株式会社 日立製作所 木下翔伍
はじめに
Apache Hadoop (以降Hadoop)とは、多種/大量なデータを蓄積し、高速に分散処理するための基盤となるOSSミドルウェアです。Hadoopの周辺では、Hadoopをより高度に利用するための関連OSSが登場してきており、これらをうまく組み合わせて活用することでデータの収集から蓄積、分析、結果の可視化までをカバーすることができます。このようにHadoopの周辺で関連OSS群が結びつき、補いながら共存している様子はHadoopエコシステムと呼ばれています。
この記事では、CDH(Cloudera社が提供している、Hadoopと、その周辺でHadoopエコシステムを構成するOSS群をパッケージングしたディストリビューション)を使ってSIしたときに、実際に遭遇した大小さまざまなトラブルから得た注意点を一口メモ風にご紹介します。
ネットワーク構成の検討は慎重に
名前解決
クラスタを構成するノードを名前解決するために、各ノードのホスト名にはhostnameコマンドの実行結果として得られるものを使います。名前解決は順引きと逆引き、両方できなければいけません。
DNSで名前解決することが望ましいですがhostsファイルで名前解決しても構いません。ただしCDH/Cloudera Managerはhostsファイルの設定にFQDNがあると、それを使って管理しようとします。ホスト名にFQDNを使わずhostsファイルで名前解決するとき、エイリアスにFQDNを残すことがないよう注意してください。
10.196.1.11 manager server01.mydomain.com
10.196.1.12 master01 server02.mydomain.com
・・・(略)・・・
10.196.1.18 worker04 server08.mydomain.com
10.196.1.11 manager
10.196.1.12 master01
・・・(略)・・・
10.196.1.18 worker04
ネットワーク構成とネットワークインタフェース
同一ノード上で複数ネットワークインタフェースを使用して、Hadoop関連の通信をおこなうような動作はサポートされません。Hadoopの処理で使うインタフェースは1つに特定しておきます。もちろん、このネットワークインタフェースは名前解決をしたときに使われるように設計する必要があります。
例えば次のようなネットワーク構成はNGです。
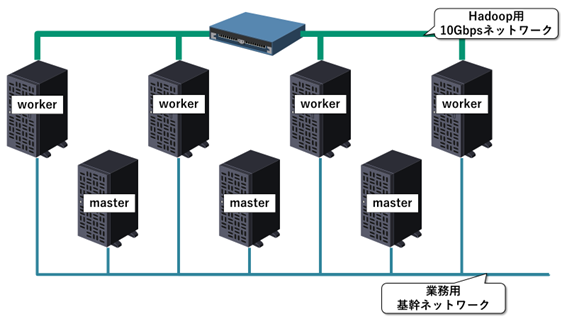
ワーカノード間では多量の通信が発生します。それが業務用の基幹ネットワークを圧迫するのを避けようと、ワーカノードどうしだけを結ぶ10Gbpsネットワークを追加してしまった例です。ワーカノードどうしの通信はよいのですが、ワーカノードとマスタノードの間の通信は、必ず業務用基幹ネットワークを通る必要があります。すなわち、ワーカノードはHadoopの処理・通信において2つのネットワークインタフェースを通信相手によって使い分ける必要が出てきます。このような構成はサポートされませんので避けなければいけません。
一方、次のようなネットワーク構成はOKです。
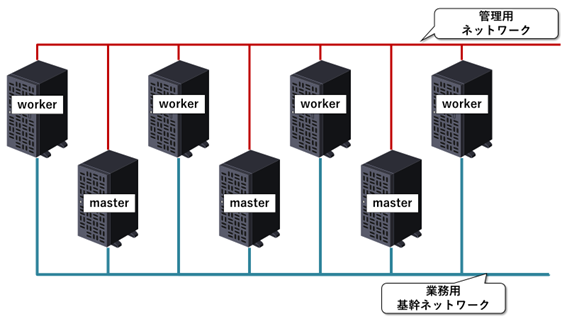
全ノードが業務用基幹ネットワークと管理系ネットワークに接続されています。このときHadoopの処理はすべて業務用基幹ネットワークを使うようにしておけば、期待通り正常に動作します。ネットワークインタフェースを複数搭載していること自体は問題ではありません。
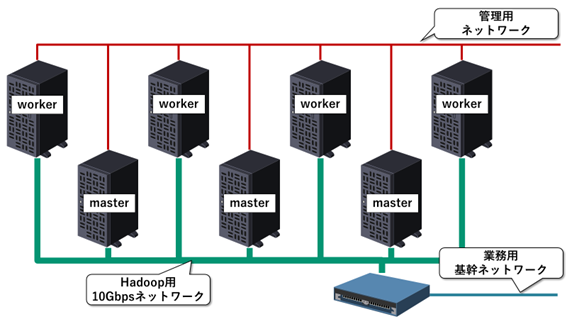
先ほどの例ではノード間通信が業務用基幹ネットワークを圧迫してしまうことを懸念する人がいるかもしれません。その解決案の一例として管理用ネットワークとは別に、クラスタの各ノード間を結ぶ新しいネットワークを導入する例を示します。Hadoopの動作要件を満たし、かつ既存の業務用基幹ネットワークに与える影響を抑えた、最もシンプルなネットワーク構成ではないでしょうか。
Impala / HiveはRDBではない
SQL on Hadoopを実現するためのツール(Hadoopエコシステムのひとつ)として、ImpalaやHiveがあります。ImpalaやHiveではHDFSに蓄積した構造化データをSQLライクに操作できます。しかしSQL風にデータを扱えるからといって、RDBと同様に考えて扱ってはいけません。いくつかRDBとは大きく異なる点と考え方をご紹介します。
データはファイルに保存
Impala/Hiveは投入されたクエリを解釈しHadoopクラスタ上のリソースを使ってデータ処理を実行しますが、データストアを内包しているわけではなく、Hadoopの分散データストア(分散ファイルシステム)であるHDFSなどにデータを格納します。Impala/Hiveはクエリを解釈して処理するサービスであって、データストアは他のサービスに任せているということです。
データの更新はしない
HDFSにはライトワンスという特性があり、一旦書きこんだファイルの本文を修正して更新することはできません(最近ではKuduというデータの更新が可能な分散データストアも登場してはいますが)。そのためクエリエンジンにImpalaやHiveを、データストアにHDFSを用いた場合、データの更新を前提とする処理は不向きといえます。
Impalaはアドホッククエリ向け
Impalaはデータサイエンティスト等がインタラクティブに分析をするときに用いられることを想定して開発されており、なによりも結果を迅速に返すことを重視します。そのため何らかの原因で処理が失敗した場合にはリトライせず、すみやかに処理を中断します。またクエリの実行開始時に用いるメモリ量を推定しますが、これがクラスタ利用可能なメモリ量を上回ったときには、実際に使用するメモリ量が利用可能な範囲であったとしても、クエリの実行をすることなく諦めて、その旨をユーザへ通知します。SQL on Hadoopでバッチ処理をする場合には、処理エンジンとしてノード障害時などのリトライ機構のあるSpark/MapReduceを使用するHiveを推奨します。
おわりに
本記事ではHadoopを構築するときのポイントをいくつかピックアップしてご紹介しました。Hadoop活用の一助となれば幸いです。