requests-html の tips
先週、 requests-html を触って得た知見を書きます。
今回は基本的に、 AsyncHTMLSession を使いました。
環境
- Python 3.7.1
- requests-html 0.10.0
対象 Web ページ
気象情報番組、ウェザーニュースライブの番組表(タイムテーブル)ページです。
https://weathernews.jp/s/solive24/timetable.html
同サイト内、flash player で動いているページなどもある中、vue を使っている比較的、新し目のページです。
ただ、古いコードも使い回しているようなので、全体的には少し懐かしい感じもするページです。
import と定数
以降のコードの先頭で読み込む import と定数は、冗長になるので先に載せておきます。
import requests
from requests_html import AsyncHTMLSession
URL = 'https://weathernews.jp/s/solive24/timetable.html'
描画待ち
上記のページで使うことはなかったのですが、別のページのスクレイプをしていたときに、
描画に時間がかかっていて、目的の DOM が見つからない現象があったので、
arender() の 引数の wait や sleep を使うとうまくいくことがありました。
def wait_render():
assesion = AsyncHTMLSession()
async def process():
r = await assesion.get(URL)
await r.html.arender(wait=5, sleep=5)
return r
r = assesion.run(process)[0]
print(r.html)
if __name__ == "__main__":
wait_render()
-
waitはページレンダリング前に入るスリープ処理なので、 Content Download の時間が長いとかでタイムアウトしてしまうページなどでは効果があるかもしれません。 -
sleepはページレンダリング後のスリープ処理なので、今回のような DOM 描画待ちとかでは、こちらが効果ありました。
スクリーンショット
requests-html は pyppeteer を内部的に使っているライブラリなので、 pyppeteer でできることは大体できるのかなと思います。
その中でもスクリーンショットは需要ありそうな気がしますので書いておきます。
arender() の引数で keep_page=True を渡してあげると、レンダリング後の page(中身は pypetteer の Page インスタンス) を捨てずに持っていてくれるので、その page でスクリーンショットを取ります。
def screenshot():
assesion = AsyncHTMLSession()
async def process():
r = await assesion.get(URL)
await r.html.arender(keep_page=True)
await r.html.page.screenshot({'path': '/tmp/ss.png'})
return r
r = assesion.run(process)[0]
print(r.html)
if __name__ == "__main__":
screenshot()
取得できた画像(2019/04/25 取得)
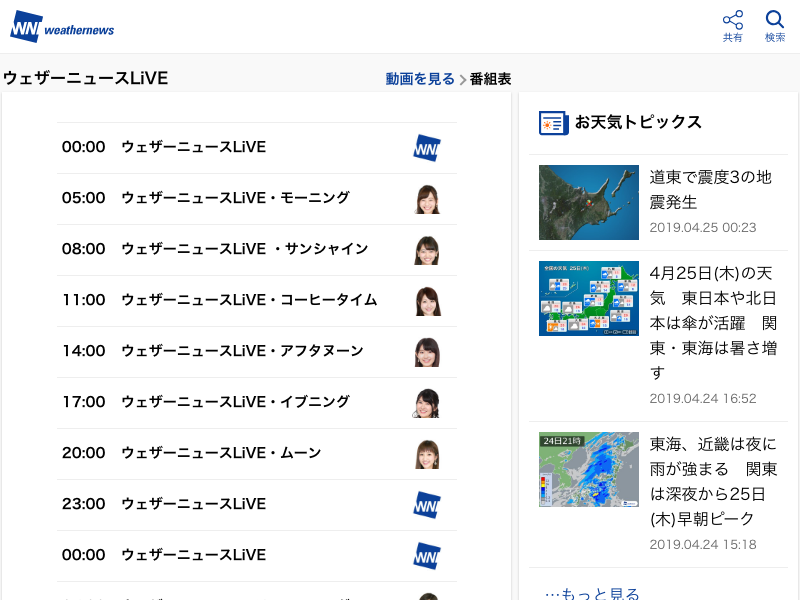
フルページ
pyppeteer の screenshot() のオプションですが、{'fullPage': True} を渡すと、ページ全体のスクリーンショットができます。
def fullpage_screenshot():
assesion = AsyncHTMLSession()
async def process():
r = await assesion.get(URL)
await r.html.arender(keep_page=True)
await r.html.page.screenshot({'path': '/tmp/ss_fullpage.png', 'fullPage': True})
return r
r = assesion.run(process)[0]
print(r.html)
if __name__ == "__main__":
fullpage_screenshot()
取得できた画像(2019/04/25 取得)
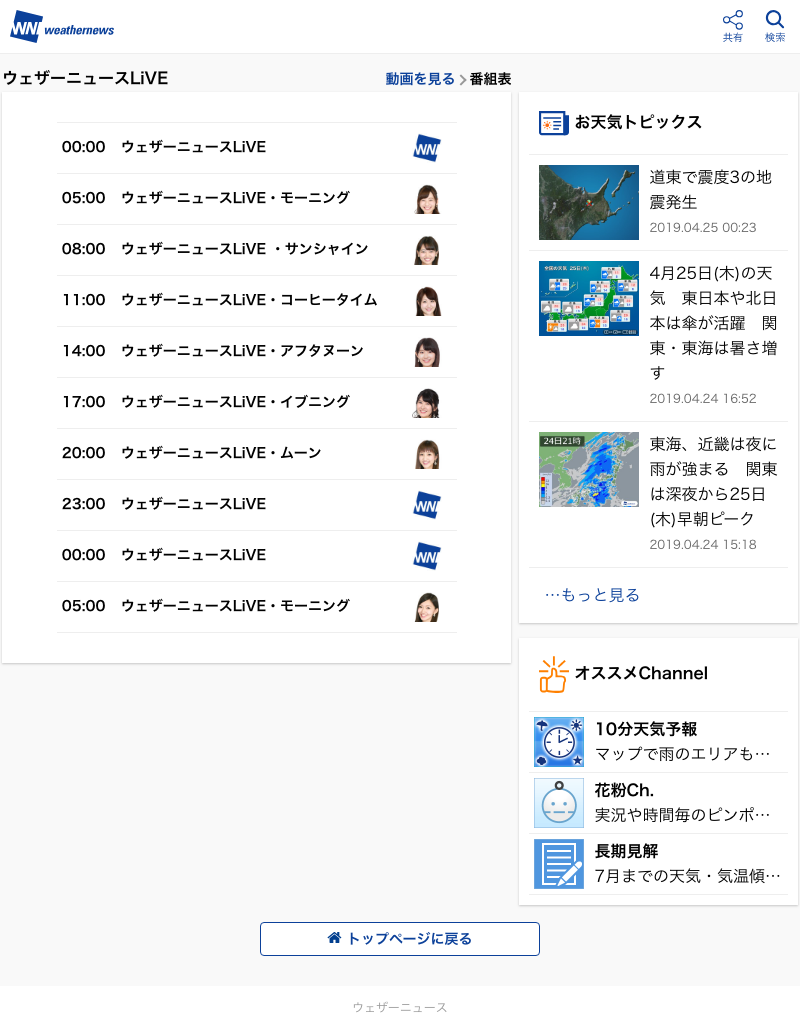
クリップ
arender() の script 引数は実行(evaluate)する js コードを渡して、返り値で結果をもらえるので、DOM にサイズを合わせてクリップということもできます。
def clip_screenshot():
assesion = AsyncHTMLSession()
async def process():
r = await assesion.get(URL)
clip = await r.html.arender(
keep_page=True,
script=(
'''() => {
const rect = document.getElementById('main').getBoundingClientRect();
return {
x: rect.x,
y: rect.y,
width: rect.width,
height: rect.height
};
}'''
),
)
await r.html.page.screenshot({'path': '/tmp/ss.png', 'clip': clip})
return r
r = assesion.run(process)[0]
print(r.html)
if __name__ == "__main__":
clip_screenshot()
取得できた画像(2019/04/25 取得)

javascript の実行
javascript を実行する目的で、その都度 arender() を使うのは内部的に pypetteer の page の goto をしているので、効率が悪いと思います。
一度 arender() した後は page の evaluate() を叩いて実行したほうがよさそうです。
def execute_js():
assesion = AsyncHTMLSession()
async def process():
r = await assesion.get(URL)
await r.html.arender(keep_page=True)
main = await r.html.page.evaluate('document.querySelector("#main").clientWidth')
print(main)
topic = await r.html.page.evaluate(
'document.querySelector("#sub > section.box.pb0").clientWidth'
)
print(topic)
return r
r = assesion.run(process)[0]
print(r.html)
if __name__ == "__main__":
execute_js()
最後に
ここまで書いてて、 pyppeteer を直接使ったほうが良い気もしました。(waitFor 系の API 等もあるので…)
実際に、コードを書いているときも、半分くらいは pyppeteer のドキュメント読んでいました。
でも、requests の API 周り の使い勝手はやはり良いので、雑にやり始めるには良い選択肢だと思います。
おまけ
今回、 requests-html のコードを読んでいて、 typing がちゃんとつけられていておもしろかったです。
requests-html/requests_html.py