◯〇].{2,4}株式会社/);
if (addressMatch) {
data.address = addressMatch[1].trim();
}
// 請求元会社名
const companyMatch = text.match(/([○◯〇].{2,4}株式会社)/);
if (companyMatch) {
data.companyName = companyMatch[1].trim();
}
// 電話番号
const telMatch = text.match(/TEL:\s*([0-9X-]+)/);
if (telMatch) {
data.tel = telMatch[1];
}
// FAX
const faxMatch = text.match(/FAX:\s*([0-9X-]+)/);
if (faxMatch) {
data.fax = faxMatch[1];
}
// 合計金額
const totalTopMatch = text.match(/請求日\s+\d{4}年\d{1,2}月\d{1,2}日\s+¥([\d,]+)/);
if (totalTopMatch) {
data.totalAmount = totalTopMatch[1].replace(/,/g, '');
}
// 小計
const subtotalMatch = text.match(/小計\s+¥([\d,]+)/);
if (subtotalMatch) {
data.subtotal = subtotalMatch[1].replace(/,/g, '');
}
// 消費税(OCR誤認識対応)
const taxMatch = text.match(/消費[税稅]\s+¥([\d,]+)/);
if (taxMatch) {
data.tax = taxMatch[1].replace(/,/g, '');
}
// 商品明細
const itemPattern = /(商品[A-Z])\s+(\d+)\s+¥([\d,]+)\s+¥([\d,]+)/g;
let match;
while ((match = itemPattern.exec(text)) !== null) {
data.items.push({
name: match[1],
quantity: match[2],
unitPrice: match[3].replace(/,/g, ''),
amount: match[4].replace(/,/g, '')
});
}
return data;
}
実行
- 関数
extractInvoiceToSheetを選択 - 「実行」ボタンをクリック
- スプレッドシートを確認 → データが入っていればOK!
こんな感じ

💡 OCR精度を上げるコツ
1. PDF品質
- 解像度:最低150dpi、推奨300dpi
- フォントサイズ:10pt以上
- 背景:白背景が最適
2. OCR言語設定
// 日本語+英語混在の場合
const options = {
ocr: true,
ocrLanguage: 'ja+en' // 複数言語対応
};
3. 正規表現で柔軟に対応
// ❌ 厳密すぎる
text.match(/消費税\s+¥([\d,]+)/)
// ✅ 柔軟(OCRで「税」→「稅」となる場合に対応)
text.match(/消費[税稅]\s+¥([\d,]+)/)
⚠️ サンプルPDFについて
今回使用しているサンプル請求書は生成AI(画像生成AI)で作成したものです。
なぜ架空のPDFを使うのか?
✅ 個人情報保護のため
実際の請求書は公開できない
✅ OCR精度テストに最適
わざと誤認識されやすい文字を含めている
✅ 汎用性を示すため
完璧なPDFでなくても処理できることを証明
実運用での注意
- 会社ごとにフォーマットが異なる → 正規表現を調整
- OCR誤認識は必ず発生する → 柔軟なパターンで対応
- 100%の精度は期待しない → エラーハンドリングを組み込む
🚀 次のステップ
短期(1週間以内)
- 自社の実際の請求書でテスト
- 正規表現パターンを調整
- エラー通知機能を追加
中期(1ヶ月以内)
- トリガーで自動実行化(週次・月次)
- 複数フォーマット対応
- データ検証ルールを追加
長期(3ヶ月以内)
- ダッシュボード化
- 異常値検知アラート
- 会計ソフト連携
📝 まとめ
今回実現したこと
✅ PDF請求書を自動でテキスト化(OCR)
✅ テキストから必要データを抽出
✅ スプレッドシートに構造化して保存
✅ エラー発生時のトラブルシューティングが容易
重要ポイント
- GAS OCRはGoogleドキュメント経由 - PDFを直接読むのではない
- 段階的処理が最強 - 各ステップで結果を確認できる
- 完璧を求めない - OCRは100%ではない、正規表現で吸収
❓ よくある質問
Q: Googleドキュメントを経由せずに直接できない?
A: できません。GASのOCRは、Drive APIの変換機能を利用しています。
Q: ドキュメントフォルダが不要になったら削除していい?
A: 削除してもOKですが、残しておくと再処理が不要になるので推奨です。
Q: OCRの精度が悪い場合は?
A: ocrLanguage パラメータを確認してください。日本語なら 'ja' を指定します。
以上、PDF請求書の自動スプレッドシート化の完全ガイドでした!