まえがき
pandas面白そうと思ってデータ操作こねくり回してその過程でいろいろ調べて発見したことをまとめておこうと思う。pythonは触りたてです。
環境
[postgres❣25e14fb5c939 (月 10月 14 12:55:52) ~/script_scratch/python]$python --version
Python 3.7.4
[postgres❣25e14fb5c939 (月 10月 14 12:55:57) ~/script_scratch/python]$pip --version
pip 19.0.3 from /usr/local/lib/python3.7/site-packages/pip (python 3.7)
[postgres❣25e14fb5c939 (月 10月 14 12:43:47) ~/script_scratch/python]$python
Python 3.7.4 (default, Oct 12 2019, 21:53:21)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
前準備
**/usr/local/lib/python3.7/site-packages/**配下にインストールされるぽい。
[postgres💟25e14fb5c939 (月 10月 14 09:55:59) ~/script_scratch/python]$su root
Password:
[root♥25e14fb5c939 (月 10月 14 09:56:33) /home/postgres/script_scratch/python]$find / -name "*pandas*" 2>/dev/null
[root♥25e14fb5c939 (月 10月 14 09:56:42) /home/postgres/script_scratch/python]$pip install pandas | tee log
Collecting pandas
Downloading https://files.pythonhosted.org/packages/7e/ab/ea76361f9d3e732e114adcd801d2820d5319c23d0ac5482fa3b412db217e/pandas-0.25.1-cp37-cp37m-manylinux1_x86_64.whl (10.4MB)
Collecting numpy>=1.13.3 (from pandas)
Downloading https://files.pythonhosted.org/packages/ba/e0/46e2f0540370f2661b044647fa447fef2ecbcc8f7cdb4329ca2feb03fb23/numpy-1.17.2-cp37-cp37m-manylinux1_x86_64.whl (20.3MB)
Collecting pytz>=2017.2 (from pandas)
Downloading https://files.pythonhosted.org/packages/e7/f9/f0b53f88060247251bf481fa6ea62cd0d25bf1b11a87888e53ce5b7c8ad2/pytz-2019.3-py2.py3-none-any.whl (509kB)
Collecting python-dateutil>=2.6.1 (from pandas)
Downloading https://files.pythonhosted.org/packages/41/17/c62faccbfbd163c7f57f3844689e3a78bae1f403648a6afb1d0866d87fbb/python_dateutil-2.8.0-py2.py3-none-any.whl (226kB)
Collecting six>=1.5 (from python-dateutil>=2.6.1->pandas)
Downloading https://files.pythonhosted.org/packages/73/fb/00a976f728d0d1fecfe898238ce23f502a721c0ac0ecfedb80e0d88c64e9/six-1.12.0-py2.py3-none-any.whl
Installing collected packages: numpy, pytz, six, python-dateutil, pandas
Successfully installed numpy-1.17.2 pandas-0.25.1 python-dateutil-2.8.0 pytz-2019.3 six-1.12.0
You are using pip version 19.0.3, however version 19.2.3 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
[root♥25e14fb5c939 (月 10月 14 09:57:11) /home/postgres/script_scratch/python]$find / -name "*pandas*" 2>/dev/null
/usr/local/lib/python3.7/site-packages/pandas-0.25.1.dist-info
/usr/local/lib/python3.7/site-packages/pandas
/usr/local/lib/python3.7/site-packages/pandas/tests/io/json/test_pandas.py
/usr/local/lib/python3.7/site-packages/pandas/tests/io/json/__pycache__/test_pandas.cpython-37.pyc
ライブラリインポート
>>> import pandas as pd
>>> import random as rd
>>> import datetime as dt
データ準備
>>> df = pd.DataFrame({"item":[c for _ in range(5) for c in ["apple", "banana","orange"]],"rank":[chr(i%7+65) for i in range(15)],"date":pd.date_range(dt.date.today(),periods=15,freq='2D'),"price":pd.Series(rd.randint(100,500) for i in range(15)),"ASCII_CODE_DEC":[i+33 for i in range(15)],"ASCII_CODE_BIN":[bin(i+33) for i in range(15)],"ASCII_CODE_HEX":[hex(i+33) for i in range(15)],"ASCII_CHR":[chr(i+33) for i in range(15)]})
>>> df
item rank date price ASCII_CODE_DEC ASCII_CODE_BIN ASCII_CODE_HEX ASCII_CHR
0 apple A 2019-10-14 476 33 0b100001 0x21 !
1 banana B 2019-10-16 377 34 0b100010 0x22 "
2 orange C 2019-10-18 495 35 0b100011 0x23 #
3 apple D 2019-10-20 365 36 0b100100 0x24 $
4 banana E 2019-10-22 270 37 0b100101 0x25 %
5 orange F 2019-10-24 229 38 0b100110 0x26 &
6 apple G 2019-10-26 162 39 0b100111 0x27 '
7 banana A 2019-10-28 416 40 0b101000 0x28 (
8 orange B 2019-10-30 491 41 0b101001 0x29 )
9 apple C 2019-11-01 352 42 0b101010 0x2a *
10 banana D 2019-11-03 214 43 0b101011 0x2b +
11 orange E 2019-11-05 338 44 0b101100 0x2c ,
12 apple F 2019-11-07 114 45 0b101101 0x2d -
13 banana G 2019-11-09 115 46 0b101110 0x2e .
14 orange A 2019-11-11 186 47 0b101111 0x2f /
集計・集約単位列が単一列の場合
単一列に集計・集約関数を単一適用(listagg除く)
>>> df.groupby("item")[['rank']].apply(max)
rank
item
apple G
banana G
orange F
型確認
>>> type(df.groupby("item")[['rank']].apply(max))
<class 'pandas.core.frame.DataFrame'>
単一列に集計・集約関数を単一適用(listagg含む)
>>> df.groupby("item")["rank"].apply(list)
item
apple [A, D, G, C, F]
banana [B, E, A, D, G]
orange [C, F, B, E, A]
Name: rank, dtype: object
型確認
>>> type(df.groupby("item")["rank"].apply(list))
<class 'pandas.core.series.Series'>
変数代入
>>> rank_liz=df.groupby("item")["rank"].apply(list)
型確認
>>> type(rank_liz)
<class 'pandas.core.series.Series'>
中身確認
>>> rank_liz
item
apple [A, D, G, C, F]
banana [B, E, A, D, G]
orange [C, F, B, E, A]
Name: rank, dtype: object
シリーズ型をリスト型に変換
をやろうと思ったけど、
リスト型をデータフレーム型に変換
をやろうと思ったけど、
agg関数の引数に集計・集約関数を単一適用
でできた。
>>> df.groupby("item")[['rank']].agg([list])
rank
list
item
apple [A, D, G, C, F]
banana [B, E, A, D, G]
orange [C, F, B, E, A]
型確認
>>> type(df.groupby("item")[['rank']].agg([list]))
<class 'pandas.core.frame.DataFrame'>
単一列に集計・集約関数を複数適用(listagg除く)
>>> df.groupby("item")[['price']].agg([min,max,sum])
price
min max sum
item
apple 114 476 1469
banana 115 416 1392
orange 186 495 1739
型確認
>>> type(df.groupby("item")[['price']].agg([min,max,sum]))
<class 'pandas.core.frame.DataFrame'>
単一列に集計・集約関数を複数適用(listagg含む)
>>> df.groupby("item")[['price']].agg([min,max,sum,list])
price
min max sum list
item
apple 114 476 1469 [476, 365, 162, 352, 114]
banana 115 416 1392 [377, 270, 416, 214, 115]
orange 186 495 1739 [495, 229, 491, 338, 186]
型確認
>>> type(df.groupby("item")[['price']].agg([min,max,sum,list]))
<class 'pandas.core.frame.DataFrame'>
複数列に集計・集約関数を単一適用(listagg除く)
>>>> df.groupby("item")[['rank','date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].apply(max)
rank date price ASCII_CODE_DEC ASCII_CODE_BIN ASCII_CODE_HEX ASCII_CHR
item
apple G 2019-11-07 476 45 0b101101 0x2d -
banana G 2019-11-09 416 46 0b101110 0x2e .
orange F 2019-11-11 495 47 0b101111 0x2f /
型確認
>>> type(df.groupby("item")[['rank','date']].apply(max))
<class 'pandas.core.frame.DataFrame'>
複数列に集計・集約関数を単一適用(listagg含む)
>>> df.groupby("item")[['rank','date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].apply(list)
item
apple [rank, date, price, ASCII_CODE_DEC, ASCII_CODE...
banana [rank, date, price, ASCII_CODE_DEC, ASCII_CODE...
orange [rank, date, price, ASCII_CODE_DEC, ASCII_CODE...
dtype: object
型確認
>>> type(df.groupby("item")[['rank','date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].apply(list))
<class 'pandas.core.series.Series'>
シリーズ型をリスト型に変換
をやろうと思ったけど、
リスト型をデータフレーム型に変換
をやろうと思ったけど、
agg関数の引数に集計・集約関数を単一適用
でできた。
>>> df.groupby("item")[['rank','date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].agg([list])
rank date price ... ASCII_CODE_BIN ASCII_CODE_HEX ASCII_CHR
list list list ... list list list
item ...
apple [A, D, G, C, F] [2019-10-14 00:00:00, 2019-10-20 00:00:00, 201... [476, 365, 162, 352, 114] ... [0b100001, 0b100100, 0b100111, 0b101010, 0b101... [0x21, 0x24, 0x27, 0x2a, 0x2d] [!, $, ', *, -]
banana [B, E, A, D, G] [2019-10-16 00:00:00, 2019-10-22 00:00:00, 201... [377, 270, 416, 214, 115] ... [0b100010, 0b100101, 0b101000, 0b101011, 0b101... [0x22, 0x25, 0x28, 0x2b, 0x2e] [", %, (, +, .]
orange [C, F, B, E, A] [2019-10-18 00:00:00, 2019-10-24 00:00:00, 201... [495, 229, 491, 338, 186] ... [0b100011, 0b100110, 0b101001, 0b101100, 0b101... [0x23, 0x26, 0x29, 0x2c, 0x2f] [#, &, ), ,, /]
[3 rows x 7 columns]
型確認
>>> type(df.groupby("item")[['rank','date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].agg([list]))
<class 'pandas.core.frame.DataFrame'>
複数列に集計・集約関数を複数適用(listagg除く)
sumが面白い。
>>> df.groupby("item")[['rank','date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].agg([min,max,sum])
rank price ASCII_CODE_DEC ASCII_CODE_BIN ASCII_CODE_HEX ASCII_CHR
min max sum min max sum min max sum min max sum min max sum min max sum
item
apple A G ADGCF 114 476 1469 33 45 195 0b100001 0b101101 0b1000010b1001000b1001110b1010100b101101 0x21 0x2d 0x210x240x270x2a0x2d ! - !$'*-
banana A G BEADG 115 416 1392 34 46 200 0b100010 0b101110 0b1000100b1001010b1010000b1010110b101110 0x22 0x2e 0x220x250x280x2b0x2e " . "%(+.
orange A F CFBEA 186 495 1739 35 47 205 0b100011 0b101111 0b1000110b1001100b1010010b1011000b101111 0x23 0x2f 0x230x260x290x2c0x2f # / #&),/
データフレームに登録された順に文字列結合されている。
>>> df[df["item"] == "apple"]
item rank date price ASCII_CODE_DEC ASCII_CODE_BIN ASCII_CODE_HEX ASCII_CHR
0 apple A 2019-10-14 191 33 0b100001 0x21 !
3 apple D 2019-10-20 193 36 0b100100 0x24 $
6 apple G 2019-10-26 428 39 0b100111 0x27 '
9 apple J 2019-11-01 160 42 0b101010 0x2a *
12 apple M 2019-11-07 145 45 0b101101 0x2d -
型確認
>>> type(df.groupby("item")[['rank','date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].agg([min,max,sum]))
<class 'pandas.core.frame.DataFrame'>
複数列で集計・集約関数を複数適用(listagg含む)
取得列多いと**...**となるのか。
>>> df.groupby("item")[['rank','date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].agg([min,max,sum,list])
rank price ... ASCII_CODE_HEX ASCII_CHR
min max sum list min max sum list ... min max sum list min max sum list
item ...
apple A M ADGJM [A, D, G, J, M] 145 428 1117 [191, 193, 428, 160, 145] ... 0x21 0x2d 0x210x240x270x2a0x2d [0x21, 0x24, 0x27, 0x2a, 0x2d] ! - !$'*- [!, $, ', *, -]
banana B N BEHKN [B, E, H, K, N] 114 359 1130 [114, 310, 206, 141, 359] ... 0x22 0x2e 0x220x250x280x2b0x2e [0x22, 0x25, 0x28, 0x2b, 0x2e] " . "%(+. [", %, (, +, .]
orange C O CFILO [C, F, I, L, O] 108 414 1245 [200, 355, 168, 414, 108] ... 0x23 0x2f 0x230x260x290x2c0x2f [0x23, 0x26, 0x29, 0x2c, 0x2f] # / #&),/ [#, &, ), ,, /]
[3 rows x 24 columns]
型確認
>>> type(df.groupby("item")[['rank','date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].agg([min,max,sum,list]))
<class 'pandas.core.frame.DataFrame'>
集計・集約単位列が複数列の場合
単一列に集計・集約関数を単一適用(listagg除く)
>>> df.groupby(["item","rank"])[['price']].apply(max)
price
item rank
apple A 288
D 446
G 220
J 492
M 162
banana B 146
E 364
H 394
K 462
N 282
orange C 415
F 407
I 141
L 308
O 371
型確認
>>> type(df.groupby(["item","rank"])[['price']].apply(max))
<class 'pandas.core.frame.DataFrame'>
単一列に集計・集約関数を単一適用(listagg含む)
>>> df.groupby(["item","rank"])["price"].apply(list)
item rank
apple A [288]
D [446]
G [220]
J [492]
M [162]
banana B [146]
E [364]
H [394]
K [462]
N [282]
orange C [415]
F [407]
I [141]
L [308]
O [371]
Name: price, dtype: object
型確認
>>> type(df.groupby(["item","rank"])["price"].apply(list))
<class 'pandas.core.series.Series'>
agg関数の引数に集計・集約関数を単一適用
でできた。
>>> df.groupby(["item","rank"])["price"].agg([list])
list
item rank
apple A [288]
D [446]
G [220]
J [492]
M [162]
banana B [146]
E [364]
H [394]
K [462]
N [282]
orange C [415]
F [407]
I [141]
L [308]
O [371]
型確認
>>> type(df.groupby(["item","rank"])["price"].agg([list]))
<class 'pandas.core.frame.DataFrame'>
単一列に集計・集約関数を複数適用(listagg除く)
>>> df.groupby(["item","rank"])[['price']].agg([min,max,sum])
price
min max sum
item rank
apple A 288 288 288
D 446 446 446
G 220 220 220
J 492 492 492
M 162 162 162
banana B 146 146 146
E 364 364 364
H 394 394 394
K 462 462 462
N 282 282 282
orange C 415 415 415
F 407 407 407
I 141 141 141
L 308 308 308
O 371 371 371
型確認
>>> type(df.groupby(["item","rank"])[['price']].agg([min,max,sum]))
<class 'pandas.core.frame.DataFrame'>
単一列に集計・集約関数を複数適用(listagg含む)
>>> df.groupby(["item","rank"])[['price']].agg([min,max,sum,list])
price
min max sum list
item rank
apple A 288 288 288 [288]
D 446 446 446 [446]
G 220 220 220 [220]
J 492 492 492 [492]
M 162 162 162 [162]
banana B 146 146 146 [146]
E 364 364 364 [364]
H 394 394 394 [394]
K 462 462 462 [462]
N 282 282 282 [282]
orange C 415 415 415 [415]
F 407 407 407 [407]
I 141 141 141 [141]
L 308 308 308 [308]
O 371 371 371 [371]
型確認
>>> type(df.groupby(["item","rank"])[['price']].agg([min,max,sum,list]))
<class 'pandas.core.frame.DataFrame'>
複数列に集計・集約関数を単一適用(listagg除く)
>>> df.groupby(["item","rank"])[['date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].apply(max)
date price ASCII_CODE_DEC ASCII_CODE_BIN ASCII_CODE_HEX ASCII_CHR
item rank
apple A 2019-10-14 288 33 0b100001 0x21 !
D 2019-10-20 446 36 0b100100 0x24 $
G 2019-10-26 220 39 0b100111 0x27 '
J 2019-11-01 492 42 0b101010 0x2a *
M 2019-11-07 162 45 0b101101 0x2d -
banana B 2019-10-16 146 34 0b100010 0x22 "
E 2019-10-22 364 37 0b100101 0x25 %
H 2019-10-28 394 40 0b101000 0x28 (
K 2019-11-03 462 43 0b101011 0x2b +
N 2019-11-09 282 46 0b101110 0x2e .
orange C 2019-10-18 415 35 0b100011 0x23 #
F 2019-10-24 407 38 0b100110 0x26 &
I 2019-10-30 141 41 0b101001 0x29 )
L 2019-11-05 308 44 0b101100 0x2c ,
O 2019-11-11 371 47 0b101111 0x2f /
型確認
>>> type(df.groupby(["item","rank"])[['date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].apply(max))
<class 'pandas.core.frame.DataFrame'>
複数列に集計・集約関数を単一適用(listagg含む)
>>> df.groupby(["item","rank"])[['date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].apply(list)
item rank
apple A [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
D [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
G [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
J [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
M [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
banana B [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
E [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
H [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
K [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
N [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
orange C [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
F [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
I [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
L [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
O [date, price, ASCII_CODE_DEC, ASCII_CODE_BIN, ...
dtype: object
型確認
>>> type(df.groupby(["item","rank"])[['date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].apply(list))
<class 'pandas.core.series.Series'>
agg関数の引数に集計・集約関数を単一適用
でできた。
>>> df.groupby(["item","rank"])[['date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].agg([list])
date price ASCII_CODE_DEC ASCII_CODE_BIN ASCII_CODE_HEX ASCII_CHR
list list list list list list
item rank
apple A [2019-10-14 00:00:00] [288] [33] [0b100001] [0x21] [!]
D [2019-10-20 00:00:00] [446] [36] [0b100100] [0x24] [$]
G [2019-10-26 00:00:00] [220] [39] [0b100111] [0x27] [']
J [2019-11-01 00:00:00] [492] [42] [0b101010] [0x2a] [*]
M [2019-11-07 00:00:00] [162] [45] [0b101101] [0x2d] [-]
banana B [2019-10-16 00:00:00] [146] [34] [0b100010] [0x22] ["]
E [2019-10-22 00:00:00] [364] [37] [0b100101] [0x25] [%]
H [2019-10-28 00:00:00] [394] [40] [0b101000] [0x28] [(]
K [2019-11-03 00:00:00] [462] [43] [0b101011] [0x2b] [+]
N [2019-11-09 00:00:00] [282] [46] [0b101110] [0x2e] [.]
orange C [2019-10-18 00:00:00] [415] [35] [0b100011] [0x23] [#]
F [2019-10-24 00:00:00] [407] [38] [0b100110] [0x26] [&]
I [2019-10-30 00:00:00] [141] [41] [0b101001] [0x29] [)]
L [2019-11-05 00:00:00] [308] [44] [0b101100] [0x2c] [,]
O [2019-11-11 00:00:00] [371] [47] [0b101111] [0x2f] [/]
型確認
>>> type(df.groupby(["item","rank"])[['date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].agg([list]))
<class 'pandas.core.frame.DataFrame'>
複数列に集計・集約関数を複数適用(listagg除く)
>>> df.groupby(["item","rank"])[['date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].agg([min,max,sum])
price ASCII_CODE_DEC ASCII_CODE_BIN ASCII_CODE_HEX ASCII_CHR
min max sum min max sum min max sum min max sum min max sum
item rank
apple A 288 288 288 33 33 33 0b100001 0b100001 0b100001 0x21 0x21 0x21 ! ! !
D 446 446 446 36 36 36 0b100100 0b100100 0b100100 0x24 0x24 0x24 $ $ $
G 220 220 220 39 39 39 0b100111 0b100111 0b100111 0x27 0x27 0x27 ' ' '
J 492 492 492 42 42 42 0b101010 0b101010 0b101010 0x2a 0x2a 0x2a * * *
M 162 162 162 45 45 45 0b101101 0b101101 0b101101 0x2d 0x2d 0x2d - - -
banana B 146 146 146 34 34 34 0b100010 0b100010 0b100010 0x22 0x22 0x22 " " "
E 364 364 364 37 37 37 0b100101 0b100101 0b100101 0x25 0x25 0x25 % % %
H 394 394 394 40 40 40 0b101000 0b101000 0b101000 0x28 0x28 0x28 ( ( (
K 462 462 462 43 43 43 0b101011 0b101011 0b101011 0x2b 0x2b 0x2b + + +
N 282 282 282 46 46 46 0b101110 0b101110 0b101110 0x2e 0x2e 0x2e . . .
orange C 415 415 415 35 35 35 0b100011 0b100011 0b100011 0x23 0x23 0x23 # # #
F 407 407 407 38 38 38 0b100110 0b100110 0b100110 0x26 0x26 0x26 & & &
I 141 141 141 41 41 41 0b101001 0b101001 0b101001 0x29 0x29 0x29 ) ) )
L 308 308 308 44 44 44 0b101100 0b101100 0b101100 0x2c 0x2c 0x2c , , ,
O 371 371 371 47 47 47 0b101111 0b101111 0b101111 0x2f 0x2f 0x2f / / /
型確認
>>> type(df.groupby(["item","rank"])[['date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].agg([min,max,sum]))
<class 'pandas.core.frame.DataFrame'>
複数列で集計・集約関数を複数適用(listagg含む)
>>> df.groupby(["item","rank"])[['date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].agg([min,max,sum,list])
price ASCII_CODE_DEC ASCII_CODE_BIN ASCII_CODE_HEX ASCII_CHR
min max sum list min max sum list min max sum list min max sum list min max sum list
item rank
apple A 288 288 288 [288] 33 33 33 [33] 0b100001 0b100001 0b100001 [0b100001] 0x21 0x21 0x21 [0x21] ! ! ! [!]
D 446 446 446 [446] 36 36 36 [36] 0b100100 0b100100 0b100100 [0b100100] 0x24 0x24 0x24 [0x24] $ $ $ [$]
G 220 220 220 [220] 39 39 39 [39] 0b100111 0b100111 0b100111 [0b100111] 0x27 0x27 0x27 [0x27] ' ' ' [']
J 492 492 492 [492] 42 42 42 [42] 0b101010 0b101010 0b101010 [0b101010] 0x2a 0x2a 0x2a [0x2a] * * * [*]
M 162 162 162 [162] 45 45 45 [45] 0b101101 0b101101 0b101101 [0b101101] 0x2d 0x2d 0x2d [0x2d] - - - [-]
banana B 146 146 146 [146] 34 34 34 [34] 0b100010 0b100010 0b100010 [0b100010] 0x22 0x22 0x22 [0x22] " " " ["]
E 364 364 364 [364] 37 37 37 [37] 0b100101 0b100101 0b100101 [0b100101] 0x25 0x25 0x25 [0x25] % % % [%]
H 394 394 394 [394] 40 40 40 [40] 0b101000 0b101000 0b101000 [0b101000] 0x28 0x28 0x28 [0x28] ( ( ( [(]
K 462 462 462 [462] 43 43 43 [43] 0b101011 0b101011 0b101011 [0b101011] 0x2b 0x2b 0x2b [0x2b] + + + [+]
N 282 282 282 [282] 46 46 46 [46] 0b101110 0b101110 0b101110 [0b101110] 0x2e 0x2e 0x2e [0x2e] . . . [.]
orange C 415 415 415 [415] 35 35 35 [35] 0b100011 0b100011 0b100011 [0b100011] 0x23 0x23 0x23 [0x23] # # # [#]
F 407 407 407 [407] 38 38 38 [38] 0b100110 0b100110 0b100110 [0b100110] 0x26 0x26 0x26 [0x26] & & & [&]
I 141 141 141 [141] 41 41 41 [41] 0b101001 0b101001 0b101001 [0b101001] 0x29 0x29 0x29 [0x29] ) ) ) [)]
L 308 308 308 [308] 44 44 44 [44] 0b101100 0b101100 0b101100 [0b101100] 0x2c 0x2c 0x2c [0x2c] , , , [,]
O 371 371 371 [371] 47 47 47 [47] 0b101111 0b101111 0b101111 [0b101111] 0x2f 0x2f 0x2f [0x2f] / / / [/]
型確認
>>> type(df.groupby(["item","rank"])[['date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR']].agg([min,max,sum,list]))
<class 'pandas.core.frame.DataFrame'>
あとがき
listaggを単一適用する場合はlistaggかどうかは関わらず、集計・集約関数のインターフェース関数をapply関数からagg関数に変えて引数に単一適用すれば、良かっただけなので、パターン分類としてはふさわしくなかった。ハンディなのはagg関数経由で集計・集約関数を適用するパターンだと思う。個人的にはlistagg発見できたのは大きい。普段はsqlをよく書いているので、sqlでダイナミックに組み立てることがpythonでもできるようにいろいろ試していこうとおもう。新しいことに取り組むのは楽しい。😆
ここまでの経過を表にまとめてみる。
apply関数の引数は単一しか受け取れないぽいので、グレーダウン。
agg関数の引数は単一でも複数でも受け取れるので、ピンク。
上記以外もできるけど、使いやすくないのかな。。
ユーザー定義の集計・集約関数の場合を見てないので、このパターンに適合されるかはその都度、試す。
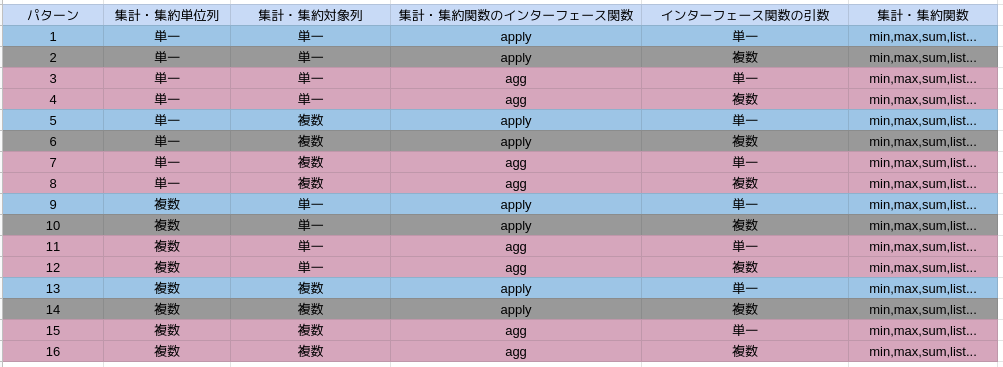
以上、ありがとうございました。
20191014追記
カラム名をフラットにしたいと思って探していたら見つけた。
pandas.DataFrameで、MultiIndexのカラムをフラットな形にrenameするする方法
non_flat
>>> df.groupby(["item"])[['price','ASCII_CODE_HEX']].agg([min,list])
price ASCII_CODE_HEX
min list min list
item
apple 219 [475, 364, 219, 399, 393] 0x21 [0x21, 0x24, 0x27, 0x2a, 0x2d]
banana 106 [433, 210, 207, 106, 377] 0x22 [0x22, 0x25, 0x28, 0x2b, 0x2e]
orange 233 [416, 248, 339, 479, 233] 0x23 [0x23, 0x26, 0x29, 0x2c, 0x2f]
flat
>>> df.groupby(["item"])[['price','ASCII_CODE_HEX','ASCII_CHR']].agg({"price":{"price_min":min,"price_list":list},"ASCII_CODE_HEX":{"ASCII_CODE_HEX_min":min,"ASCII_CODE_HEX_list":list}})
price_min price_list ASCII_CODE_HEX_min ASCII_CODE_HEX_list
item
apple 219 [475, 364, 219, 399, 393] 0x21 [0x21, 0x24, 0x27, 0x2a, 0x2d]
banana 106 [433, 210, 207, 106, 377] 0x22 [0x22, 0x25, 0x28, 0x2b, 0x2e]
orange 233 [416, 248, 339, 479, 233] 0x23 [0x23, 0x26, 0x29, 0x2c, 0x2f]
agg関数の引数に与える形をlist型からdict型に変更
>>> print(type([min,list]))
<class 'list'>
>>> print(type({"price":{"price_min":min,"price_list":list},"ASCII_CODE_HEX":{"ASCII_CODE_HEX_min":min,"ASCII_CODE_HEX_list":list}}))
<class 'dict'>
なお、集計・集約関数はmin,listはagg関数の引数に与えるとき、ダブルクヲートで囲まずに実行しないといけないぽい。
>>> df.groupby(["item"])[['price','ASCII_CODE_HEX','ASCII_CHR']].agg({"price":{"price_min":"min","price_list":"list"},"ASCII_CODE_HEX":{"ASCII_CODE_HEX_min":"min","ASCII_CODE_HEX_list":"list"}})
AttributeError: 'SeriesGroupBy' object has no attribute 'list'
jqコマンドに食わせるときはダブルクヲートで囲んでやる必要があるから、めんどくさい。
[postgres💘25e14fb5c939 (月 10月 14 19:27:17) ~/script_scratch/python]$echo '{"price":{"price_min":min,"price_list":list},"ASCII_CODE_HEX":{"ASCII_CODE_HEX_min":min,"ASCII_CODE_HEX_list":list}}' | jq .
parse error: Invalid numeric literal at line 1, column 26
[postgres💘25e14fb5c939 (月 10月 14 19:27:25) ~/script_scratch/python]$echo '{"price":{"price_min":"min","price_list":"list"},"ASCII_CODE_HEX":{"ASCII_CODE_HEX_min":"min","ASCII_CODE_HEX_list":"list"}}' | jq .
{
"price": {
"price_min": "min",
"price_list": "list"
},
"ASCII_CODE_HEX": {
"ASCII_CODE_HEX_min": "min",
"ASCII_CODE_HEX_list": "list"
}
}
[postgres💘25e14fb5c939 (月 10月 14 19:27:59) ~/script_scratch/python]$jq --version
jq-1.5
文字列をシリーズ型に変換
便利
【便利】Python 標準のリストと Pandas のDataFrame, Seriesを相互に変換する方法をまとめてみた
ASCII / ISO 8859-1 (Latin-1) Table with HTML Entity Names
ライブラリインストール
置換処理でつかう
>>> import re
>>> re.__version__
'2.2.1'
コマンド文字列ビルド
#1.データフレームからカラム情報取得
#2.取得したカラム情報を文字列型に変換
#3.文字列からスペース削除
#4.文字列から改行削除
#5.文字列からleft square bracketとその左側削除
#6.文字列からright square bracketとその右側削除
#7.文字列の左端に**'pd.Series('+'['を付与
#8.文字列の右端に+']'+')'**を付与
>>> to_series='pd.Series('+'['+re.sub('\].*','',re.sub('.*\[','',re.sub(' ','',re.sub('\n','',str(df.columns)))))+']'+')'
コマンド文字列出力確認
>>> to_series
"pd.Series(['item','rank','date','price','ASCII_CODE_DEC','ASCII_CODE_BIN','ASCII_CODE_HEX','ASCII_CHR'])"
型確認
>>> type(to_series)
<class 'str'>
eval関数でコマンド文字列即時実行
>>> eval(to_series)
0 item
1 rank
2 date
3 price
4 ASCII_CODE_DEC
5 ASCII_CODE_BIN
6 ASCII_CODE_HEX
7 ASCII_CHR
dtype: object
型確認
>>> type(eval(to_series))
<class 'pandas.core.series.Series'>
シリーズ型をリスト型に変換
>>> eval(to_series).values.tolist()
['item', 'rank', 'date', 'price', 'ASCII_CODE_DEC', 'ASCII_CODE_BIN', 'ASCII_CODE_HEX', 'ASCII_CHR']
型確認
>>> type(eval(to_series).values.tolist())
<class 'list'>
リスト型をデータフレーム型に変換
>>> pd.DataFrame(eval(to_series).values.tolist(),columns=['col_info'])
col_info
0 item
1 rank
2 date
3 price
4 ASCII_CODE_DEC
5 ASCII_CODE_BIN
6 ASCII_CODE_HEX
7 ASCII_CHR
型確認
>>> type(pd.DataFrame(eval(to_series).values.tolist(),columns=['col_info']))
<class 'pandas.core.frame.DataFrame'>
ここまでをoneliner
データフレームの変数名(df)とシリーズの変数名(to_series)はダイナミックにしておくのがよさげ。
>>> pd.DataFrame(eval('pd.Series('+'['+re.sub('\].*','',re.sub('.*\[','',re.sub(' ','',re.sub('\n','',str(df.columns)))))+']'+')').values.tolist(),columns=['col_info'])
col_info
0 item
1 rank
2 date
3 price
4 ASCII_CODE_DEC
5 ASCII_CODE_BIN
6 ASCII_CODE_HEX
7 ASCII_CHR
20191015追記
ここらへんからの件は、正規化したデータフレームをdbに打ち込もうとしているプロセスです。目標は分析関数が使えるdbで色々弄るまで。padasでも分析関数はあるぽいので、試していこうとおもう。
pandasで窓関数を適用するrollingを使って移動平均などを算出
[Window](https://pandas.pydata.org/pandas-docs/stable/reference/window.html#standard-moving-window-functions
Rのshiny的なやつが実現できそうなpythonライブラリあった。可視化をハンディにできるかも。
雑然データ作成してcsvファイル作成するの便利かも。ランダムに色々ノイズ入れて、整然データ作成する練習。
pandas操作
たまたまみつけたけど、Rでも似たようなことができるらしいので、試したい。
Loading Data Frame to Relational Database with R
Importの仕方
X転送とかでローカルに持ってきて使ってみようかな。Jupiter notebook
https://qiita.com/takuyanin/items/8bf396e7b6b051670147
ダイナミックには必須
https://qiita.com/icoxfog417/items/bf04966d4e9706eb9e04
バージョン確認
バージョン確認するために以下を参考
Count Method Calls Using a Metaclass
アトリビュート(状態)とアトリビュート以外(振舞)に分類できる。
>>> import random as rd
>>> [x for x in dir(eval("rd")) if x.startswith("__") ]
['__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
>>> [x for x in dir(eval("rd")) if not x.startswith("__") ]
['BPF', 'LOG4', 'NV_MAGICCONST', 'RECIP_BPF', 'Random', 'SG_MAGICCONST', 'SystemRandom', 'TWOPI', '_BuiltinMethodType', '_MethodType', '_Sequence', '_Set', '_acos', '_bisect', '_ceil', '_cos', '_e', '_exp', '_inst', '_itertools', '_log', '_os', '_pi', '_random', '_sha512', '_sin', '_sqrt', '_test', '_test_generator', '_urandom', '_warn', 'betavariate', 'choice', 'choices', 'expovariate', 'gammavariate', 'gauss', 'getrandbits', 'getstate', 'lognormvariate', 'normalvariate', 'paretovariate', 'randint', 'random', 'randrange', 'sample', 'seed', 'setstate', 'shuffle', 'triangular', 'uniform', 'vonmisesvariate', 'weibullvariate']
>>> rd.__spec__
ModuleSpec(name='random', loader=<_frozen_importlib_external.SourceFileLoader object at 0x7fe7a3137510>, origin='/usr/local/lib/python3.7/random.py')
>>> dt.__spec__
ModuleSpec(name='datetime', loader=<_frozen_importlib_external.SourceFileLoader object at 0x7fe7a3132ed0>, origin='/usr/local/lib/python3.7/datetime.py')
>>> import datetime as dt
>>> [x for x in dir(eval("dt")) if not x.startswith("__") ]
['MAXYEAR', 'MINYEAR', 'date', 'datetime', 'datetime_CAPI', 'sys', 'time', 'timedelta', 'timezone', 'tzinfo']
>>> [x for x in dir(eval("dt")) if x.startswith("__") ]
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
>>> dt.__spec__
ModuleSpec(name='datetime', loader=<_frozen_importlib_external.SourceFileLoader object at 0x7fe7a3132ed0>, origin='/usr/local/lib/python3.7/datetime.py')
**version**属性がないライブラリはバージョンわからない。
>>> import pandas as pd
>>> [x for x in dir(eval("pd")) if x.startswith("__") ]
['__builtins__', '__cached__', '__doc__', '__docformat__', '__file__', '__getattr__', '__git_version__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '__version__']
>>> [x for x in dir(eval("pd")) if not x.startswith("__") ]
['Categorical', 'CategoricalDtype', 'CategoricalIndex', 'DataFrame', 'DateOffset', 'DatetimeIndex', 'DatetimeTZDtype', 'ExcelFile', 'ExcelWriter', 'Float64Index', 'Grouper', 'HDFStore', 'Index', 'IndexSlice', 'Int16Dtype', 'Int32Dtype', 'Int64Dtype', 'Int64Index', 'Int8Dtype', 'Interval', 'IntervalDtype', 'IntervalIndex', 'MultiIndex', 'NaT', 'NamedAgg', 'Period', 'PeriodDtype', 'PeriodIndex', 'RangeIndex', 'Series', 'SparseArray', 'SparseDataFrame', 'SparseDtype', 'SparseSeries', 'Timedelta', 'TimedeltaIndex', 'Timestamp', 'UInt16Dtype', 'UInt32Dtype', 'UInt64Dtype', 'UInt64Index', 'UInt8Dtype', '_config', '_hashtable', '_lib', '_libs', '_np_version_under1p14', '_np_version_under1p15', '_np_version_under1p16', '_np_version_under1p17', '_tslib', '_typing', '_version', 'api', 'array', 'arrays', 'bdate_range', 'compat', 'concat', 'core', 'crosstab', 'cut', 'date_range', 'datetime', 'describe_option', 'errors', 'eval', 'factorize', 'get_dummies', 'get_option', 'infer_freq', 'interval_range', 'io', 'isna', 'isnull', 'lreshape', 'melt', 'merge', 'merge_asof', 'merge_ordered', 'notna', 'notnull', 'np', 'offsets', 'option_context', 'options', 'pandas', 'period_range', 'pivot', 'pivot_table', 'plotting', 'qcut', 'read_clipboard', 'read_csv', 'read_excel', 'read_feather', 'read_fwf', 'read_gbq', 'read_hdf', 'read_html', 'read_json', 'read_msgpack', 'read_parquet', 'read_pickle', 'read_sas', 'read_spss', 'read_sql', 'read_sql_query', 'read_sql_table', 'read_stata', 'read_table', 'reset_option', 'set_eng_float_format', 'set_option', 'show_versions', 'test', 'testing', 'timedelta_range', 'to_datetime', 'to_msgpack', 'to_numeric', 'to_pickle', 'to_timedelta', 'tseries', 'unique', 'util', 'value_counts', 'wide_to_long']
>>> pd.__version__
'0.25.1'
ライブラリをデータフレーム管理したらおもろそう
ライブラリ名をリスト型で持ちわます
>>> for i in ["rd","dt"]:print(i);
...
rd
dt
ライブラリから状態と振舞の情報を取得するコマンドをビルド
>>> for i in ["rd","dt"]:print('[x for x in dir(eval("'+i+'")) if x.startswith("__") ]');
...
[x for x in dir(eval("rd")) if x.startswith("__") ]
[x for x in dir(eval("dt")) if x.startswith("__") ]
コマンド即時実行
>>> for i in ["rd","dt"]:print(eval('[x for x in dir(eval("'+i+'")) if x.startswith("__") ]'));
...
['__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
取得できたリスト型をデータフレーム型に変換するコマンドをビルド
>>> for i in ["rd","dt"]:print('pd.DataFrame('+str(eval('[x for x in dir(eval("'+i+'")) if x.startswith("__") ]'))+',columns=[\''+i+'\'])');
...
pd.DataFrame(['__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__'],columns=['rd'])
pd.DataFrame(['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__'],columns=['dt'])
コマンド即時実行
>>> for i in ["rd","dt"]:print(eval('pd.DataFrame('+str(eval('[x for x in dir(eval("'+i+'")) if x.startswith("__") ]'))+',columns=[\''+i+'\'])'));
...
rd
0 __all__
1 __builtins__
2 __cached__
3 __doc__
4 __file__
5 __loader__
6 __name__
7 __package__
8 __spec__
dt
0 __builtins__
1 __cached__
2 __doc__
3 __file__
4 __loader__
5 __name__
6 __package__
7 __spec__
データフレーム変数に入れておくためのコマンドビルド
>>> for i in ["rd","dt"]:print('tmp_'+i+'=pd.DataFrame('+str(eval('[x for x in dir(eval("'+i+'")) if x.startswith("__") ]'))+',columns=[\''+'col_name'+'\'])');
...
tmp_rd=pd.DataFrame(['__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__'],columns=['col_name'])
tmp_dt=pd.DataFrame(['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__'],columns=['col_name'])
コマンド即時実行
変数代入式はexec関数でそれ以外はeval関数を使用するぽい。
Pythonでevalを使って変数の値を代入するにはどうすればいいですか?
メッセージつけてみた。Noneがでてくるので、メッセージでわかるようにした。
>>> for i in ["rd","dt"]:print(exec('tmp_'+i+'=pd.DataFrame('+str(eval('[x for x in dir(eval("'+i+'")) if x.startswith("__") ]'))+',columns=[\''+'col_name'+'\'])'));print("データフレーム"+"tmp_"+i+"の作成が完了 しました。😆")
...
None
データフレームtmp_rdの作成が完了しました。😆
None
データフレームtmp_dtの作成が完了しました。😆
>>> tmp_rd
col_name
0 __all__
1 __builtins__
2 __cached__
3 __doc__
4 __file__
5 __loader__
6 __name__
7 __package__
8 __spec__
>>> tmp_dt
col_name
0 __builtins__
1 __cached__
2 __doc__
3 __file__
4 __loader__
5 __name__
6 __package__
7 __spec__
テーブル名とカラム名のデータフレームよりライブラリ管理テーブル作成
直積をイメージ。
>>> tbl_rd=pd.DataFrame(data=['rd'], columns=['tbl_name'])
>>> col_rd=pd.DataFrame(['__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__'],columns=['col_name'])
>>> tbl_rd
tbl_name
0 rd
>>> col_rd
col_name
0 __all__
1 __builtins__
2 __cached__
3 __doc__
4 __file__
5 __loader__
6 __name__
7 __package__
8 __spec__
product経由で組み合わせリスト作って、データフレームに食わせる
この部分、デフォルトライブラリで実現できそう。list関数とzip関数使って組み合わせ出せそう。
>>> tbl_rd
tbl_name
0 rd
>>> col_rd
col_name
0 __all__
1 __builtins__
2 __cached__
3 __doc__
4 __file__
5 __loader__
6 __name__
7 __package__
8 __spec__
>>> from itertools import product
>>> product(tbl_rd['tbl_name'],col_rd['col_name'])
<itertools.product object at 0x7feecb4b6cd0>
>>> type(product(tbl_rd['tbl_name'],col_rd['col_name']))
<class 'itertools.product'>
>>> list(product(tbl_rd['tbl_name'],col_rd['col_name']))
[('rd', '__all__'), ('rd', '__builtins__'), ('rd', '__cached__'), ('rd', '__doc__'), ('rd', '__file__'), ('rd', '__loader__'), ('rd', '__name__'), ('rd', '__package__'), ('rd', '__spec__')]
>>> type(list(product(tbl_rd['tbl_name'],col_rd['col_name'])))
<class 'list'>
>>> pd.DataFrame(list(product(tbl_rd['tbl_name'],col_rd['col_name'])),columns=['tbl_name','col_name'])
tbl_name col_name
0 rd __all__
1 rd __builtins__
2 rd __cached__
3 rd __doc__
4 rd __file__
5 rd __loader__
6 rd __name__
7 rd __package__
8 rd __spec__
この続きはまた。。スクラッチ楽しい。あとはここらへん参考にしてやるか。
https://deepage.net/features/pandas-concat.html
一度ここまでの流れをスクリプト化しておく。
**#1.**整形したデータフレームを縦方向に連結するため、一時データフレームを用意
**#2.**for文のin句の引数にリスト型のパッケージを与える(ここはライブラリ情報を取得するメソッドの戻り値を設定する予定)
**#3.**ライブラリ名から取得できるアトリビュートを設定し、要素数を求めておく(各データフレームを一意に決めるID列の生成のため)
**#4.**tmp_col_ライブラリ別名の作成
**#5.**tmp_tbl_ライブラリ別名の作成
**#6.**tmp_tbl_ライブラリ別名、tmp_col_ライブラリ別名を直積してtbl_ライブラリ別名を作成
**#7.**ライブラリ情報テーブルの作成(ライブラリ単位にデータフレームを縦方向に連結)
**#8.**変数名を変えてライブラリテーブルを作成
以上はアトリビュートの情報だけで、かつアトリビュート情報の詳細を含んでいないので、これをベースに
アトリビュート以外の情報も含めていきたい。正規化やデータフレーム操作の練習になりそう。
Pandas case文
# !/usr/local/bin/python3.7
import pandas as pd
import random as rd
import datetime as dt
from itertools import product
# バッファーデータフレーム宣言
tmp_concat=pd.DataFrame({'tbl_name':[],'col_name':[]});
for i in ["rd","dt"]:
#リスト変数名:tmp_list
print('tmp_list='+str(eval('[x for x in dir(eval("'+i+'")) if x.startswith("__") ]')));
print(exec('tmp_list='+str(eval('[x for x in dir(eval("'+i+'")) if x.startswith("__") ]'))));
print(len(tmp_list))
#一時カラム変数名:tmp_col_ライブラリ別名
print('tmp_col_'+i+'=pd.DataFrame({\'id\':[i for i in range(len(tmp_list))],\'col_name\':'+str(eval('[x for x in dir(eval("'+i+'")) if x.startswith("__") ]'))+'})');
print(exec('tmp_col_'+i+'=pd.DataFrame({\'id\':[i for i in range(len(tmp_list))],\'col_name\':'+str(eval('[x for x in dir(eval("'+i+'")) if x.startswith("__") ]'))+'})'));
#一時テーブル変数名:tmp_tbl_ライブラリ別名
print('tmp_tbl_'+i+'=pd.DataFrame({\'id\':[len([\''+i+'\'])],\'tbl_name\':\''+i+'\'})');
print(exec('tmp_tbl_'+i+'=pd.DataFrame({\'id\':[len([\''+i+'\'])],\'tbl_name\':\''+i+'\'})'));
print('pd.DataFrame(list(product('+'tmp_tbl_'+i+'[\'tbl_name\'],'+'tmp_col_'+i+'[\'col_name\'])),columns=[\'tbl_name\',\'col_name\'])');
#テーブル変数名:tbl_ライブラリ別名
print('tbl_'+i+'='+'pd.DataFrame(list(product('+'tmp_tbl_'+i+'[\'tbl_name\'],'+'tmp_col_'+i+'[\'col_name\'])),columns=[\'tbl_name\',\'col_name\'])');
print(exec('tbl_'+i+'='+'pd.DataFrame(list(product('+'tmp_tbl_'+i+'[\'tbl_name\'],'+'tmp_col_'+i+'[\'col_name\'])),columns=[\'tbl_name\',\'col_name\'])'));
#print(eval('tbl_'+i));
#ライブラリ情報テーブルの作成
print('tmp_concat=pd.concat([tmp_concat,'+'tbl_'+i+'])');
print(exec('tmp_concat=pd.concat([tmp_concat,'+'tbl_'+i+'])'));
print(eval('tmp_concat'));
print("データフレーム"+"tbl_"+i+"の作成が完了 しました。😆");
# tmp_concatデータフレームをライブラリテーブルに登録
print(('lib_tbl=tmp_concat'));
print(exec('lib_tbl=tmp_concat'));
print(eval('lib_tbl'));
実行ログ
[postgres🧡25e14fb5c939 (火 10月 15 23:00:11) ~/script_scratch/python]$python dyn.py
tmp_list=['__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
None
9
tmp_col_rd=pd.DataFrame({'id':[i for i in range(len(tmp_list))],'col_name':['__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']})
None
tmp_tbl_rd=pd.DataFrame({'id':[len(['rd'])],'tbl_name':'rd'})
None
pd.DataFrame(list(product(tmp_tbl_rd['tbl_name'],tmp_col_rd['col_name'])),columns=['tbl_name','col_name'])
tbl_rd=pd.DataFrame(list(product(tmp_tbl_rd['tbl_name'],tmp_col_rd['col_name'])),columns=['tbl_name','col_name'])
None
tmp_concat=pd.concat([tmp_concat,tbl_rd])
None
tbl_name col_name
0 rd __all__
1 rd __builtins__
2 rd __cached__
3 rd __doc__
4 rd __file__
5 rd __loader__
6 rd __name__
7 rd __package__
8 rd __spec__
データフレームtbl_rdの作成が完了 しました。😆
tmp_list=['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
None
8
tmp_col_dt=pd.DataFrame({'id':[i for i in range(len(tmp_list))],'col_name':['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']})
None
tmp_tbl_dt=pd.DataFrame({'id':[len(['dt'])],'tbl_name':'dt'})
None
pd.DataFrame(list(product(tmp_tbl_dt['tbl_name'],tmp_col_dt['col_name'])),columns=['tbl_name','col_name'])
tbl_dt=pd.DataFrame(list(product(tmp_tbl_dt['tbl_name'],tmp_col_dt['col_name'])),columns=['tbl_name','col_name'])
None
tmp_concat=pd.concat([tmp_concat,tbl_dt])
None
tbl_name col_name
0 rd __all__
1 rd __builtins__
2 rd __cached__
3 rd __doc__
4 rd __file__
5 rd __loader__
6 rd __name__
7 rd __package__
8 rd __spec__
0 dt __builtins__
1 dt __cached__
2 dt __doc__
3 dt __file__
4 dt __loader__
5 dt __name__
6 dt __package__
7 dt __spec__
データフレームtbl_dtの作成が完了 しました。😆
lib_tbl=tmp_concat
None
tbl_name col_name
0 rd __all__
1 rd __builtins__
2 rd __cached__
3 rd __doc__
4 rd __file__
5 rd __loader__
6 rd __name__
7 rd __package__
8 rd __spec__
0 dt __builtins__
1 dt __cached__
2 dt __doc__
3 dt __file__
4 dt __loader__
5 dt __name__
6 dt __package__
7 dt __spec__
ここまでの段階でDBにぶち込めるか確認したいので、調べた。
とりあえず使えそうな SQLAlchemy 入門(※ ORM機能は使いません)
SQLAlchemy
PostgreSQLのデータをPandasのデータフレームとして読み書きする
postgresで試してみる。oracleもできるそう!とりあえず、データベースtest_01を作成しておいた。
[postgres💘25e14fb5c939 (火 10月 15 23:29:28) ~]$psql -U postgres -d test_01
psql (12.0)
Type "help" for help.
test_01=# \dt
Did not find any relations.
[postgres💘25e14fb5c939 (火 10月 15 23:32:02) ~]$lsof -P -i:5432
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
postgres 9430 postgres 3u IPv4 120545 0t0 TCP localhost:5432 (LISTEN)
ライブラリインストール
pipもアップグレードしてみた。sqlalchemyはsqlite3みたいに結構いろんなところで使われているぽい。
[postgres💘25e14fb5c939 (火 10月 15 23:32:40) ~]$su root
Password:
[root💙25e14fb5c939 (火 10月 15 23:35:02) /home/postgres]$pip install sqlalchemy | tee log
Collecting sqlalchemy
Downloading https://files.pythonhosted.org/packages/14/0e/487f7fc1e432cec50d2678f94e4133f2b9e9356e35bacc30d73e8cb831fc/SQLAlchemy-1.3.10.tar.gz (6.0MB)
Installing collected packages: sqlalchemy
Running setup.py install for sqlalchemy: started
Running setup.py install for sqlalchemy: finished with status 'done'
Successfully installed sqlalchemy-1.3.10
You are using pip version 19.0.3, however version 19.2.3 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
[root💙25e14fb5c939 (火 10月 15 23:37:09) /home/postgres]$find / -name "*sqlalchemy*"
/var/lib/yum/yumdb/p/40ab7ec875759f05aa3733204e49de9ae3c07743-pgadmin4-python-flask-sqlalchemy-2.3.2-1.rhel7-noarch
/var/lib/yum/yumdb/p/1c7dbc420471b75b725bda219a33f4486cd2cd80-pgadmin4-python-sqlalchemy-1.2.18-1.rhel7-x86_64
/usr/share/doc/pgadmin4-python-flask-sqlalchemy-2.3.2
/usr/share/doc/pgadmin4-python-sqlalchemy-1.2.18
/usr/share/licenses/pgadmin4-python-flask-sqlalchemy-2.3.2
/usr/local/lib/python3.7/site-packages/sqlalchemy
/usr/lib/python2.7/site-packages/pgadmin4-web/sqlalchemy
/usr/lib/python2.7/site-packages/pgadmin4-web/wtforms/ext/sqlalchemy
/usr/lib/python2.7/site-packages/pgadmin4-web/flask_sqlalchemy
[root💙25e14fb5c939 (火 10月 15 23:35:29) /home/postgres]$pip install --upgrade pip | tee log
Collecting pip
Downloading https://files.pythonhosted.org/packages/4a/08/6ca123073af4ebc4c5488a5bc8a010ac57aa39ce4d3c8a931ad504de4185/pip-19.3-py2.py3-none-any.whl (1.4MB)
Installing collected packages: pip
Found existing installation: pip 19.0.3
Uninstalling pip-19.0.3:
Successfully uninstalled pip-19.0.3
Successfully installed pip-19.3
[root💙25e14fb5c939 (火 10月 15 23:35:52) /home/postgres]$pip --version
pip 19.3 from /usr/local/lib/python3.7/site-packages/pip (python 3.7)
とりあえず、実行
[postgres💘25e14fb5c939 (火 10月 15 23:41:00) ~]$python
Python 3.7.4 (default, Oct 12 2019, 21:53:21)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from sqlalchemy import create_engine
>>> import pandas as pd
>>> engine = create_engine('postgresql://postgres:postgres_pwd@localhost:5432/test_01')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.7/site-packages/sqlalchemy/engine/__init__.py", line 479, in create_engine
return strategy.create(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/sqlalchemy/engine/strategies.py", line 87, in create
dbapi = dialect_cls.dbapi(**dbapi_args)
File "/usr/local/lib/python3.7/site-packages/sqlalchemy/dialects/postgresql/psycopg2.py", line 737, in dbapi
import psycopg2
ModuleNotFoundError: No module named 'psycopg2'
**ModuleNotFoundError: No module named 'psycopg2'**だそうなので、インストール。
[root💙25e14fb5c939 (火 10月 15 23:47:26) /home/postgres]$pip install psycopg2 | tee log
Collecting psycopg2
Downloading https://files.pythonhosted.org/packages/5c/1c/6997288da181277a0c29bc39a5f9143ff20b8c99f2a7d059cfb55163e165/psycopg2-2.8.3.tar.gz (377kB)
Installing collected packages: psycopg2
Running setup.py install for psycopg2: started
Running setup.py install for psycopg2: finished with status 'done'
Successfully installed psycopg2-2.8.3
[root💙25e14fb5c939 (火 10月 15 23:47:44) /home/postgres]$find / -name "*psycopg2*" 2>/dev/null
/var/lib/yum/yumdb/p/8d5f74033cc6a5938e236f8ee4997e34b1efd60a-python2-psycopg2-2.8.3-2.rhel7-x86_64
/usr/local/lib/python3.7/site-packages/sqlalchemy/dialects/postgresql/psycopg2.py
/usr/local/lib/python3.7/site-packages/sqlalchemy/dialects/postgresql/psycopg2cffi.py
/usr/local/lib/python3.7/site-packages/sqlalchemy/dialects/postgresql/__pycache__/psycopg2cffi.cpython-37.pyc
/usr/local/lib/python3.7/site-packages/sqlalchemy/dialects/postgresql/__pycache__/psycopg2.cpython-37.pyc
/usr/local/lib/python3.7/site-packages/psycopg2
/usr/local/lib/python3.7/site-packages/psycopg2-2.8.3-py3.7.egg-info
/usr/lib/python2.7/site-packages/pgadmin4-web/pgadmin/utils/driver/psycopg2
/usr/lib/python2.7/site-packages/pgadmin4-web/sqlalchemy/dialects/postgresql/psycopg2.py
/usr/lib/python2.7/site-packages/pgadmin4-web/sqlalchemy/dialects/postgresql/psycopg2.pyo
/usr/lib/python2.7/site-packages/pgadmin4-web/sqlalchemy/dialects/postgresql/psycopg2cffi.pyo
/usr/lib/python2.7/site-packages/pgadmin4-web/sqlalchemy/dialects/postgresql/psycopg2cffi.py
/usr/lib/python2.7/site-packages/pgadmin4-web/sqlalchemy/dialects/postgresql/psycopg2cffi.pyc
/usr/lib/python2.7/site-packages/pgadmin4-web/sqlalchemy/dialects/postgresql/psycopg2.pyc
/usr/lib64/python2.7/site-packages/psycopg2-2.8.3-py2.7.egg-info
/usr/lib64/python2.7/site-packages/psycopg2
とりあえずエラーでなくなった。
[postgres❣25e14fb5c939 (火 10月 15 23:48:49) ~]$python
Python 3.7.4 (default, Oct 12 2019, 21:53:21)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from sqlalchemy import create_engine
>>> import pandas as pd
>>> import psycopg2
>>> engine = create_engine('postgresql://postgres:postgres_pwd@localhost:5432/test_01')
データフレームはこれ。ひとまず、単一。
>>> tbl_rd
tbl_name col_name
0 rd __all__
1 rd __builtins__
2 rd __cached__
3 rd __doc__
4 rd __file__
5 rd __loader__
6 rd __name__
7 rd __package__
8 rd __spec__
おお、ふつうに取れた。カラム名はデータ元と同じで、index列が追加されている。テーブルはcreateしておく必要はないのか。
これは便利。😆
>>> tbl_rd.to_sql('tbl_rd', engine, if_exists='replace')
>>> fetch_pgdb=pd.read_sql("SELECT * FROM tbl_rd", engine)
>>> fetch_pgdb
index tbl_name col_name
0 0 rd __all__
1 1 rd __builtins__
2 2 rd __cached__
3 3 rd __doc__
4 4 rd __file__
5 5 rd __loader__
6 6 rd __name__
7 7 rd __package__
8 8 rd __spec__
postgresクライアントアプリからもデータ取れる。これは。。楽しすぎる。。。いろいろ幅が広がるなー。
[postgres🧡25e14fb5c939 (水 10月 16 00:05:27) ~/script_scratch/python]$psql -U postgres -d test_01
psql (12.0)
Type "help" for help.
test_01=# \dt
List of relations
Schema | Name | Type | Owner
--------+--------+-------+----------
public | tbl_rd | table | postgres
(1 row)
test_01=# select * from tbl_rd;
index | tbl_name | col_name
-------+----------+--------------
0 | rd | __all__
1 | rd | __builtins__
2 | rd | __cached__
3 | rd | __doc__
4 | rd | __file__
5 | rd | __loader__
6 | rd | __name__
7 | rd | __package__
8 | rd | __spec__
(9 rows)
test_01=#
postgres側で作成したテーブルをデータフレームに取り込んでみる。
test_01=# select * from generate_series(1,10,1);
generate_series
-----------------
1
2
3
4
5
6
7
8
9
10
(10 rows)
test_01=# create table seqqqq as select rn from generate_series(1,10,1) as seq(rn);
SELECT 10
test_01=# \dt
List of relations
Schema | Name | Type | Owner
--------+--------+-------+----------
public | seqqqq | table | postgres
public | tbl_rd | table | postgres
(2 rows)
python側でフェッチ。カラム名はデータベースにある定義そのままぽいです。楽しみがふえるなー。😁
>>> fetch_pgdb=pd.read_sql("SELECT * FROM seqqqq", engine)
>>> fetch_pgdb
rn
0 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
9 10
>>> fetch_pgdb['rn']
0 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
9 10
Name: rn, dtype: int64
>>> type(fetch_pgdb['rn'])
<class 'pandas.core.series.Series'>
>>> fetch_pgdb['rn'].values.tolist()
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> type(fetch_pgdb['rn'].values.tolist())
<class 'list'>
データフレームからデータ取り出してset化して
集合演算して新しくデータフレーム作り出しても面白いかも
これは面白いことできそうかも
https://qiita.com/amowwee/items/e63b3610ea750f7dba1b
メソッド情報取得
https://blog.amedama.jp/entry/2016/10/31/225219
重複行削除データフレーム
duplicated
Importの仕方
https://note.nkmk.me/python-import-usage/
アトリビュート情報取得コマンド作成
列追加してミスったら列削除してやりなおす。
>>> tbl_rd
tbl_name col_name cmd
0 rd __all__ 0 rd.__all__\n1 rd.__builtins__\n2 ...
1 rd __builtins__ 0 rd.__all__\n1 rd.__builtins__\n2 ...
2 rd __cached__ 0 rd.__all__\n1 rd.__builtins__\n2 ...
3 rd __doc__ 0 rd.__all__\n1 rd.__builtins__\n2 ...
4 rd __file__ 0 rd.__all__\n1 rd.__builtins__\n2 ...
5 rd __loader__ 0 rd.__all__\n1 rd.__builtins__\n2 ...
6 rd __name__ 0 rd.__all__\n1 rd.__builtins__\n2 ...
7 rd __package__ 0 rd.__all__\n1 rd.__builtins__\n2 ...
8 rd __spec__ 0 rd.__all__\n1 rd.__builtins__\n2 ...
>>> del tbl_rd['cmd']
>>> tbl_rd['cmd']=tbl_rd['tbl_name']+'.'+tbl_rd['col_name']
>>> tbl_rd
tbl_name col_name cmd
0 rd __all__ rd.__all__
1 rd __builtins__ rd.__builtins__
2 rd __cached__ rd.__cached__
3 rd __doc__ rd.__doc__
4 rd __file__ rd.__file__
5 rd __loader__ rd.__loader__
6 rd __name__ rd.__name__
7 rd __package__ rd.__package__
8 rd __spec__ rd.__spec__
コマンド列の取得してリスト型に変換
forでぐるぐる即時実行するため。
>>> tbl_rd['cmd']
0 rd.__all__
1 rd.__builtins__
2 rd.__cached__
3 rd.__doc__
4 rd.__file__
5 rd.__loader__
6 rd.__name__
7 rd.__package__
8 rd.__spec__
Name: cmd, dtype: object
>>> list(tbl_rd['cmd'])
['rd.__all__', 'rd.__builtins__', 'rd.__cached__', 'rd.__doc__', 'rd.__file__', 'rd.__loader__', 'rd.__name__', 'rd.__package__', 'rd.__spec__']
>>> for cmd in list(tbl_rd['cmd']):print(cmd);
...
rd.__all__
rd.__builtins__
rd.__cached__
rd.__doc__
rd.__file__
rd.__loader__
rd.__name__
rd.__package__
rd.__spec__
テーブルにマージする予定なので、出力結果の型は事前に確認しておく。統一しておきたい。リスト型に。
辞書からリストは
items関数か
Pythonでリストとタプルと辞書の変換
joinメソッドのところカンマ以外を与えたら、面白そう
sprintf関数はバインド値にリスト型データ取れるの便利そう
テンプーレトに与える引数
>>> for cmd in list(tbl_rd['cmd']):print('='*100);print(exec(re.sub('$','liz=',cmd)+'eval(\''+cmd+'\')'));print(type(eval(cmd)));print(cmd);
...
====================================================================================================
None
<class 'list'>
rd.__all__
====================================================================================================
None
<class 'dict'>
rd.__builtins__
====================================================================================================
None
<class 'str'>
rd.__cached__
====================================================================================================
None
<class 'str'>
rd.__doc__
====================================================================================================
None
<class 'str'>
rd.__file__
====================================================================================================
None
<class '_frozen_importlib_external.SourceFileLoader'>
rd.__loader__
====================================================================================================
None
<class 'str'>
rd.__name__
====================================================================================================
None
<class 'str'>
rd.__package__
====================================================================================================
None
<class '_frozen_importlib.ModuleSpec'>
rd.__spec__