この記事は何?
多くの金融機関で、口座の取引明細を CSV で取得できるようになっています。
これらを Excel を使って会計処理したいときに、金融機関ごとにバラバラな CSV 形式 (項目名や日付の表現方法など) を統一したくなるわけですが、そんなとき、近頃の Excel に標準装備されている PowerQuery が威力を発揮します。ポチポチとクリックしていくだけで、それぞれの CSV を統一した Excel テーブルに変換できます。
それはそれで便利ですが、統一化後の項目名を変更したくなったら、それぞれの「CSV 読込みクエリ」の該当箇所を変更しなければなりませんし、新たな形式の CSV に対応しようと思ったら、始めからポチポチとクリックしていく必要があります。
もし、さまざまな形式の CSV に対応したひとつのロード関数があって、その引数を変えて呼ぶだけでいい、となったら便利ではないかな、と考えたので、試行錯誤しながら作ってみました。その中で M 言語を用いたプログラミングのプラクティスもちょっと探ってみました。
できたもの
「汎用的な口座取引明細CSVローダ」
とりあえずできたものが、下に示す関数クエリ「口座CSVロード」です。
(はっきり言って読みやすいコードではありません。あしからず。)
/*
* [引数]
* key : 口座を区別するための名前
* fieldSpecString : CSV のどの項目から必要な情報を得るかの指定
*
* optString : key=value 形式で書かれた CSV 形式に関するオプション
* - reverse : 新しい取引から記述されている場合に指定 (T/F)
* - skip : CSV ファイルの先頭に CSV 形式ではない情報が記述されている行数 (整数)
* - cols : 項目数。skip > 0 の場合は先頭行で項目数がわからないので明示的に指定する (整数)
* - solidDate : 日付が YYYYMMDD 形式の場合に指定 (T/F)
*
* [クエリ]
* CSVフォルダ : CSV が置いてあるフォルダのパス
*/
(key as text, fieldSpecString as text, optional optString as text) =>
let
SeqExec = (Obj, Funcs) => List.Accumulate(Funcs, [k=false,o=Obj],
(_, f) => if [k] then _ else if f = null then [k=true,o=[o]] else [k=false,o=f([o])])[o],
/*
* オプションの処理。デフォルト値と引数 optString から Opts レコードを作成する。
*/
Opts = ((default, pairs)=>let
rcd1 = Record.FromList(List.Transform(pairs, each if List.Count(_) > 1 then _{1} else true), List.Transform(pairs, each _{0})),
rcd2 = SeqExec(default, {
each Record.ToTable(_),
each Table.AddColumn(_, "Default", each if List.Count([Value]) > 1 then [Value]{0} else false),
each Table.AddColumn(_, "Type", each if List.Count([Value]) > 1 then [Value]{1} else Logical.Type),
each Table.AddColumn(_, "_Value", (_) => let
v = Record.FieldOrDefault(rcd1, [Name], [Default])
in if [Type] = Int64.Type then Int64.From(v) else Value.ReplaceType(v, [Type])),
each Table.SelectColumns(_, { "Name", "_Value" }),
each Table.RenameColumns(_, {{ "_Value", "Value" }}),
each Record.FromTable(_)
})
in rcd2
)([ skip={0, Int64.Type}, cols={0, Int64.Type}, reverse={}, solidDate={} ],
List.Transform(Text.Split(optString, ","), each Text.Split(_, "="))),
/*
* 最終的に出力するフィールドに関する設定
*/
Junks = ((m) => List.Transform(Table.ToRecords(Record.ToTable([
口座={ type text, (_) => key },
seq={},
日付={ type date,
let s = m(0), cnv = (_)=> Combiner.CombineTextByDelimiter("/")(Splitter.SplitTextByPositions({0,4,6})(_))
in if s{0} = 1 then if Opts[solidDate] then each cnv(Record.Field(_, s{1})) else each Record.Field(_, s{1})
else each Record.Field(_, s{1}) & "/" & Record.Field(_, s{2}) & "/" & Record.Field(_, s{3}),
each Text.Length(_) > 7
},
出金={ Int64.Type,
let s = m(1)
in if s{0} = 2 then if s{1} = "" then each 0 else each Record.Field(_, s{1})
else each if Record.Field(_, s{1}) = s{2} then Record.Field(_, s{4}) else 0
},
入金={ Int64.Type,
let s = m(1)
in if s{0} = 2 then if s{2} = "" then each 0 else each Record.Field(_, s{2})
else each if Record.Field(_, s{1}) = s{3} then Record.Field(_, s{4}) else 0
},
摘要={ type text, each Record.Field(_, m(2){1}) },
残高={ Int64.Type, if m(3){1} = "" then each 0 else each Record.Field(_, m(3){1}) }
])), (rcd)=> ((name, arr) => [
name=name,
tmpName="__" & name,
type= if List.IsEmpty(arr) then Int64.Type else arr{0},
func= if List.IsEmpty(arr) then null else arr{1},
checker=if List.IsEmpty(arr) or List.Count(arr) < 3 then null else arr{2}
])(Record.Field(rcd, "Name"), Record.Field(rcd, "Value"))))((idx) =>
let spec = Text.Split(Text.Split(fieldSpecString, "/"){idx}, ",")
in List.InsertRange(spec, 0, { List.Count(spec) })),
/*
* 読み込んだ CSV を変換したテーブル
*/
RawTable = ((path, opts)=>
Csv.Document(File.Contents(path), if Opts[cols] > 0 then Record.AddField(opts, "Columns", Opts[cols]) else opts)
)(CSVフォルダ & key & "2024.csv", [Delimiter=",", Encoding=932, QuoteStyle=QuoteStyle.None]),
/*
* テーブルの標準化処理
*/
ProperTable = SeqExec(RawTable, {
each Table.PromoteHeaders(Table.Skip(_, Opts[skip])),
each if Opts[reverse] then Table.ReverseRows(_) else _,
(w) => List.Accumulate(Junks, w, (tbl, _) =>
if [func] = null then tbl else Table.AddColumn(tbl, [tmpName], [func])),
(w) => Table.AddColumn(w, "Validity",
each List.Accumulate(Junks, true,
(v,j)=> if not v or j[checker] = null then v
else j[checker](Record.Field(_, j[tmpName]))), Logical.Type),
each Table.RemoveMatchingRows(_, {[Validity=false]}, "Validity"),
((idxName) => (_) => Table.AddIndexColumn(_, idxName, 1))(List.Select(Junks, each [func] = null){0}[tmpName]),
(w) => Table.SelectColumns(w, List.Transform(Junks, each [tmpName])),
(w) => Table.TransformColumnTypes(w, List.Transform(Junks, each { [tmpName], [type] })),
(w) => Table.RenameColumns(w, List.Transform(Junks, each { [tmpName], [name] })),
each _
}),
Dummy = 1
in
ProperTable
使い方
たとえば、三井住友銀行 (SMBC) の取引明細 CSV は、日時が「年月日」列、出金が「お引出し」列、入金が「お預入れ」列、摘要に相当するものが「お取り扱い内容」列、残高が「残高」列にあり、新しい取引から順に並んでいるので、次のようなクエリで標準化したテーブルが読み込まれます。
= 口座CSVロード("SMBC", "年月日/お引出し,お預入れ/お取り扱い内容/残高", "reverse")
埼玉りそな銀行の場合、日時は「取扱日付 年」「取扱日付 月」「取扱日付 日」の 3 列に分割して書かれています。出金、入金、摘要に相当するもの、残高は、それぞれ「お引出し」列、「お預入れ」列、「お取り扱い内容」列、「残高」列にあります。取引は時系列順に並んでいるので、reverse で反転する必要はなく、次のようなクエリで標準化したテーブルが読み込まれます。
= 口座CSVロード("埼玉りそな", "取扱日付 年,取扱日付 月,取扱日付 日/取引名,支払,入金,金額/摘要/取引後残高", "")
ゆうちょ銀行の取引明細 CSV は、日時が「取引日」列、出金が「払出金額(円)」列、入金が「受入金額(円)」列、摘要に相当するものが「詳細2」列、残高が「現在(貸付)高」列にあります。CSV ファイルの先頭に「お客さま口座情報」が 7 行にわたって記述してありますので、これを skip=7 で飛ばします。先頭に CSV 以外の情報があると Csv.Document() 関数が自動で列認識できないので、cols=9 で列数も指定する必要があります。
また、「取引日」列の日付は YYYYMMDD という 8 桁の数字で書かれているので solidDate も指定する必要があります。
まとめると、標準化したテーブルが読み込むクエリは次のようになります。
= 口座CSVロード("ゆうちょ", "取引日/払出金額(円),受入金額(円)/詳細2/現在(貸付)高", "skip=7,cols=9,solidDate")
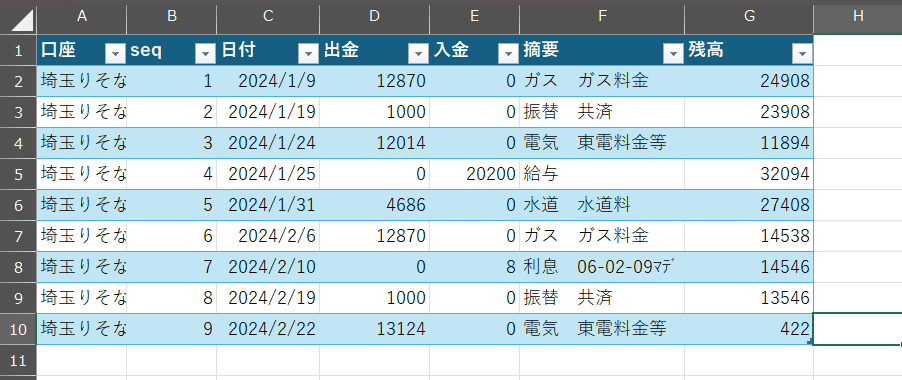
標準化されたテーブルは、たとえば次のスクリーンショットのようになります。
「seq」列はこの「口座」における連番です。標準化されているので複数の口座について、ひとつのテーブルにまとめることができますが、その際、「口座」と「seq」でレコードを一意に指定することができます。
「汎用的な口座取引明細CSVローダ」に関するプログラミング的視点からの説明
let ブロック末尾のダミー変数定義式
let ブロック末尾にダミーの変数定義式 Dummy=1 を入れています。これは開発時の名残りで、完成時にはまったく意味がありません。開発時に式を追加したり削除したりする際に、行末のカンマの有無を気にしないで済むように入れているダミーです。
すなわち、let ブロック内の式は、最後の式はカンマがあってはいけないし、最後でない式はカンマが必須なので、うっかりすると行末カンマのせいでシンタックスエラーが発生します。最後の行にダミー行を書くことで、処理が増えようが減ろうが、常に行末カンマをつけておけばいいことになります。
List.Accumulate() を用いて連続変換をコンパクトに書き、変更に強くする
PowerQuery を使っていると、「元々のテーブルの先頭行をヘッダーに変換して、列を逆順にして、インデックス列を追加して、列名を変更して」のように、あるオブジェクト (テーブルのことが多い) に連続で変換を作用させていくことがよくあります。実際にはこれは、一つのオブジェクトに変換を作用させているのではなく、「あるテーブルの先頭行をヘッダーに変換したテーブルを作り、そのテーブルに列を逆順にしたテーブルを作り、そのテーブルにインデックス列を作り、そのテーブルの列名を変更したテーブルを作り」のように、毎回新しいオブジェクト (テーブル) を作成しています。
たとえば、次のようなコードになります。
NewTable = let
Table1 = Table.PromoteHeaders(OrgTable),
Table2 = Table.ReverseRows(Table1),
Table3 = Table.AddIndexColumn(Table2, "ID", 1),
Table4 = Table.RenameColumns(Table3, { "Name", "Key" }),
Dummy = 1
in
Table4
ここで処理の順番を「逆順→インデックス追加」から「インデックス追加→逆順」に変えたくなったらどうなるでしょう。式の順番を入れ替えるだけでは駄目で、変数名も入れ替える必要があります。
NewTable = let
Table1 = Table.PromoteHeaders(OrgTable),
Table3 = Table.AddIndexColumn(Table1, "ID", 1), // Table2 -> Table1
Table2 = Table.ReverseRows(Table3), // Table1 -> Table3
Table4 = Table.RenameColumns(Table2, { "Name", "Key" }), // Table3 -> Table2
Dummy = 1
in
Table4
変換処理の追加や削除でも同様の問題 (というか面倒臭さ) が発生します。
この問題 (というか面倒臭さ) を、List.Accumulate() を用いて解消します。
そのために定義した関数が SeqExec() です。
SeqExec = (Obj, Funcs) => List.Accumulate(Funcs, [k=false,o=Obj],
(_, f) => if [k] then _ else if f = null then [k=true,o=[o]] else [k=false,o=f([o])])[o],
SeqExec() は、第0引数に処理対象のオブジェクトを、第1引数に「ひとつのオブジェクトを引数にとり変換後のオブジェクトを返す関数」のリストをとります。
このSeqExec()を用いると、先の例は次のように書けます。
NewTable = SeqExec(OrgTable, [
each Table.PromoteHeaders(_),
each Table.ReverseRows(_),
each Table.AddIndexColumn(_, "ID", 1),
each Table.RenameColumns(_, { "Name", "Key" }),
each _])
この書き方ならば、途中の変数名を考える必要もありませんし、行を入れ替えるだけで処理の順番を入れ替えることができます。
なお、リスト末尾の each _ は、let ブロックの末尾のダミー式と同じ目的で入れてあるものです。
それと、 SeqExec() にはもう一つ、デバッグに便利な機能が埋め込んであります。次のように、処理リストの中に null を入れておくと、それ以降の変換処理をスキップします。
NewTable = SeqExec(OrgTable, [
each Table.PromoteHeaders(_),
each Table.ReverseRows(_),
null,
each Table.AddIndexColumn(_, "ID", 1),
each Table.RenameColumns(_, { "Name", "Key" }),
each _])
SeqExec() を使わない素朴な書き方は、PowerQuery エディタで途中の結果も見られるというメリットがあったわけですが、この null によるスキップを用いることで、同じように PowerQuery エディタで途中結果を見られるようになります。
let ブロック内のカンマを嫌った即時関数の利用
コンパクトに書きたくなっちゃってやりすぎました。
RawTable = ((path, opts)=>
Csv.Document(File.Contents(path), if Opts[cols] > 0 then Record.AddField(opts, "Columns", Opts[cols]) else opts)
)(CSVフォルダ & key & "2024.csv", [Delimiter=",", Encoding=932, QuoteStyle=QuoteStyle.None]),
これは、次のように書いたほうが断然わかりやすいし、メンテもしやすいですよね。
RawTable = let
path = CSVフォルダ & key & "2024.csv",
opts = [Delimiter=",", Encoding=932, QuoteStyle=QuoteStyle.None],
newOpts = if Opts[cols] > 0 then Record.AddField(opts, "Columns", Opts[cols]) else opts
in
Csv.Document(File.Contents(path), newOpts)
Opts = ((default, pairs)=>let
...
のところも、無駄に即時関数を使っています。
標準化後のフィールドに関する設定
標準化後のフィールドに関する設定は、次のところにまとめて書きました。
Junks = ((m) => List.Transform(Table.ToRecords(Record.ToTable([
口座={ type text, (_) => key },
...
設定は、「フィールド名を Name、設定値をリストにしたものを Value としたレコード」のリストで書くのがいちばんコンパクトに書けそうなのでそうしました。それを加工して、各標準化フィールドごとの設定を次のようなレコードにまとめたもののリストを作成して使っています。
| フィールド名 | 説明 | デフォルト値 |
|---|---|---|
name |
最終的なフィールド名 | |
tmpName |
生CSVの列名と最終的なフィールド名がかぶっても問題ないように利用している一時的フィールド名 | |
type |
このフィールドの型 | Int64.Type |
func |
このフィールド値を元CSVレコードから生成する関数 | null |
checker |
レコード全体が有効であるためにこのフィールド値が許容されるか試す真偽値関数 | null |
おわりに
とりあえず、そんなところで。