前回の記事で書いた異常検知モデル自動作成プラットフォーム「ADFI」が、実際のところ、どのくらい使い物になるのか、性能を検証してみました!
ADFIについては、前回の記事を参照ください。
ADFIの画面:
実験設定
データセット
検証実験には、非常に有名な異常検知の画像データセットであるMVTecを使いました。
異常検知関連の論文の検証実験で頻繁に使われるデータセットで、15種類のカテゴリのサブデータセットが含まれています。
今回は、その全15種類のサブデータセット(以降、単純に「データセット」と表記)に対して、ADFIで深層距離学習(DML)モデルを自動作成して性能を検証しました。
データセット画像例:

データ数
データセットによって正常画像と異常画像の数がバラバラで条件が異なってしまうため、各データセットとも下記表の通りにしました。
(Training画像はデータセットの中からランダムに抽出。Test画像は、Training画像で使用していない画像の中からランダムに抽出。)
| 項目 | データ数 |
|---|---|
| Training 正常画像 | 50 |
| Training 異常画像 | 10 |
| Test 正常画像 | 20 |
| Test 異常画像 | 20 |
検証項目
各データセットに対して下記項目を測定しました。
-
学習時間
モデルの学習にかかった時間 -
テスト時間
テストを実行してから全テストデータ(40画像分)の結果が出るまでの時間 -
AUC(Area Under the Curve)
異常検知で良く使われる評価指標。
ROC(Receiver Operating Characteristic)曲線の下部分に該当する面積。
AUCが1に近いほど性能が高いモデル。(完全にランダムに予測される場合、AUCは0.5となる。)
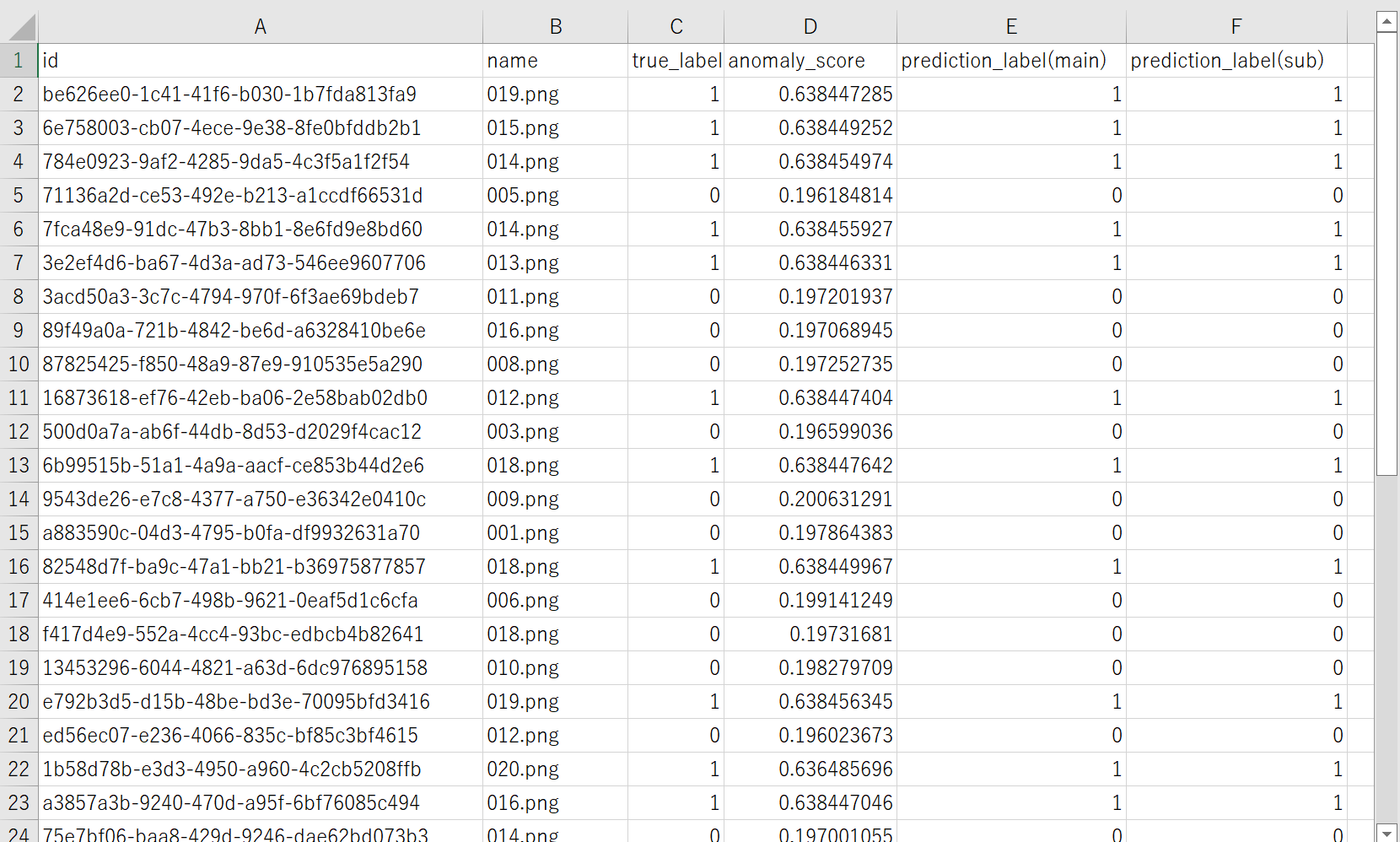
各テストデータのスコア結果のCSVをダウンロードしてAUCを算出。
AUCの算出方法
スコア結果のCSVをダウンロードして、「true_label」列と「anomaly_score」列の値を下記Pythonコードに入れて、JupyterNotebookなどで実行してください。AUCを算出してくれます。
ダウンロードしたCSV:
# ROC AUCの算出
from sklearn import metrics
import matplotlib.pyplot as plt
import numpy as np
# 「true_label」列と「anomaly_score」列の値をリストにセットする
y_true = np.array([<true_label>])
y_score = np.array([<anomaly_score>])
fpr, tpr, thresholds = metrics.roc_curve(y_true, y_score)
auc = metrics.auc(fpr, tpr)
plt.plot(fpr, tpr, label='ROC curve (AUC = %.3f)'%auc)
plt.legend()
plt.xlabel('FPR: False positive rate')
plt.ylabel('TPR: True positive rate')
plt.grid()
plt.show()
実験結果
全てのデータセットに対して、ADFIで深層距離学習(DML)モデルを作成した結果は下記表になりました。
| データセット | 学習時間 | テスト時間 | AUC |
|---|---|---|---|
| Bottle | 11分11秒 | 4秒 | 1.000 |
| Cable | 10分44秒 | 3秒 | 0.875 |
| Capsule | 11分1秒 | 4秒 | 0.948 |
| Carpet | 10分58秒 | 4秒 | 0.930 |
| Grid | 11分50秒 | 3秒 | 0.935 |
| Hazelnut | 10分49秒 | 5秒 | 1.000 |
| Leather | 10分55秒 | 3秒 | 1.000 |
| Metal Nut | 10分37秒 | 4秒 | 1.000 |
| Pill | 11分12秒 | 4秒 | 0.917 |
| Screw | 11分3秒 | 4秒 | 0.782 |
| Tile | 10分50秒 | 3秒 | 0.965 |
| Toothbrush | 11分43秒 | 4秒 | 0.923 |
| Transistor | 11分9秒 | 3秒 | 0.930 |
| Wood | 10分51秒 | 3秒 | 1.000 |
| Zipper | 10分48秒 | 3秒 | 0.995 |
学習時間の平均は約11分。
テスト時間の平均は約4秒。
AUCの平均は0.947。
CableとScrew以外のデータセットではAUCが0.9を超える非常に良い結果となりました。
深層距離学習の各手法との性能比較
ADFIを使わずに深層距離学習の各手法で作成したモデルとAUC値を比較しました。
MVTecに対する深層距離学習の各手法のAUC値を調べてみたところ、すでにdaisukelabさんが実験されていたので、勝手に引用させていただきました。ありがとうございます!
(ぜひ、daisukelabさんの深層距離学習についての素晴らしい記事もご覧ください。)
MVTecデータセットでの各手法のAUC値:
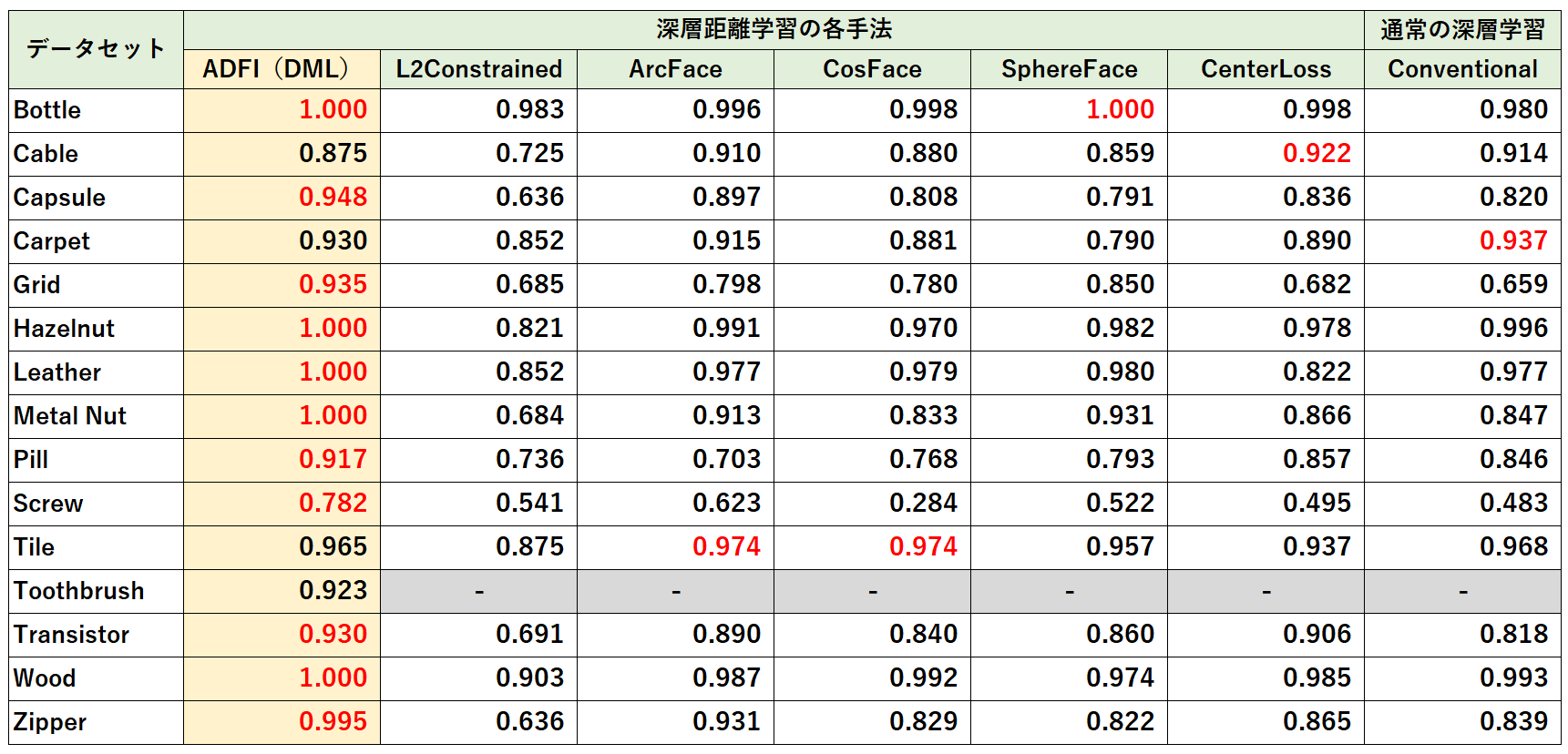
実験設定が異なるため単純に優劣はつけられませんが、AUC値としてはADFIが多くのデータセットで最高を記録しました。
この結果を見ると、やはり、システムエンジニアの自分としては、深層距離学習のプログラムを自分でゴリゴリ開発するより、ADFIを使った方が素早く高性能な異常検知モデルが作れそうです。
所感
MVTecデータセットを使ってADFIの性能を検証してみて、ADFIの威力を痛感!
「わずか10分ちょっとの時間で、深層距離学習のプログラムを自分で開発するより高性能な異常検知モデルが作れる」ということに、ある意味ショックを受けました。
とは言え、便利なものは、どんどん活用していきたいと思います!
ADFIについては前回の記事もご参照ください。
関連する記事