TL;DR
- ClaudeCodeのスキルで何ヶ月も塩漬けだったレガシーバグが10分で原因特定
- 鍵は「事前情報ファイル」と「調査結果の自動更新ループ」の2つ
- 基盤系の権限は徹底してReadOnlyに固定し、データ破壊リスクを構造的に消す
対象読者
- 障害対応を抱えているSRE・運用担当・テックリード
- AIエージェントを業務に組み込みたいが、踏み込んだ使い方の事例を探している方
- ClaudeCodeのSkillsを実務でどう使うかに関心のある方
本記事では業務上の理由から、スキルの具体的なファイル構成やプロンプトは公開していません。設計思想と運用フローのみを共有します。
はじめに
数年前から何度か発生していたバグがありました。
特定の業務操作の後にエラー画面に飛ばされる、というものです。発生頻度は月1回程度。レガシーフレームワークの上に他サービスとの連携が層を成しており、再現条件も掴めず、ログを追うだけで丸一日溶けます。担当者は「再現待ち」のまま、チケットだけが積み上がっていました。
これに対して、筆者がやったことは一つだけです。
障害報告のURLをClaudeCodeに渡し、こう打ちました。
「このURLについて調査して」
10分後、原因が特定されました。コードの該当行と、なぜそこが踏まれるのかの条件、そして再現手順までが揃った状態で出てきました。
本記事では、それを実現している「障害調査スキル」の設計思想と、運用フローを共有します。
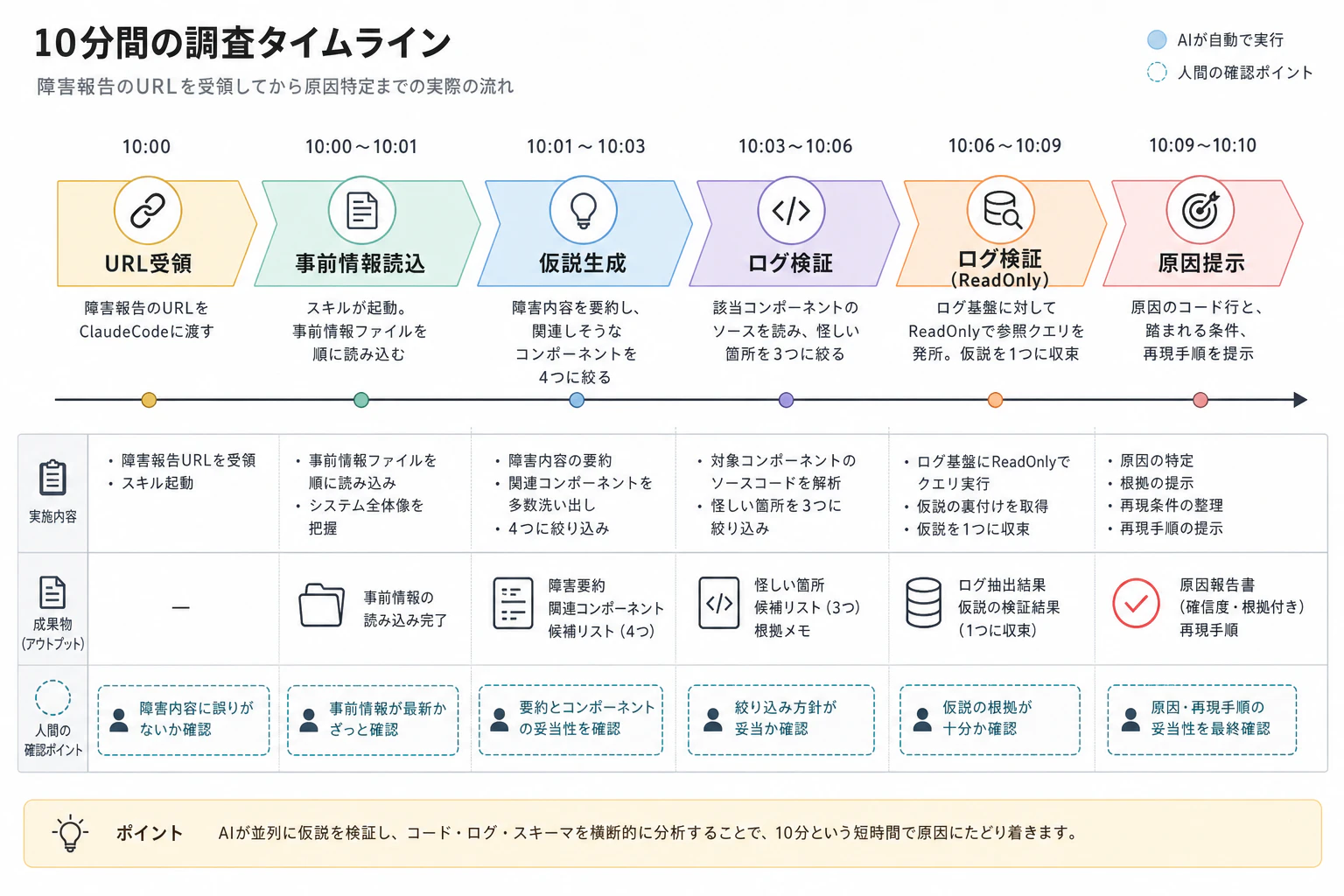
当時の調査タイムライン
実際の流れを時系列で書きます。業界とシステム種別はぼかしています。
| 経過 | 出来事 |
|---|---|
| 00:00 | 障害報告のURLをClaudeCodeに渡す |
| 00:00〜00:01 | スキルが起動。事前情報ファイルを順に読み込む |
| 00:01〜00:03 | 障害内容を要約し、関連しそうなコンポーネントを4つに絞る |
| 00:03〜00:06 | 該当コンポーネントのソースを読み、怪しい箇所を3つに絞る |
| 00:06〜00:09 | ログ基盤に対してReadOnlyで参照クエリを発行。仮説を1つに収束 |
| 00:09〜00:10 | 原因のコード行と、踏まれる条件、再現手順を提示 |
提示された結果には、必ず確信度と根拠がついていました。
確信度: 高
根拠:〇〇ファイル:142のキャッシュ無効化処理が、特定のバッチ完了直後に走るときだけスキップされる。直近30日のログから、バッチ完了と画面での確定処理が同時に起きる場合でのみ障害が再現していることを確認。
筆者の役割は、これを読んで「あ、これ確かに」と頷くだけでした。
なぜAI調査が速いのか
筆者は理由を2つだと考えています。
理由1: 仮説の並列検証
人間は基本的に、仮説を1つずつ検証します。「Aかもしれない」と思ったらAを潰すまで他を見ない。これは認知の限界として仕方のないことです。
AIはこれを並列でやります。「Aの可能性」「Bの可能性」「Cの可能性」を同時に走らせ、コード・ログ・スキーマを横断的に確認しながら、勝ち残った仮説に絞り込んでい
きます。
人間が直列で1時間かけることを、AIが並列で5分にしてしまう、という構図です。
理由2: コード読解能力の差
実体験からコードを読み、構造を把握し、関連を辿る能力において、AIはすでに人間の平均を上回りつつあると感じます。
特にレガシーコードのように、命名規則がバラバラで、コメントもなく、層が深いコードベースでは差が顕著です。人間はこの種のコードを読むだけで疲弊しますが、AIは疲
れず、見落としもしません。
| 観点 | 人間 | ClaudeCode |
|---|---|---|
| 仮説検証の進め方 | 直列 | 並列 |
| 横断的なgrep + 構造理解 | 時間がかかる | ほぼゼロ秒 |
| 集中力・疲労 | 影響大 | 影響なし |
| 命名がバラバラなコードの読解 | 苦手 | 得意 |
もちろん「人間のほうが優秀な領域」もあります。ただ「障害調査の初動」においては「AIに任せた方が速い局面が確実に存在する」というのが実感です。
スキルの全体構成
スキルが回している処理の流れは次の通りです。
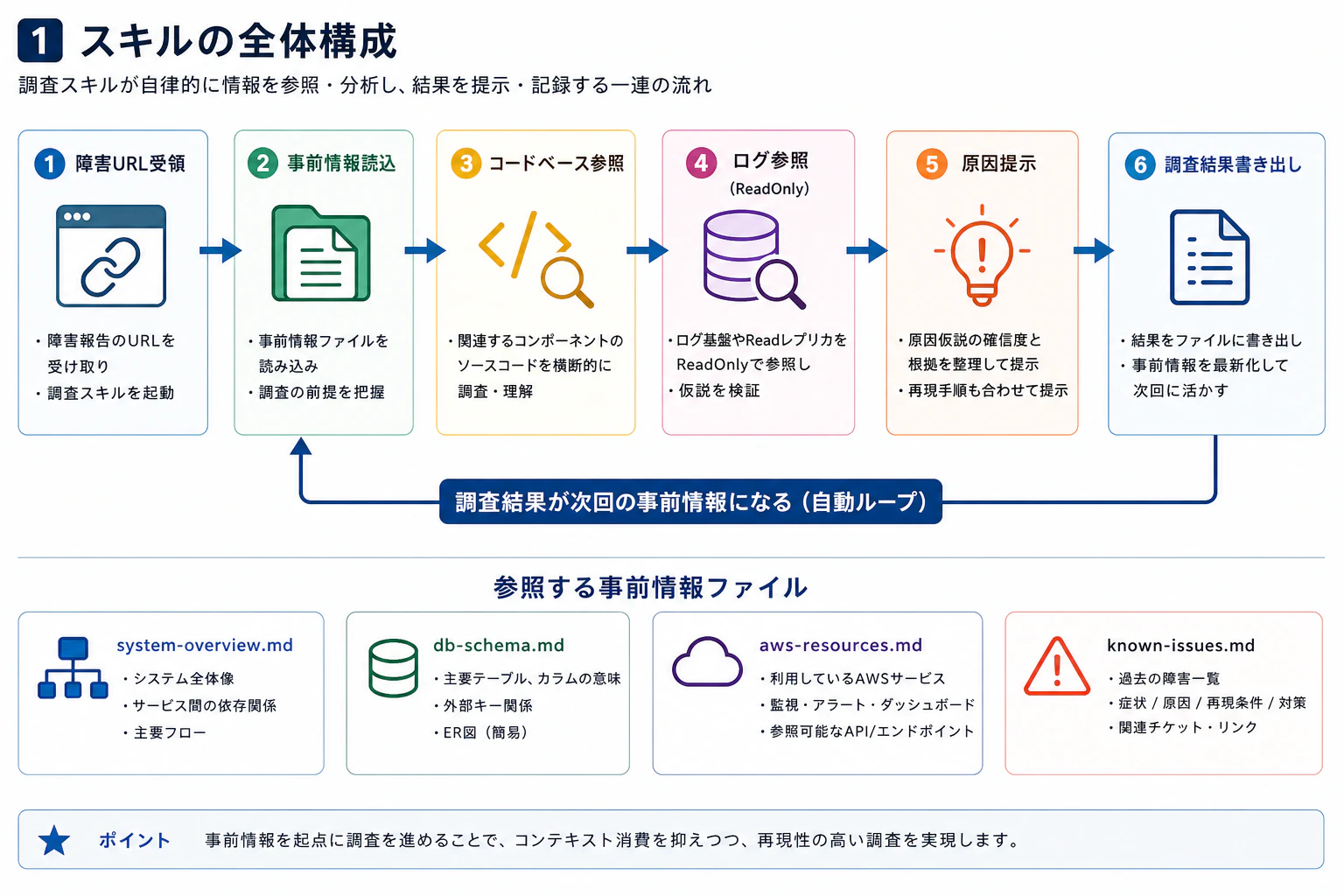
ポイントは「調査結果が次回の事前情報ファイルになる」という自動フィードバックループです。
事前情報ファイルの構造
事前情報ファイルは、4つに分割しています。
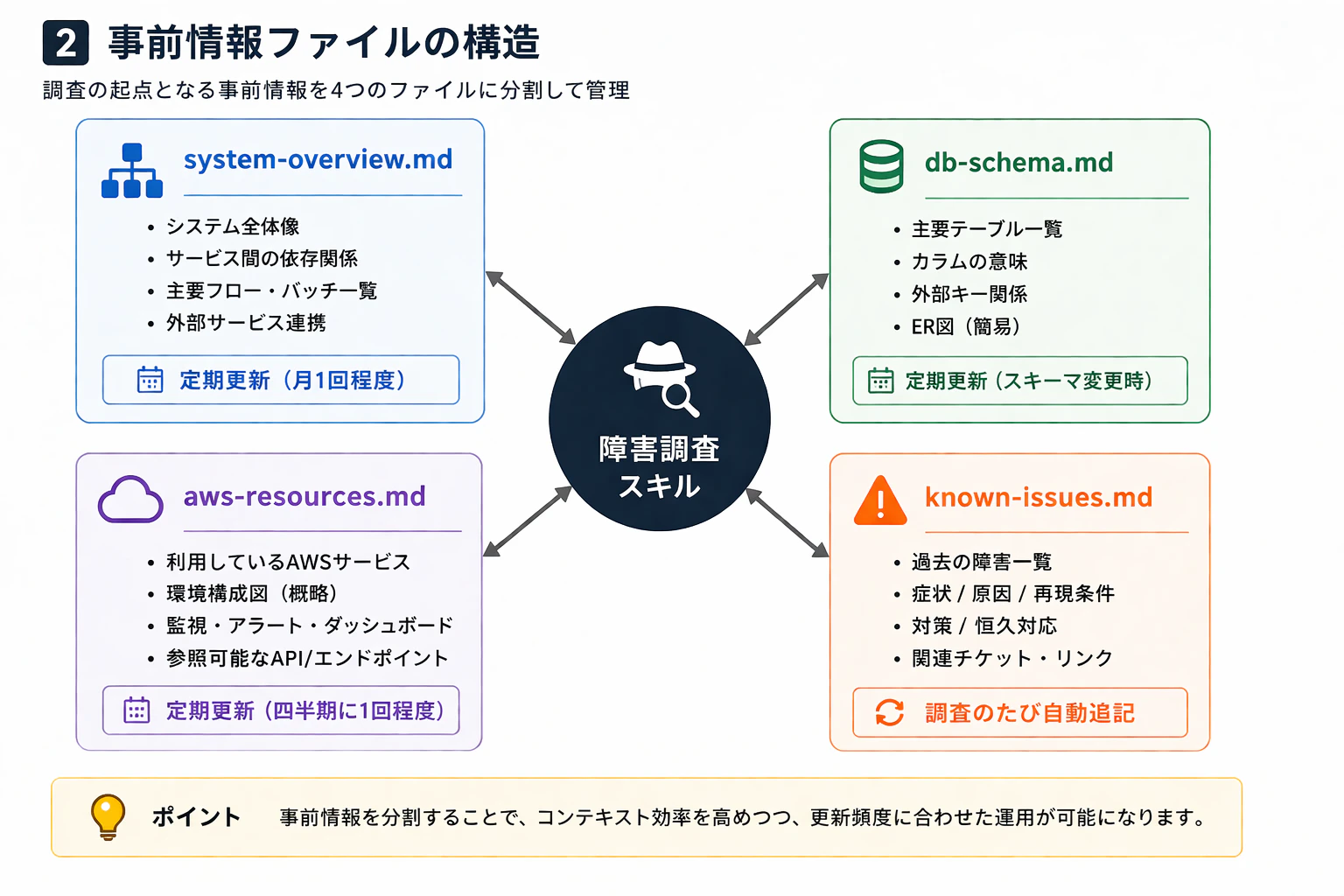
| ファイル | 役割 | 更新頻度 |
|---|---|---|
system-overview.md |
システム全体像、サービス間の依存関係 | 月1回程度 |
db-schema.md |
主要テーブルとカラムの意味、外部キー関係 | スキーマ変更時 |
aws-resources.md |
利用しているマネージドサービス、参照可能な監視ダッシュボード | 四半期に1回程度 |
known-issues.md |
過去の障害調査結果と原因 | 障害調査のたびに自動追記 |
毎回コードベース全体を読み込ませると、コンテキストがすぐ枯渇します。一度AIに読ませて要約をファイル化しておくことで、調査の起点を固定できます。
事前情報ファイルは、AIにコードベースを読ませて自動生成しています。最初の生成時点でほぼ実用レベルに仕上がり、以降は調査のたびに自動追記されるため、メンテコストもほとんどかかりません。
ReadOnlyの徹底
ここは設計上、最も気を使った部分です。
調査のためにデータを壊すというのは、本末転倒では済まない大事故です。スキルが触れる権限は、すべて参照系に固定しています。
| 対象 | 権限 |
|---|---|
| ソースコード | Read |
| ログ基盤 | Read(クエリ実行のみ、書き込み不可) |
| データベース | Readレプリカへのみ接続。本番DBへの直接接続不可 |
| クラウドリソース | 参照系APIのみ。状態変更APIは権限自体を付与しない |
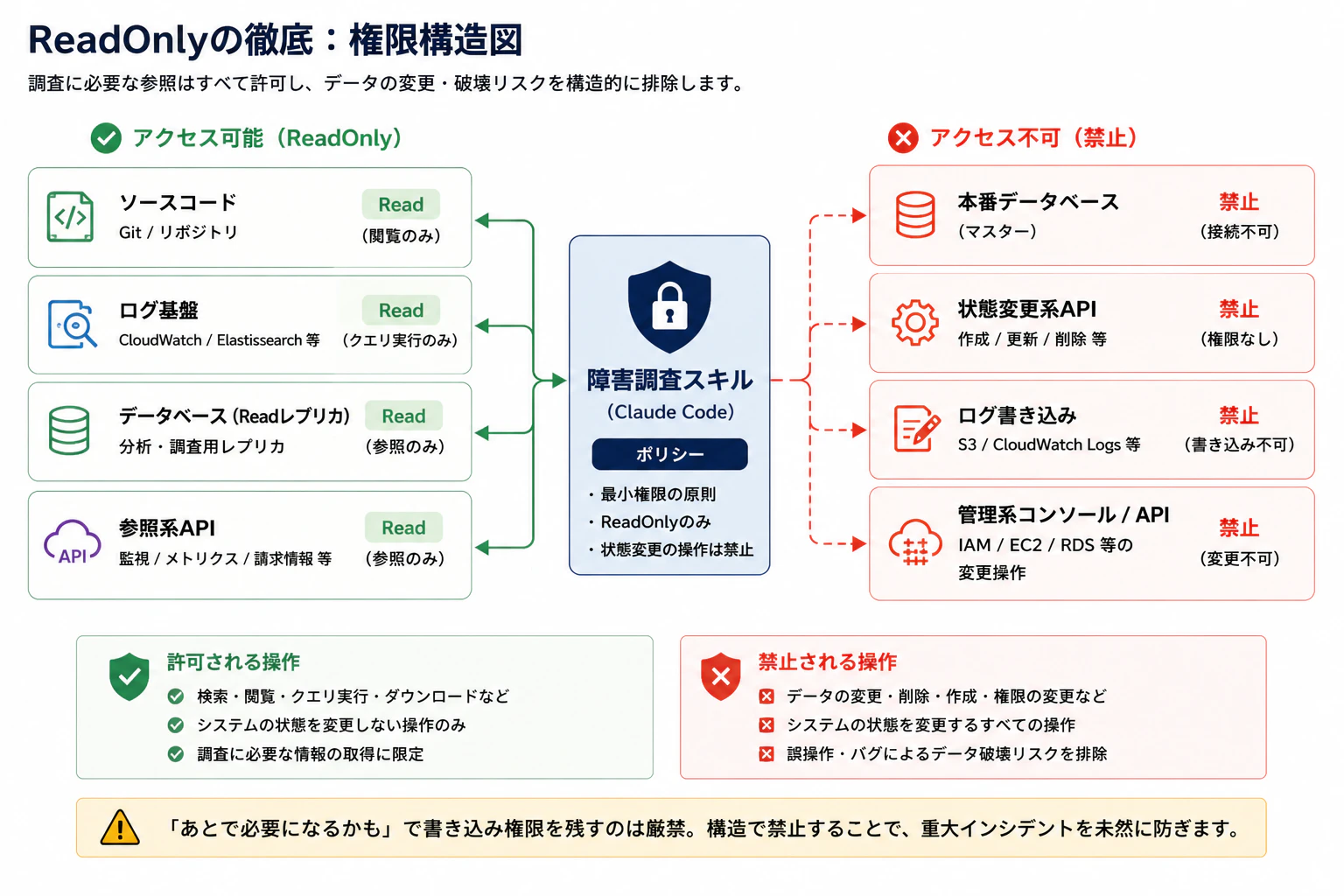
「あとで本番DBに繋ぎたくなるかも」という理由で書き込み権限を残すのは✕。最初から構造で禁じておくように。
自動更新ループ
調査が終わったあと、AIには2つの作業を必ずやってもらいます。
- 調査結果を
known-issues.mdに追記する(症状・原因・再現条件・対策のテンプレで) - 必要であれば
system-overview.mdなどの記述を最新化する
これによって、次に類似した障害が来たときには、AIが過去の調査結果を先に参照します。「この症状、3ヶ月前のあの障害と挙動が似ている」という気付きが、人間より先に出てきます。
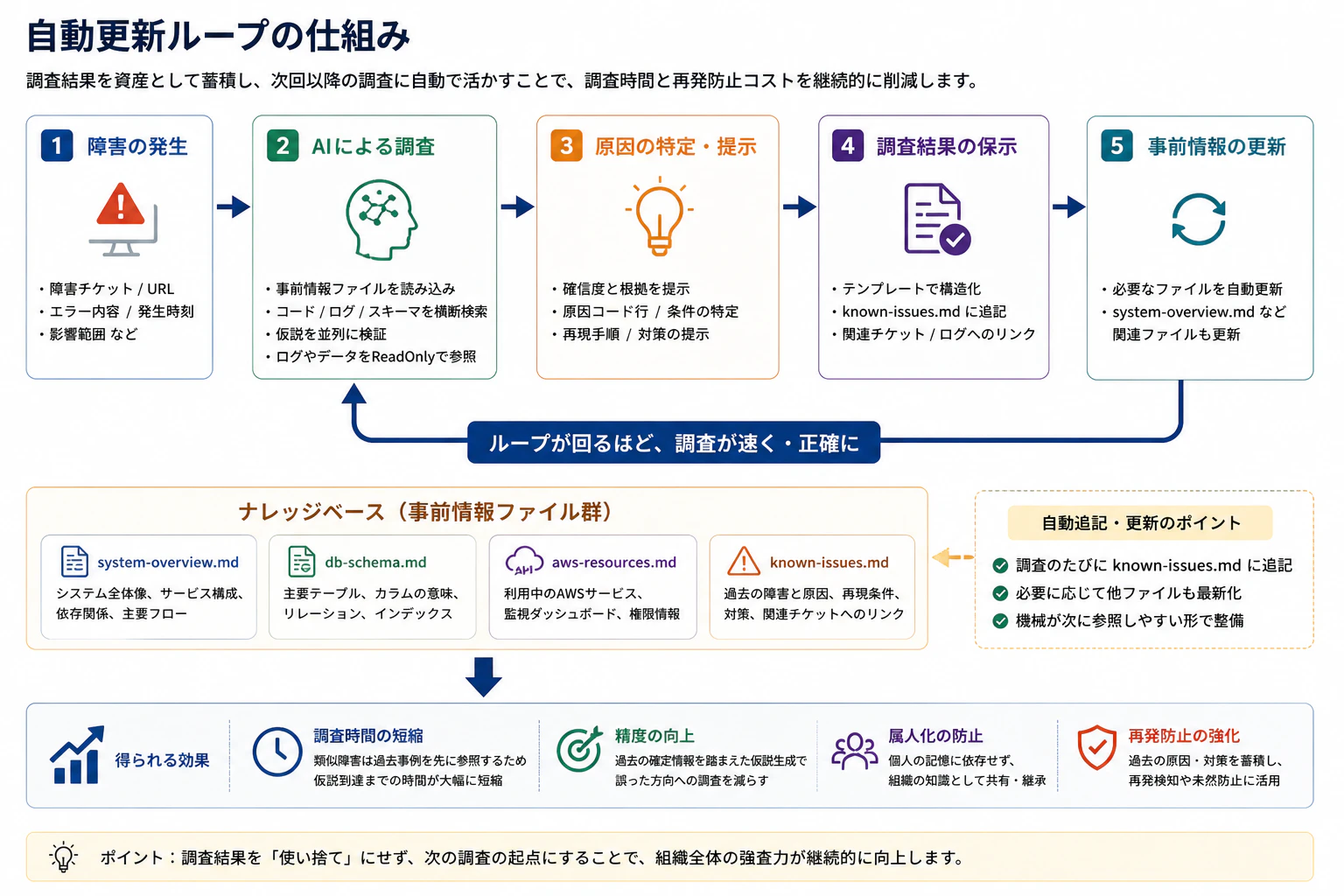
知識が個人の記憶に閉じこもらず、ファイルとして全員で共有されるのが大きいポイントです。
運用上の注意点
万能ではありません。実際にやってみて見えてきた限界もあります。
-
インフラ起因の障害は条件付き:
コードベースに痕跡が残らない障害(ネットワーク・物理・外部APIのレート制限など)は、AIだけでは特定しきれません。ただし、IaC(Terraform / CloudFormation
など)で構成がコード化されていれば、それを読み込ませることで調査範囲に含められます。コード化されていない領域だけが弱点、という整理になります - 事前情報ファイルが古いと精度が落ちる: 月1回程度の鮮度チェックは必須です。「AIに最新化させて、人間がレビューする」という二段構えにしています
- 確信度が低い結果も出る: その場合は素直に「分かりませんでした、追加情報をください」と言わせています。無理に答えさせると、それっぽい嘘が混ざります
おわりに
これまで「再現待ちで放置」だったレガシーコードの障害が、URLを渡すだけで10分で原因特定できるようになりました。
この体験で大きかったのは、調査スキルが個人ではなく組織の資産になることです。担当者が変わっても、過去の調査結果はファイルに残り、次のAIに引き継がれます。
レガシーシステムの「あの人しか分からない」状態を、構造的に解消できる手応えがあります。
あわせて読みたい
本記事と同じく「AI × レガシーコード」の話です。1週間でモダン化が完了した実体験とPMという職種への危機感をまとめました。
AIに開発を任せる時代に、品質をどう担保するかを4案で整理しました。本記事の「ReadOnly徹底」「確信度+根拠」の発想とつながる内容です