みなさんこんにちは。この記事はTypeScript Advent Calendar 2020の5日目の記事です。
TypeScriptにはintersection typeという機能があります。これはT & Uのような構文をもつ型であり、意味としては「TでもありUでもある型」です。
構造的部分型とIntersection Type
「TでもありUでもある」という説明の仕方をされるとIntersection Typeが何の役に立つのかピンと来ないという方がいるかもしれません。実際のところ、Intersection Typeはオブジェクト型を合体するという役割によく使われます。
例えば、Tが{ foo: string }型でUが{ bar: number }型だった場合、T & Uは実質上{ foo: string; bar: number }型となります。
type T = { foo: string };
type U = { bar: number };
type I = T & U;
// 代入できる
const obj: I = {
foo: "foo",
bar: 123
};
見方によっては、T & UはTとUの両方のプロパティを併せ持つオブジェクト型であると言えます。実際のところ、このような直観でIntersection型を扱うことが多くあります。
このようになる理由には構造的部分型が関わっています。そもそも、T({ foo: string })型とは「string型のプロパティfooを持つオブジェクト」という意味の型でした。構造的部分型の世界では、この型はfoo以外のプロパティには関与しません。つまり、この型の意味は「string型のプロパティfooを持っていれば他のプロパティは何でもいい」という意味になります。{ foo: "foo", bar: 123 }というオブジェクトもこの条件を満たしているのでT型に当てはまります。同様に、Uも「number型のプロパティbarを持つオブジェクト」という意味です。
T & UはTとUの両方の条件を満たす値の型ですから、具体的な条件は「string型のプロパティfooを持ち、number型のプロパティbarも持つ」となります。{ foo: "foo", bar: 123 }は確かにこれに当てはまりますね。
Intersection Typeとジェネリクス
上のような例はあまり面白くありませんが、ジェネリクスと組み合わせるとすこし意味のある例が作れます。次の例では、イミュータブルなレコード(ImmutableRecord<Data>)を扱うempty関数とset関数を定義しました(declare functionで型定義だけ書き、実装は省略しています)。
declare const recordBrand: unique symbol;
type ImmutableRecord<Data> = {
[recordBrand]: Data
};
/** 新しい空のImmutableRecordを返す */
declare function empty(): ImmutableRecord<{}>;
/**
* 受け取ったImmutableRecordに新しいキーを足してできた
* 新しいImmutableRecordを返す
*/
declare function set<Data, Key extends string, Value>(
map: ImmutableRecord<Data>,
key: Key,
value: Value,
): ImmutableRecord<Data & {
[K in Key]: Value
}>;
/**
* 受け取ったImmutableRecordから指定されたキーの値を返す
*/
declare function get<Data, Key extends keyof Data>(
map: ImmutableRecord<Data>,
key: Key
): Data[Key];
// ImmutableRecord<{}>
const m1 = empty();
// ImmutableRecord<{ foo: string }>
const m2 = set(m1, "foo", "pikachu");
// ImmutableRecord<{ foo: string } & { bar: number }>
const m3 = set(m2, "bar", 12345);
// string
const v1 = get(m3, "foo");
// number
const v2 = get(m3, "bar");
empty関数は空のレコード(ImmutableRecord<{}>型)を作って返します。set関数は今のレコードと新しいデータを受け取って、データが追加された新しいImmutableRecordを返します。getはレコードから指定されたキーのデータを取り出します。
ここで、set関数の返り値の型にIntersection型が使われています。Data & { [K in Key]: Value }というのは、Dataと{ [K in Key]: Value }を合体させたオブジェクト型であると見ることができます。&の右にあるのはmapped typeであり、ここではValueを値とするKeyという名前のキーを一つだけ持つオブジェクト型を表します1。
上の例ではm1はImmutableRecord<{}>であり、次のm2は文字列の値を持つ"foo"というキーが追加されたので、ImmutableRecord<{ foo: string }>となります。これにより、m2はfooというキーを持つことが示されます。
さらに、m3は"bar"も追加されてImmutableRecord<{ foo: string } & { bar: number }>となりました。このように、intersection型を用いることでデータの増加を表すことができます。
上書きの問題と対処法
上のような実装は比較的単純なもので、そのため大きな問題点があります。それは、データの上書きを表現できないということです。上の実装では、次のように同じキーに対して2回setをしたときに前の型と新しい型が混ざってしまいます。
// ImmutableRecord<{}>
const m1 = empty();
// ImmutableRecord<{ foo: string }>
const m2 = set(m1, "foo", "pikachu");
// ImmutableRecord<{ foo: string } & { foo: number }>
const m3 = set(m2, "foo", 12345);
// never
const v1 = get(m3, "foo");
この例ではm3がImmutableRecord<{ foo: string } & { foo: number }>となっていますが、この中のインターセクション型はfooがstring型でもありnumber型でもある、すなわちstring & number型であるという意味になっています。文字列であり数値でもある値は存在しませんから、これは存在しないことを表すnever型に解決されます。よって、上の例のv1の型がneverとなります。
これは求める結果ではありませんね。正しくは、2回目のsetの時点で1回目のfooの型は捨てられるべきです。これを実現するためには、まずDataからfooを消したあとに新しい型を追加する必要があります。これはこのように実装できます。
/**
* 受け取ったImmutableRecordに新しいキーを足してできた
* 新しいImmutableRecordを返す
*/
declare function set<Data, Key extends string, Value>(
map: ImmutableRecord<Data>,
key: Key,
value: Value,
): ImmutableRecord<Omit<Data, Key> & {
[K in Key]: Value
}>;
変更点は、返り値の&の左のDataがOmit<Data, Key>に変わったことです。これは、DataからKeyという名前のキーを消した型という意味です。Omitは標準ライブラリに備わっています。これならば直感通りに動作し、v1はnumber型となります。
// ImmutableRecord<{}>
const m1 = empty();
// ImmutableRecord<Pick<{}, never> & { foo: string }>
const m2 = set(m1, "foo", "pikachu");
// ImmutableRecord<Pick<Pick<{}, never> & { foo: string }, never> & { foo: number }>
const m3 = set(m2, "foo", 12345);
// number
const v1 = get(m3, "foo");
型の見やすさの問題
しかし、ここで新たな問題が出てきました。m3の型を調べてみると、ImmutableRecord<Pick<Pick<{}, never> & { foo: string }, never> & { foo: number }>と書いてあります。行った操作から考えると実態はImmutableRecord<{ foo: number }>のはずですが、Pickや&が出てくる複雑な型となっています。なお、PickはOmitの内部実装で使われている型です。
このように、複雑な操作をすると型が読みにくくなってしまうという問題が、ある程度複雑な型プログラムを書くと顕在化します。型はプログラムの読み手を助ける役割を持っていますから、読みにくい型というのは望ましくありません。
このような問題に対する対処法の一つは、次のように定義されたFlatten型を使うことです。
type Flatten<T> = {
[K in keyof T]: T[K];
};
これはmapped typeを使った型で、オブジェクト型の中身を計算してくれる効果を持ちます。例えば、単純なIntersection型もFlattenで綺麗にすることができます。
type T = { foo: string } & { bar: number };
// type U = { foo: string; bar: number }
type U = Flatten<T>;
このように、2つのオブジェクトのIntersection型に対してFlattenを適用すると、意味が同じ1つのオブジェクト型となり、より見やすくなります。
これをset時のImmutableの中に適用することで結果がより見やすくなりそうです。具体的にはこうですね。
/**
* 受け取ったImmutableRecordに新しいキーを足してできた
* 新しいImmutableRecordを返す
*/
declare function set<Data, Key extends string, Value>(
map: ImmutableRecord<Data>,
key: Key,
value: Value,
): ImmutableRecord<Flatten<Omit<Data, Key> & {
[K in Key]: Value
}>>;
こうすればm3の型もより分かりやすく...
// ImmutableRecord<{}>
const m1 = empty();
// ImmutableRecord<Flatten<Pick<{}, never> & { foo: string }>>
const m2 = set(m1, "foo", "pikachu");
// ImmutableRecord<Flatten<Pick<Pick<{}, never> & { foo: string }, never> & { foo: number }>>
const m3 = set(m2, "foo", 12345);
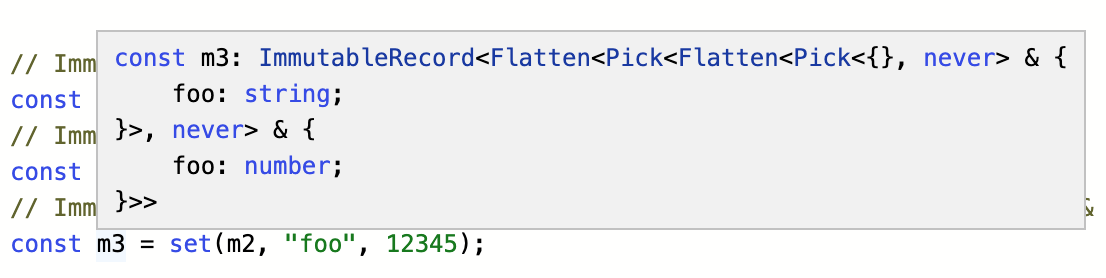
あれ? ![]()
結果を見ると、m3の型にFlattenがそのまま残っていて、結果がきれいになっていません。
このように、Flattenは複雑な型の中では効果を発揮しないことがあります。
自前のMapped Typeを使う
以上の問題に対処するには、Flattenという名前を付けるのをやめて型定義の中で直接mapped typeを使うという手があります。
/**
* 受け取ったImmutableRecordに新しいキーを足してできた
* 新しいImmutableRecordを返す
*/
declare function set<Data, Key extends string, Value>(
map: ImmutableRecord<Data>,
key: Key,
value: Value,
): ImmutableRecord<
Key extends keyof Data
? {
[K in keyof Data]: K extends Key ? Value : Data[K]
}
: {
[K in keyof Data | Key]:
K extends keyof Data
? Data[K]
: Value
}>;
// ImmutableRecord<{}>
const m1 = empty();
// ImmutableRecord<{ foo: string }>
const m2 = set(m1, "foo", "pikachu");
// ImmutableRecord<{ foo: number }>
const m3 = set(m2, "foo", 12345);
// number
const v1 = get(m3, "foo");
ちょっとsetの定義が長くなりましたね。ここでconditional typesが登場しました。この定義では、返り値の型はまずKey extends keyof Dataか道家で分岐します。これは、Keyがkeyof Dataの中に存在する(=Keyが既存のキーである)という条件を表しています。
既存のキーの場合はキーの上書きとなるので、Dataと比べて新しいキーは増えません。よって、{ [K in keyof Data]: ... }というmapped typeを返しています。一方で、新しいキーの場合は{ [K in keyof Data | Key]: ... }というmapped typeを返しています。
こうすることで、m2やm3の型がすっきりしましたね。
実は、この型定義の中に出てきたmapped typeを抜き出して型名を付けると、その部分が計算されなくなってしまい結果の型が分かりにくくなってしまいます。ですから、このようにmapped typesを関数の返り値の型にベタ書きして、型の計算を強制するテクニックが有効です。
まとめ
複雑な型の計算をする際は、計算結果の型の見やすさにまで気を配るとよいでしょう。そのためには、この記事で紹介したようなmapped typesをベタ書きするテクニックが有効です。
筆者はRoconの開発でこのテクニックを用いました。Roconはライブラリなので、型の読みやすさまで含めて分かりやすいインターフェースを提供することはとても重要です。
-
正確には、
Keyがユニオン型のときは1つとは限りません。実はそれだと今回のコードの安全性が壊れてしまうので、この記事では省略していますがユニオン型に対する対策が必要です。 ↩