背景
新人研修でSQLを習って半年経ちました。
基本的な構文はある程度扱えるようになったものの、パフォーマンス的なこととかは何も分かっておらず、パフォーマンスを上げるHow toテクニック的なものを見ても、なぜそれをしたら早くなるのかがピンときませんでした。
それはRDBMSが何をしてくれて何をしてくれないかを分かっていないからです。
車の性能を上げたければ最低限の車の構造を知ってなきゃいけない。(構造を知っているからといて上げられるわけではないけど)
だから、やんわりとで良いからRDBMSの仕組みを知っておきたい(お近づきになりたい)という背景です。
対象読者
以下にあてはまる方
- SQL初心者
- SQLの基本的な構文は扱えるが、RDBMSがどう動いているか全く考えたがない
- RDBMSの文脈でインデックス、コストベースとか聞いてもなにそれって感じ
内容に入る前に
以降の内容は、本やネットの記事、RDBMS製品のドキュメントを読んで理解したことを、私なりの具体例や追加の検証を交えながら説明するものになります。
参考にした書籍の中で「RDBMS解剖学 よくわかるリレーショナルデータベースの仕組み」という本があるのですが、あまりに分かりやすかったので、私の理解はこの本書がベースになっています。
残念ながら本書は現在絶版となっているのですが、できればこの記事よりも本書を読むことをお勧めします。
また、ここに記載の情報は複数の文献を参照してある程度確信を得たものを記載しているつもりですが、間違っていたり、内容が古かったりすることがあるかもしれません。もしあればコメントなどで指摘していただけると幸いです。
この記事の目指すところ
とりあえずRDBMSのブラックボックスな部分をふんわりとでいいから理解したい。
とりあえずなんでもいいので、「SQL文を渡して結果が出力されるまでの過程を追ってみる」をゴールとします。
準備
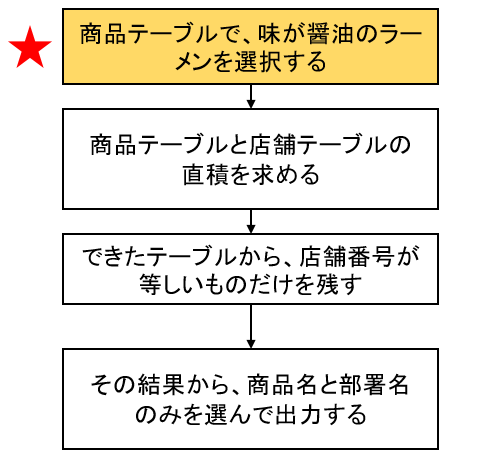
ラーメンが大好きな私は醤油ラーメンを食べたいので、「ラーメンテーブル」と「店舗テーブル」を用意し、味が「醤油」のラーメンの商品名と店名を取り出すSQLを作りました。
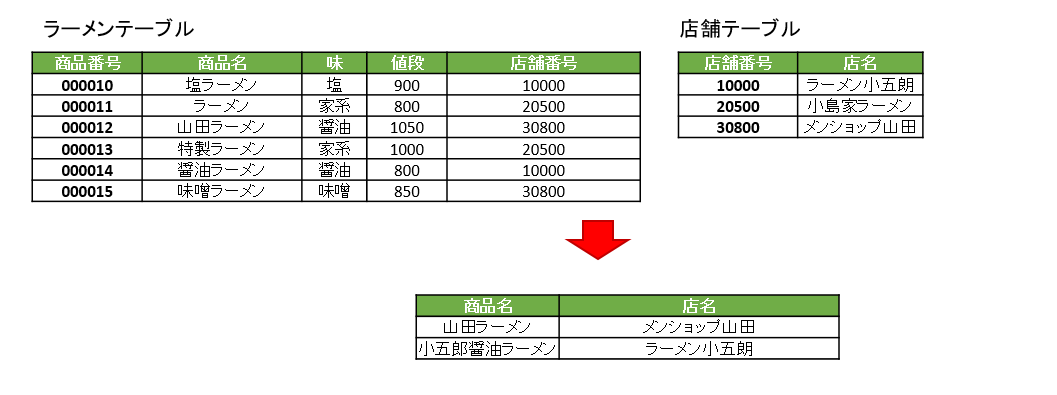
SELECT 商品名, 店名
FROM ラーメン, 店舗
WHERE ラーメン.店舗番号 = 店舗.店舗番号
AND ラーメン.味 = '醤油'
以降では、このSQLがRDBMSに渡されると、どのようにSQLが実行されるかを追っていきます。
全体像
詳細に入る前に、まず大まかな流れについて把握しておきましょう。
RDBMSにSQLが渡されて、結果が返るまでには大きく分けて4つのステップがあります。

最初のステップは、構文解析と呼ばれるステップです。この役割はRDBMSのパーサと呼ばれる部分が担当します。
パーサは受け取ったSQLを、後の過程で使いやすい構造へと直します。
次に出てくるのは、オプティマイザ(またはプランナ)と呼ばれるものです。
オプティマイザは、どのようにクエリを処理をするか「計画」する役割を担います。
オプティマイザが実行計画を立てる際、「論理プラン」を決める段階と「物理プラン」を決める段階の2つの段階があります。
「論理プラン」ではパーサから渡された構造を用いて、関係代数ベースで大まかな計画を立てます。
一方、「物理プラン」ではテーブルの統計情報なども使って具体的な処理を決めます。
オプティマイザを野球の監督に例えると、試合が始まる前の選手起用などが論理プラン、試合が始まってから試合の進行・選手の調子などを踏まえて、出す指示を物理プラン、等といえるでしょうか。
最後に、実行エンジンと呼ばれる部分がオプティマイザが決めた計画通りに処理を実行します。
実行エンジンは多くの機能モジュールで構成されます。実行エンジンの機能は、実際のエンジンに実装されているもの、いないものがあるので、実行エンジンが実行できるプランがオプティマイザから渡されるようになってます。
構文解析
パーサーはSQL文を受け取って構文解析する役割があります。以下の順で作業を行います。
SQL文の解析 → 構文木への変換 → 整合性チェック
※整合性チェックを行うのはアナライザと表記している文献もありましたが、ここではパーサがまとめてが処理していることで話を進めます。
-
SQLの解析
渡されたSQL文の文法がルール通り正しく書かれているか(解釈可能であるか)をチェックします。
私はポンコツなのでよく syntax error を返されるのですが、そういうのはこの時点ではじかれています。 -
構文木への変換
構文木というのは一般的な字句解析に触れたことのある方はなじみがあるかもしれませんが、文を決められたルールに基づいて構造化した木のことです。
SELECT文の構造木は以下のような構造をしており、最上位にSELECT文用のノードが存在し、そのノードの下にFROM句等、各句のノードがあります。
そのノードの下には、SELECT句であれば属性リスト、WHERE句であれば条件式が連なります。

醤油ラーメンを取得する例を先ほどのに当てはめるとこんな感じになります。
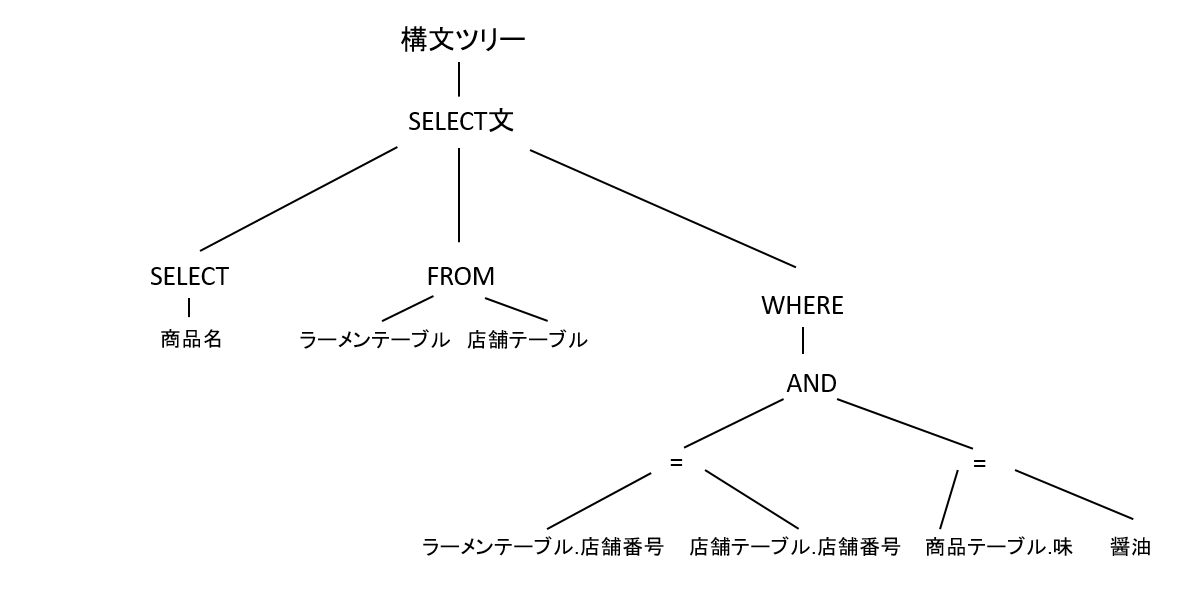
このように直しておくことで何が良いのかといいますと、例えばアクセスするべきテーブルが何かを知りたいときはFROMの子ノードを見て、他のノードに注意せずとも「ラーメンテーブル」と「店舗テーブル」だと分かるようになります。 -
整合性のチェック
先ほど作った構文木を用いて、実際のデータベース情報とSQL文の内容の整合性をチェックします。
例えば、SQL文の文法自体は正しく無事構文木に直すことができたとしても、データベースに必要なテーブルがなかったら、ここでエラーが送出されます。
論理プランの作成
ここからは、いよいよどのようにSQLを実行するかの計画を立てます。
論理プランでは、関係代数を用いてデータベースの処理手順を考案します。
関係代数とは、SQLで扱われる数式みたいなもので、和や差、直積などのことです。
ゆるくイメージをつかむために、関係代数ではなく中学校で習う代数を用いて考えてみます。
以下の数式からxを求めよという問題があったとします。ここでは具体的なa,b,cは分かっていません。
この数式を解くシンプルな方法としては、掛け算2回と足し算1回を順に行っていくというものです。
x = ab+ac
でも、ちょっと待ってください。右辺はaが共通項なので因数分解できますよね。
x = a(b+c)
こうすることで、掛け算1回と足し算1回で計算できます。
このように、より計算の負担が減るように工夫するイメージです。
話をデータベースに戻します。
SELECT 商品名, 店名
FROM ラーメン, 店舗
WHERE ラーメン.店舗番号 = 店舗.店舗番号
AND ラーメン.味 = '醤油'
醤油ラーメンを検索するSQLの処理方法として、下図(a)のような手順を真っ先に思いつくのではないでしょうか。
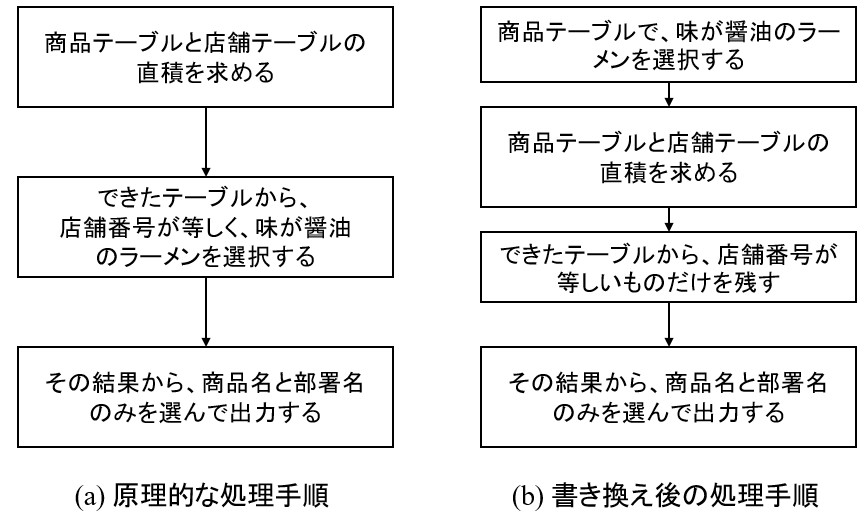
(a)の方法は間違ってはいないのですが、少し問題があります。
例えばラーメンテーブルのタプル(行)が10000個あって、店舗が1000店舗ある場合、直積をとると一時的に10000000個のテーブルができてしまいます。これは、メモリ的にも実行時間的にもあまり良くなさそうです。
そこで、オプティマイザは、(b)の手順に書き換えをします。
(a)の手順との差異は、最初に「醤油ラーメンを選択する処理」をしている点です。
こうすることで、直積後にできるテーブルは(a)の手順に比べて大幅に削減され、メモリ的にもパフォーマンス的にも良さそうです。
なぜかというと、ラーメンテーブルに醤油ラーメンが300個(全体の3%)ある場合、直積後にできるテーブルも(a)の場合に比べて3%になるからです。
ここで、察しの良い方はこう思われるかもしれません
「醤油ラーメンは多くの店が看板メニューとして売っているのだから、上記の仮定の3%は無理があるんじゃないの?仮に50%だったら半分しか削減されないんだから言うほど効率化できてるようには思わないけど?検索するのがレアな味のラーメンとかだったら納得できるけど」
確かに、その通りです。しかし、論理プランでは醤油ラーメンがラーメンテーブルにどのくらいの割合あるかは考えません。
それを考えるのは物理プランを作成する段階になってからです。あくまで論理プランは、関係代数にのっとって最適化っぽいことをするだけ、というのがミソ(味噌)です。
物理プランの作成
さて、論理プランの作成が終わり、後は決められた処理手順に従って実行するだけ....ですが、そう単純ではありません。
先ほど決めた「ラーメンテーブルで、味が醤油のラーメンを残す」は、具体的にどのように探せばよいでしょうか。
これには、フルテーブルスキャンやインデックススキャン等のいくつかの方法があります。
フルテーブルスキャンは、単純にテーブルを一つずつ見ていくやり方です。
インデックススキャンは、事前にインデックスと呼ばれる索引を作っておいて、索引をもとにデータを探すやり方です。
インデックススキャンにはいくつか種類がありますが、B-Treeインデックスなどが有名です。
B-Treeインデックススキャンはいろいろな方が記事を書かれているのでそちらを参照してください。
次の図はラーメンの味をインデックスとしたときのB-Treeインデックススキャンのイメージ図です。
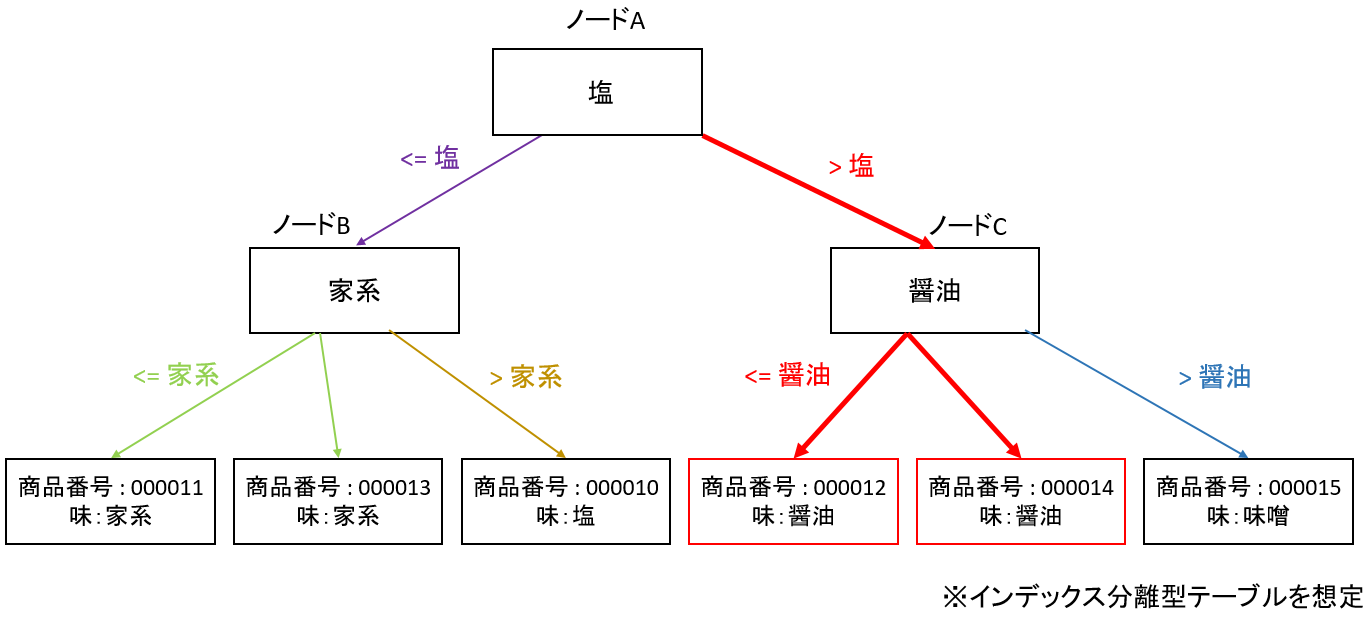
味が醤油のラーメンを探すインデックススキャンでは、次のような流れで醤油ラーメンを探します。
- ノードAで醤油は塩より辞書順で大きいため、右側のノードに遷移
- ノードCで醤油は味噌より辞書順で小さいため、左側のノードに遷移
- この時点で移動したノードの先には醤油ラーメンしか存在しないので、一つずつこれらのROWID(データにアクセスするための情報)を取得
- 取得したROWIDを用いてテーブルにアクセスする。
なんとなくB-Treeインデックスの方が早く求められそうですね。
実際に、B-Treeインデックスは検索の効率化のために考案されたデータ構造なので、基本的には計算効率が向上します。
特にテーブルのデータが増えれば増えるほど威力を発揮します。
しかし、どんな状況でもB-Treeインデックスが万能というわけではありません。
B-Treeの性能が下がってしまう場合の例としては、データの種類が少ない場合です。
例えば、この世に塩ラーメンと醤油ラーメンの2種類しか存在しない場合です。
データの種類が少なく、インデックスの威力が発揮しにくい場面では、インデックススキャンの方ではインデックスを取得してからテーブルにアクセスするという2回の論理的なアクセスが発生する分、フルテーブルスキャンの方が早くなる可能性があります。
また、そもそもインデックスが存在しない場合、後の実行エンジンはインデックススキャンを実行することができません。
オプティマイザはこのように、インデックスが存在するかであったり、テーブルの統計情報(カタログ)を参照しながら最も効率のよいプランを考えます。
物理プランの最適化方式
もしも計画の候補が複数存在した場合、実際に物理プランはどのように最適な計画を決定するのでしょうか。
代表的な方式として、ルールベース方式とコストベース方式があります。
-
ルールベース方式
ルールベース方式は、事前に物理プラン選択の優先順位を定義したルールを用意し、今の状況に該当したプランのうち、一番優先順位の高いものを選択する方式です。
ルールベース方式は、その名の通りルール通りにしか動くものなので、それがメリットにもデメリットにもなりえます。
メリットは、オプテマイザの判断が規則的なので、ユーザが正確に予測できる点です。逆に、あらかじめ決めた単純なルールでは複雑なものは扱いきれないので、それがデメリットになります。
個人的になじみのある、H2 Database、MySQL、PostgreSQLの最新のドキュメントを調べたところ、すべて後述のコストベース方式を採用していました。ルールベースはあまり使われていないようです。 -
コストベース方式
コストベース方式は、データベースシステムの各種統計情報(カタログ)を使用し、コストと呼ばれる指標を算出し、コストが最も小さい物理プランを選択する方式です。コストの算出には、物理プランを実行する上で必要になるCPUやディスクI/O等の使用量も関係しているようです。
例えば、テーブルスキャンとインデックススキャンという2つの候補があったとします。
オプティマイザはインデックススキャンで該当するレコードを探索するのに必要なコストと、テーブルスキャンでのコストを概算し、コストの小さい方を採用します。
処理の実行
オプティマイザの頑張りにより、実行エンジンが実行する計画が練られました。
最後に、物理プランで作成された計画をもとに、実行エンジンが処理を行います。
と、ここまででSQL文が渡されてから実行エンジンが実行するまでの流れを長ったらしく説明してきましたが、本当にそのようなことが行われているのでしょうか。
実行エンジンに渡された実行計画はEXPLAIN等を使えば見ることができます。せっかくなので見てみたいと思います。
実行計画を見てみる
醤油ラーメンを検索するSQL文を実行してみます。
同時に、DBMS製品での違いも見るため、私の環境にインストールされていたH2 Database、MySQL、PostgleSQLで検証してみます。
テーブル数が少ないと分かりづらいので、ラーメンテーブルと店舗テーブルにかさましをして、それぞれ10000行にしました。
ただ、かさましした分はてきとうなダミーデータなので、SELECT文を実行した結果はこれまでと変わらず2件です。
H2 Database(H2 2.1.214)
SELECT文の先頭にEXPLAINを付けた以下の文をコンソール上で実行してみます。
EXPLAIN SELECT ramen_name, shop_name FROM ramen, shop
WHERE ramen.shop_id = shop.shop_id
AND ramen.taste = '醤油';
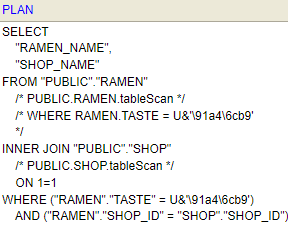
醤油がUnicode化してしまいましたが、実行計画が出力されました。
特にインデックスも作っていないのでテーブルスキャンが行われていることが分かります。
MySQL(8.0)
H2 Databaseのときと同様、EXPLANEを付けたSELECT文を実行してみます。

出力結果を見てみると、typeがALLなので、フルテーブルスキャンが実行されていると判断することができます。
possible_keysはNULLとなっています。これは、オプティマイザがテーブルのアクセスに利用可能だと判断したインデックスないことを表しています。
なんだか悔しいので、適当なインデックスを貼ってみます。
create index shop_id on shop(shop_id);
再度、EXPLAIN付きSELECT文を行ってみると、結果が変わりました。

先ほどのと比べてみると、インデックスを貼った店舗テーブル(shop)のtypeがrefになりました。これは、インデックススキャンがされたことを表しています。
また、rowsの例はまたも店舗テーブルの方が1になっていますが、rowsは対象テーブルから取得される行の見積もりであるので、探索範囲が明らかに狭まっていることが分かります。
この程度の件数ではフルテーブルスキャンの場合もインデックススキャンの場合も一瞬で処理が終了してしまし、体感上違いを時間することはできなかったのですが、もっと件数が増えたり複雑なSQL文になるとそういった効果もありそうです。
また、MySQLではMySQL5.6からオプティマイザトレースというものが用意されており、オプティマイザが実行計画を選択する過程を見ることができる機能があります。オプティマイザの実行するには、以下のように、オプティマイザトレースの機能をONにした後に処理を実行して、information_schema.optimizer_traceを表示させます。
SET optimizer_trace="enabled=on";
SELECT ... ;(トレースしたいSELECT文を実行) ;
SELECT * FROM information_schema.optimizer_trace\G ;
実行結果が以下です、なにやら随分と長い結果が出てきました。
ちゃんと読もうと骨が折れそうですが、最終的な計画の結果っぽいクエリがあったり、costが計算されて使われていそうなことが分かります。
オプティマイザトレースの結果
TRACE: {
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `ramen`.`ramen_name` AS `ramen_name`,`shop`.`shop_name` AS `shop_name` from `ramen` join `shop` where ((`ramen`.`shop_id` = `shop`.`shop_id`) and (`ramen`.`taste` = '醤油'))"
}
]
}
},
{
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "((`ramen`.`shop_id` = `shop`.`shop_id`) and (`ramen`.`taste` = '醤油'))",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(multiple equal(`ramen`.`shop_id`, `shop`.`shop_id`) and multiple equal('醤油', `ramen`.`taste`))"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(multiple equal(`ramen`.`shop_id`, `shop`.`shop_id`) and multiple equal('醤油', `ramen`.`taste`))"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "(multiple equal(`ramen`.`shop_id`, `shop`.`shop_id`) and multiple equal('醤油', `ramen`.`taste`))"
}
]
}
},
{
"substitute_generated_columns": {}
},
{
"table_dependencies": [
{
"table": "`ramen`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": []
},
{
"table": "`shop`",
"row_may_be_null": false,
"map_bit": 1,
"depends_on_map_bits": []
}
]
},
{
"ref_optimizer_key_uses": [
{
"table": "`shop`",
"field": "shop_id",
"equals": "`ramen`.`shop_id`",
"null_rejecting": true
}
]
},
{
"rows_estimation": [
{
"table": "`ramen`",
"table_scan": {
"rows": 10191,
"cost": 24.25
}
},
{
"table": "`shop`",
"table_scan": {
"rows": 10099,
"cost": 24.25
}
}
]
},
{
"considered_execution_plans": [
{
"plan_prefix": [],
"table": "`ramen`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 10191,
"filtering_effect": [],
"final_filtering_effect": 0.1,
"access_type": "scan",
"resulting_rows": 1019.1,
"cost": 1043.35,
"chosen": true
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 1019.1,
"cost_for_plan": 1043.35,
"rest_of_plan": [
{
"plan_prefix": [
"`ramen`"
],
"table": "`shop`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "ref",
"index": "shop_id",
"rows": 1.0099,
"cost": 360.216,
"chosen": true
},
{
"rows_to_scan": 10099,
"filtering_effect": [],
"final_filtering_effect": 1,
"access_type": "scan",
"using_join_cache": true,
"buffers_needed": 3,
"resulting_rows": 10099,
"cost": 1.02927e+06,
"chosen": false
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 1029.19,
"cost_for_plan": 1403.57,
"chosen": true
}
]
},
{
"plan_prefix": [],
"table": "`shop`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "ref",
"index": "shop_id",
"usable": false,
"chosen": false
},
{
"rows_to_scan": 10099,
"filtering_effect": [],
"final_filtering_effect": 1,
"access_type": "scan",
"resulting_rows": 10099,
"cost": 1034.15,
"chosen": true
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 10099,
"cost_for_plan": 1034.15,
"rest_of_plan": [
{
"plan_prefix": [
"`shop`"
],
"table": "`ramen`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 10191,
"filtering_effect": [],
"final_filtering_effect": 0.1,
"access_type": "scan",
"using_join_cache": true,
"buffers_needed": 16,
"resulting_rows": 1019.1,
"cost": 1.04475e+06,
"chosen": true
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 1.02919e+07,
"cost_for_plan": 1.04578e+06,
"pruned_by_cost": true
}
]
}
]
},
{
"attaching_conditions_to_tables": {
"original_condition": "((`ramen`.`taste` = '醤油') and (`shop`.`shop_id` = `ramen`.`shop_id`))",
"attached_conditions_computation": [],
"attached_conditions_summary": [
{
"table": "`ramen`",
"attached": "((`ramen`.`taste` = '醤油') and (`ramen`.`shop_id` is not null))"
},
{
"table": "`shop`",
"attached": "(`shop`.`shop_id` = `ramen`.`shop_id`)"
}
]
}
},
{
"finalizing_table_conditions": [
{
"table": "`ramen`",
"original_table_condition": "((`ramen`.`taste` = '醤油') and (`ramen`.`shop_id` is not null))",
"final_table_condition ": "((`ramen`.`taste` = '醤油') and (`ramen`.`shop_id` is not null))"
},
{
"table": "`shop`",
"original_table_condition": "(`shop`.`shop_id` = `ramen`.`shop_id`)",
"final_table_condition ": null
}
]
},
{
"refine_plan": [
{
"table": "`ramen`"
},
{
"table": "`shop`"
}
]
}
]
}
},
{
"join_execution": {
"select#": 1,
"steps": []
}
}
]
}
postgleSQL(11.5)
同じく、EXPLANEを付けたSELECT文を実行することで、以下の結果を得ることができました。

これはツリー構造を表していて、下記サイトを参考にツリー構造に直してみた結果が下の図です。

確かにラーメンが醤油の判定は結合前にやっていそうです。
結局SQLのパフォーマンスを上げたいならどうすればよいのか
記事を書いていく中で感じた率直な感想は、「結構オプティマイザが頑張ってくれているんだな」でした。
しかし、オプティマイザには限界があるらしいので、チューニングで改善を加えられる部分はありそうです。
ルールベースオプティマイザの限界は極めて明らかである。内容は少し違うが、コストベースオプティマイザにもまた明らかな限界がある。その中でも最も代表的なものは、やはり完璧ではない統計情報に基づいて処理範囲を予測することに関する正確さに限界があるということである。
「データベースパフォーマンスアップの教科書 基本原理編」 P112
ここからは完全に個人の感想ですが、インデックスを貼る、アンチパターンと呼ばれるSQLの書き方を避ける等、ある程度人間がやるべきことをやった上で、ある程度オプティマイザを信頼しても良さそうです。
ただ、今回異なるRDBMS製品で簡単な比較をしましたが、製品(あるいはバージョン)によって結構差異があると感じたので、できれば普段使っているRDBMSがどんな特性を持つのかくらいは知っておくとよさそうです。
また、処理時間に悩んでいるSQL文があった場合、EXPLAINやトレースで実行計画を除いてみると改善するためのヒントになるかもしれないので、こういったものは覚えておいて損はないと思いました。
おわりに
SQLともっと仲良くなりたい。。