58歳・Python経験ゼロから4ヶ月。「ピチョン」と呼んでいた私がAIを相棒に不動産分析ツールを完結させた話

こんにちは!58歳からプログラミングと統計学の独学を始めました。
「実力がないならAIと検索を最大限活用すればいい」と考え、
4ヶ月で不動産賃貸データの収集から統計分析、自動レポート生成まで
一気通貫で処理できるシステムを作りました。
58歳、Python経験ゼロ。
「ピチョン」と読んでいたレベルから、4ヶ月後には
不動産賃貸データの収集・統計分析・レポート生成までを行う
“フル自動システム”を完成させました。
ユーザーフレンドリーなフロントエンド、Flaskの中間層、
そしてバックエンドでは
スクレイピング → 前処理 → 重回帰分析 → 可視化 → PowerPoint自動生成
までを“ツークリックで完結”させる仕組みを構築しています。
この記事では、完全独学の私がどのようにAIを使い倒し、
エンドツーエンドの分析ツールを作り上げたのかをまとめます。
なぜ不動産賃貸家賃を取り上げたのか?
-
統計学習に最適なテーマ
- 重回帰分析の練習として適切な複雑さ
- 変数間の関係が理解しやすい
-
実用性と共感性
- 誰もが関心を持つ身近なテーマ
- 日本人の感覚で理解できるデータ
-
質の高いデータソース
- SUUMO様のデータは構造化されており分析しやすい
- ※最小限の利用に留め、スクレイピングのルールには配慮しています
- time.sleep(3) を入れて負荷を抑えている
- スクレイピングは個人学習目的のローカル実行に留めている
- robots.txt や利用規約を確認した
-
Kaggleデータセットの課題
- 海外の住宅データは日本の感覚と乖離
- 一部データセットには差別的要素の懸念も
-
汎用性のある学び
- ユーザーフレンドリーなシステム設計は他分野にも応用可能
- エンドツーエンドの開発経験を積める
私のバックグラウンド
保有資格
- MOSマスター2016
- ITパスポート(基本情報・応用情報は挑戦中)
- ビジネス統計スペシャリスト
これまでの技術経験
- VBA(業務自動化で実務経験あり)
- GAS(スプレッドシート連携)
- HTML/CSS(基本的なWeb修正)
- RPA(初歩レベル)
このプロジェクト開始時点でのPython経験:ほぼゼロ
(「Python」を「ピチョン」と読むレベルでした)
このプロジェクトの目的
1. 統計学の実践的習得
- 重回帰分析、ANOVA(分散分析)の理論と実装
- 教科書的な知識を実データで検証
- 予測区間・信頼区間の可視化まで実装
2. 実践的プログラミングスキルの獲得
- Python:ゼロ(「ピチョン」レベル)からの出発
- Web技術:JavaScript、Flask、HTML/CSS
- データ処理:スクレイピングから可視化まで
3. エンドツーエンドの開発経験
- データ収集 → 分析 → 可視化 → レポート生成
- 一気通貫で動くシステムの設計・実装
- 実務で使えるツールを作るという実践経験
4. キャリアチェンジのためのポートフォリオ
- 58歳での転職活動における実力証明
- 「学習能力」「問題解決能力」の可視化
- 20年の製造業経験 × 新しい技術スキル
システム全体の構成
フロントエンド
使用技術:JavaScript、HTML/CSS
- AI(Claude/ChatGPT)を頼りに初めて実装
- ユーザーインターフェースの設計
中間層(Flask)
最大の難関:2ヶ月の試行錯誤
- Flaskの存在自体をAIから教わる
- フロントエンドとバックエンドの連携に苦戦
- 無料AIで2ヶ月 → 有料AI(Claude Pro)により4日で解決
-なんといってもJavaScriptとPythonをつなぐ中間層のFlaskに苦労。AI課金で乗り切ったが、その前の2か月の格闘が大いに役立っている
-bs4のコードにURLを利用者がいちいち調べて入力するという手間はユーザーフレンドリーでないと考え、どうしても乗り越えなくてはならない壁であった
バックエンド処理
1. データ収集
- BeautifulSoup4によるSUUMOスクレイピング
- 人生初のスクレイピング体験
2. データ前処理
- 重複データの削除
- 欠損値処理
- データクレンジング
3. 統計分析
- 基本統計量の算出
- 重回帰分析(R² = 0.88〜0.94達成)
- ANOVA(分散分析)
4. 可視化
- 散布図、箱ひげ図の自動生成
- 予測区間・信頼区間のグラフ化
- 駅間比較チャート
5. レポート自動生成
- python-pptxでPowerPoint自動作成
- グラフ・表の自動配置
- ファイルの自動整理
AI活用戦略
プロジェクト全体で複数のAIを使い分けました:
主要AI
- ChatGPT:基本的なコード生成、エラー解決
- Claude:途中から課金(後述の通り、これが転換点に)
- Copilot:コード補完、リファクタリング提案
- Gemini:Google関連技術の相談
- Perplexity:技術情報の検索、最新情報の確認
特筆すべき貢献
-
Grok:スクレイピング実装のきっかけをくれた
(「bs4の使い方」を教えてくれた)
AI活用の変遷
初期(0〜2ヶ月):無料AIのみ
- 複数のAIを使い分けて無料で進行
- 各AIの得意分野を見極めながら活用
- しかしFlaskで完全に行き詰まる...
転機(2ヶ月目):Claude Pro契約
- 月額約3,000円の投資を決断
- 長いコンテキスト対応が決定的に効いた
- Flask問題が4日で解決
その後(3〜4ヶ月):
- 複雑な実装はClaude Pro
- 簡単な質問は無料AIで節約
- 効率的な使い分けを確立
完成したシステムと成果
エンドツーエンドの自動化フロー
ユーザー入力(駅名選択)
↓
SUUMOスクレイピング
↓
データクレンジング
↓
統計分析・重回帰モデル構築
↓
可視化(グラフ・表)
↓
PowerPointレポート自動生成
↓
ファイル自動整理・保存
全て自動で、ボタン一つで完結
達成した技術指標
1. 高精度な予測モデル
- 決定係数(R²):0.88〜0.94
- 東京、神奈川、埼玉、千葉の各県と大阪環状線で検証済み
- 予測区間・信頼区間まで可視化
2. 対象データの規模
- 対象範囲:南関東1都3県
- 駅数:約1,000駅
- 各駅ごとに統計分析・レポート生成が可能
3. ユーザーフレンドリーなUI
- Flaskによるフロント・バック連携
- 技術知識がなくても使える設計
- 駅間比較、箱ひげ図、ANOVA結果も自動表示
生成されるレポートの例
秋葉原駅の分析結果(自動生成されたPowerPointより):
【ここに3つの画像を挿入】
- データ全体の分布把握(賃料、徒歩時間、専有面積、築年数の8グラフ)
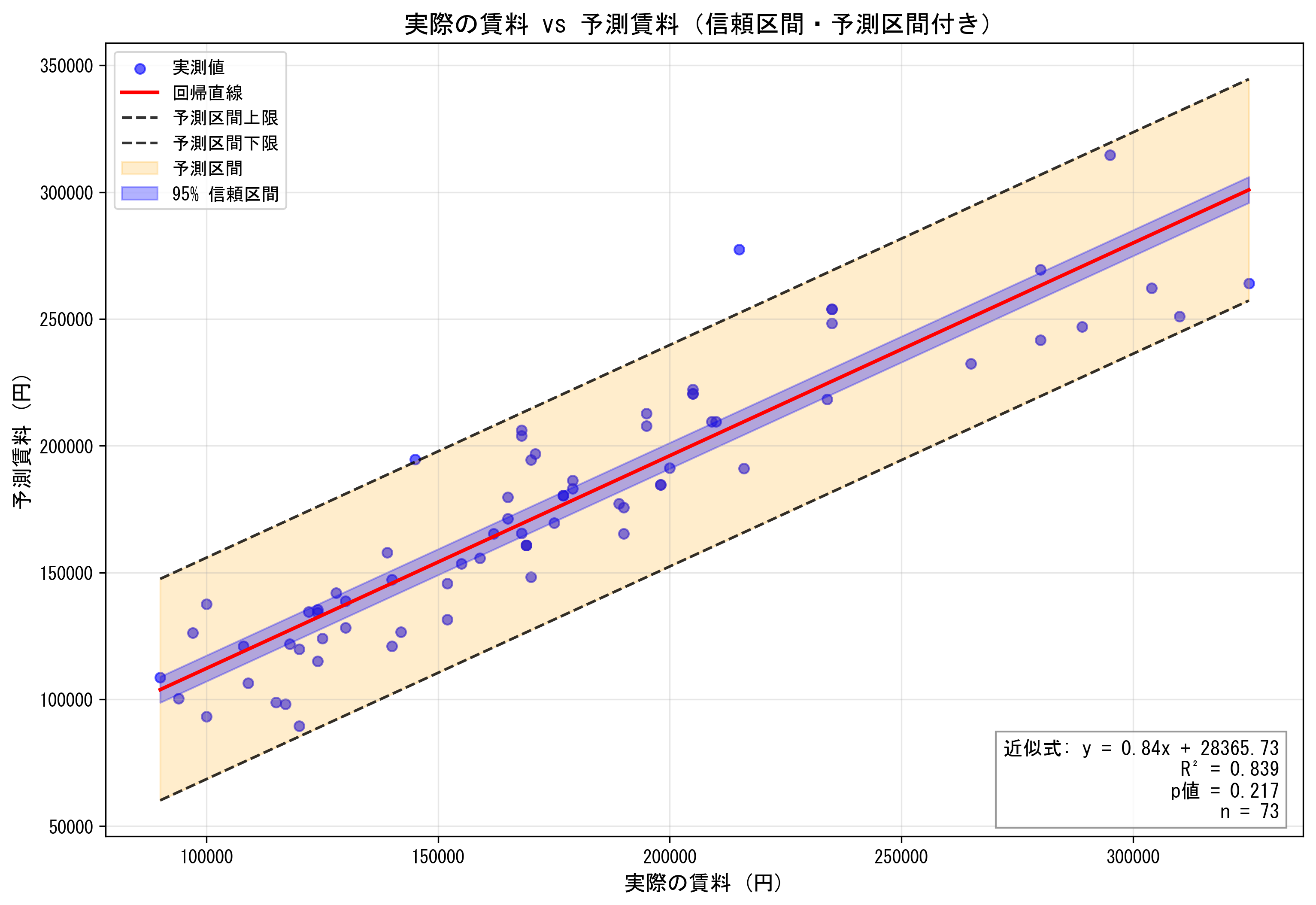
- 予測精度検証グラフ(実際の賃料 vs 予測賃料、R² = 0.839、予測区間・信頼区間付き)
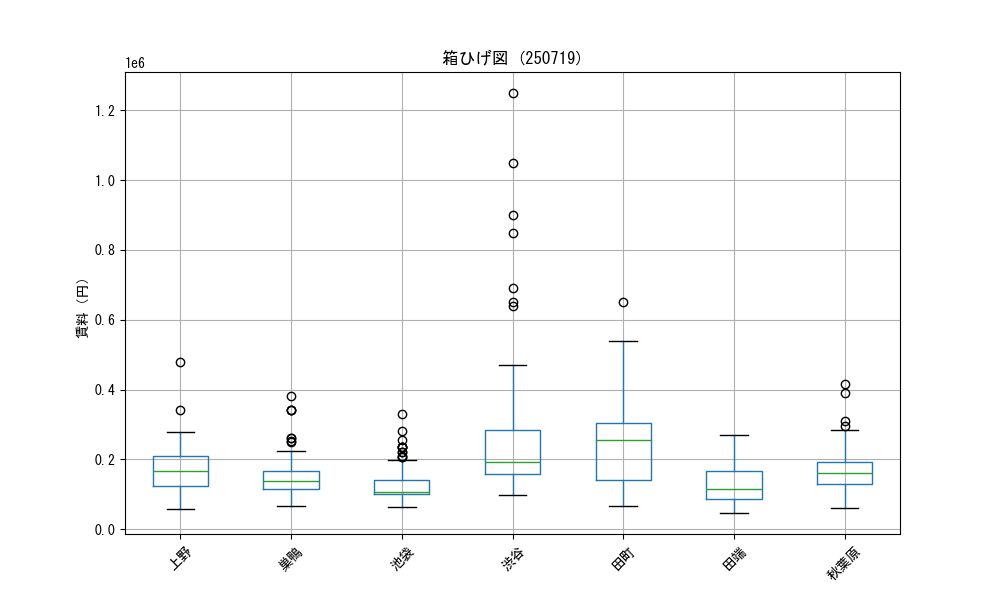
- 駅間比較の箱ひげ図(複数駅の賃料比較、ANOVA分析結果付き)
※画像は記事投稿後に追加予定
このシステムの独自性
既存の類似投稿との違い:
- ❌ スクレイピングのコードだけ → ⭕ 使える完成品
- ❌ 分析結果の表示まで → ⭕ レポート自動生成まで
- ❌ Jupyter Notebookで完結 → ⭕ Webアプリとして動作
- ❌ データサイエンティスト向け → ⭕ 誰でも使える
汎用性の高い設計:
不動産データを題材にしていますが、システム構成は他分野にも応用可能:
- 商品価格分析
- 医療データ分析
- マーケティングデータ分析
- など、多変量データの分析全般に対応
デモと公開状況
フロントエンド(デモ公開中)
🔗 https://stationsurlgen.netlify.app/
実際の画面を確認いただけます。
(バックエンドと未接続のため、見た目のみの確認となります)
中間層・バックエンド
現状非公開
理由:
- SUUMOのスクレイピング部分を含むため
- サーバー負荷への配慮
- データ利用規約への配慮
今後の記事予定
本記事への反響次第で、以下のような続編を執筆予定です:
- 「Flask初心者がつまづいたポイント解説」
- 「python-pptxで自動レポート生成の実装方法」
- 「重回帰分析でR²=0.9超を達成する方法」
- 「予測区間・信頼区間の可視化実装」
興味のあるテーマがあれば、コメントで教えてください!
また、生成されたレポートのサンプルデータにご興味がある方は、コメント欄でお知らせください。
まとめ
58歳、Python未経験から4ヶ月で、AIを最大限活用することで:
- エンドツーエンドの実用的なシステムを完成
- R²=0.9超の高精度予測モデルを構築
- 約1,000駅分の自動分析システムを実装
年齢や経験に関係なく、適切なツール(AI)を使えば、短期間で実用的なシステムを作れることを証明できたと思います。
この記事が、同じようにキャリアチェンジや新しい技術習得に挑戦している方の参考になれば幸いです。