この記事は豊田工業大学Kaggleサークル Advent Calendar 2021の21日目の記事です。
1.はじめに
豊田工業大学3年生のよしむらです。
来年2月に工場実習があるのですが、選考の結果、第一志望の企業に行くことになりました!
選考時には企業が求める経験やスキルを持っていることを用紙にアピールする必要があります。その内定した企業が必須としているものは、
Pythonフレームワークを用いたディープラーニングによる画像認識の経験というものでした。私はこの経験について語ることで第一志望をつかみ取ることができました。
問題は画像認識なんてやったことないということです。
そのことがバレて怒られないように今のうちにやっておこうと思います。
2. 概要
画像分析の初心者のためのKaggleコンペティション Digit Recognizer でPytorchを使って、いわゆるLeNetチックな畳み込みニューラルネットワークの実装をしてみました。
そのためにNKNSH.MASAKIさんのNotebook(notebookc1493f48d8)を参考・改変しています。このNotebookには普通のニューラルネットワークで予測を行ったプログラムが書かれています。そのモデルをCNNに変更することで、結果がどれだけ改善されるかを見てみます。
読者として初心者の方を想定して、初見でもなんとなくの雰囲気はつかめるように意識しました・・・が、分量が予想外に多くなりすぎてしまいました。
3. 技術の説明
3-1. CNNとは
CNN(Convolutional Neural Network, 畳み込みニューラルネットワーク)は、機械学習モデルの一つであるニューラルネットワークの中でも、とりわけ画像を扱いたいときに使われるものです。
普通のニューラルネットワークは、入力層と出力層の中間にある層(=中間層)に、全結合層(=入力に重みを掛けて全部足す層)しか持たないのに対し、このCNNには畳み込み層とプーリング層という層が存在します。

普通のニューラルネットワーク

畳み込みニューラルネットワーク
画像引用:
https://atmarkit.itmedia.co.jp/ait/articles/1811/20/news012.html
https://atmarkit.itmedia.co.jp/ait/articles/1901/06/news032.html
その名の通り、畳み込み層では入力されたデータに対し畳み込み演算の処理を施します。プーリング層も同様にプーリング演算を行います。
それらの処理が完了した後、最後に全結合層を通り出力が帰ってきます。
大雑把な説明ですが、畳み込み層では画像空間をぼかすとともに、特徴を得ることができます。 特徴を得るのに適したn×nの2次元配列のフィルタを用意して、2次元配列として表された画素データとの積を取ります。すると、画像からフィルタに応じた特徴が抽出できます。CNNではこのフィルタの値を最適化することが学習の目標の一つになってきます。
プーリング層は画像空間上の位置のずれを軽減する役割を持ちます。 あるn×nの範囲の画素の平均値や最大値を取る演算をします。例えば最大値でプーリングするなら、最大値を持つ画素が数ピクセルずれていたとしても、プーリング層を通すことで同じ特徴として拾うことができます。
人間は視界上の物体の輪郭や位置のずれを自然に認識できますが、機械はそうではありません。機械にも画像データを認識できるよう作られた、人間の認識プロセスに近いモデルがCNNというわけです。
3-2. LeNet-5とは
LeNet-5は1998年にヤン・ルカン(Yann LeCun)という研究者らが発表した最初期の畳み込みニューラルネットワークのことです。
先ほどの畳み込み層の考えは自体は1989年ごろにあったようですが、それが初めて実用化されたのがこのLeNet-5というモデルです。
これを用いて彼らは手書き文字認識をしました。
結果はエラー率1%、リジェクト率9%というもので、当時の他のすべてのモデルより優れた結果を出しました。たちまちLeNet-5は一気に注目の的となりました。
(参考: https://ja.wikipedia.org/wiki/LeNet)
このモデルは
畳み込み、プーリング、活性化関数を1単位とした畳み込み層が連なった後、最後に全結合層を通すというものです。
畳み込み層は特徴検出、全結合層は分類器の役割があります。
今回は畳み込み層を2回通した後、全結合層を3回通るモデルを作ってみようと思います。
4. 実行環境
-
Kaggle Kernel
-
Python 3.6.5
-
numpy 1.19.5
-
pandas 1.1.5
-
matplotlib 3.3.4
-
scikit-learn 0.24.2
-
torch 1.10.0
5. コード紹介
おおまかなコードは先ほど紹介したNotebookからの引用です。適宜コメントを挟んでいきます。
notebookc1493f48d8
5-1. データサイズの確認
sample = pd.read_csv(r"/kaggle/input/digit-recognizer/sample_submission.csv",dtype = np.int32)
train = pd.read_csv(r"/kaggle/input/digit-recognizer/train.csv",dtype = np.float32)
test = pd.read_csv(r"/kaggle/input/digit-recognizer/test.csv",dtype = np.float32)
#pandasで使用する画像データ(csv形式)を読み込む
print(train.shape)
train.head()
出力結果:
(42000, 785)
| label | pixel0 | pixel1 | pixel2 | ... | pixel783 | |
|---|---|---|---|---|---|---|
| 0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | |
| 2 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | |
| 3 | 4.0 | 0.0 | 0.0 | 0.0 | 0.0 | |
| 4 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 |
訓練データとして正解ラベル + 28×28(=784)[pixel]の画像データを1次元にしたものが42000個分あるようです。
コードは省略しますが、テストデータの大きさは(28000,784)でした。こちらには正解ラベルがありません。完成したモデルにテストデータを突っ込むことでラベルを予測するのが目標です。
5-2. データの確認
import matplotlib.pyplot as plt
%matplotlib inline
X_train = (train.iloc[:,1:].values).astype('float32') # 2列目は画素値
y_train = train.iloc[:,0].values.astype('int32') # 1列目はラベルデータ
X_test = test.values.astype('float32')
#訓練データと教師データを分割. pandasのilocはインデックス番号で分割を指定できる.
# 28 × 28 の行列に画像を変換
X_train = X_train.reshape(X_train.shape[0], 28, 28)
plt.figure(figsize=(10,10))
for i in range(0, 9):
plt.subplot(330 + (i+1))
plt.imshow(X_train[i], cmap=plt.get_cmap('gray'))
plt.title(y_train[i], size=21, color="white");

これが今回の予測対象の手書き文字たちです。サイズ28×28、チャンネル数は1のモノクロ画像です。数字は0から9まであり、それぞれを「0」から「9」の10個のクラスに分類します。
ちなみにこのデータはMNISTデータセットというもので、画像分野で学習や評価用に広く使われている有名なデータです。
5-3. 学習データの準備
# Import Libraries
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
import pandas as pd
from sklearn.model_selection import train_test_split
# train と validation に分割
train_image, validation_image, train_label, validation_label = train_test_split(X_train, y_train, test_size = 0.2, random_state = 42)
# ndarray形式からTensor形式へ変換
train_image = torch.from_numpy(train_image)
validation_image = torch.from_numpy(validation_image)
train_label = torch.from_numpy(train_label).type(torch.LongTensor)
validation_label = torch.from_numpy(validation_label).type(torch.LongTensor)
ここでは訓練データを学習用と評価用に分けています。
注意点として、Pytorchではモデルに突っ込むデータ型として、numpy配列ではなくTensor型を使用する必要があります。
と言っても怖がる必要はまったくなく、中身はほとんどnumpy配列と同じです。違いはGPUを使用して演算ができるということです。
5-4. ミニバッチ学習の準備
# バッチサイズとエポック数の定義
batch_size = 100
num_epochs = 30
# データローダにデータを読み込ませる
train = torch.utils.data.TensorDataset(train_image,train_label)
validation = torch.utils.data.TensorDataset(validation_image,validation_label)
train_loader = DataLoader(train, batch_size = batch_size, shuffle = False)
validation_loader = DataLoader(validation, batch_size = batch_size, shuffle = False)
ここでは先ほど作ったTensor配列をDataLoaderに格納しています。
ディープラーニングではミニバッチ学習というものを行います。これは学習時に学習データを分割して使用する方法で、学習を進めやすくしたり、過学習を抑制する効果があります。対するのがバッチ学習です。こちらは学習時にすべてのデータを利用します。
batch_sizeはミニバッチ学習に使用するデータ数の単位です。データをバッチサイズ分、順番に使用していって、最終的に全データを使い切ったときの単位を1エポックといいます。
今回はnum_epochs分エポックを回していきます。
DataLoaderはPytorchに搭載されているデータ型です。これはバッチサイズを指定するとそれに対応したデータ分割・保持を行ってくれるもので、ミニバッチ学習を行う際にはこれを使うと楽です。
5-5. モデルの準備
# モデルの作成
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
#特徴量検出
nn.Conv2d(1, 6, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.ReLU(inplace=True),
nn.Conv2d(6, 16, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.ReLU(inplace=True),
#分類
nn.Flatten(), #全結合を行うため二次元データを一次元にする
nn.Linear(16*7*7, 120),
nn.ReLU(inplace=True),
nn.Linear(120,84),
nn.ReLU(inplace=True),
nn.Linear(84, 10),
nn.Softmax(dim=1)
)
def forward(self, x):
return self.layers(x)
NKNSH.MASAKIさんが作成した普通のニューラルネットワークモデル「LogisticRegressionModelクラス」に代わり、LeNetチックな畳み込みニューラルネットワーク「CNNクラス」を作成しました。(前者のコードはリンク先を参照してください。)
torch.nnというクラスを継承してモデルを記述するクラスを設定することで、Pytorchでのモデルの定義ができます。
torch.nnにはモデル作成に必要な層を定義したメソッドがたくさんあり、それらを使ってクラスを構成します。
今回のCNNクラスの構成は
特徴抽出部として
畳み込み(nn.conv2d) -> プーリング(nn.MaxPool2d) -> ReLu関数(nn.ReLU)
を二回通した後、分類器として
全結合(nn.Linear) ->ReLu関数(nn.ReLU)
を二回通し、最後に
全結合(nn.Linear) ->ソフトマックス関数(nn.Softmax)
を通らせるというものです。
__init__で層を定義し、forwardでデータが伝わる流れ(=順伝播)を記述することが最低限クラスに必要な機能です。
記法として、今回のように一連の層をnn.Sequentialにまとめて書いていくものを採用するとforwardで一気に流れを指定できるので楽です。
しかし、層ごとの出力を細かく見たい場合などには、一つ一つの層をちゃんとクラス変数に格納し、forwardで細かく流れを明示することもできます。
5-6. GPU使用の準備とモデルのインスタンス作成
#モデルの読み込み
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = CNN().to(device)
CNNインスタンス「model」を作成します。この後の計算を早くするため、modelをGPUに送ります。
torch.device('cuda')でGPU使用を指定できますが、その際にtorch.cuda.is_available()でGPUが使用可能か判別するようにしています。もし使えないならばCPUが使用されます。
5-7. 損失関数、オプティマイザの定義
# 損失関数の定義(cross entropy)
criterion = nn.CrossEntropyLoss()
# オプティマイザの定義(今回はSGD)
learning_rate = 0.001
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
損失関数としてクロスエントロピー誤差関数を使います。
これは多クラス分類の時によく使用される誤差関数です。損失関数は学習の評価をするために必ず設定する必要がある関数で、この誤差関数の結果をもとに各パラメータが変化していきます。
オプティマイザはパラメータ最適化をどう行うかを決定します。誤差が減る方向にパラメータを動かす際に、オプティマイザで指定したアルゴリズムが適用されます。
今回使用するtorch.optim.SGDは確率的勾配降下法というアルゴリズムを指定しています。これはミニバッチ学習に適したアルゴリズムで、分割したデータそれぞれで最急降下法(=単純に下方向に降りる方法)を行います。
5-8. 学習の実行
import time
# 学習過程でロスと精度を保持するリスト
train_losses, val_losses = [], []
train_accu, val_accu = [], []
for epoch in range(num_epochs):
epoch_start_time = time.time()
# 学習用データで学習
train_loss = 0
correct=0
model.train()
for images, labels in train_loader:
# to でGPUを利用するように指定
images = images.to(device)
labels = labels.to(device)
# 勾配の初期化
optimizer.zero_grad()
# 順伝播
outputs = model(torch.unsqueeze(images, 1))
#unsqueezeは次元エラーを回避するために使用する。次元を1つ増やせる。
# ロスの計算と逆伝播
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 正答数を計算
predicted = torch.max(outputs.data, 1)[1]
correct += (predicted == labels).sum()
train_loss += loss.item()
train_losses.append(train_loss/len(train_loader))
train_accu.append(correct/len(train_loader))
# 検証用データでlossと精度の計算
val_loss = 0
correct = 0
model.eval()
with torch.no_grad():
for images, labels in validation_loader:
# to でGPUを利用するように指定
images = images.to(device)
labels = labels.to(device)
# 順伝播
outputs = model(torch.unsqueeze(images, 1))
# ロスの計算
val_loss += criterion(outputs, labels)
# 正答数を計算
predicted = torch.max(outputs.data, 1)[1]
correct += (predicted == labels).sum()
val_losses.append(val_loss / len(validation_loader))
val_accu.append(correct / len(validation_loader))
print(f"Epoch: {epoch+1}/{num_epochs}.. ",
f"Time: {time.time()-epoch_start_time:.2f}s..",
f"Training Loss: {train_losses[-1]:.3f}.. ",
f"Training Accu: {train_accu[-1]:.3f}.. ",
f"Val Loss: {val_losses[-1]:.3f}.. ",
f"Val Accu: {val_accu[-1]:.3f}")
Epoch: 1/30.. Time: 1.59s.. Training Loss: 2.059.. Training Accu: 43.000.. Val Loss: 1.921.. Val Accu: 55.000
Epoch: 2/30.. Time: 1.09s.. Training Loss: 1.912.. Training Accu: 55.000.. Val Loss: 1.889.. Val Accu: 57.000
...
Epoch: 30/30.. Time: 1.07s.. Training Loss: 1.857.. Training Accu: 59.000.. Val Loss: 1.847.. Val Accu: 60.000
このコードではモデルの学習をしています。大まかには、
1.データローダーに入っているデータをモデルに入力し、データを順伝播させ出力を得る
2.出力と正解データから誤差を計算
3.誤差をモデルに伝え、パラメーターを最適化する(誤差逆伝播法)
この流れを設定したエポック分回しています。また、1エポックごとに経過時間、誤差、精度を表示しています。
データローダーに入っているデータはGPUに送っています。学習過程は機械学習で一番実行時間を要する部分ですが、GPUで計算することでその時間を短縮することができます。
CPUでこのコードを実行すると1エポックごとに10~11秒かかっていたのですが、今回の出力表示を見るとTimeはどれも1秒台になっています。単純計算で実行時間が10分の1になっており、GPUの有効性がわかります。
5-9. 結果の可視化
# loss と accuracy の可視化
plt.figure(figsize=(12,12))
plt.subplot(2,1,1)
ax = plt.gca()
ax.set_xlim([0, epoch + 2])
plt.ylabel('Loss')
plt.plot(range(1, epoch + 2), train_losses[:epoch+1], 'r', label='Training Loss')
plt.plot(range(1, epoch + 2), val_losses[:epoch+1], 'b', label='Validation Loss')
ax.grid(linestyle='-.')
plt.legend()
plt.subplot(2,1,2)
ax = plt.gca()
ax.set_xlim([0, epoch+2])
plt.ylabel('Accuracy')
plt.plot(range(1, epoch + 2), train_accu[:epoch+1], 'r', label='Training Accuracy')
plt.plot(range(1, epoch + 2), val_accu[:epoch+1], 'b', label='Validation Accuracy')
ax.grid(linestyle='-.')
plt.legend()
plt.show()
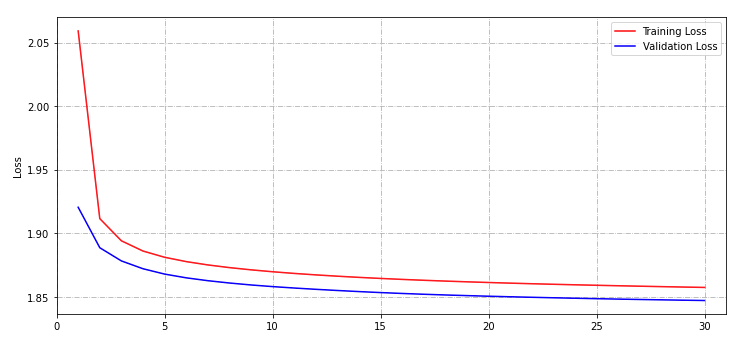

誤差の減少と正解率の向上の様子をグラフに出力しています。
見たところ訓練誤差(赤線)が汎化誤差(青線)より小さすぎるということはなく、過学習には陥ってないようですが、正解率が6割程度と低いです。
5-10. 結果の出力
# テストデータを使って回答を作る
X_test = X_test.reshape(X_test.shape[0], 28, 28)
X_test = torch.from_numpy(X_test).to(device)
model.eval()
output = model(torch.unsqueeze(X_test, 1))
output = output.to('cpu')
prediction = torch.argmax(output, 1)
modelにテストデータを入れることで、予測結果predictionを得ます。
このときGPUからCPUにデータを戻す必要があります。
予測結果をcsvに出力し、Kaggleにsubmitしました。Kaggle側の正解データを参照に、あちらで勝手に正解率を算出してくれます。
結果は、0.59778でした。
ちなみにCNN実装前の普通のニューラルネットワークの正解率は0.74628でした。
6. 改善していない・・・!?
CNNを実装したのに精度が下がってしまいました。
調べてみると、モデルの各層にバッチ正規化という処理を挟むことで、学習が安定するようになるようです。
6-1. バッチ正規化
ミニバッチ学習は、ミニバッチごとにデータの分布が異なっています。層を通ることで分布はさらに広がりを増します。
これが学習に悪影響をもたらしているようで、分布を正規化し揃えることで汎化性能の向上を狙えるようです。これがバッチ正規化です。
モデルを定義するCNNクラスを以下のように改変しました。
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.layers = nn.Sequential(
#特徴量検出
nn.Conv2d(1, 6, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.BatchNorm2d(6), #バッチ正規化
nn.ReLU(inplace=True),
nn.Conv2d(6, 16, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True),
#分類
nn.Flatten(),
nn.Linear(16*7*7, 120),
nn.BatchNorm1d(120), #1次元に注意
nn.ReLU(inplace=True),
nn.Linear(120,84),
nn.BatchNorm1d(84),
nn.ReLU(inplace=True),
nn.Linear(84, 10),
nn.BatchNorm1d(10),
nn.Softmax(dim=1)
)
def forward(self, x):
return self.layers(x)
各層にバッチ正規化処理を増やしました。
このモデルを使って結果を予測していきます。コードは先ほど紹介したものと同じものを流用しました。
6-2. 結果


誤差はバッチ正規化実装前よりも0.2程度下がり、精度は90%を超えています。
結果を出力してKaggleにsubmitすると、0.96232という結果が得られました。
7. おわりに
今回はLeNetチックなCNNモデルを作り、手書き文字の認識をやってみました。
私はまだPytorchの使用に慣れておらず、画像認識も未経験であるため、もし間違ったことを書いていたら指摘していただけると助かります。
また、Qiitaの記事を書くのも初めてでした。読みやすい文章を意識してはいましたが、わかりにくいうえに文章がやたら長くなってしまいました。ここまで読んでいただいた方、本当にありがとうございます。