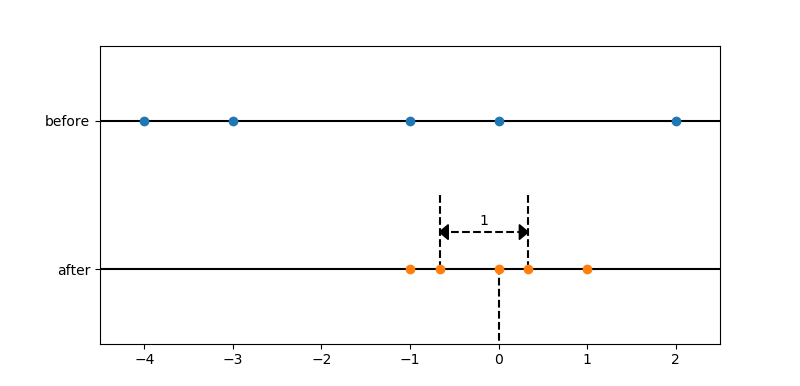
scikit-learnの前処理機能の1つであるRobustScalerについて理解を深めるために、単純なデータポイントに適用した結果をグラフにプロットしてみました。
RobustScalerの特徴
- データポイントを、中央値が0になり、四分位範囲(interquartile range、IQR)が1になるように移動・スケール変換する。
- 高校数学では四分位数をデータポイントの中央値前後部分の中央値として求めるが、RobustScalerではデータポイントの要素数を $n$ とすると、$q$ 分位数(quartile)は $(n-1)q +1$ 番目のデータポイント(自然数にならない場合は値を補完する)として求める。
- 例:5個の要素を持つデータポイントでは、25%分位数は2番目の要素になる。
- 平均と分散を使った移動・スケール変換に比べて、外れ値の影響を受けにくい。
検証用コード
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import RobustScaler
# 検証用データポイント
X = np.array([[-4], [-3], [-1], [0], [2]])
# RobustScalerを検証用データポイントに適用する。
scaler = RobustScaler()
X_ft = scaler.fit_transform(X)
# 適用前後のデータポイントをグラフに描画する。
fig = plt.figure(figsize=(8,4))
ax1 = fig.add_subplot(1, 1, 1)
# 適用前のデータポイントをx=1上にプロットする。
ax1.hlines([1], -5, 3)
ax1.plot(X, np.array([[1], [1], [1], [1], [1]]), "o")
# 適用後のデータポイントをx=0上にプロットする。
ax1.hlines([0], -5, 3)
ax1.plot(X_ft, np.array([[0], [0], [0], [0], [0]]), "o")
# グラフの見た目を調整する。
ax1.set_xlim(-4.5, 2.5)
ax1.set_ylim(-0.5, 1.5)
ax1.set_yticks([0, 1])
ax1.set_yticklabels(["after", "before"])
# グラフに注釈(補助線など)を入れる。
ax1.vlines([X_ft[2]], -1, 0, linestyles='dashed')
ax1.vlines([X_ft[1], X_ft[3]], 0, 0.5, linestyles='dashed')
hw = 0.1
hl = 0.1
ax1.hlines([0.25], X_ft[1], X_ft[3], linestyles='dashed')
# 25%分位数は2番目(インデックス1)、75%分位数は4番目(インデックス3)となる。
ax1.arrow(X_ft[3][0]-hl, 0.25, 0.001, 0, fc='black', ec='black', head_width=hw, head_length=hl)
ax1.arrow(X_ft[1][0]+hl, 0.25, -0.001, 0, fc='black', ec='black', head_width=hw, head_length=hl)
ax1.text((X_ft[3][0]+X_ft[1][0]) / 2 - 0.05, 0.3, '1', fontsize=10)
# グラフを表示する。
plt.show()
実行結果