まえがき
実現したいことが別にあり、その過程でいろいろ調べて発見した参考文献をもとに作成した。
2-1-9 数値を2進数、16進数に変換
10進数と2進数の変換・1回目
環境
builder_query
ファンクションにしたほうが便利そうなので、ファンクションをダイナミックに生成できるようにビルダークエリを作成。生成されたファンクションを実行。
with digit as(
select level as rn from dual connect by level <= 32
),template as (
select 'to_char(sign(bitand(i_dec,power(2, @-1))))' as tobe_replace from dual
),exec_replace as(
select s1.rn,s2.tobe_replace,replace(s2.tobe_replace,'@',s1.rn) as done_replace from digit s1,template s2
),header as(
select 'CREATE OR REPLACE FUNCTION DEC2BIN( i_dec IN NUMBER) RETURN VARCHAR2 IS o_bin VARCHAR2(32); BEGIN o_bin := ' as header from dual
),footer as(
select ' ;RETURN o_bin;END;' as footer from dual
),builder as(
select s1.rn,s1.done_replace || case when not exists(select 1 from exec_replace s2 where s1.rn>s2.rn ) then '' else '||' end as mainer from exec_replace s1
)select header||listagg(mainer)within group(order by rn desc)||footer as build_sql from header,builder,footer;
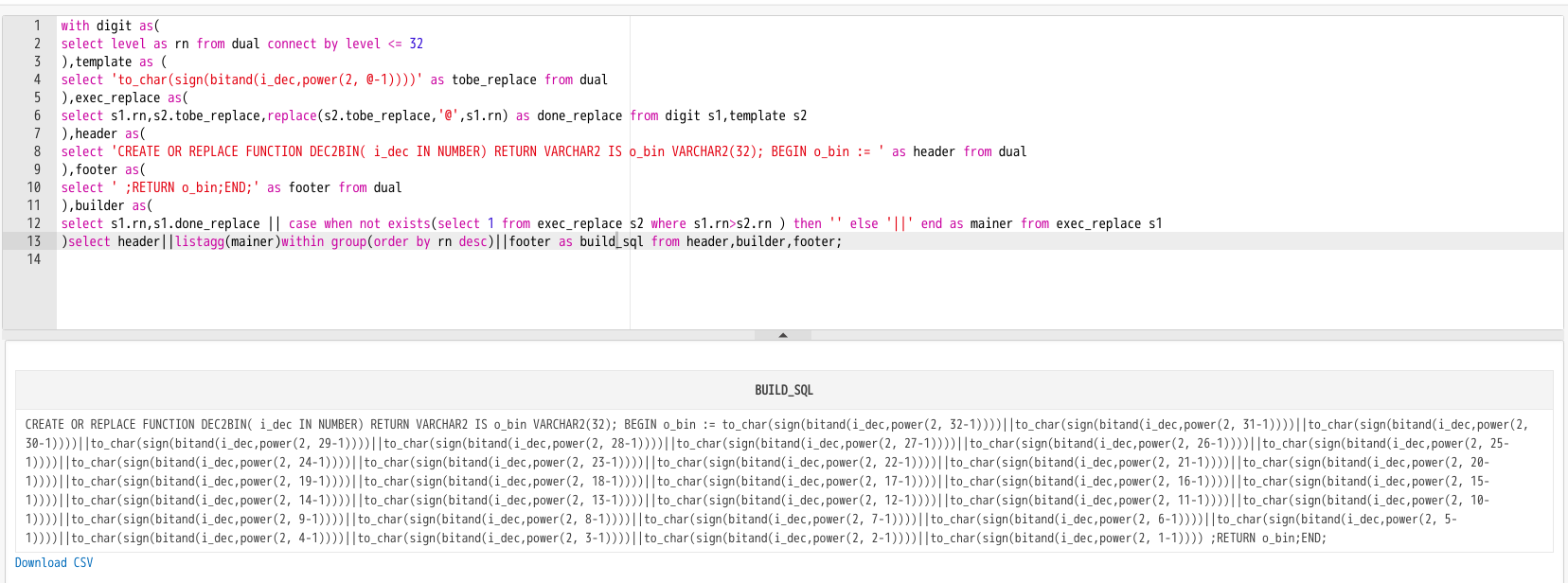
generate_query
CREATE OR REPLACE FUNCTION DEC2BIN( i_dec IN NUMBER) RETURN VARCHAR2 IS o_bin VARCHAR2(32); BEGIN o_bin := to_char(sign(bitand(i_dec,power(2, 32-1))))||to_char(sign(bitand(i_dec,power(2, 31-1))))||to_char(sign(bitand(i_dec,power(2, 30-1))))||to_char(sign(bitand(i_dec,power(2, 29-1))))||to_char(sign(bitand(i_dec,power(2, 28-1))))||to_char(sign(bitand(i_dec,power(2, 27-1))))||to_char(sign(bitand(i_dec,power(2, 26-1))))||to_char(sign(bitand(i_dec,power(2, 25-1))))||to_char(sign(bitand(i_dec,power(2, 24-1))))||to_char(sign(bitand(i_dec,power(2, 23-1))))||to_char(sign(bitand(i_dec,power(2, 22-1))))||to_char(sign(bitand(i_dec,power(2, 21-1))))||to_char(sign(bitand(i_dec,power(2, 20-1))))||to_char(sign(bitand(i_dec,power(2, 19-1))))||to_char(sign(bitand(i_dec,power(2, 18-1))))||to_char(sign(bitand(i_dec,power(2, 17-1))))||to_char(sign(bitand(i_dec,power(2, 16-1))))||to_char(sign(bitand(i_dec,power(2, 15-1))))||to_char(sign(bitand(i_dec,power(2, 14-1))))||to_char(sign(bitand(i_dec,power(2, 13-1))))||to_char(sign(bitand(i_dec,power(2, 12-1))))||to_char(sign(bitand(i_dec,power(2, 11-1))))||to_char(sign(bitand(i_dec,power(2, 10-1))))||to_char(sign(bitand(i_dec,power(2, 9-1))))||to_char(sign(bitand(i_dec,power(2, 8-1))))||to_char(sign(bitand(i_dec,power(2, 7-1))))||to_char(sign(bitand(i_dec,power(2, 6-1))))||to_char(sign(bitand(i_dec,power(2, 5-1))))||to_char(sign(bitand(i_dec,power(2, 4-1))))||to_char(sign(bitand(i_dec,power(2, 3-1))))||to_char(sign(bitand(i_dec,power(2, 2-1))))||to_char(sign(bitand(i_dec,power(2, 1-1)))) ;RETURN o_bin;END;

動作確認
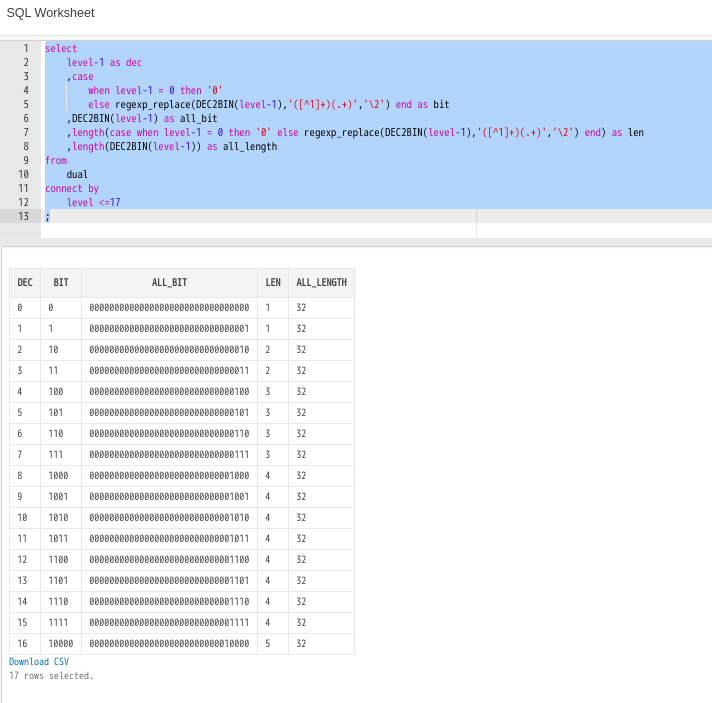
1以外の連続した文字列とそれ以外に分けて後方参照ではそれ以外のみを抜き取り。
select
level-1 as dec
,case
when level-1 = 0 then '0'
else regexp_replace(DEC2BIN(level-1),'([^1]+)(.+)','\2') end as bit
,DEC2BIN(level-1) as all_bit
,length(case when level-1 = 0 then '0' else regexp_replace(DEC2BIN(level-1),'([^1]+)(.+)','\2') end) as len
,length(DEC2BIN(level-1)) as all_length
from
dual
connect by
level <=17
;
あとがき
進数変換系はあまり得意でないけど、たのしい。😆
20191012追記
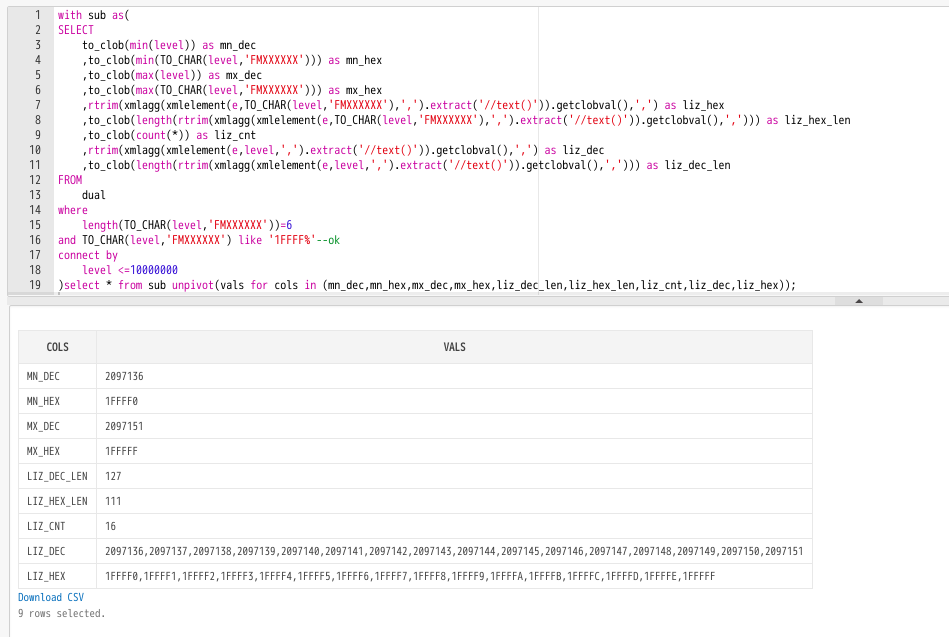
cols列には値を集約する際は、型を統一しておく必要があるので、明示的にto_clobで変換しておく。
16進数と10進数の関係これで掴めそう。unpivot便利。😆
with sub as(
SELECT
to_clob(min(level)) as mn_dec
,to_clob(min(TO_CHAR(level,'FMXXXXXX'))) as mn_hex
,to_clob(max(level)) as mx_dec
,to_clob(max(TO_CHAR(level,'FMXXXXXX'))) as mx_hex
,rtrim(xmlagg(xmlelement(e,TO_CHAR(level,'FMXXXXXX'),',').extract('//text()')).getclobval(),',') as liz_hex
,to_clob(length(rtrim(xmlagg(xmlelement(e,TO_CHAR(level,'FMXXXXXX'),',').extract('//text()')).getclobval(),','))) as liz_hex_len
,to_clob(count(*)) as liz_cnt
,rtrim(xmlagg(xmlelement(e,level,',').extract('//text()')).getclobval(),',') as liz_dec
,to_clob(length(rtrim(xmlagg(xmlelement(e,level,',').extract('//text()')).getclobval(),','))) as liz_dec_len
FROM
dual
where
length(TO_CHAR(level,'FMXXXXXX'))=6
-- and TO_CHAR(level,'FMXXXXXX') like '1%'--ORA-06502: PL/SQL: numeric or value error: character string buffer too small
-- and TO_CHAR(level,'FMXXXXXX') like '1F%'--ok
-- and TO_CHAR(level,'FMXXXXXX') like '1FF%'--ok
-- and TO_CHAR(level,'FMXXXXXX') like '1FFF%'--ok
and TO_CHAR(level,'FMXXXXXX') like '1FFFF%'--ok
-- and TO_CHAR(level,'FMXXXXXX') like '1FFFFF%'--ok
connect by
level <=10000000
)select * from sub unpivot(vals for cols in (mn_dec,mn_hex,mx_dec,mx_hex,liz_dec_len,liz_hex_len,liz_cnt,liz_dec,liz_hex));
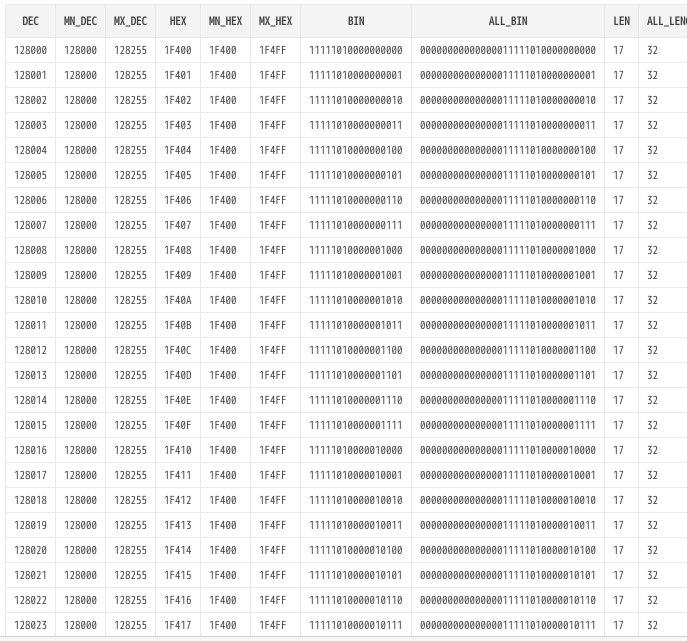
2進数,16進数,10進数の一覧作成した。なまえ、bitかbinか揺れ動く。
select
level-1 as dec
,min(level-1)over() as mn_dec
,max(level-1)over() as mx_dec
,TO_CHAR(level-1,'FMXXXXXX') as hex
,min(TO_CHAR(level-1,'FMXXXXXX'))over() as mn_hex
,max(TO_CHAR(level-1,'FMXXXXXX'))over() as mx_hex
,case
when level-1 = 0 then '0'
else regexp_replace(DEC2BIN(level-1),'([^1]+)(.+)','\2') end as bin
,DEC2BIN(level-1) as all_bin
,length(case when level-1 = 0 then '0' else regexp_replace(DEC2BIN(level-1),'([^1]+)(.+)','\2') end) as len
,length(DEC2BIN(level-1)) as all_length
from
dual
where
level > 128000
connect by
level <=128255 + 1
;
これをファンクションに落とし込む一歩手前。二歩かも。
oracleはutf32のエンコーディング方式を採用していなくて、utf16のエンコーディング方式を採用している。dump関数とconvert関数で使ってutf16にエンコード変換した後(デフォルトのエンコーディング方式はutf8だったはず。)、その結果を16進数で取得。取得した進数を2桁にゼロ埋めしたあと、サロゲートペアにしてunistr関数に食わせて絵文字を表示。
UTF-32、UTF-16、UTF-8 の相互変換
char16_tとchar32_t
std::uint8_t
CとC++の演算子
Unicode
シフト演算と割り算(python3)
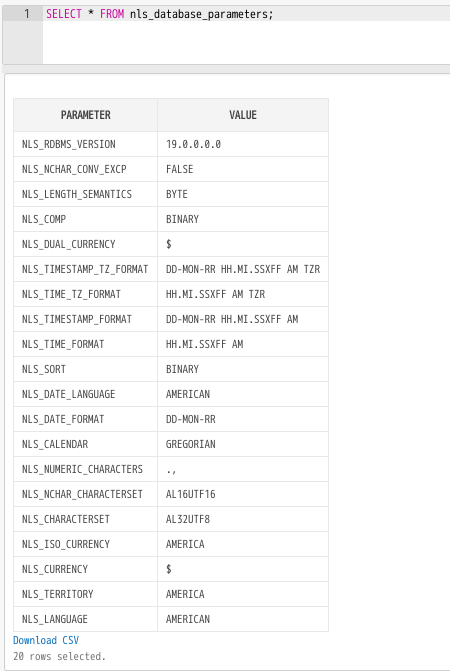
デフォルトエンコーディングの確認はこれでできる。NLS_NCHAR_CHARACTERSETとNLS_CHARACTERSET。
SELECT * FROM nls_database_parameters;
めちゃくちゃ楽しそう😆
Unicode の番号と文字を SQL で相互変換
with sub as(
select replace(regexp_substr(dump(convert('🍎','AL16UTF16'),1016),':.*'),': ','') as item from dual
),subb as(
select
level as seq
,item
,regexp_instr(item,'[^,]+',1,level) as start_rn
,nvl(lead(regexp_instr(item,'[^,]+',1,level))over(order by level),4000) as next_rn
,substr(item,regexp_instr(item,'[^,]+',1,level),nvl(lead(regexp_instr(item,'[^,]+',1,level))over(order by level),4000)-regexp_instr(item,'[^,]+',1,level)-1) as ele
,lpad(substr(item,regexp_instr(item,'[^,]+',1,level),nvl(lead(regexp_instr(item,'[^,]+',1,level))over(order by level),4000)-regexp_instr(item,'[^,]+',1,level)-1),2,0) as ele_zero_pad
,case when level in (1,2) then 1 else 2 end grp
from
sub
connect by
regexp_instr(item,'[^,]+',1,level) <> 0
),subbb as(
select
grp
,listagg(ele_zero_pad)within group (order by seq) as surrogate_pair
from
subb
group by
grp
)select
'\'||listagg(surrogate_pair,'\')within group (order by grp) as utf16_item_encode
,unistr('\'||listagg(surrogate_pair,'\')within group (order by grp)) as utf16_item_decode
from
subbb
;
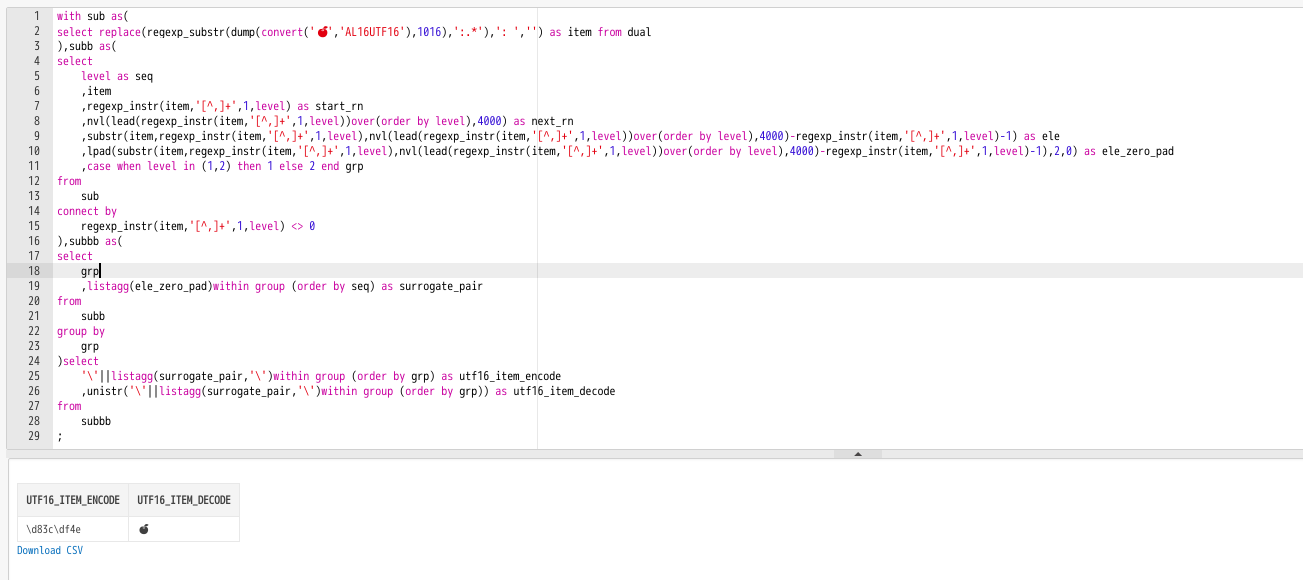
エンコーディング実装模倣しようと思ったけど、力尽きる。また次回。
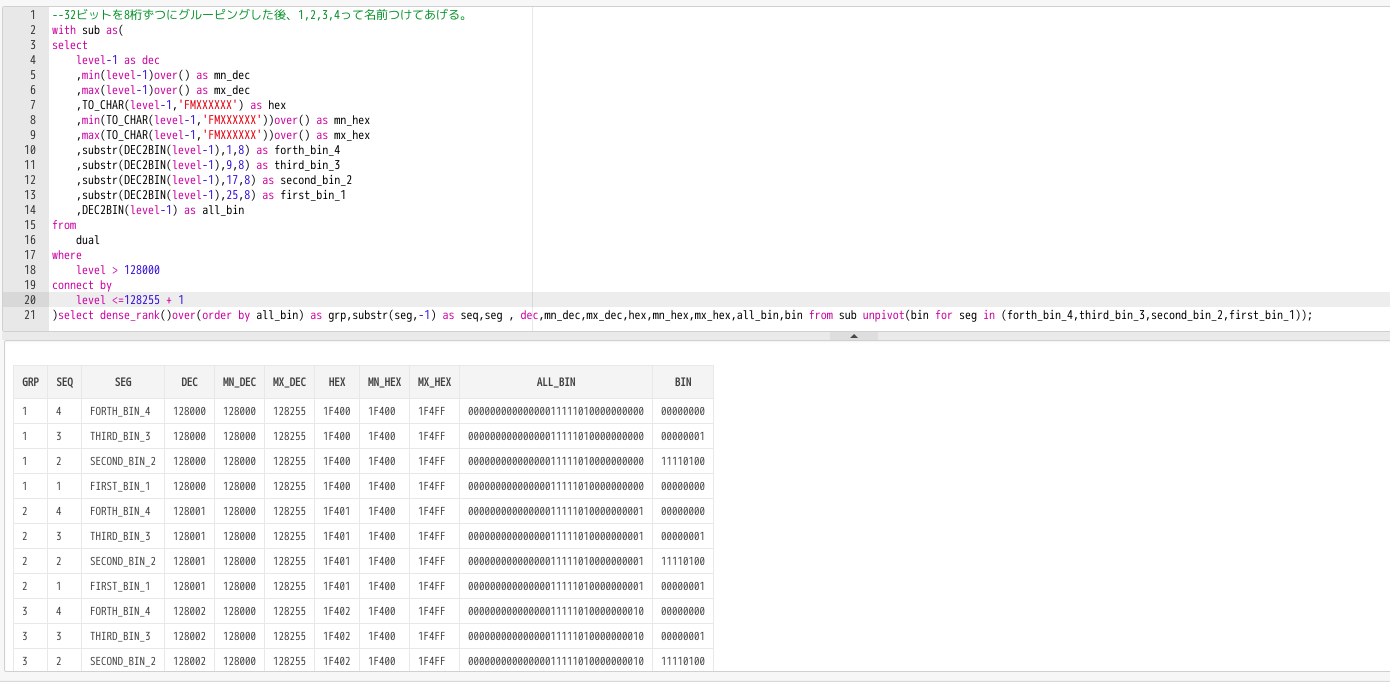
--32ビットを8桁ずつにグルーピングした後、1,2,3,4って名前つけてあげる。
with sub as(
select
level-1 as dec
,min(level-1)over() as mn_dec
,max(level-1)over() as mx_dec
,TO_CHAR(level-1,'FMXXXXXX') as hex
,min(TO_CHAR(level-1,'FMXXXXXX'))over() as mn_hex
,max(TO_CHAR(level-1,'FMXXXXXX'))over() as mx_hex
,substr(DEC2BIN(level-1),1,8) as forth_bin_4
,substr(DEC2BIN(level-1),9,8) as third_bin_3
,substr(DEC2BIN(level-1),17,8) as second_bin_2
,substr(DEC2BIN(level-1),25,8) as first_bin_1
,DEC2BIN(level-1) as all_bin
from
dual
where
level > 128000
connect by
level <=128255 + 1
)select dense_rank()over(order by all_bin) as grp,substr(seg,-1) as seq,seg , dec,mn_dec,mx_dec,hex,mn_hex,mx_hex,all_bin,bin from sub unpivot(bin for seg in (forth_bin_4,third_bin_3,second_bin_2,first_bin_1));
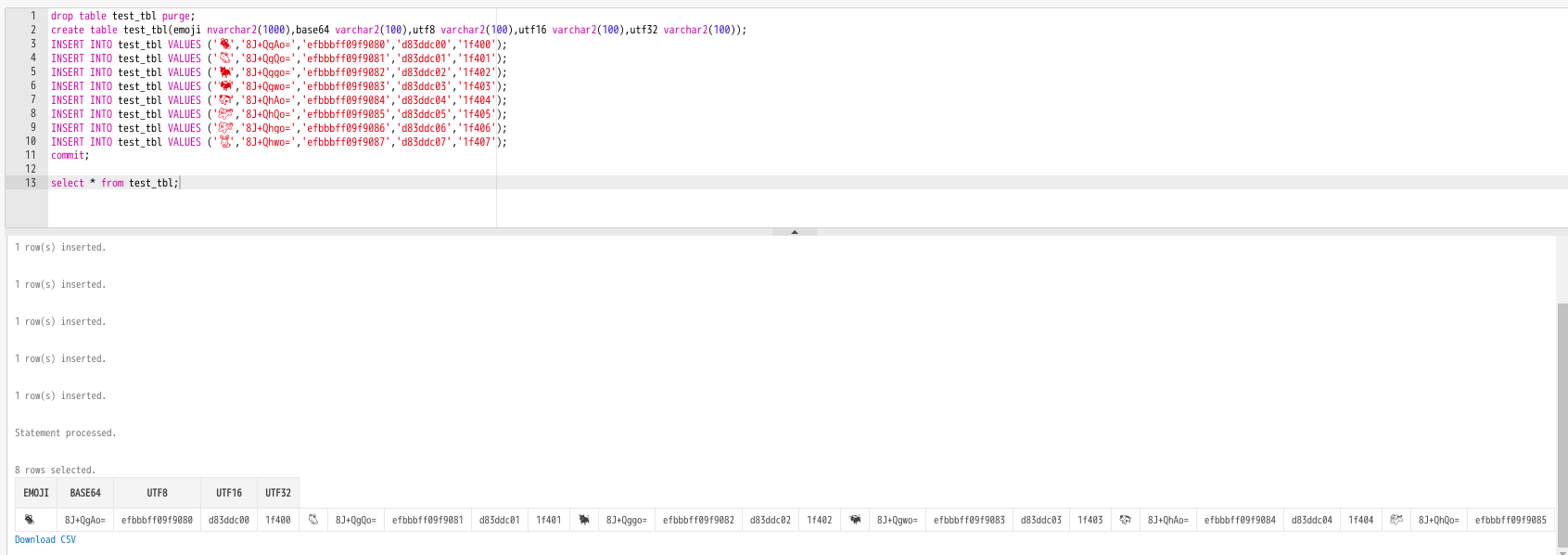
左から、絵文字、base64、utf8(ビッグエンディアンBOM指定なし)、utf16(ビッグエンディアンBOM指定なし)、utf32(ビッグエンディアンBOM指定なし)。
[aine💝centos (土 10月 12 23:30:36) ~]$echo -e '\U1f4'{{0..9},{A..F}}{{0..9},{A..F}} | tr ' ' '\n' | xargs -I@ bash -c 'paste <(echo -ne @) <(base64<<<@) <(echo -ne @ | nkf -W8 -w8B0 | xxd -ps -c48) <(echo -ne @ nkf -W8 -w16B0 | xxd -ps -c48 ) <(echo -ne @ | nkf -W8 -w32B0 | xxd -ps -c48 | sed "s;^0*;;")' | awk 'BEGIN{SQT="\x27";print "drop table test_tbl purge;\n""create table test_tbl(emoji nvarchar2(1000),base64 varchar2(100),utf8 varchar2(100),utf16 varchar2(100),utf32 varchar2(100));"}{print "INSERT INTO test_tbl VALUES ("SQT$1SQT","SQT$2SQT","SQT$3SQT","SQT$4SQT","SQT$5SQT");"}END{print "commit;"}' >a.sql
[aine💝centos (土 10月 12 23:31:31) ~]head a.sql
drop table test_tbl purge;
create table test_tbl(emoji nvarchar2(1000),base64 varchar2(100),utf8 varchar2(100),utf16 varchar2(100),utf32 varchar2(100));
INSERT INTO test_tbl VALUES ('🐀','8J+QgAo=','efbbbff09f9080','d83ddc00','1f400');
INSERT INTO test_tbl VALUES ('🐁','8J+QgQo=','efbbbff09f9081','d83ddc01','1f401');
INSERT INTO test_tbl VALUES ('🐂','8J+Qggo=','efbbbff09f9082','d83ddc02','1f402');
INSERT INTO test_tbl VALUES ('🐃','8J+Qgwo=','efbbbff09f9083','d83ddc03','1f403');
INSERT INTO test_tbl VALUES ('🐄','8J+QhAo=','efbbbff09f9084','d83ddc04','1f404');
INSERT INTO test_tbl VALUES ('🐅','8J+QhQo=','efbbbff09f9085','d83ddc05','1f405');
INSERT INTO test_tbl VALUES ('🐆','8J+Qhgo=','efbbbff09f9086','d83ddc06','1f406');
INSERT INTO test_tbl VALUES ('🐇','8J+Qhwo=','efbbbff09f9087','d83ddc07','1f407');
[aine💝centos (土 10月 12 23:31:34) ~]tail a.sql
INSERT INTO test_tbl VALUES ('📷','8J+Ttwo=','efbbbff09f93b7','d83ddcf7','1f4f7');
INSERT INTO test_tbl VALUES ('📸','8J+TuAo=','efbbbff09f93b8','d83ddcf8','1f4f8');
INSERT INTO test_tbl VALUES ('📹','8J+TuQo=','efbbbff09f93b9','d83ddcf9','1f4f9');
INSERT INTO test_tbl VALUES ('📺','8J+Tugo=','efbbbff09f93ba','d83ddcfa','1f4fa');
INSERT INTO test_tbl VALUES ('📻','8J+Tuwo=','efbbbff09f93bb','d83ddcfb','1f4fb');
INSERT INTO test_tbl VALUES ('📼','8J+TvAo=','efbbbff09f93bc','d83ddcfc','1f4fc');
INSERT INTO test_tbl VALUES ('📽','8J+TvQo=','efbbbff09f93bd','d83ddcfd','1f4fd');
INSERT INTO test_tbl VALUES ('📾','8J+Tvgo=','efbbbff09f93be','d83ddcfe','1f4fe');
INSERT INTO test_tbl VALUES ('📿','8J+Tvwo=','efbbbff09f93bf','d83ddcff','1f4ff');
commit;
レンダリングがうまくいっていないが、テーブルに格納はできている
base64のエンコーディング方式oracleとbase64コマンドとで異なる!?
with bash_command as(
SELECT
'bash_command' as tbl_name
,base64
,cast(UTL_RAW.CAST_TO_VARCHAR2(
UTL_ENCODE.BASE64_DECODE(
UTL_RAW.CAST_TO_RAW(base64)
)
) as nvarchar2(1000)) AS BASE64_dec
FROM
test_tbl
where
emoji = '📷'
),oracle_function as(
SELECT
'oracle_function' as tbl_name
,UTL_RAW.CAST_TO_VARCHAR2(
UTL_ENCODE.BASE64_ENCODE(
UTL_RAW.CAST_TO_RAW(emoji)
)
) AS BASE64_enc
,emoji
FROM
test_tbl
where
emoji = '📷'
)select * from bash_command union all
select * from oracle_function
;
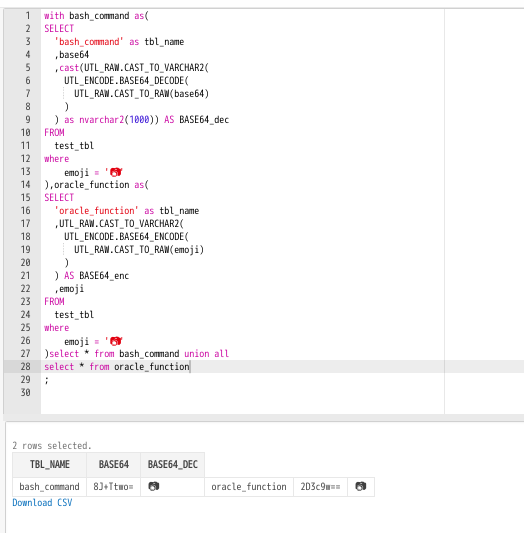
おもしろい。😆
デコードするのはこれでもいける。
select
utf16
,emoji
,utl_raw.cast_to_nvarchar2(HEXTORAW(utf16)) as utf16_dec
from
test_tbl
where
emoji = '📷'
;
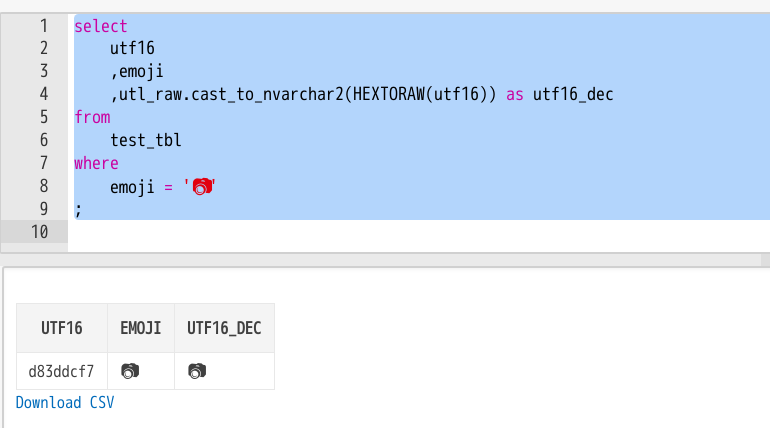
20191013追記
別名作って
with sub as(
select
case
when 4 = mod(level,4)+1 then 'forth_bin'
when 3 = mod(level,4)+1 then 'third_bin'
when 2 = mod(level,4)+1 then 'second_bin'
when 1 = mod(level,4)+1 then 'first_bin'
end as octet_name
, case
when 2=row_number()over(partition by mod(level,4)+1 order by level) then 'upper_nibble'
when 1=row_number()over(partition by mod(level,4)+1 order by level) then 'lower_nibble'
end as nibble_name
,mod(level,4)+1 as grp
, row_number()over(partition by mod(level,4)+1 order by level) as seq
from dual connect by level <= 4 * 2--octet*nibble
)select listagg(OCTET_NAME||'_'||NIBBLE_NAME||'_'||GRP||SEQ,',')within group (order by substr(OCTET_NAME||'_'||NIBBLE_NAME||'_'||GRP||SEQ,-2) desc) as als from sub
;
たのしい😆
with sub as(
select
dense_rank()over(order by level-1) as grp
,level-1 as dec
,min(level-1)over() as mn_dec
,max(level-1)over() as mx_dec
,TO_CHAR(level-1,'FMXXXXXX') as hex
,min(TO_CHAR(level-1,'FMXXXXXX'))over() as mn_hex
,max(TO_CHAR(level-1,'FMXXXXXX'))over() as mx_hex
,substr(DEC2BIN(level-1),1,8) as forth_bin_4
,substr(substr(DEC2BIN(level-1),1,8),1,4) as forth_bin_upper_nibble_42
,substr(substr(DEC2BIN(level-1),1,8),5,4) as forth_bin_lower_nibble_41
,substr(DEC2BIN(level-1),9,8) as third_bin_3
,substr(substr(DEC2BIN(level-1),9,8),1,4) as third_bin_upper_nibble_32
,substr(substr(DEC2BIN(level-1),9,8),5,4) as third_bin_lower_nibble_31
,substr(DEC2BIN(level-1),17,8) as second_bin_2
,substr(substr(DEC2BIN(level-1),17,8),1,4) as second_bin_upper_nibble_22
,substr(substr(DEC2BIN(level-1),17,8),5,4) as second_bin_lower_nibble_21
,substr(DEC2BIN(level-1),25,8) as first_bin_1
,substr(substr(DEC2BIN(level-1),25,8),1,4) as first_bin_upper_nibble_12
,substr(substr(DEC2BIN(level-1),25,8),5,4) as first_bin_lower_nibble_11
,DEC2BIN(level-1) as all_bin
from
dual
where
level > 128250
connect by
level <=128255 + 1
),subb as(
select
grp
,row_number()over(partition by grp order by substr(seg,-2) desc) as grp_seq
,substr(substr(seg,-2),1,1) as sub_grp
,substr(substr(seg,-2),2,1) as rn
,seg
,dec
,mn_dec
,mx_dec
,hex
,mn_hex
,mx_hex
,all_bin
,nibble
,bin_to_num(substr(nibble,1,1),substr(nibble,2,1),substr(nibble,3,1),substr(nibble,4,1)) as nibble_dec
,to_char(bin_to_num(substr(nibble,1,1),substr(nibble,2,1),substr(nibble,3,1),substr(nibble,4,1)),'FMXX') as nibble_hex
from sub unpivot(nibble for seg in (forth_bin_upper_nibble_42,forth_bin_lower_nibble_41,third_bin_upper_nibble_32,third_bin_lower_nibble_31,second_bin_upper_nibble_22,second_bin_lower_nibble_21,first_bin_upper_nibble_12,first_bin_lower_nibble_11))
)select
s1.*
,replace(sys_connect_by_path(nibble_hex,' '),' ','') as hex_connect
,lpad(replace(sys_connect_by_path(nibble_hex,' '),' ',''),8,'0') as hex_connect_zero_pad
,ltrim(sys_connect_by_path(nibble,','),',') as nibble_connect
,ltrim(sys_connect_by_path(nibble_hex,','),',') as nibble_hex_connect
,ltrim(sys_connect_by_path(nibble_dec,','),',') as nibble_dec_connect
from
subb s1
start with
s1.grp_seq = 1
connect by
prior s1.grp=s1.grp
and prior s1.grp_seq + 1=s1.grp_seq
;
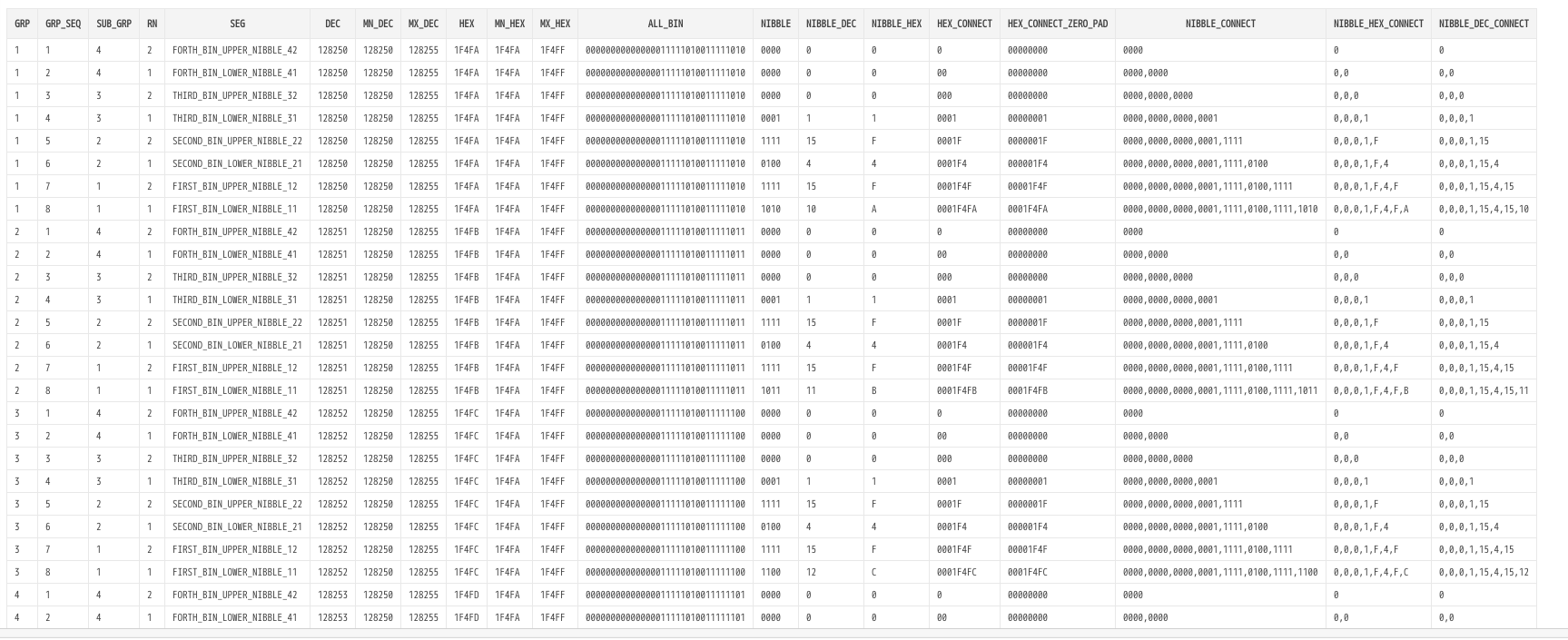
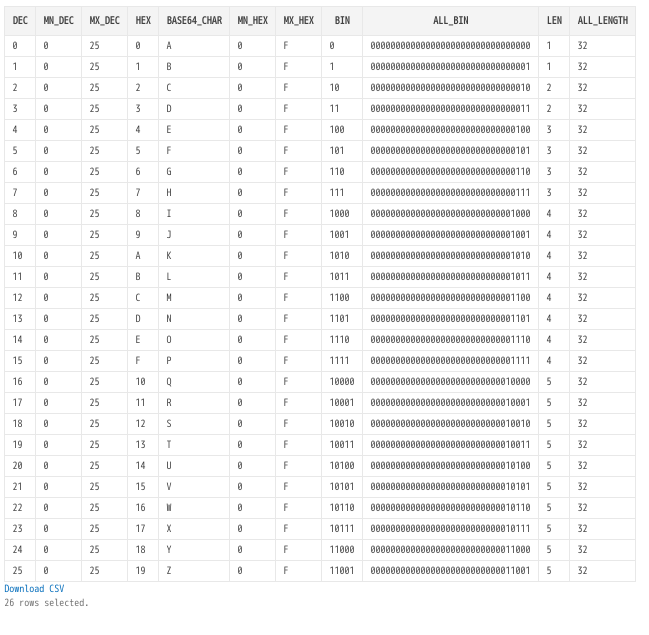
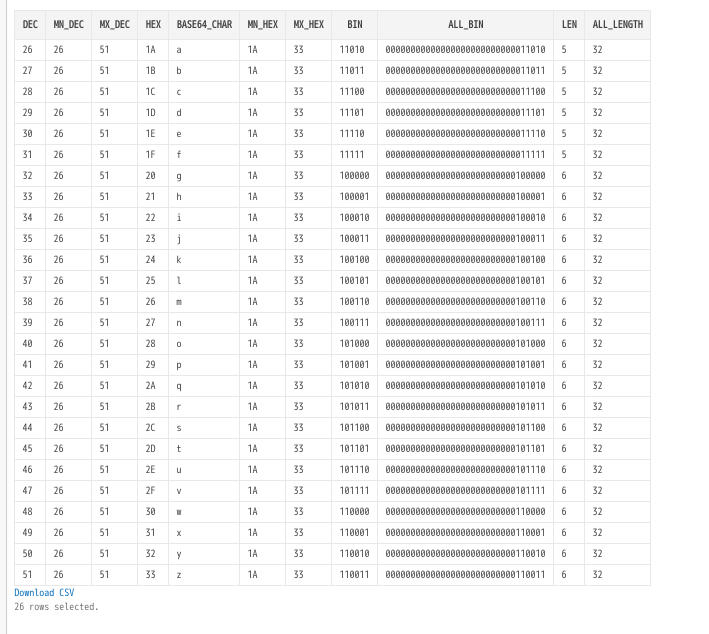
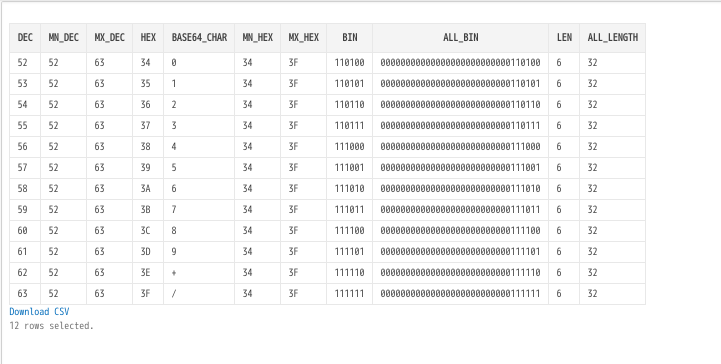
base64変換表
select
level-1 as dec
,min(level-1)over() as mn_dec
,max(level-1)over() as mx_dec
,TO_CHAR(level-1,'FMXXXXXX') as hex
,case
when level-1 between 0 and 25 then CHR(65+level-1)
when level-1 between 26 and 51 then CHR(97+level-27)
when level-1 between 52 and 61 then CHR(48+level-53)
when level-1 between 62 and 62 then CHR(43+level-63)
when level-1 between 63 and 63 then CHR(47+level-64)
end as base64_char
,min(TO_CHAR(level-1,'FMXXXXXX'))over() as mn_hex
,max(TO_CHAR(level-1,'FMXXXXXX'))over() as mx_hex
,case
when level-1 = 0 then '0'
else regexp_replace(DEC2BIN(level-1),'([^1]+)(.+)','\2') end as bin
,DEC2BIN(level-1) as all_bin
,length(case when level-1 = 0 then '0' else regexp_replace(DEC2BIN(level-1),'([^1]+)(.+)','\2') end) as len
,length(DEC2BIN(level-1)) as all_length
from
dual
where
-- level -1 between 0 and 25
-- level -1 between 26 and 51
level -1 between 52 and 63
connect by
level <=63 + 1
;
bashでも
[postgres🖤25e14fb5c939 (日 10月 13 11:56:06) /usr/local/src/gawk-5.0.0]$seq 0 63|xargs -I@ dc -e'10i@dpd2opd8opd16op'|xargs -n4|awk '{if($1>=0 && $1<=25)printf "%s %s %s %s %c\n", $1,$2,$3,$4,65+$1-0;else if($1=26 && $1<=51)printf "%s %s %s %s %c\n", $1,$2,$3,$4,97+$1-26;else if($1>=52 && $1<=61)printf "%s %s %s %s %c\n", $1,$2,$3,$4,48+$1-52;else if($1>=62 && $1<=62)printf "%s %s %s %s %c\n", $1,$2,$3,$4,43+$1-62;else if($1>=63 && $1<=63)printf "%s %s %s %s %c\n", $1,$2,$3,$4,47+$1-63;else print $1,$2,$3,$4,"---"}' | keta
0 0 0 0 A
1 1 1 1 B
2 10 2 2 C
3 11 3 3 D
4 100 4 4 E
5 101 5 5 F
6 110 6 6 G
7 111 7 7 H
8 1000 10 8 I
9 1001 11 9 J
10 1010 12 A K
11 1011 13 B L
12 1100 14 C M
13 1101 15 D N
14 1110 16 E O
15 1111 17 F P
16 10000 20 10 Q
17 10001 21 11 R
18 10010 22 12 S
19 10011 23 13 T
20 10100 24 14 U
21 10101 25 15 V
22 10110 26 16 W
23 10111 27 17 X
24 11000 30 18 Y
25 11001 31 19 Z
26 11010 32 1A a
27 11011 33 1B b
28 11100 34 1C c
29 11101 35 1D d
30 11110 36 1E e
31 11111 37 1F f
32 100000 40 20 g
33 100001 41 21 h
34 100010 42 22 i
35 100011 43 23 j
36 100100 44 24 k
37 100101 45 25 l
38 100110 46 26 m
39 100111 47 27 n
40 101000 50 28 o
41 101001 51 29 p
42 101010 52 2A q
43 101011 53 2B r
44 101100 54 2C s
45 101101 55 2D t
46 101110 56 2E u
47 101111 57 2F v
48 110000 60 30 w
49 110001 61 31 x
50 110010 62 32 y
51 110011 63 33 z
52 110100 64 34 0
53 110101 65 35 1
54 110110 66 36 2
55 110111 67 37 3
56 111000 70 38 4
57 111001 71 39 5
58 111010 72 3A 6
59 111011 73 3B 7
60 111100 74 3C 8
61 111101 75 3D 9
62 111110 76 3E +
63 111111 77 3F /
ファンクション実装してみる。
文字列sを文字数nで分割したリストを返すの部分。便利そう。
base64ってなんぞ??理解のために実装してみた
エミュ用イメージ
[postgres🖤25e14fb5c939 (日 10月 13 12:44:51) /usr/local/src/gawk-5.0.0]$python
Python 3.7.4 (default, Oct 12 2019, 21:53:21)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> def split(s, n):
... return [s[i:i+n] for i in range(0, len(s), n)]
...
>>> split("44GG44KT44GTCg==", 6)
['44GG44', 'KT44GT', 'Cg==']
parallelコマンドでも
GNU Parallel Tutorial
parallelコマンドでの実行コマンド文字列はエスケープ2つ必要。-Nは4つずつ引数処理。
本当は引数をファイルで処理したい。20は5行かける4列。
[postgres💓25e14fb5c939 (日 10月 13 15:12:03) /usr/local/src/gawk-5.0.0]$cat <<ARGS_FILE | xargs -n20
0 25 65 0
26 51 97 26
52 61 48 52
62 62 43 62
63 63 47 63
ARGS_FILE
0 25 65 0 26 51 97 26 52 61 48 52 62 62 43 62 63 63 47 63
[postgres💓25e14fb5c939 (日 10月 13 15:08:21) /usr/local/src/gawk-5.0.0]$parallel --version
GNU parallel 20190922
Copyright (C) 2007-2019 Ole Tange and Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
GNU parallel comes with no warranty.
Web site: http://www.gnu.org/software/parallel
When using programs that use GNU Parallel to process data for publication
please cite as described in 'parallel --citation'.
[postgres💓25e14fb5c939 (日 10月 13 15:13:29) /usr/local/src/gawk-5.0.0]$parallel -N4 echo "seq {1} {2} \| awk \'{printf \\\"%s %c\\\n\\\",\\\$0,{3}+\\\$0-{4}}\'" ::: 0 25 65 0 26 51 97 26 52 61 48 52 62 62 43 62 63 63 47 63 | bash
0 A
1 B
2 C
3 D
4 E
5 F
6 G
7 H
8 I
9 J
10 K
11 L
12 M
13 N
14 O
15 P
16 Q
17 R
18 S
19 T
20 U
21 V
22 W
23 X
24 Y
25 Z
26 a
27 b
28 c
29 d
30 e
31 f
32 g
33 h
34 i
35 j
36 k
37 l
38 m
39 n
40 o
41 p
42 q
43 r
44 s
45 t
46 u
47 v
48 w
49 x
50 y
51 z
52 0
53 1
54 2
55 3
56 4
57 5
58 6
59 7
60 8
61 9
62 +
63 /