はじめに
OSS-DB Silverの学習のために、Windowsパソコン上に環境構築をしています。
ここまで、以下の作業を進めてきました。
1.WindowsPCにLinux環境(仮想環境/CentOS7)を構築
「OSS-DB Silverのための環境構築 #1_VirtualBox/VagrantでLinux環境(CentOS7 仮想環境)をつくる」
2.CentOS7上にPostgreSQLを操作するユーザーアカウントを作成
「OSS-DB Silverのための環境構築 #2_事前準備1-CentOS7上にPostgreSQLを操作するユーザーアカウントを作成」
今回は、その次の作業に進みます。
3.「ソースコードからPostgreSQLをインストールするために必要なソフトウェアパッケージ6つをインストールする」
教科書該当箇所=『OSS教科書 OSS-DB Silver Ver2.0対応(緑本)』) 3章-インストール「事前準備(p48)」
作業
教科書 3章「インストール」の最初のページ(p48) にこうありました。
//3-1-1事前準備// ソースコードからPostgreSQLをインストールするには、次のソフトウェアパッケージが必要です。事前にインストールしておいてください。
● GNU make (3.8以降)
● ISO/ANSI C コンパイラ (最近のgccを推奨)
● readline
● zlib
● Flex (2.5.31 以降)
● Bison (1.875 以降)
何のことやら?です。
「OSS-DB + (上記各ソフトウェア名)」でググっても、それぞれの説明を書いたような初心者向けの記事はヒットしませんでした。また、OSS-DBの公式ページ内の「OSS-DB道場-第1回 PostgreSQLのインストール」でも、解説されていませんでした。
「PostgreSQL 8.2.6文書 - 第 14章インストール手順 - 14.2. 必要条件」に概要が書かれていたのでこちらを参考にしつつ、ひとつひとつどんな機能のソフトなのか調べつつ、インストールしていきます。
① GNU make (3.8以降)
GNU makeはよくgmakeという名前でインストールされます。
GNU makeの試験を行うためには以下を実行してください。
gmake --version
バージョン3.76.1以降を使用することを推奨します。
書籍『GNU Make 第3版』のAmazon詳細欄にこうありました。「makeは、Unixのプログラム開発や各種ソフトウェアのインストールに必須の基本ツールです。」
Unixとは?:OS。(参考:「3分間で人に説明できるようになるUnixとLinuxの違い」)
なるほど。どう必須なのでしょうか?具体的な役割は何なのでしょうか?また、GNUとは何なのでしょうか?
GNUとは?:フリーソフトウェアのみでUNIX風のOSと関連するソフトウェア群を開発・公開するプロジェクトの名前。 (参考:「GNUとは」)
makeの役割:いろいろな作業を自動化してくれる。自動化する作業のプラットフォームとしてmakeを活用することができる。 (参考:「自動化のためのGNU Make入門講座」)
GNU makeとは?:作業を自動化するためのツール。makeを利用するには、①メイクファイルに作業内容を書く、②コマンドラインからmakeを実行、という2つの手順を踏む。 (参考:「自動化のためのGNU Make入門講座」)
インストール方法: (参考:「「make: command not found」エラー」)
参考記事のとおり入力したところ、
$ sudo yum -y install make
下記のように表示されました。(入力箇所=6行目)
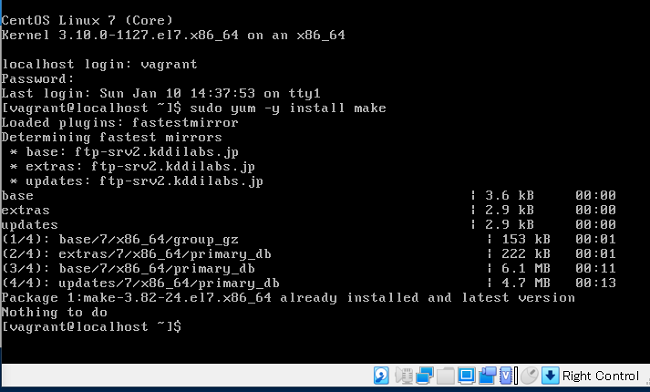
インストールできたようです。
19行目に「make-3.82」とあります。
たった1行のコマンドで、ちゃんと最新版がインストールされました。どんなコマンドを使えば良いかがわかりさえすれば、簡単に実行できるのですね!
この「適切なコマンドを見つける」作業が、今の私にはすごく時間がかかるので、数をこなして早く見つけるコツを掴みたいです。
② ISO/ANSI C コンパイラ (最近のgccを推奨)
ドキュメント-14.2. 必要条件 の文言:
GCC の最近のバージョンをお勧めしますが、PostgreSQLは異なるベンダの、様々なコンパイラでも構築できることで知られています。
ISO/ANSI C コンパイラ を分解:
ISO=国際標準化機構。
ANSI=「American National Standards Institute」の略。米国規格協会。アンシー。米国における工業規格の標準化を行う機関。
C=C言語。
コンパイラ=人間語→機械語の翻訳をしてくれるプログラム。
gccとは?:
GNU Compiler Collectionの略。
GCCはGNUプロジェクトが開発・公開しているコンパイラ。
ISO/ANSI C コンパイラとは?:
ドンピシャでこの言葉を説明する記事は見当たらなかった。上記で調べた内容をふまえると
ISO/ANSI規格のC言語コンパイラってことかな?
インストール方法: (参考:「LinuxでC言語 - コンパイラ(gcc)のインストール」)
記事のとおり、下記のyumコマンドを実行しました。
# yum install gcc
実行すると、ダーッとコマンドが動いて、最後の行にはこう表示されました。
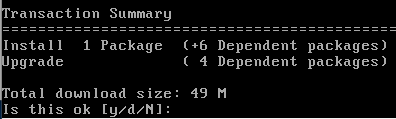
完了で良いのかな?参考記事にはこのインストールの直後に「gccでコンパイル」をしていましたが、今回は「ISO/ANSI C コンパイラのインストール」が目的だったので、gccでコンパイルはせずにこのまま次へ進みます。
③ readline
(単純なな行編集とコマンド履歴取得のための)GNU Readlineライブラリは、デフォルトで使用されます。 使用したくない場合は、configureに--without-readlineオプションを指定する必要があります 代わりに、BSDライセンスのlibeditライブラリを使用することもできます。 このライブラリは元々NetBSDで開発されていました。 libeditライブラリはGNUのReadlineと互換性があり、libreadlineを認識できなかった場合やconfigureのオプションに--with-libedit-preferredが使用された場合に使用されます。 パッケージベースのLinuxディストリビューションを使用し、そのディストリビューションの中でreadlineとreadline-develパッケージが別個に存在していた場合、両方とも必要ですので注意してください。
readlineとは?:コマンドラインの 編集機能を提供するライブラリ。ラインエディタ(1行単位でテキストを編集するためのプログラム)の一種。・・・プログラミング初学者の私にとってわかりやすい説明は発見できなかったのだけれど、どうも入力済みのコマンドを後から修正しやすくするためのソフトらしい。
ライブラリとは?:コードの図書館ってことかな。これまでも色々調べる中でよく目にする言葉だったけれど、どのように使って、何ができるのか、現段階ではよくわからない。インストールして使ってみて、わかるようになっていこう。
汎用性の高い複数のプログラムを再利用可能な形でひとまとまりにしたものである。ライブラリと呼ぶときは、それ単体ではプログラムとして動作させることはできない、つまり実行ファイルではない場合がある。ライブラリは他のプログラムに何らかの機能を提供するコードの集まりと言える。(引用:Wikipedia)
インストール方法: (参考:「CentOS7にPostgreSQL9系をインストールする方法」)
ISO/ANSI Cコンパイラインストール後の状態から、Enterを押すと、おなじみの「root@localhost ~]#」という表示が出たので、そこに続けて参考記事のコマンドを打っていきます。参考記事では「zlib」も同時にインストールするコマンドが提示されていたので、同時にインストールします。
# yum -y install readline-devel zlib-devel
黒い画面のコマンドが動き、最終行に下記のコマンドが表示されました。
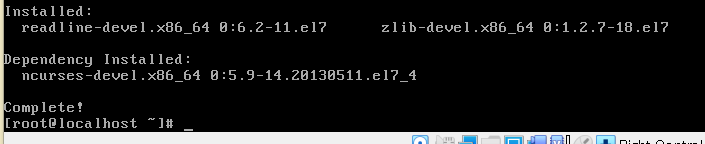
完了です!
④ zlib
zlib圧縮ライブラリはデフォルトで使用されます。 これを使用したくなければ、configure時に--without-zlibを指定しなければなりません。 このオプションを使用すると、pg_dumpおよびpg_restore内の圧縮アーカイブサポートが無効になります。
zlibとは?:データの圧縮および伸張を行うためのフリーのライブラリ
インストール方法: 上記「readline」参照。readlineと同時にインストールした。
⑤ Flex (2.5.31 以降)
GNUのFlexおよびBisonは、CVSチェックアウトから構築する場合や、実際のスキャナとパーサの定義ファイルを変更した場合に必要となります。 それらが必要な場合は、Flex 2.5.4以降とBison 1.875以降を使うようにしてください。 他のyaccプログラムを使用することも可能ですが、この場合、追加の作業が必要となりますのでお勧めできません。 他のlexプログラムでは確実に問題が起こります。
↑この文、今の私にはチンプンカンプン。
Flexとは?:Flexとは何者なのか、まず調べてみます。が、調べはじめると、Adobe Flexとか、Flex開発とか色々と出てきて、今から扱う「Flex」がいったい何者なのかがわかりません。「Flex PostgreSQL」等でググるとインストール方法についての記事は出てくるのですが、Flexで何ができるのか、Flexが何者であるかの解説は見当たりませんでした。今の私は検索能力が全く足りません…。プログラミングの基礎が足りていなさ過ぎますね。ここはとりあえずインストールして、次に進みます。
インストール方法: (参考:「[pkgs.org-flex-2.5.37-6.el7.x86_64.rpm] (https://centos.pkgs.org/7/centos-x86_64/flex-2.5.37-6.el7.x86_64.rpm.html)」)
上記参考記事の「Install Howto」に沿って下記のコマンド(#以降のみ)を入力。
Install flex rpm package:
# yum install flex
黒い画面のコマンドが動き、最終行に下記のコマンドが表示されました。
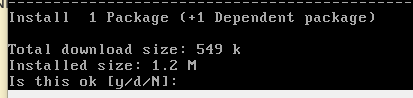
完了!ということで良いのかな?次へ進みます。
⑥ Bison (1.875 以降)
(Flexと同)
構文解析器を生成するパーサジェネレータの一種であり、CコンパイラとしてのGCCのサポートのために開発されたフリーソフトウェアである。(引用:「Wikipedia」)
構文解析器:構文解析を行う機構のこと
構文解析:
分解したトークン列をもとに構文木を構築する工程。
人間が理解しやすい高級言語で記述されたプログラムを、ハードウェア寄りの低級言語(機械語もしくは中間言語)に変換する際、その変換のプロセスは、大きく分けて次の四つの機構から成る。その2つ目がこの「構文解析」。
1.字句解析(Lexical Analysis)
ソースコードを読み込んで、トークン(字句)に分解する工程
2.構文解析(Syntactic Analysis)
分解したトークン列をもとに構文木を構築する工程
3.最適化(Optimization)
構築した構文木を効率の良いものに変換する工程
4.コード生成(Code Generation)
構文木からオブジェクトコードを生成する工程
(引用:「パーサコンビネータで構文解析をより身近なものにする」)
→正直、今は理解できない。人間語から機械語に変換する際の工程のひとつなのね、というところだけおさえておこう。
パーサジェネレータ: 構文解析器を生成するプログラム。
(参考:「パーサコンビネータで構文解析をより身近なものにする」)
インストール方法: (参考:「pkgs-org / bison-3.0.4-2.el7.x86_64.rpm」)
上記参考記事の「Install Howto」に沿って下記のコマンド(#以降のみ)を入力。
Install bison rpm package:
# yum install bison
黒い画面のコマンドが動き、最終行に下記のコマンドが表示されました。
完了!ということで良いのかな?
これで6つ全てインストール完了です!
(● tarおよびgzipかbzip2のどちらか)
教科書には記載ありませんでしたが、ドキュメントに下記の通り記載されていたのでここにメモしておきます。
まず配布物を展開するために、tarおよびgzipかbzip2のどちらかが必要です。
→こう書かれていましたが、今回の一連のインストールは情報量が多くて頭の中が整理できていないので、とりあえず今は教科書に書かれているもののみをインストールします。この「tarおよびgzipかbzip」については、今はインストールしません。
(● ディスク空き容量の確認)
教科書には記載ありませんでしたが、ドキュメントに下記の通り記載されていたのでここにメモしておきます。
十分なディスク領域があることも確認してください。 コンパイル中、ソースツリーのために65メガバイト、インストールディレクトリに15メガバイトほど必要となります。 空のデータベースクラスタだけでも約25メガバイト必要であり、またデータベースは、同じデータのフラットテキストファイルと比べて5倍ほどの領域が必要になります。 リグレッションテストを実行する場合は、一時的に最大で90メガバイトの領域がさらに必要になります。 ディスクの空き容量を確認するためにはdfコマンドを使います。
→dfコマンド使ってみました。
参考:「dfコマンドについてまとめました【Linuxコマンド集】」- エンジニアの入り口 2016.10.04
下記コマンドを入力。
(ユーザーを変更する。#(rootユーザー) → $(一般ユーザー/ユーザー名=vagrant))
# su vagrant
(Enterを押す。ユーザー変更完了。)
$ df
(Enterを押す。下記の通り表示される。)
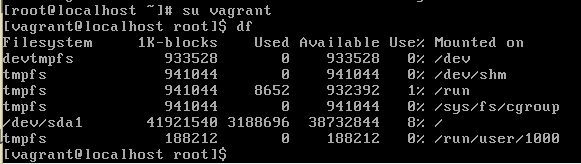
ディスク容量に関する情報が表示されました。
読み解いてみます。
| Filesystem | 1K-blocks | Used | Available | Use% | Mounted on |
|---|---|---|---|---|---|
| どのディスクか(※1) | 全ディスク容量 | 使用容量 | 空き容量 | 使用率 | (※2) |
※1=Linuxはディスク装置のことをファイルシステムと表現する。
※2=Linuxのシステムのどこにファイルシステムが認識されているかを示すマウントポイントを指している
ドキュメントには色々書いてあったけれど、
一時的に最大で90メガバイトの領域がさらに必要
とあるから、90メガバイトあれば十分なのかな?
Available(空き容量)の欄を見ればよいのかな。単位がありません。上記参考記事に、単位と一緒に表示できるコマンドが紹介されていました。-Hオプションというようです。一般的に使用されているSI単位と呼ばれる「k」「M」「G」の単位を使って表示できます。下記の通り実行します。
(-Hオプション(--siオプション):単位を付けて表示する)
$ df -H
結果はこちら。
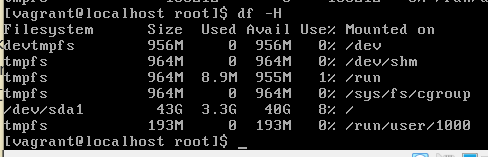
表示がAvailになったけど、Availableのことだよね。
どのディスクのことを見れば良いのかがわからないけれど、とりあえず表示されている6つのディスク、全て90メガ以上ある!ので、OKでしょう。
未解決事項
・Flexの役割。何者?何するためのソフトなの?
おわりに
・これでソースコードからPostgreSQLをインストールするために必要なソフトウェアパッケージ6つを、インストールすることができました。
・これまで書いてきたQiita記事(OSS-DB Silverのための環境構築#1,#2,#3)の内容は、教科書ではp48の1ページのみに書かれていました。周辺知識が無さ過ぎて、この1ページを完了させるのにかなり時間がかかってしまいました。この先が思いやられます・・・。
・作業時間は合計7時間40分+α。(1/9土~1/19火 作業時間ゼロの日も含め11日) 今回も、その時間のほとんどが、ググる時間でした。
・今回も、ググって各項目を調べる最中、調べれば調べるほどわからないことが増えていきました。今の目的(=PotgreSQLインストールのための準備)達成のために必要無さそうなことについては、調べるのはホドホドにしておかないと、目的の達成がどんどん遠のいていきます。今調べても理解が難しいことが多いので、今必要無さそうなことは潔く「わからない」「あいまい」なまま浮かせて、次に進むようにしなくては。「あいまい」なこととは、また出会うでしょう!
・やっと事前準備が完了しました。次回はいよいよ「ソースコードからPostgreSQLをインストール」します!
参考
・書籍:『OSS教科書 OSS-DB Silver Ver2.0対応』
・ドキュメント:PostgreSQL 8.2.6文書