はじめに
はじめまして.私はアルバイトで深層学習を用いた分析などをしている大学生です.
物体検出を扱うことがあったのですが,調べることも多く手間取りました.
そこで,作業を進める中で得たことを自分なりにまとめてみました.
方針
これから物体検出を試してみようとする人に向けての記事です.
Tensorflow2 を使いたいという条件で自前で画像を用意して学習させて,実際に動かしてみます.
精度の向上等を主にするものではありません.
YOLOv3-tf2 とは
物体検出モデルの YOLOv3 の Tensorflow2 代替実装です.今回はこちらのリポジトリを利用します.

$ git clone https://github.com/zzh8829/yolov3-tf2.git
データセットを作る
学習させるためのデータセットを作ります.
データセットは基本画像ファイルとアノテーションファイルの2つから成ります.
アノテーションとは対象となる物体の名前,座標や状態を記載しておくラベル付けのファイルのことです.
実際に写真を撮って1枚ずつ labelImg 等のアノテーションツールを利用してラベル付けを行います.
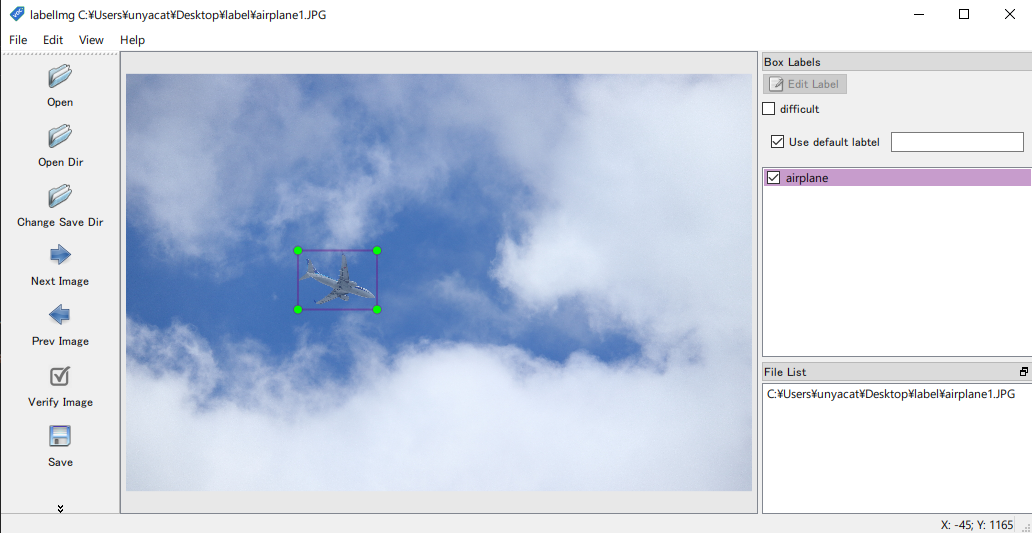
このようにできることがベストですが,相応の手間と時間がかかってしまいます.
そこで今回は物体の透過画像を背景画像に貼って擬似的に画像を生成し,アノテーションを作ることにします.
対象の物体の画像に偏りができてしまうので注意が必要ですが,手間を減らして完璧な精度を持ったアノテーションと画像のセットを量産できるメリットがあります.
画像
Python では Pillow(PIL) を使うことで画像の操作をすることができます.
背景はリアルな画像だけでなくランダムな単色画像を背景にする混ぜることで背景画像に依存しない学習が望めます.
物体も回転や明度変更を行うことで汎化性能の向上を図れます.
回転すると画像サイズが変わるため物体のギリギリになるようにアノテーションできるように処理する必要があります.

Python での実装(クリックして展開)
from PIL import Image, ImageEnhance, ImageDraw
import os
import random
# 画像サイズ
size = (4608, 3456)
# 生成枚数
num_of_images = 100
dirs = ["watch", "ramune"]
# dirs = os.listdir('./Photos')
for i in range(num_of_images):
# 物体情報を保持する
obj_details = []
# 背景画像
red = random.randint(0, 255)
green = random.randint(0, 255)
blue = random.randint(0, 255)
bg = Image.new('RGB', size, (red, green, blue))
# bg = Image.open('background.jpg')
# 物が置けない場所を管理する
# - 透過していると物が置ける(もっといい処理ありそう)
# - 重なったり,実際に存在し得ない場所に配置されないようにする
deployable_area = Image.new('RGBA', size, (0, 0, 0, 0))
for j in range(len(dirs)):
photos = os.listdir("./Photos/" + dirs[j])
obj = Image.open("./Photos/" + dirs[j] + "/" + photos[i % len(photos)])
# 明度変更
obj = ImageEnhance.Brightness(obj).enhance(random.uniform(0.7, 1.3))
# 回転
obj = obj.rotate(angle=random.randint(0, 360), expand=True, fillcolor=(0, 0, 0, 0))
# 回転により生まれた余計な部分を削除する
crop = obj.convert('RGB').getbbox()
obj = obj.crop(crop)
while True:
obj_x = random.randint(0, bg.size[0] - obj.width)
obj_y = random.randint(0, bg.size[1] - obj.height)
# 配置可能か検証
for _x in range(obj_x, obj_x + obj.width):
for _y in range(obj_y, obj_y + obj.height):
if deployable_area.getpixel((_x, _y)) == (0, 0, 0, 255):
break
else:
continue
break
else:
break
continue
obj_details.append(
{
"xmin": obj_x,
"xmax": obj_x + obj.width,
"ymin": obj_y,
"ymax": obj_y + obj.height,
"name": dirs[j]
}
)
print(obj_x, obj_y, "に", dirs[j], "を配置")
for _x in range(obj.width):
for _y in range(obj.height):
if obj.getpixel((_x, _y)) != (0, 0, 0, 0):
deployable_area.putpixel((_x + obj_x, _y + obj_y), (0, 0, 0, 255))
bg.paste(obj, (obj_x, obj_y), obj.split()[3])
bg.save("./dataset/images/" + str(i).zfill(len(str(num_of_images))) + ".jpg")
アノテーションは PascalVOC 形式で作ります.作るのは以下のような画像と同名の XML ファイルです.
<annotation>
<filename>001.jpg</filename>
<size>
<width>4608</width>
<height>3456</height>
<depth>3</depth>
</size>
<object>
<name>watch</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>928</xmin>
<ymin>1162</ymin>
<xmax>1533</xmax>
<ymax>1861</ymax>
</bndbox>
</object>
</annotation>
記載されている内容は
- filename: 対象の画像名です.
- size
- width/height: 画像の縦横pxです.
- depth: 色の層です.
3は RGB の 3 色に対応します.白黒であれば1です.
- object
- name: 物体の名前です.
- pose:
Left,Frontal,Right,Rearなど物体の向きを記述できます.
特に指定がなければUnspecifiedです. - truncated: オブジェクトの一部分に対応していることを示します.例えば人に対する上半身のみ,や画像で見切れている場合に
1を指定します.そうでなければ0です. - difficult: 認識が難しいオブジェクトを示します.例えば他の要素を含まないと認識できないものであるときは
1を指定します.そうでなければ0です. - bndbox: 物体の存在する範囲を指定します.左上座標をxmin/ymin, 右下座標を xmax/ymax に記述します.
PascalVOC 形式には他にも記述可能な項目がありますが,このリポジトリを利用する上で必要なことは以上です.
形式の詳細はこちら: The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Development Kit
画像とアノテーションのフォルダは分けておきます.
XML は Python なら ElementTree ライブラリで作れます.
Python 実装例(クリックして展開)
import xml.etree.ElementTree as Et
# from PIL import Image
# bg = Image.new('RGB', size, (red, green, blue))
# obj_details = [{
# "xmin": 131,
# "xmax": 176,
# "ymin": 309,
# "ymax": 403,
# "name": "book"
# }]
root = Et.Element("annotation")
filename = Et.SubElement(root, "filename")
filename.text = str(i).zfill(len(str(num_of_images))) + ".jpg"
size = Et.SubElement(root, "size")
width = Et.SubElement(size, "width")
width.text = str(bg.size[0])
height = Et.SubElement(size, "height")
height.text = str(bg.size[1])
width = Et.SubElement(size, "depth")
width.text = str(3)
for obj_detail in obj_details:
object = Et.SubElement(root, "object")
name = Et.SubElement(object, "name")
name.text = obj_detail["name"]
pose = Et.SubElement(object, "pose") # Pose
pose.text = "Unspecified"
truncated = Et.SubElement(object, "truncated") # truncated
truncated.text = str(0)
difficult = Et.SubElement(object, "difficult") # difficult
difficult.text = str(0)
bndbox = Et.SubElement(object, "bndbox")
xmin = Et.SubElement(bndbox, "xmin")
xmin.text = str(obj_detail["xmin"])
xmin = Et.SubElement(bndbox, "xmax")
xmin.text = str(obj_detail["xmax"])
ymin = Et.SubElement(bndbox, "ymin")
ymin.text = str(obj_detail["ymin"])
ymax = Et.SubElement(bndbox, "ymax")
ymax.text = str(obj_detail["ymax"])
xml = Et.ElementTree(root)
xml.write("./dataset/xml/" + str(i).zfill(len(str(num_of_images))) + ".xml", encoding="utf-8")
TFRecord を作る
学習には画像とアノテーションをまとめた TFRecord 形式のファイルを生成する必要があります.
その前に train として使う画像のリスト,val として使う画像のリスト,学習させる物体が書かれたリストが書かれたファイルを作ります.
改行してファイル名を記述していきます.拡張子は不要で,train に利用したい画像が 001.jpg から 100.jpg なら
000
001
002
...
(略)
...
100
と順に記述して適当に train.txt のように名前をつけて保存しておきます.val.txt も同様に行います.
物体が書かれたリストも同じように改行して記述していきます.
apple
orange
...
(略)
...
banana
適当に dataset.names のように名前をつけて保存します.
ここまでで以下のようにな構造になっているといい感じです.
dataset
|--images
| |--000.jpg
| |--001.jpg
| |--...
|--xml
| |--000.xml
| |--001.xml
| |--...
|--train.txt
|--val.txt
|--dataset.names
リポジトリのコードは VOC2012 データセットに対応しているので,リポジトリのコードを適宜変更します.変更箇所は以下の3つです.
# 20-21行目: 画像を読み込めるように
img_path = os.path.join(FLAGS.data_dir, 'images', annotation['filename'])
# 95-96行目: train.txt / val.txt を読み込めるように
image_list = open(os.path.join(FLAGS.data_dir, '%s.txt' % FLAGS.split)).read().splitlines()
# 99-100行目: XML を読み込めるように
annotation_xml = os.path.join(FLAGS.data_dir, 'xml', name + '.xml')
ここまで来たら準備完了です.TFRecord を生成するには以下を実行します.
$ python tools/voc2012.py \
--data_dir './dataset' \
--split train \
--output_file ./dataset/dataset_train.tfrecord
$ python tools/voc2012.py \
--data_dir './dataset' \
--split val \
--output_file ./dataset/dataset_val.tfrecord
学習させる
転移学習をさせるための元の重みデータをダウンロードしてくる必要があります.
$ wget https://pjreddie.com/media/files/yolov3.weights -O data/yolov3.weight
また,重みデータを変換するために,以下を実行します.
$ python convert.py
適宜引数を変えて以下を実行します.
$ python train.py \
--dataset ./dataset/dataset_train.tfrecord \
--val_dataset ./dataset/dataset_val.tfrecord \
--classes ./dataset/dataset.names \
--num_classes 20 \
--mode fit --transfer darknet \
--batch_size 16 \
--epochs 50 \
--weights ./checkpoints/yolov3.tf \
--weights_num_classes 80
./checkpoint/ に記録されていきます.
学習が停滞したら EarlyStopping が効きます.
検出させてみる
Webカメラからの入力を受け付けているので試してみます.
実際にラムネ(2枚)と時計(5枚)の画像を貼り付けた画像を100枚ほど生成して学習させてみました.
python detect_video.py --video 0 --weight ./checkpoint/yolov3_train_42.tf --num_classes 2 --classes ./dataset/dataset.names
精度は怪しいですが用意する手間を考えたらかなりよくできたのではないでしょうか.(映像が汚くて申し訳ない)

これから
このリポジトリには性能評価指標である mAP が実装されていません.
要望は多いようで最近の Issue にもあります.yolov3-tf2/issues/125 は古いながらも参考になりそうです.
時間があれば試してみます.