これは、言語実装 Advent Calendar 2020 19日目の記事です。
最近は、コンパイラやインタプリタなどの言語処理系や、それに類するものを作る人が増えてきています。(私の周りだけかもしれませんが。)
しかし、もう一歩進んで、コンパイラ基盤を作ってみたという話はあまり聞きません。
コンパイラ基盤は、それの対象とするアーキテクチャについてや、それ自体の使い勝手を考えるのが非常に面白いものです。また、コンパイラ基盤を作る中で、コンパイラや計算機自体についてより深く学ぶことが出来ます。
この記事では、私が開発中のコンパイラ基盤を例として、コンパイラ基盤について語っていきます。
そもそもコンパイラ基盤とは
コンパイラ基盤と言えば、近年色々な所で目にするのがLLVMです。
LLVMを使うことで、コンパイラの複雑で面倒な部分を避けつつ、コンパイラを構成することができるようになりました。
下の図の Common Optimizer の部分を LLVM だと思うと分かりやすいです。コンパイラ作成者は、CやFortranのフロントエンドを作るだけで (正確には、高級言語をLLVMの中間言語に変換するだけで)、様々なアーキテクチャ向けのコード最適化やコード生成ができることになります。
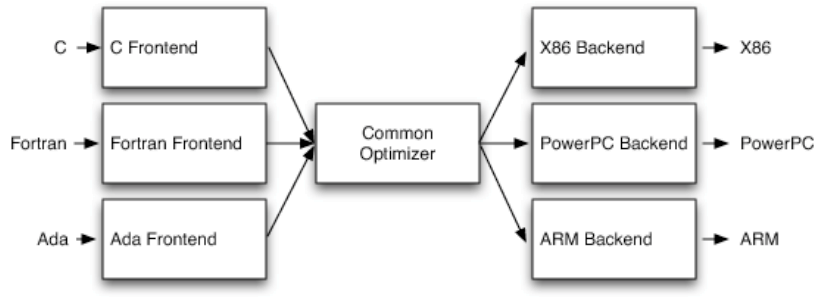
つまりLLVMは、コード生成やコード最適化を肩代わりしてくれるというわけです。コンパイラ作成者は、LLVMの強力な機能を使ってコンパイラを簡単に作ることが可能になります。
ここまでで LLVM の話ばかりしてしまいましたが、コンパイラ基盤には様々なものがあり、COINSといった日本で研究されていたものもあります。また、LLVMはかなり汎用的に使えるものですが、より特化型のもの(Deep Learning 向けの TVM など)もあります。
学術的に面白い内容が沢山あるので、調べてみてください。
コンパイラ基盤を自作する
コンパイラ基盤とは何なのかがぼんやりとわかったところで、実際に私がコンパイラ基盤を作ってみて気づいたことをまとめていきます。以降、私の自作コンパイラ基盤をSericumと呼びます。
コンパイラを以下のような構造だと仮定すると、Sericum はコード最適化以降を担当します。ちょうど LLVM と同じような感じです。
ソースコード → 字句解析 → 構文解析 → 中間表現生成 → コード最適化 → コード生成
きっかけ
そもそも Sericum を作り始めたのは、私が Rust から LLVM API を触っていたときに、不満を感じたことが発端です。
どのような不満かというと、LLVM がたまに SEGV で落ちてしまうのです。もちろん私がLLVMに対しておかしな入力をするのが問題なのですが、GDB を使って何が原因なのかを探るのも大変ですし、IR を Verify しても落ちるし、たまに LLVM 自体のバグに遭遇することもありました。そもそも LLVM が C++ で書かれているからこのような問題が発生するのであって、Rust で書かれていれば問題はないのです。
そんなわけで、勉強もかねて、Sericum を Rust で書き始めたのです。
(実は大学受験の逃避のために作り始めた、というのも理由の一つ)
(ここではひとまずCraneliftのことは置いておきます)
特徴
現在 Sericum はそれほど奇抜な機能を備えていません。
強いて挙げるなら、README にも書いてありますが、中間表現 (IR) をマクロで記述できることができます。以下はフィボナッチ数を返す関数のIRです。これをそのままRustのソースコード中に記述することが出来ます。
このマクロの文法についてはまだ改良中で、今後は余分な括弧などを減らしていこうと思っています。
let fibo = sericum_ir!(module; define [i32] fibo [(i32)] {
entry:
cond = icmp le (%arg.0), (i32 2);
br (%cond) l1, l2;
l1:
ret (i32 1);
l2:
a1 = sub (%arg.0), (i32 1);
r1 = call f [(%a1)];
a2 = sub (%arg.0), (i32 2);
r2 = call f [(%a2)];
r3 = add (%r1), (%r2);
ret (%r3);
});
一応、マクロを使わない場合の例を載せておきます。
// モジュールの生成。モジュールはコンパイルに必要な情報をすべて保持しています。
let mut module = Module::new("sericum");
// 関数の生成
let fibo = module.create_function("fibo", Type::i32, vec![Type::i32]);
// 関数に命令を追加するために、ビルダーを生成
let mut builder = module.ir_builder(fibo);
// 必要な基本ブロックを追加
let entry = builder.append_basic_block();
let block1 = builder.append_basic_block();
let block2 = builder.append_basic_block();
// entryブロックに命令を追加していく
builder.set_insert_point(entry);
let arg0 = builder.get_param(0).unwrap();
let eq = builder.build_icmp(ICmpKind::Le, arg0, 1 /* i32 に Into<Value> が実装されているため、リテラルをそのまま書ける */);
builder.build_cond_br(eq, block1, block2);
// block1ブロックに命令を追加していく
builder.set_insert_point(block1);
builder.build_ret(1);
// block2ブロックに命令を追加していく
builder.set_insert_point(block2);
let arg1 = builder.build_sub(arg0, 1);
let ret0 = builder.build_call(builder.new_func_value(fibo).unwrap(), vec![arg1]);
let arg2 = builder.build_sub(arg0, 2);
let ret1 = builder.build_call(builder.new_func_value(fibo).unwrap(), vec![arg2]);
let add = builder.build_add(ret0, ret1);
builder.build_ret(add);
println!("{:?}", module);
/*
以下のように出力されます
Module (name: demo)
define i32 fibo(i32) {
label.0: // pred(), succ(1,2)
%0 = icmp le i32 %arg.0, i32 1
br i1 %0, %label.1, %label.2
label.1: // pred(0), succ()
ret i32 1
label.2: // pred(0), succ()
%3 = sub i32 %arg.0, i32 1
%4 = call i32 fibo, i32 %3
%5 = sub i32 %arg.0, i32 2
%6 = call i32 fibo, i32 %5
%7 = add i32 %4, i32 %6
ret i32 %7
}
*/
// ここから先は実装が適当になっている
let machine_module = standard_conversion_into_machine_module(module);
let mut printer = MachineAsmPrinter::new();
printer.run_on_module(&machine_module);
println!("{}", printer.output);
/*
以下のように出力されます。最適化パスを追加すれば内容は変わってきます。
.text
.intel_syntax noprefix
.globl fibo
fibo:
.L0:
push rbp
mov rbp, rsp
sub rsp, 16
mov eax, edi
cmp eax, 1
jg .L2
.L1:
mov eax, 1
jmp .L3
.L2:
mov edi, eax
sub edi, 1
mov dword ptr [rbp-4], eax
call fibo
mov edi, dword ptr [rbp-4]
sub edi, 2
mov dword ptr [rbp-4], eax
call fibo
mov ecx, dword ptr [rbp-4]
add ecx, eax
mov eax, ecx
.L3:
add rsp, 16
pop rbp
ret
*/
Module > Function > Basic Block > Instruction のような構造も LLVM を真似しています。
内部構造
Sericum の内部では、IR が様々なパス(様々な変換を行うメソッド)を通りながら低レベルな表現へと変換されていきます。
大まかにまとめると以下のようになります。括弧内の変換について一つづつ見ていきます。
IR → (1. IRに対する最適化) → (2. IRからDAGに変換) → DAG
→ (3. DAGに対するCombine/Legalize/Instruction Selection) → (4. DAGからMachineInstに変換) → MachineInst
→ (5. MachineInstに対する最適化/アーキテクチャ固有の変換) → (6. MachineInstからアセンブリに変換) → アセンブリ
1. IRに対する最適化
IRに対して、基本的にはアーキテクチャ非依存の最適化を行います。現在実装されているのは、
- mem2reg (LLVMのそれと同じ)
- Loop Invariant Code Motion
- (Sparse Conditional) Constant Propagation (Folding)
- Common Expression Elimination
- Dead Code Elimination
- ... その他の細々としたもの
といった基本的なものだけで、まだまだ最適化能力は低いです。PRE とか GVN とか欲しいですね...
2. IRからDAGに変換
IR を DAG (Directed Acyclic Graph) に変換します。
Basic Block 単位なら簡単に DAG へ変換できます。(Cyclicな構造がないので)
DAG表現を使うことで、IRの時よりもパターンマッチがやりやすくなります。
3. DAGに対するCombine/Legalize/Instruction Selection
DAGに対して様々なパターンマッチを行い構造を変換していきます。
Combineでは命令の簡単化や合体を行います。例えば以下のようなものです。
Add x, 0 -> x # 0は足す意味がない
Add 1, x -> Add x, 1 # 変数はLHSへ
BrCond (ICmp EQ, x, y), block1, block2 -> Brcc EQ, x, y, block1, block2 # 2命令での条件分岐を1命令で表現
Legalizeではアーキテクチャ固有の変換のうちの一部を行います (実は Legalize は Instruction Selection と合体させようかと思っています。分ける意味がなくなってしまったので)。例えば以下のようなものです。(細かいことは置いておきましょう)
# x86の場合
(Load (Add base, (Mul off, 4))) -> MOVrm32 [base + 4 * off]
Instruction Selectionでは、その名の通り命令選択を行います。
# x86
Add x, 2 -> ADDrm32 x, 2
Store slot, 2 -> MOVri32 [rbp-XXX], 2
4. DAGからMachineInstに変換
DAG を アセンブリ命令一つひとつを表現する MachineInst の列へと変換します。訳あって、1つのIR命令から複数のアセンブリ命令が生成される場合もこのパスで処理します。(DAGの段階では無視する)
5. MachineInstに対する最適化/アーキテクチャ固有の変換
- PHI 命令の削除
- (必要に応じて)
y = add x, 2をy = x; x = add x, 2に変換する (x86など) - レジスタ割付
- Peephole最適化
- Basic Block の合併・削除
- プロローグ・エピローグ挿入
... などを行います。
6. MachineInstからアセンブリに変換
タイトルそのままです。アセンブリが出力されます。
あとはアセンブルすれば、晴れて実行可能となります。
(実はアセンブラもこつこつと実装しているので、いつかオブジェクトコードを吐けるようになります)
難しかったこと
コンパイラ基盤というものの性質上、実装するうえで難しい部分が多くありました。
特に、アーキテクチャごとに共通化する部分・分離する部分の線引きが難しかったです。(もちろん様々な先例を参考にしましたが)
また、今回は実装にRustを使ったため、それに起因する問題も多く発生しました。
しかしそれらは主に、参考にしたC++のコードがポインタを多用したものであったためで、適切に対処すればRustでも実装できました。大した問題ではなかったのかもしれません。
(参考までに述べておくと、LLVM の SlotIndex などの Linked List 的な構造です)
触ってみたい人へ
Sericum は GitHub 上で公開されています。
さらに、Sericum をバックエンドとして使った簡単な言語が実装してあります。
リポジトリ内の ./minilang には、簡単な文法の小さな言語が実装してあります。小さいながらも、レイトレを実行したりすることができます。
また、./sericumcc には Cコンパイラ が実装してあります。まだ実装途中ですが、./sericumcc/examples を見れば雰囲気が分かると思います。