keras とは、
Google製のA.I.関連ライブラリである tensowflow を簡単に扱うためのライブラリ?ということでいいかな?
というわけで、本件の前提として最低 python3系 と keras のインストールが必要です。
当方では、とりあえず Anaconda を Windows7 64bit版に入れて、keras を追加したようなかっこうです。(そいつらのインストール方法は他に譲ります。)
keras の例題としては、
MNIST(文字認識ネタで死ぬほどよく出てくるやつ)とかは飽きた、ていうか、入力データが画像だと前処理がややこしいというか、初心者向けで、もっと全体を見渡せるような、軽くて簡単な数値入力~数値出力~視覚化、みたいな例題があれば初心者としてはうれしいではないかと。
#自分も思い切り初心者だし。
で、本件ではどういう課題を想定するか、なんですが、、
あるヤバい施設の周囲の放射能レベル
をいくつかの地点で測り、危険だった地点の座標と、安全だった地点の座標とを、ニューラルネットワークで構築したモデルに学習させ、危険区域がどんな広さ・形なのかを推定しようという作戦です。
これにより、あなたの家が危険区域に入っているかどうか、が一目瞭然になる!というわけです。
いや・・決して実際のデータではないです! 架空です、架空。
入力値は、実際なら何ベクレルとかいう数値になるのでしょうけど、本件ではとりあえず、測定地点のXY座標と、そこで測定した放射能レベルが危険値なのか安全値なのか、という二値の判定をインプット(教師データ)として学習させます。
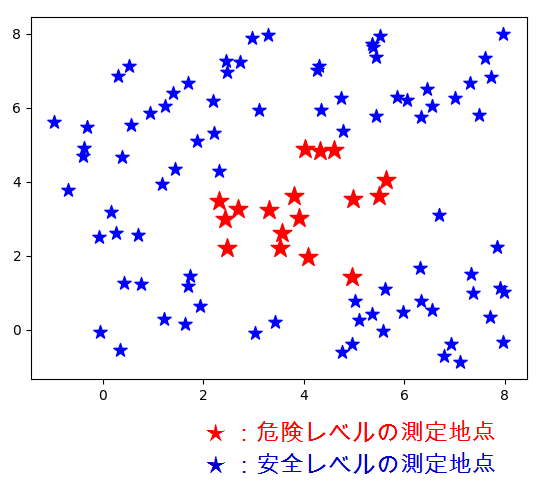
入力データのイメージ :
測定地点の座標と、そこの放射線が危険レベル(=1)かどうか、という判定。
たとえば、
[東経=135.01, 北緯=35.01, 危険度=0 (ここは安全レベル)]
:
[東経=135.05, 北緯=35.05, 危険度=1 (ここは危険レベル)]
:
で、入力データをプロットするとこんな感じ。
ニューラルネットワークの形状(Shape):
2-3-2の、かなりベーシックなやつにします。
(世間ではディープなんとかの話でもちきりですが、こちらは全然ディープではありません。)
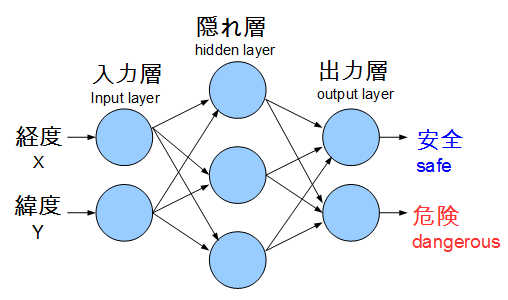
出力層は1個にしてゼロイチで判定してもいいんですが、成行き上2つにしました。
(実は、元ソースはMNISTの4--9 判断のチュートリアルからパクってて、
出力をひとつにする修正方法がわからない・・)
なお、後で隠れ層と出力層にバイアスを追加したが、図示してません。
出力例:
で、危険区域の形をビジュアルに示すことが目標(アウトプット)です。
上記の入力をモデルに食わせると、次のような区域が推定されました。
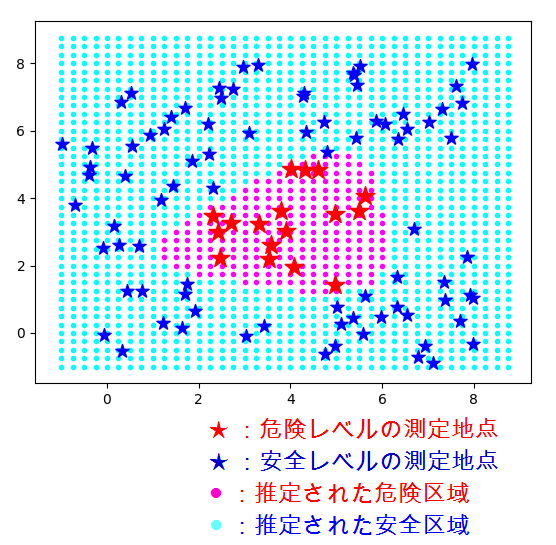
(測定地点の座標は乱数を用いているので、再実行してもこの通りにはなりません。)
ところで、上の出力イメージのどこがエライのか?ってわかりますか?
赤い点と青い点の境界は「非線形分離」を表現している、と言えるんではないしょうか?
すなわち、2次元平面では分類の境界が1本の直線で表せるならば「線形分離可能」とか言われます。
しかし本件では明らかに、危険区域と安全区域は1本の直線では分けられない。
そこで、隠れ層が(ひとつ)あるニューラルネットワークを採用することにより、
直線では表せない(=非線形の)境界線を求められる、という理屈を「一目瞭然」に
表現できているのです! エライ!
ソースコード:
https://github.com/uminor/radioactive_area
上のリンクから、radioactive_area.py をとってきて、
python radioactive_area.py 5000
とかで走らせます。5000 というのは学習の繰り返し数(エポック)です。
入力データの座標生成に乱数を用いているため、再実行しても上記の通りにならず、(5000回では)収束が見えない場合もあります。
学習曲線
ログをリダイレクトして、上記付属のツール log_analyzer.p で読ませる
python radioactive_area.py 5000 >log.txt
log_analyzer.py log.txt >learning_curve.csv
と、学習曲線(損失と精度)のcsvデータが出力されます。
これをExcelで読み込ませてグラフを作ってみると、
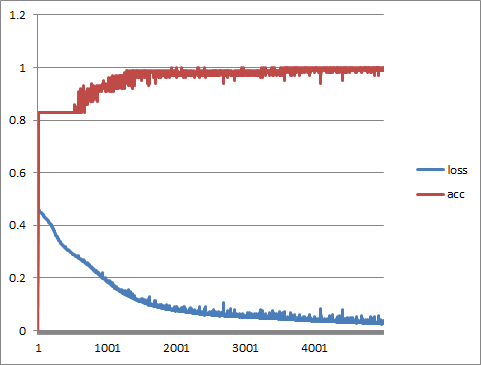
こんなかんじ。
- 横軸がエポック回数。
- loss が損失関数。
- acc が学習用データに対する精度で、1に近づけば完璧だが、データによる。
今回は評価用データは用意していない。つまり交差妥当性評価はおこなっていない。
最適化関数のカスタマイズ
(ソースにコミット済み)
≪変更前≫
model.compile(loss = 'sparse_categorical_crossentropy', optimizer = 'sgd', metrics = ['accuracy'])]
≪変更後≫
from keras.optimizers import SGD
:
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss = 'sparse_categorical_crossentropy', optimizer = sgd, metrics = ['accuracy'])
#カスタマイズといっても適当にサンプルソースからコピペしただけ。。
これによって学習の収束が10倍ぐらい速くなった感じ!
その後、隠れ層と出力層にバイアスを考慮してなかったのを追加。
model.add(Dense(units = hidden_units, input_dim = 2, use_bias=True))
model.add(Dense(units = 2, use_bias=True))