はじめに
OpenAIのAPIは非常に便利ですよね。多くの会社で活用されており、開発現場でも広く使用されていると思います。しかし、その中で問題になるのが、誰がどれくらいトークンを使用したかを把握することです。これが見えないため、個別のアカウントを持っている場合は分かりますが、共通の方法でトークン数を管理したいというニーズもあるでしょう。
そこで、今回はOpenAIのAPIをラップしてトークン数を測定する方法を模索しました。単純にAPIをラップして途中でトークン数を測定すれば、この課題を解決できるのではないかと考えましたので、コードを実装してみました。
やりたいこと(図)
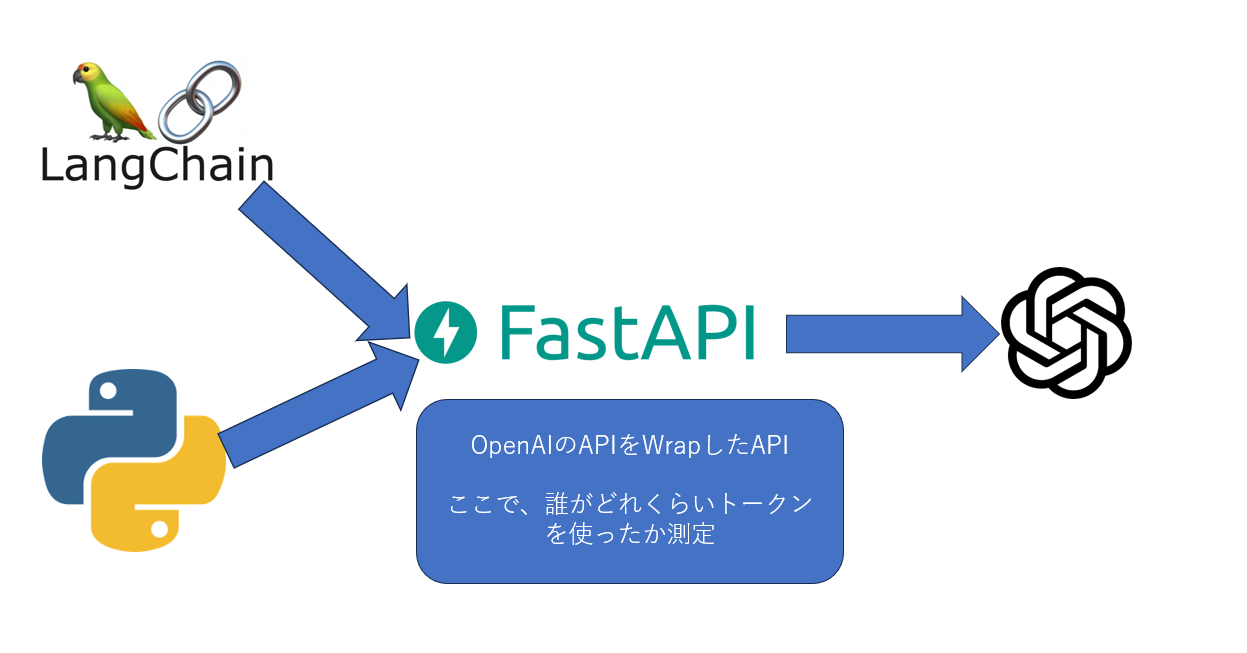
一旦はこんなイメージ
今回はチャットの基本機能だけWrapします。Embeddingなどほしい方は、それぞれ欲しい機能のパスを追加してリレーして上げる必要があります。
どのようにユーザーを識別するか
ユーザーの識別はFastAPI側で払い出したAPIキーをもとに測定をする想定です。
※ただし、今回はいろんな認証方法があったりするので、認証はデモでtestというキーをユーザーから受けそれを認証とする事にします。
OpenAIのAPIをWrapする
以下に、OpenAIのWrap元があります。
こちらをそのままリクエストをリレーするようにします。ただし、Streamingなどはちょっとコツが要るので後述します。
まずは以下のパッケージをダウンロードします。
fastapi
uvicorn
python-dotenv
パスと機能を作成
まずは、元と同じように/chat/completionsというパスをPOSTメソッドで受け付けるようにします。
@app.post("/chat/completions")
次にAPI認証を噛ませ、認証OKであればリクエストをそのままリレーし、Requestsで送信します。
async def relay_openai_request(request: Request):
# クライアントからのリクエストの認証ヘッダーを取得
client_auth_header = request.headers.get("Authorization")
if client_auth_header != "Bearer test":
# 認証ヘッダーが一致しない場合、エラーを返す
raise HTTPException(status_code=401, detail="Unauthorized")
# JSONデータを取得
data = await request.json()
# OpenAIへのリクエストを中継
response = requests.post(f"{OPENAI_URL}/chat/completions", json=data, headers=headers, stream=stream)
上記で一旦OPENAIのAPIに中継する事ができます。今度はResponseを加工してopenaiのライブラリなどでも使える形で変換します。
# 通常のJSONレスポンスを返す
response_data = response.json()
total_tokens = response_data.get("usage", {}).get("total_tokens")
if total_tokens is not None:
print(f"使用したトークン数: {total_tokens}")
else:
print("トークン数情報が見つかりません")
return response_data
こちらで、標準的なレスポンスの実装は完了です。
上記のprintの部分で使用したトークン数などを見ることができます。
StreamがTrueであればストリーミングで返すようにする
stream = data.get("stream", False)
こちらが記載されていればレスポンスをストリーミングで返すようにする必要があります。
ただしこちらの場合は、ストリーミングなので通常レスポンスのように返せませんので、FastAPIのStreamingResponseを使ってストリーミングで返す実装をします。
# ストリーミングオプションが有効の場合、ストリーミングレスポンスを返す
if stream:
total_tokens_limit = int(response.headers.get("x-ratelimit-limit-tokens", 0))
total_tokens_remaining = int(response.headers.get("x-ratelimit-remaining-tokens", 0))
used_tokens = total_tokens_limit - total_tokens_remaining
if used_tokens > 0:
print(f"使用したトークン数: {used_tokens}")
else:
print("トークン数情報が見つかりません")
# print(response.headers)
def generate():
for chunk in response.iter_content(chunk_size=8192):
yield chunk.decode('utf-8')
# ストリーミングとしてテキストを返す
return StreamingResponse(generate(), media_type="text/event-stream")
ストリーミングの場合、残念なことに標準レスポンスのときのようなtotal_tokensは拾ってこれませんので、使える合計のトークンと、残りのトークンを減算することで出しています。
ヘッダーx-ratelimit-limit-tokens(合計トークン数)
x-ratelimit-remaining-tokens(残りトークン数)
また、注意点としてはStreamingResponseを返す際は、text/event-streamで返す必要があります。こちらで返さない場合、Pythonのopenaiのライブラリ側でエラーが発生します。
最終的に完成したAPIコード
from fastapi import FastAPI, HTTPException, Request
from fastapi.responses import StreamingResponse
import requests
import os
from dotenv import load_dotenv
# .envファイルから環境変数を読み込む
load_dotenv()
app = FastAPI(
title="PrivateGPT",
description="ただのWrapper",
version="0.0.1"
)
# OpenAIのエンドポイントとAPIキーの定義
OPENAI_URL = "https://api.openai.com/v1"
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
# リクエストのヘッダーを定義
headers = {
"Authorization": f"Bearer {OPENAI_API_KEY}",
"Content-Type": "application/json",
"User-Agent": "OpenAI FastAPI Wrapper"
}
@app.post("/chat/completions")
async def relay_openai_request(request: Request):
# クライアントからのリクエストの認証ヘッダーを取得
client_auth_header = request.headers.get("Authorization")
if client_auth_header != "Bearer test":
# 認証ヘッダーが一致しない場合、エラーを返す
raise HTTPException(status_code=401, detail="Unauthorized")
# JSONデータを取得
data = await request.json()
# ストリーミングオプションが設定されているか確認
stream = data.get("stream", False)
# OpenAIへのリクエストを中継
response = requests.post(f"{OPENAI_URL}/chat/completions", json=data, headers=headers, stream=stream)
# レスポンスのステータスコードを確認
if response.status_code != 200:
raise HTTPException(status_code=response.status_code, detail=response.text)
# ストリーミングオプションが有効の場合、ストリーミングレスポンスを返す
if stream:
"""
レスポンスヘッダーから使用したトークン数を取得するには、
ヘッダーx-ratelimit-limit-tokens(合計トークン数)と
x-ratelimit-remaining-tokens(残りトークン数)を使用して計算することができます。
"""
total_tokens_limit = int(response.headers.get("x-ratelimit-limit-tokens", 0))
total_tokens_remaining = int(response.headers.get("x-ratelimit-remaining-tokens", 0))
used_tokens = total_tokens_limit - total_tokens_remaining
if used_tokens > 0:
print(f"使用したトークン数: {used_tokens}")
else:
print("トークン数情報が見つかりません")
# print(response.headers)
def generate():
for chunk in response.iter_content(chunk_size=8192):
yield chunk.decode('utf-8')
# ストリーミングとしてテキストを返す
return StreamingResponse(generate(), media_type="text/event-stream")
# 通常のJSONレスポンスを返す
response_data = response.json()
total_tokens = response_data.get("usage", {}).get("total_tokens")
if total_tokens is not None:
print(f"使用したトークン数: {total_tokens}")
else:
print("トークン数情報が見つかりません")
return response_data
if __name__ == "__main__":
# FastAPIのアプリを実行
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
テスト
API側のWrapperが完成したのでテストします。
openaiのライブラリの中にあるChatCompletionクラスを使ってテストします。
標準レスポンステスト
import openai
openai.api_base = "http://127.0.0.1:8080"
openai.api_key = "test"
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role":"system","content":"作文を300文字で作って"}],
temperature=0.5,
)
response = completion.choices[0].message['content']
print(response)
結果
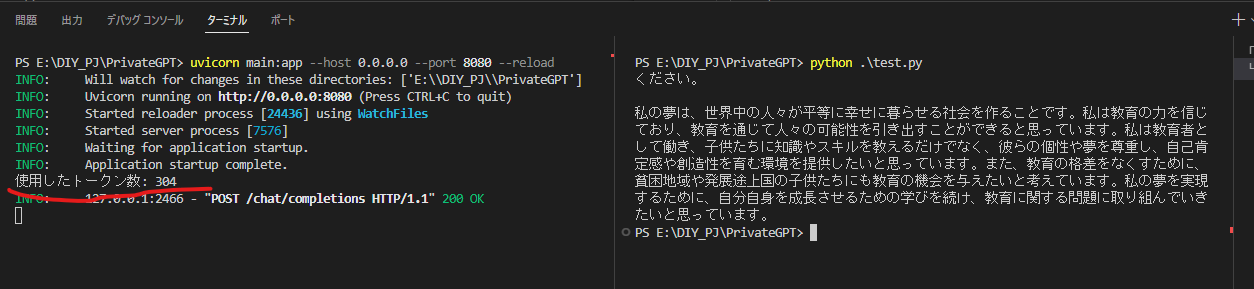
ストリーミングテスト
import os
import openai
from openai import util
import json
openai.api_base = "http://127.0.0.1:8080"
openai.api_key = "test"
# チャンクごとの応答を生成します
for chunk in openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{
"role": "user",
"content": "作文を300文字で作って"
}
],
temperature=0,
stream=True
):
content = chunk["choices"][0].get("delta", {}).get("content")
if content is not None:
print(content, end='', flush=True) # flush=Trueを追加
結果

ん~~なんかトークン数少ないような・・・
ストリーミングだと正確なトークン数が拾ってこれないようです。なのでStreamが来た際はエラーで返してやる必要があるかもしれません。