TypeScriptはJavaScriptに静的型を追加した言語で、コンパイルエラーを検出することでJavaScript開発をさらに快適・効率的にしてくれるものです。
型システムを備えている言語は、多かれ少なかれ何らかの形で型推論を備えています。大ざっぱに言えば、これは型を明示的に書かなくてもコンパイラがいい感じに型を推測して理解してくれる機能です。型推論は静的型付き言語における花型機能のひとつと言ってもよく、色々な言語がそれぞれの特色を持っています。
この記事ではTypeScriptにおける型推論について詳説します。この記事に書いてあることは、TypeScriptを普段から書いている方ならなんとなく理解している内容が多いと思います。しかし、これらの内容がちゃんと言語化されている記事がいまいち見当たらなかったので今回記事を書くことにしました。
※ この記事の内容は執筆時点の最新版のTypeScript (3.5 RC) に基づいています。TypeScriptの型推論は破壊的変更が比較的起こりやすい部分であり、最新版のTypeScriptではこの記事に書いてある通りの動作をしない可能性があります。
※ 解説の内容は--strictオプションを指定した状態を前提としています。このオプションを指定していない場合の挙動はこの記事と異なるところが結構あります。
TypeScriptの型推論の概要
TypeScriptにおける型推論の基本は式の型の推論です。それに付随して、変数の型の推論や関数の型引数の推論、またオーバーロードの解決などが発生します。推論という言葉を聞き慣れない方もいるかもしれませんが、これは必要な情報を何らかの方法で推測し決定することです。推論というのは普通は当てずっぽうではなく、ちゃんと何らかの論理的な方法で決定されます。TypeScriptがどういう方法で型推論を行うのかというのがこの記事のテーマですね。
前提として、JavaScript (TypeScript)は文と式という基本的な概念を持ちます。この2つの違いは、式は評価結果の値があるという点です。
TypeScriptでは(もっと言えば、ほとんどの静的型付き言語では)全ての式に対してその式の型が決定されます。この処理こそが型推論の本体であると言ってもよいでしょう。
非常に簡単な例で説明します。
const a = 2 + 3;
このプログラムにおいて、変数aの型はどうなるでしょうか。それは、aに代入されている2 + 3という式の型をTypeScriptがどう推論するかによって決められます。結論から言えば、aの型はnumberです。つまり、2 + 3という式の評価結果はnumber型の値、すなわち数値になるであろうとTypeScriptが推論したことになります。この推論は、「2や3は数値である」という事実と「+で数値同士を足した結果は数値である」という2つの事実から裏付けられます。
また、次の例ではどうでしょうか。
const a = x + 3;
変数xはあらかじめ定義されているとしましょう。この場合、aの型、つまりx + 3の型はxの中身によって決まります。もしxが"123"という文字列だった場合、JavaScriptの+演算子に文字列と数値を渡した場合は文字列の結合となりますから結果は"1233"となります。つまり、x + 3の型はstring型です。一方で、もしxが456という数値だった場合、+は数値の加算として働きますからx + 3は459となります。よって、x + 3はnumber型です。
この例から分かることは、式の型を推論するためにはその中に登場する変数の型が必要であるということです。x + 3という式の型を推論するためにはまずxの型が分からないといけないのです。このことから、宣言された全ての変数に対してその型を推論する需要が発生します。型推論のそのほかの要素(型引数の推論など)もその目的はすべて「式の型を推論する」ということに集約されます。
では、TypeScriptの型推論の詳細に踏み入っていくことにしましょう。
式の型の推論 (1)
とりあえず、TypeScriptがどのように式の型を推論するのかを見ていきます。ここから先はいろいろな型が登場しますが、もしよく分からない型が出てきたら以下の記事を見てみるのがよいでしょう。
プリミティブリテラルの型
JavaScript/TypeScriptプログラミングにおける最も基本的な要素はリテラルです。リテラルは何らかの値をプログラム上で表現する方法です。例えばabcdeという文字列を表したい場合は"abcde"と書きますね。この"abcde"がリテラル(この場合は文字列リテラル)です。リテラルはプリミティブ値(真偽値、数値、文字列など)を作るリテラルとオブジェクトを作るリテラルに大別できますが、まず前者を見ていきます。
一般的なプログラミング言語では、"abcde"というリテラルは文字列を生み出すので、その型は文字列型(string型)に推論されるでしょう。同様に、234などの数値リテラルはnumber型、trueやfalseは真偽値リテラルなのでboolean型に推論されるというのが一般的な挙動です。
しかし、TypeScriptはそれとは少し違う挙動をします。その理由はリテラル型の存在です。
結論としては、TypeScriptではリテラルの型は対応するリテラル型に推論されます。何を言っているのかよく分からない方のために、例を用いて解説していきます。
単純な例として、以下のプログラムで変数aの型はどうなるでしょうか。この問題はつまり、"abcde"というリテラルの型がどう推論されるかという問題と同じです。
const a = "abcde";
この場合は、aの型は**"abcde"型**になります。分かりにくいですが、stringという名前の型があるのと同様に"abcde"という名前の型があるのです。この型は"abcde"という文字列のみが許される型であり、文字列型(string型)の部分型1です。
基本的に、型推論においてはより厳しい型が推論されるほうが(情報が増えるので)嬉しいです。aが"abcde"型を持つことによって、aは"abcde"という文字列であることが型システム上で保証されます。もしaがstring型だった場合は「aは何らかの文字列である」という情報しか無いことにになり、余計な可能性が発生しているという点で情報が少ないと言えます。
これは文字列リテラルの例ですが、数値リテラル・真偽値リテラルについても同じです。例えば3というリテラルの型は3型であると推論され、trueはtrue型であると推論されます。また、TypeScriptはnull型(nullという値のみが存在する型)も持っており、nullというリテラルもnull型に推論されます2。
組み込み演算子の型推論 (1)
型推論の挙動というのは、言語に存在する各構文がどのようなルールで型を推論されるかによって決まります。ここまで解説したのはプリミティブリテラルに対するルールでしたね(オブジェクトを作るリテラルもあるのですが、都合上それはすこし後回しにします)。
JavaScriptには多くの演算子(特に数値計算関係)がありますので、それに対する型推論を見てみましょう。
算術演算子
-や*などほとんどの数値演算は、まずそのオペランド(演算子の計算の対象となる値)が数値である、すなわちnumber型かbigint型である必要があります。そうでない場合は型エラーが発生します。ここまでの説明ではあまり強調してきませんでしたが、型がおかしい場合に型エラーを発生させるのはTypeScriptの型推論の目的のひとつでありたいへん重要です。
そして、オペランドがnumber型なら結果の型もnumber型となり、オペランドがbigint型なら結果の型もbigint型となります。これは-などの演算子の実際の挙動と一致していますね。まあ、型推論が実際の挙動と一致していなかったら型の意味がないのですが。
ここまでの説明をまとめると次のようになります。
// a は number 型
const a = 123 - 45;
// b は bigint 型
const b = 56n - 789n;
// これは型エラー(オペランドが数値でないので)
const c = "1234" - {};
他に注意すべき点としては、オペランドの片方がnumberで片方がbigintの場合はエラーになるという点です。これは実際のJavaScriptで実行時エラーとなるためそれを防ぐ意味があります。
// これも型エラー
const d = 123n - 45;
また、たとえ結果があらかじめ分かっていたとしても算術演算子の結果がリテラル型になることはありません。上の変数aの例だと、-の左が123型で右が45型であることからaに入るのは78であるのは明らかですが、aの型は78型ではなくnumber型です。なお、123型や45型はnumber型の部分型であることに注意してください。これにより、上で説明した「両辺がnumber型の場合」が適用されるのです。
ここまでは-を用いて説明しましたが、他の算術演算子やビット演算もすべて同様です。
ちなみに、両辺がany型で実際の結果がnumberなのかbigintなのか分からない場合は、演算子の結果はnumber型に推論されます。もしany型の値が実際にはBigIntだった場合に実行時の値が型推論と矛盾してしまいますが、まあanyを使用した時点で型安全性は既に消し飛んでいるので大した問題ではありませんね。
+
一方、+だけは異なる挙動を示します。これは、+が数値の加算だけでなく文字列の連結にも使われることが理由です。-などと同様なのは、両オペランドがnumber型だと結果がnumber型となり、両辺がbigint型だと結果がbigint型になる点です。numberとbigint型を組み合わせるのはやはりエラーです。
// a は number 型
const a = 123 + 456;
// b は bigint 型
const b = 1n + 2345n;
// これは型エラー
const c = 12 + 345n;
// こういうのも型エラー
const d = 123 + null;
その一方、どちらか片方のオペランドがstring型だった場合は結果がstring型になります。面白いのは、この場合はもう片方がどんな値だろうとエラーになりません(ただしsymbol型のみ例外的にエラーとなります)。
// e は string 型
const e = "123" + "456";
// f も string 型
const f = "1234" + null;
// g も string 型
const g = {foo: 123} + "456";
// h も string 型
const h = "123" + function foo() { return 456; };
両辺とも文字列でない場合はこういう変な値を足すことは当然できません。
// これは型エラー
const i = {} + function foo() { return 456; };
また、+のオペランドにany型が来ている場合は、もう一方がstring型であることが判明している場合は+の結果がstringとなり、そうでない場合は+の結果もanyとなります。
単項演算子
単項演算子は数値用(+, -, ~)、真偽値用(!)、そしてインクリメント/デクリメント(++、--)の3種類に大別できます。
数値用の単項演算子は「nullやundefined以外は何でも受け付ける」という特性を持ち、結果はbigint型(オペランドがbigint型の場合)かnumber型(それ以外の場合)になります。この何でも受け付けるという特性は+などが他の型から数値へ変換する目的で使われることがあるからでしょう。
// a は number 型
const a = +"123";
// b も number 型
const b = -"456";
// c も number 型
const c = -{};
// これは型エラー
const d = +null;
// e は number 型
const e = +(3n as any);
ちなみに、負の数のリテラル型に対応できるようにだと思いますが、+や-の結果はリテラル型になることがあります。
// f は 123 型
const f = +123;
// g は number 型
const g = +(+123);
// h は -456 型
const h = -456;
// i は number 型
const i = -(456);
次に!に関しては、オペランドとしてnullやundefined型、unknown型を含めてどんな値でも受け付けることができます(これはif文の条件部分など、真偽値が期待される場面における共通の挙動です)。例外はvoid型であり、この型の値が与えられたときのみ型エラーとなります。
!演算子の結果の値は基本的には常にboolean型ですが、型情報から結果が明らかな場合はtrue型かfalse型が生成されることがあります。
const num: number = 123;
// a は boolean 型
const a = !num;
// b は true 型
const b = !0;
// c は false 型
const c = !123;
// d は boolean 型
const d = !(123 as unknown);
// e も boolean 型
const e = !(0 as any);
// f は false 型
const f = !{foo: 123};
// これは型エラー
const g = !(()=>{}());
インクリメント・デクリメントは算術二項演算子と同じ感じの処理になります。
他にも&&や||や? :などの説明が残っていますが、説明の都合上後回しにします。
変数の型の推論
このあたりで変数の型の推論を解説します。JavaScriptではいくつかの方法で変数を作ることができますが、その中でも型推論が重要になるのが変数宣言(var, let, const)で変数を作る場合です。利便性のために変数宣言で変数を作るときに型註釈を省略できるようになっており、その場合はTypeScriptがその変数の型を推論して自動的に決めてくれます。
変数の型推論における基本的な原則は、変数の型は宣言時に決まる(変数が宣言後にどのように使われるかは型推論において考慮されない)こと、そして一度決まった変数の型は変わらないということです。これが原則ですが、実はこのあといくつか例外が出てきます(後で詳説しますがフロー情報を用いた推論がされる場合です)。それでも、宣言時に型が決まるというのはTypeScriptの基本的な言語デザインですから、そう思っておくのは悪いことではありません。
constの推論
constの場合が一番話が簡単なので、まずそれを解説します。一応説明しておくと、JavaScriptにおいてconstで作られた変数は再代入が不可能となります。変数の中に入っているオブジェクトをいじることに関しては制限はありません。その性質から、constで宣言する場合は必ずconst 変数 = 式;という形で変数の中身を書く必要があります。const 変数;のように宣言だけしておいてあとから代入することはできません。
話は簡単で、その変数に代入されている式の型推論結果が変数の型となります。
// a は 123 型
const a = 123;
// b は number 型
const b = a + 456;
この例では、変数aに代入されているのは123という式で、この式の型推論結果は123型です。よって、aの型は123型となります。また、変数bに代入されているa + 456という式の型推論結果はnumber型です。よって、bの型はnumber型となるのです。
型註釈がある場合
TypeScriptでは、変数宣言はこのように変数の型を型註釈として明示的に宣言することができます。
// 変数 a の型は number 型になる
const a: number = 3;
// これはエラー(宣言に反する値を代入しているので)
const b: number = "foo" + "bar";
このように変数の型が宣言されている場合、TypeScriptはその変数に代入されている値が正しいかどうかを型検査します。すなわち、=の右の式の型を推論して、その型が変数の型に代入可能かを調べます。上の変数aの例では=の右は3という式であり、この式の型は3型と推論されます。3型はnumber型の部分型なので、3型の式は変数aに代入することができます。よって、変数aの宣言ではエラーは起きませんでした。一方の変数bの場合、式"foo" + "bar"の型を推論するとstring型になります。string型はnumber型に代入可能ではありませんから、ここで型エラーが発生します。
また、変数の型は原則として型註釈がそのまま採用されます。というのも、上の例の変数aなどは型註釈がnumberであるとはいえ実際は3であることが分かっているので、3型に変えてしまう手もありそうですね。しかし、TypeScriptが勝手にそのような変更を加えることはありません。
なお、もう慣れてきたかと思いますが、“原則として”ということはやはり例外もあります。それは型註釈がunion型の場合ですが、これについては詳しくは後述します。
varやletの推論
varとletも、型推論上の基本的な扱いはほぼ同様です。この2つの特徴はconstとは異なり再代入があることです。つまり、最初に宣言された後も他の値が変数に代入される可能性があります。
とはいえ、基本はconstの場合と同じで、宣言時に代入された式の型が変数の型となります。とりあえずこの例を見てください。
// a の型は number 型
var a = 123 - 456;
// b の型は string 型
let b = "foo" + "bar";
123 - 456という式の型はnumber型なので、変数aの型はnumber型となります。同様に変数bの型はstring型となります。これはconstの場合と同じで分かりやすいですね。
リテラル型のwidening
お察しとは想いますが、上の例ではわざと簡単な式を避けていました。次のような場合、varやletの結果はconstとは異なるものになります。
// a の型は number 型
var a = 123;
// b の型は string 型
let b = "foobar";
// a は number 型なので別の数値を代入可能
a = 456;
// b も同様
b = "aiu";
constとは異なり、varやletに代入された式がリテラル型の場合はそれらはリテラル型ではない型に変換されます。上の例では、123型はnumber型に、"foobar"型はstring型に変換されました。このように、リテラル型からそれに対応するプリミティブ型に変換される挙動はwidening(型の拡張?)と呼ばれます。
このwideningによって、変数に別の値を再代入することができるようになっています。もし変数aの型がnumber型ではなく123型に推論されていたら、a = 456は型エラーとなってしまい大変不便です(456型の値は123型に当てはまらないため)。
型註釈がある場合
varやletの場合でも変数宣言に型註釈をつけることが可能です。この場合の挙動はconstと同じで、変数の型はその型註釈が尊重されます。もちろんこれはwideningよりも優先されますから、次のようなことが可能です。
// 変数 a は 123 型
let a: 123 = 123;
a = 456; // 456 型の値を 123 型の変数に代入できないのでエラー
varやletに対する型註釈は、さらに広い型を変数につけたい場合も有用です。例えば数値も文字列も入れることができる変数を作りたい場合は、number | string型の変数を作るとよいでしょう。この|を用いた記法はunion型の記法で、これはnumber型でもstring型でもいいということになります。
let a: number | string = 456;
a = "foo";
宣言時に初期化しない場合(型註釈あり)
JavaScriptでは、varやletで変数を宣言だけして宣言時に何も代入しないことも可能です。TypeScriptもこれをサポートしています。
// number 型の変数 a を宣言だけする
let a: number;
if (Math.random() < 0.5) {
a = 123;
} else {
a = 0;
}
console.log(a);
この場合、型註釈にある通り変数aの型はnumber型です。aは宣言された直後のif文の中で数値が代入されますから、実際aには数値が入っていることになりこれは正しいですね。
しかし、aに何も入っていない所が一瞬あってちょっと怪しい感じがします。JavaScriptでは宣言だけして何も代入していない変数はundefinedが入っていますから、if文の前ではaにundefinedが入っていて型に従っていないような気がしますね。
TypeScriptはこの問題にちゃんと対処してくれる機構を持っています。それは、「宣言後に初期化されていない変数を使おうとしたらエラーを出す」という機構です。この例ではif文の前にaを使おうとするとエラーになります。
// number 型の変数 a を宣言だけする
let a: number;
console.log(a); // これはエラー(a に値を代入する前に使用しているので)
if (Math.random() < 0.5) {
a = 123;
} else {
a = 0;
}
console.log(a);
また、aに値が代入されていない可能性があるだけでもやはりエラーです。
// number 型の変数 a を宣言だけする
let a: number;
if (Math.random() < 0.5) {
a = 123;
}
// これはエラー(aに何も代入されていない可能性があるので)
console.log(a);
ちなみに、変数aの型をundefinedを許すように宣言することで、何も代入しないで使うことができます。気がきく仕様ですね。
let a: number | undefined;
if (Math.random() < 0.5) {
a = 123;
}
// エラーにならずにaを使える
console.log(a);
この機構により安心して変数を初期化無しで宣言することができます。コードの可読性の観点からは、初期化無しで変数を宣言するときは型を明示した方が良いですね。
しかし実は、型註釈も無し、初期化も無しという宣言も許されています。その場合、TypeScriptが急に本気を出します。それが次の話題です。
宣言時に初期化しない場合(型註釈なし)
varやletが型註釈無し・初期値無しで宣言されている場合、その変数に対しては代入されるとそれに応じて型が変わるという挙動が有効になります。これは先に説明した「変数の型は宣言時に決まる」の例外となる挙動ですが、主にJSの型チェックにおいて必要となるため実装されています。
ただ、先に述べておきますが、この機能は微妙に危険なので新たにTypeScriptコードを描く場合は利用を避けるべきです。ちゃんと型註釈くらい書きましょう。
では例に移ります。
let a;
// ここでは a は undefined 型
console.log(a);
const u: undefined = a;
if (Math.random() < 0.5) {
a = 123;
} else {
a = 0;
}
// ここで a は number 型
const num: number = a;
console.log(a);
このコードでは変数aを宣言したあと、いきなりaを使用しています。これはエラーにはならず、ここではaはundefined型の変数として扱われます。aは宣言された後に触られていないため、初期値のundefinedが入っていると判断されてundefined型になるのです。
次がポイントです。次のif文ではaに数値が代入されていますが、これによりその後でaがnumber型に変化しています。
このように、型註釈無し・初期値無しで宣言された変数は現在の型と異なる値を代入することができ、それに合わせて変数の型が変わるのです。
次の例のように、必要に応じてunion型が発生することもあります。
let a;
if (Math.random() < 0.5) {
a = 123;
}
// a は number | undefined 型
console.log(a);
この挙動は便利に見えますが、変数の型がころころと変わる(=変数が複数の意味を持つ)のはあまり良いことではありません。初期値をちゃんと指定するか、それができない場合は型を明示するのが良いでしょう。このどちらかをすることで、後から異なる型を代入するのは型エラーとなります。
さらに、この機能に関してはTypeScriptが推論できる範囲にも限界があります。特に関数呼び出しが関わる場合が問題で、この場合は誤った推論結果となる可能性があります。
let a;
// ここでは a は undefined 型
console.log(a);
const u: undefined = a;
change_a();
// ここで a は undefined 型
const num: undefined = a;
console.log(a); // "123" が表示される
function change_a() {
a = "123";
}
change_a()関数はletで宣言された変数aに文字列を代入しています。しかし、change_a()を呼び出す側のコードではその事実が無視され、change_a()を呼び出した後も変数aの型はundefined型となっています。TypeScriptが関数呼び出しの中までは見に行かない上になぜかその場合も自信を失わないため、このような誤った推論が発生してしまいます。
これは安全性と利便性を天秤にかけた結果このような挙動になっているのだと思いますが、危険なことには変わりませんからあまり積極的に使うべきではありません。
まあ、実際のところ宣言される変数のほとんどはconstであり、letで変数を宣言することは多くありません。そのレアケースを突破した上にさらにその変数を関数の中から書き換えるというシェフの気まぐれパスタみたいなコードが生み出されることは稀でしょうから、頭の片隅に置いておけば大丈夫だと思います。
余談:--noImplicitAnyが無しの場合の挙動
上記の「型註釈も初期値もない変数」の型が代入された値に応じて変化するという挙動は、実は--noImplicitAnyコンパイラオプションが有効のときの挙動です。もしこの--noImplicitAnyオプションが無い場合は話はもっと単純で、そのような変数の型はany型となります。
どっちにせよ危険な挙動ですから、やらなければ問題ありませんね。
余談2:型註釈がunion型の場合の挙動
型註釈ありで変数を宣言して、その型註釈がunion型だった場合の挙動は少し特殊です。個人的にはこの挙動は余計なお世話に思えますが、知らないとたまに困りそうなので解説しておきます。
変数の型註釈がunion型の場合で実際の中身がその中のどれに当てはまるのか明らかな場合、註釈を無視して変数の型がそれに固定されます。言葉ではいまいち伝わりにくいと思いますので例を見てください。
const stringOrNull: string | null = "abcde";
// stringOrNull は string | null 型ではなく string 型になる
// よって length プロパティを見たりしてもエラーが起きない
console.log(stringOrNull.length);
この例では、変数stringOrNullにstring | null型という型註釈を付けたにも関わらず、実際の型はstring型になっています。まあ確かに、変数の宣言を見れば実際はstringOrNullにnullが入ったりしないのは一目瞭然ですから、この挙動は分からないでもありません。個人的には型註釈を勝手に無視しないで欲しいですが。
また、let(やvar)で宣言した場合も同様の事象が発生します。
let stringOrNull: string | null = "abcde";
// ここでは stringOrNull は string 型
console.log(stringOrNull.length);
しかもややこしいことに、この場合はstring | nullという型註釈が完全に死んだわけではありません。stringOrNullは最初はstring型ですが、これにnull型の値やstring | null型の値を代入したりできるのです。
let stringOrNull: string | null = "abcde";
// stringOrNull は string | null 型ではなく string 型になる
// よって length プロパティを見たりしてもエラーが起きない
console.log(stringOrNull.length);
// stringOrNull は string 型だが実は null を代入してもよい
stringOrNull = null;
// ここでは stringOrNull の型は null に変わっているのでこれはエラー
console.log(stringOrNull.length)
// 文字列を代入すると string 型に戻せる
stringOrNull = "foobar";
// これはOKになる
console.log(stringOrNull.length);
// string | null に当てはまらないものは代入できない
// のでこれはエラー
stringOrNull = 123;
このように変数に代入すると型が変わるという挙動は先程説明した「letで型註釈も初期値もない場合」と同じですね。今回は型註釈を何も付けない代わりにunion型がついており、その結果代入に制限がかかるようになりました。ある意味で、変数が「読み出し時の型」と「代入時の型」を2つを持っているようなイメージです。実は先程の場合は「代入時の型」がanyであり何でも書き込み可能という扱いになっています。
そして、例は省略しますがこの場合も「関数を呼び出してその中で変数を書き換える場合は安全性が壊れる」という問題がそのまま残っています。前の場合はletに型註釈をつけないことが条件だったのでやる機会が少なそうでしたが、letの型註釈にunion型を書くというのはわりと機会がありそうです。そんなコードを見かけたら警戒レベルを1段階上げたほうがいいかもしれません。
式の型の推論 (2)
さて、結構長いこと説明してきましたが、ここまで登場した型はstring型などのプリミティブ型や"foo"などのリテラル型だけでいまいち面白くないですね。ここからはやっとオブジェクト型が登場します。
一瞬だけ復習しましょう。オブジェクト型というのは次のような記法を持つ型です。
// number 型のプロパティ foo と string 型のプロパティ bar を持つオブジェクトの型
{
foo: string;
bar: number;
}
このようにオブジェクト型の中にはプロパティ名: 型というペアを書くことができます。この他にもインデックスシグネチャや関数シグネチャなどもありますが詳細は型入門に譲ります。
JavaScript・TypeScriptにあまり馴染みがない方のためにちょっと補足しておくと、オブジェクト型において「型名」はあまり重要ではありません。これはクラスベースのオブジェクト指向言語とは対照的です。
クラスベースオブジェクト指向言語の多くは、オブジェクトは「クラス」から作られます。これに伴い、オブジェクトの型はクラスの名前によって表現されます。例えばclass Person {}というクラスがあった場合、new Person()という式はPerson型になります。
しかし、TypeScriptのオブジェクトはクラスとは毛色が違います。オブジェクト型という概念はクラスとは何の関係もなく、例えば{ foo: string; bar: number; }自体がオブジェクトの型となります3。次の例を通してこのことを理解しましょう。
type Hoge = {
foo: string;
bar: number;
}
type Fuga = {
bar: number;
foo: string;
}
// obj は Hoge 型
const obj: Hoge = {
foo: "uwaaaa",
bar: -5,
};
// obj はFuga 型でもある
const obj2: Fuga = obj;
ここで登場したtype文は型に別名をつけることができる文です。ここではHoge型は{ foo: string; bar: number; }型の別名となり、Fuga型は{ bar: number; foo: string; }型の別名となります。
ここで気づいていただきたいことは、Hoge型とFuga型は同じ型であるということです。この2つはどちらも{ foo: string; bar: number; }型を指しています(プロパティの順番が違うのは関係ありません)。
HogeとFugaは全く同じ型です。型に別々の名前が付いているとかそういうことは全く関係ありません。よって、Hoge型の変数objは当然Fuga型として扱うことができます(逆も同じ)。
これからオブジェクト型の話をするにあたって、型にどんな名前が付いているかは関係ないという事実はぜひ覚えておきましょう。当然ながら、このようにオブジェクト型に名前をつけずに使うことも可能です。この例では{ foo: string; bar: number; }型を変数objの型註釈として用いています。
const obj: { foo: string; bar: number; } = {
foo: "uwaaaaaaaa",
bar: -8,
}:
オブジェクトリテラルの型の推論
JavaScript・TypeScriptにおいてオブジェクトを作る主要な方法はオブジェクトリテラルを使うことです。オブジェクトリテラルも当然ひとつの式です。
const obj = {
foo: "hello",
bar: 123,
};
この例において変数objの型はどうなるでしょうか。それはもちろん、{ foo: "hello", bar: 123 }という式の型がどのように推論されるかによって決まります。
実はこの場合、この式の型は{ foo: string; bar: number }型となります。このように、オブジェクトリテラルからはその形に基づいたオブジェクト型が推論されます。この推論は以下のルールで行われます。
- オブジェクトリテラルに対してはオブジェクト型(これを
Rとします)が推論されます。 - オブジェクトリテラルが持つ各プロパティ
prop: exprに対して、推論結果のオブジェクト型Rにもそのプロパティpropが追加されます。 -
Rのプロパティpropの型は式exprの型推論結果となります。ただし、この型はwideningされます。
先ほどの例に沿って確認しましょう。{ foo: "hello", bar: 123 }というオブジェクトリテラルはfooとbarという2つのプロパティを持ちますので、結果のオブジェクト型もfooとbarという2つのプロパティを持った型となります。
オブジェクトリテラルにおけるfooプロパティの中身は"hello"という式であり、この式に対する型推論の結果は"hello"型です。これがwideningされてstring型となるため結果のオブジェクト型のfooプロパティはstring型となります。barプロパティも同様に、123型がwideningされてnumber型となります。これにより、このオブジェクトリテラルに対する型推論の結果は{ foo: string; bar: number; }型となります。
プロパティの型がwideningされる理由は、varやletの場合と同じです。後から中身を変更できるようにということですね。JavaScriptのオブジェクトは(Object.freezeなどを使って変更不可にしない限り)プロパティを後から書き換えることができますから、その需要に対応できるようにこの仕様になっています。wideningが嫌な場合はletのときと同様に型註釈を明示的に書くか、あるいは後述のas constを使いましょう。
配列リテラルの場合
JavaScriptでは配列を作るときに配列リテラルを使用できます。当然これに対しても型推論が働き、推論結果は配列型となります。配列型はnumber[]のように、要素の型が何かという情報を持っています。number[]は全ての要素がnumber型である配列です。
配列リテラルの型推論は、それに含まれる各要素に対して型推論を行い、それに対してwideningを行ったものが要素の型となります。例えば、下の例の配列arrは各要素に対する型推論の結果(1型、234型、-56型)をwideningした結果であるnumberを要素とする配列の型、すなわちnumber[]型となります。
// arr の型は number[] 型
const arr = [1, 234, -56];
arr.push(789); // 数値を追加可能
arr.push("foobar"); // これはエラー
では、[1, "foo", -56]のように複数の型が入り混じった配列リテラルを書いた場合はどうなるでしょうか。この場合は、各要素の型のunion型が取られます。
// arr2 の型は (number | string)[] 型
const arr2 = [1, "foo", -56];
// 任意の数値や文字列を追加可能
arr2.push(789);
arr2.push("foobar");
例によって、これだと困る場合は型註釈の出番です。例えば、配列の要素として数値はOKだけど文字列は"foo"のみOKという場合はこんな型を書きましょう。
const arr: (number | "foo")[] = [1, "foo", -56];
arr.push(789); // これはOK
arr.push("foobar"); // これはエラー
as constによる推論の変化
TypeScript 3.4からはas constという構文が導入されています。これはリテラル(各種プリミティブのリテラル・オブジェクトリテラル・配列リテラル)に後置で付加することができるものです(他の構文にも付加可能ですが意味はありません)。as constが付加されたリテラルは、型推論の挙動が変化します。具体的には以下のような変化があります。
- リテラル型やオブジェクトのプロパティのwideningが発生しなくなります。
- オブジェクトリテラルに対する型推論の結果は各プロパティが
readonlyになります。 - 配列リテラルに対する型推論の結果は
readonlyタプル型となります。
また、この効果はas constが付加されたリテラルそのものだけでなく、その中にあるリテラルに対しても適用されます。つまり、ネストしたオブジェクト・配列リテラルに対してas constを付加した場合、その中の全てのリテラルがas constの適用対象となります。
as constの例はこんな感じです。
// 変数 a の型は string ではなく "foo"
let a = "foo" as const;
// 変数 b の型は { readonly foo: "foobar" }
const b = {
foo: "foobar"
} as const;
// 変数 c の型は readonly ["foo", 123]
const c = ["foo", 123] as const;
基本的にas constを使用する主な目的はwideningを防ぐこととタプル型を簡単に作ることにあります。プロパティがreadonlyになる効果もありますが、そのために使う場面はそんなに多くないと思います。
論理演算子の型推論
&&と||は論理演算子として知られていますが、返り値が常に真偽値であるとは限らないという特徴を持ちます。これらの演算子は常にオペランドのどちらかを返します。a && bという式の場合、aを真偽値に変換してtrueの場合はbが、そうでない場合はaを返します。一方a || bという式の場合、aを真偽値に変換してtrueならばaが、そうでない場合はbを返します。
これを踏まえてa && bやa || bの型推論の結果を考えてみましょう。ここで重要なのはこの式の評価結果として「aとbのどちらかが帰ってくる」という事実です。ここから考えると、これらの型の型推論結果は(aの型) | (bの型)というunion型になりそうですね。
これは基本的には正しいです。例えばこんな例で確かめられます。
const num: number = 123;
// or の型は number | "foobar" 型
const or = num || "foobar";
変数numがnumber型であることを踏まえて考えると、num || "foobar"は、numが0またはNaNの場合は"foobar"を返し、それ以外の場合はnumを返します。よって、num || "foobar"の型はnumber | "foobar"型となります。
余談ですが、constをletに変えると変数orの型はnumber | stringに変わります。union型の中にもwideningが働くわけですね。
では、この場合も考えてみましょう。
const and = num && "foobar";
さっきと同様にこの場合のandの型はnumber | "foobar"となりそうですが、実は少し違います。この場合、andの型は0 | "foobar"型となります。この背景には先ほども述べたとおりnum && "foobar"がnumを返すのはnumを真偽値に変換した結果がfalseになる場合のみであり、具体的には0とNaNしかないことがあります。numはnumber型といっても実際に数値が返ってくるのは0かNaNだけなのでTypeScriptは親切にも型を絞り込んでくれるのです。
残念なことに、TypeScriptはNaNを知らない(正確にはNaNのリテラル型を持たない)という問題があります。今の説明だと型が0 | NaN | "foobar"などにならないといけませんが、実際はNaNの可能性は闇に葬られています4。厳密な安全性を求めるならこれは危険な挙動なのですが、そもそもNaNがロジックに組み込まれている時点で異常事態なのでまあ大目に見てあげましょう。
とにかく、NaNの可能性を忘れるならばこれは良い挙動ですね。上の例の変数andに入る可能性がある数値は0(とNaN)だけであることが型情報に現れています。
ほかに論理演算子がよく使われる場面はnullかもしれない値を扱う場合です。ある変数にオブジェクトが入っているかもしれないしnullが入っているかもしれないというような場合に||を使うことでnullだった場合のデフォルト値を指定できます。この場合も型がいい感じに推論されます。
type MyObj = { foo: string };
const objOrNull: MyObj | null = null;
// obj は MyObj 型
const obj = objOrNull || { foo: "" };
この例で||の左辺はobjOrNull、すなわちMyObj | null型の値ですが、もしnullが入っている場合は||の右側の値が返る(objOrNullが返らない)ため、型推論の結果からnullが排除されています。
このように、||や&&は結構直感通りに型推論を行ってくれて便利です。
その上、実はこいつらはさらに強力な推論能力を秘めています。それが次の話題です。
条件分岐による型の絞り込み
たまには天下り的に例を示してみます。次の例を見てください。
type MyObj = { foo: string; };
let objOrNull: MyObj | null;
if (Math.random() < 0.5) {
objOrNull = { foo: "123" };
} else {
objOrNull = null;
}
// fooの型は string | null
const foo = objOrNull && objOrNull.foo;
ポイントは一番下のobjOrNull && objOrNull.fooという式です。objOrNullがMyObj | null型であることを鑑みるといきなりobjOrNull.fooとするのは型エラーとなるのですが(nullの可能性がある変数に対してプロパティアクセスすることはできないため)、objOrNull && objOrNull.fooとすればエラーは起きません。この理由は、&&の右側の式を型推論するときはobjOrNullの型がMyObj | nullからMyObjに変化しているからです。
このように、TypeScriptは特定の条件において変数の型が変化する挙動を持っています。この挙動は元の型よりも厳しい型(元の型の部分型)になることから型の絞り込み (type narrowing) と呼ばれています。
型の絞り込みが起きるのは条件分岐が発生した場合です。&&は「左側の値を真偽値に変換したらtrueのときのみ右側を評価する」ということですから、これもある種の条件分岐であると見なせます。&&の右側では、「左側の値を真偽値に変換したらtrueだった」という情報を使って良いわけです。
今回&&の左側はobjOrNullでその型はMyObj | nullでした。nullは真偽値に変換するとfalseになる値ですから、&&の右側では「objOrNullがnullである」という可能性は排除されています。ゆえに、&&の右側ではobjOrNullの型からnullを除いてMyObjとなるのです。
このような挙動は&&以外にも発生します。もちろん||も可能ですし、条件演算子? :も型の絞り込みをサポートしています。
さらに、条件分岐といえばif文ですから、if文も当然型の絞り込みができます。
type MyObj = { foo: string; };
let objOrNull: MyObj | null;
if (Math.random() < 0.5) {
objOrNull = { foo: "123" };
} else {
objOrNull = null;
}
if (objOrNull != null) {
// この中では objOrNull は MyObj
// なのでプロパティ foo を参照できる
console.log(objOrNull.foo);
}
また、条件についても色々なものがサポートされています。直前の例ではobjOrNull != nullという判定によってobjOrNullがnullである可能性を排除しました。他の例としては、typeof value === "string"という判定によって変数valueの型がstring以外である可能性を排除するといったことが可能です。
このような「if文の中でだけ型が変わる」のような挙動はフロー解析と呼ばれることもあります。TypeScriptのフロー解析はreturn文もサポートしているため、次のようなコードを書くこともできます。
type MyObj = { foo: string; };
function useMyObj(obj: MyObj | null) {
if (obj == null) {
// objがnullの場合は先にreturnする
return;
}
// ここではobjはMyObj型なのでfooを見ることができる
console.log(obj.foo);
}
TypeScriptではこのようなフロー解析を交えた型推論が便利で、特にunion型との相性が良い機能です。union型は型の表現力を大きく上げてくれるものですから積極的に使っていきましょう。
関数型の推論とcontextual types
この記事をここまで読んだ皆さんはだいぶ疲れているかと思いますが、まだ折り返し地点です。この記事で伝えたいことはまだまだあるのです。続きを読むのは明日とかでも大丈夫ですよ。(でもここまで読んでいいねと思ったらとりあえずいいねボタンを押していただけるとありがたいです。)
次のテーマは関数です。TypeScriptプログラミングにおいて関数は無くてはならない非常に頻出の概念であり、関数と型推論にまつわる色々な話題があります。
関数の型註釈・関数型
基本的な事実として、TypeScriptでは関数宣言時に引数と返り値の型の型註釈を書くことができます。型註釈を全部書いた場合はこんな感じの見た目になります。
function lengthOrDefault(str: string | null, defaultLength: number): number {
return str != null ? str.length : defaultLength;
}
ここで宣言されているlengthOrDefault関数は引数が2つあり、1つ目の引数strの型がstring | nullであること、2つ目の引数defaultLengthの型がnumberであること、そして返り値がnumberであることが型註釈によって明記されています。
また、関数宣言は変数を作ります。上の例の関数宣言は、関数オブジェクトが入ったlengthOrDefault関数を作っていることになりますね。このような変数の型は関数型となります。具体的には、lengthOrDefaultの型は(str: string | null, defaultLength: number) => number型ですね。ここまでは型推論とはそんなに関係ないただの関数型の復習でした。
なお、ここではfunctionによる関数宣言の場合を示しましたが、function式やアロー関数式なども同じです。
戻り値の型の推論
実は、関数の戻り値の型註釈を省略した場合は戻り値の型が推論されます。この推論は、当然ながら関数からreturnされている式の型を推論することで行われます。複数のreturn文がある場合は、どのreturn文からも値が返される可能性があるということで、それぞれの返り値の型のunion型をとったものになります。具体例はこんな感じです。
// foo は (num: number) => "hoge" | "fuga" 型
function foo(num: number) {
if (num >= 0) {
return "hoge";
} else {
return "fuga";
}
}
この例ではreturn文が2つあり、一方では返り値の型が"hoge"型、もう一方では"fuga"型ということで、それらのunionを取った"hoge" | "fuga"型がfooの返り値の型となります。
また、return文が無い関数の場合は返り値の型としてvoid型が推論されます。一方、「return文はあるけどreturnせずに関数が終了する場合がある」という場合はreturnしない部分はundefined型を返すものとして推論されます。下の例の関数は、num >= 0のときは"foo"を返しますがそうでない場合は何もreturnしません。JavaScriptではreturnしない関数はundefinedを返した扱いになりますので、TypeScriptもそれに合わせる形で「この関数はundefinedを返す可能性がある」という推論を行い、それによりundefined型とのunion型が生成されます。
// fooの返り値は "hoge" | undefined 型
function foo(num: number) {
if (num >= 0) {
return "hoge";
}
}
こういう時は勝手にundefinedを推論するんじゃなくてエラーにしてほしいという場合は--noImplicitReturnsオプションを使いましょう。これは--strictに含まれていませんので別途指定が必要です。
引数の型の推論
このように関数の返り値の型は推論できましたが、引数の型についてはそうもいきません。次のように関数の引数の型註釈を省略した場合はエラーとなります(もし--noImplicitAnyを使用していない場合はエラーにはなりませんが、その場合は引数の型がanyに推論されます)。
// これは num に型註釈が無いのでエラー
function foo(num) {
if (num >= 0) {
return "hoge";
}
}
foo(123);
人間が見ればnumの型はきっとnumber型だろうなあという気持ちになりますが、TypeScriptはそういう推論はしてくれません。これは言語設計上の意思決定であり、TypeScriptの型推論アルゴリズムを簡単に(それでも型システム自体が複雑なせいでアルゴリズムも結構こんがらがっていますが)するためにこのような制限がかかっています。
まず、関数の中で引数がどう使われているかは見られません。今回はnum >= 0とあるのでnumがnumber型のような気がしますが、その情報は使われません。これはもちろん、関数の中まで見て引数の型を決めると型推論が複雑化するし遅くなるからです。逆に、関数型言語では関数の中まで見て引数の型を推論するという挙動が多く見られますから、そういう挙動が好きな方は関数型言語をやるとよいでしょう。
また、関数の外にもfoo(123)という呼び出しがありますが、これを見て引数numの型が推論されるようなこともありません。これは「変数の型は宣言時に決まる」という原則により説明できます。それに、いちいちプログラム全体を探索してfooの呼び出しを探してからnumの型を決定するというような挙動はパフォーマンス的に無理があります。TypeScriptでは基本的に“上から下”5にワンパスで型推論を行い前から順番に型を決めていくのです。
余談ですが、引数の型が推論されないというのは型推論時の話であり、TypeScriptが提供するquickfix(型エラーの修正をサジェストする機能)では実は「関数の使われ方を見て引数の型を自動で決める」という機能があります。例えばVSCodeではこれは以下のように使います。
引数の型エラーの部分でquickfixから「使用状況からパラメータの型を推論する」を選択します。
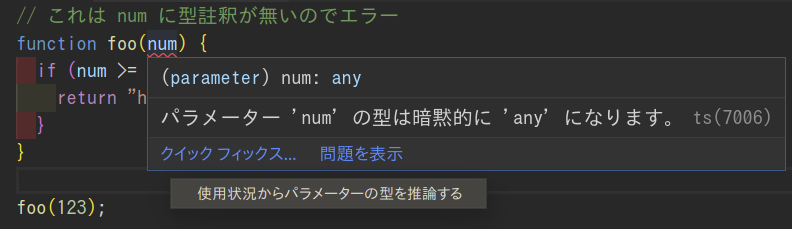
すると、foo(123)からnumの型が類推されてnumberになりました。
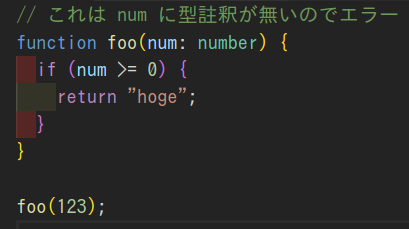
これは、型検査に組み込むほど堅牢ではないけどエラーの修正を補助するには便利なので提供されていると考えられます。
contextual type による引数型の推論
話を戻しますが、とにかく関数の引数はちゃんと型註釈で型を宣言しなければならないというのがTypeScriptの基本的な考え方です。特に、関数の宣言そのものだけから型を決める必要があり、関数の中身とか関数の呼び出し側などそれ以外の部分の情報は使わないようになっています。
これを逆の視点から見ると、関数宣言そのものだけから型が決まりさえすれば無理に引数に型註釈を書かなくて良いということになります。これが、「関数の引数は型註釈を書かなければいけない」の例外となります。では、引数の型註釈がなくても引数の型が分かる場合というのはどういう場合でしょうか。
それは、contextual typeがある場合です。contextual typeを日本語で説明すると「文脈から分かる型」という感じでしょうか。今回も例で説明します。
type Func = (arg: number) => number;
const double: Func = function(num) {
// 引数 num の型は number 型と推論されている
return num * 2;
};
これは変数doubleに代入されているfunction式の引数numに型註釈が無いにも関わらず、エラーになりません。その理由は、変数doubleに型註釈Funcがあるからです。この型註釈によって、「doubleに代入される値はFunc型でなければならない」という情報が生まれます。doubleに代入されるのは=の右側の値、すなわちfunction(num) { return num * 2; }ですから、この式を型推論するときはfunction(num) { return num * 2; }はFunc型でなければならないという条件が与えられていることになります。このように、型推論の時点で期待される型があらかじめ分かっている場合をcontextual typeがあると言います。
contextual typeがある場合は式の型推論の結果がcontextual typeと矛盾しないかチェックすることになりますが、contextual typeの役目はそれだけではありません。そう、関数式の引数の型を推論するときにcontextual typeを使用することができるのです。
今回の場合、function(num) { return num * 2; }の型はFuncであるというcontextual typeがあります。Func型というのは引数がnumber型の関数ですから、それに合致させるためには当然引数numはnumber型でなければいけません。よって、引数numの型がnumber型と推論されるのです。
contextual typeはいくつかの場合に発生します。今しがた見たのは、変数の型註釈によって型推論中の式の型があらかじめ分かっている場合でした。これの応用として、ネストしたオブジェクトでも大丈夫です。
interface MyObj {
foo: (arg: number) => void;
}
const obj: MyObj = {
// ↓この num の型は number 型に推論される
foo: num => console.log(num * 2),
}
この場合は、objに代入されている{ foo: num => console.log(num * 2) }のcontextual typeがMyObj型です。よって、そのfooプロパティであるnum => console.log(num * 2)という式のcontextual typeはMyObjのfooプロパティの型、すなわち(arg: number) => voidとなるのです。
関数引数のcontextual type
もう一つcontextual typeが発生する重要な例は、関数引数の場合です。
function callWith100(callback: (arg: number) => void) {
callback(100);
}
callWith100(num => {
// ここでは num は number 型
console.log(num * 10);
});
callWith100は引数として(arg: number) => void型の値を受け取る関数です。ということは、callWith100を呼び出すときの引数の型は当然この型でなければいけません。ここでcontextual typeが発生しています。
つまり、num => { console.log(num * 10); }は(arg: number) => voidというcontextual typeを伴って型推論されるため、引数numがnumber型と推論できるのです。
この挙動は便利ですが、一つ注意しなければいけない点がありますね。それは、一度コールバック関数を別の変数に入れようとすると上手くいかないということです。
function callWith100(callback: (arg: number) => void) {
callback(100);
}
// ↓これは num の型を推論できないのでエラー
const func = num => {
// ここでは num は number 型
console.log(num * 10);
};
callWith100(func);
この例ではcallWith100の引数を一度変数funcに入れるように変更しただけですが、エラーが発生しています。これは、num => { console.log(num * 10); };が作られた瞬間には変数に入れられるだけでその後funcがどう使われるか分からないためcontextual typeが無いということで説明できます。それくらい推論してくれてもいいじゃんと思わないでもないですが、過去にあったそのような提案は却下されています。
関数返り値のcontextual type
他にcontextual typeが発生する場面として、関数の返り値が型註釈で指定されている場合です。例はこういう感じですね。
type Func = (arg: number) => number;
function makeFunc(val: number): Func {
// ↓引数numはnumber型に推論される
return num => num + val;
}
この例では、関数makeFuncの返り値の型がFuncとされています。よって、return文で返される式にはcontextual typeが働きます。これにより返される関数の引数numの型を書かなくても良くなっているのです。
この3種類がとりあえず思いつくcontextual typeの出現ポイントです。他にもあるかもしれませんが、思いつかないので省略します。原則としては、まあ面倒な推論をしなくてもその場で型が明らかに分かりそうなときにcontextual typeがつきます。
関数呼び出しの型推論
TypeScriptの型推論において中々ややこしいことが起こりがちなのが関数呼び出しです。
とはいえ、普通の関数呼び出しは特に難しいことはありません。例えば下の例では関数funcを引数123で呼び出しています。
const func = (num: number) => String(num * 2);
const str = func(123);
TypeScriptの「原則として関数の型は宣言時に決まる」という性質から、func(123)という式を型推論する段階ではfuncの型は判明済みのはずです。それゆえ、やるべきことはまずfuncがちゃんと関数型かどうかをチェックし、引数の式(123)の型を(contextual type付きで)型推論して、成功したらfunc(123)という式の結果をすでに判明済みのfuncの型の返り値部分にすればいいわけです。
しかし、話がそう簡単には進まない場合があります。ひとつは、型引数がある関数の場合です。
型引数がある関数の場合
型引数というのは、要するにジェネリクスのことです。次の例を使って説明することにします。
function apply<T, R>(value: T, func: (arg: T) => R): R {
return func(value);
}
// res は string 型
const res = apply(100, num => String(num ** 2));
関数applyは2つの型引数T, Rを持つものとして宣言されています。関数宣言時にはTやRはどんな型でもOK(extendsで制限を付けることできますが)なものとして扱われます。つまり、TやRが具体的にどんな型かは、applyを呼び出すたびにその場で決められます。
型引数を明示する場合
TやRが何かを明示するために、呼び出し時に<>で型引数を明示することができます。上の例の型引数を省略せずに書くとapply<number, string>(100, num => String(num ** 2))となります。Tとしてnumber型を、Rとしてstring型を選んだということになります。型引数が明示されている場合はapplyの型が完全に判明しているので特に型推論で難しい点はありません。
型引数の推論
問題は、関数呼び出し時に型引数の指定を省略できる点です。この場合は、TやRといった型引数も一緒に推論されます。これがどのように行なわれるかというと、引数から推論されます。
例えば、applyの型引数Tはどのように推論されるでしょうか。この場合は第1引数にヒントがあります。第1引数valueの型はTですが、呼び出し側ではこの引数に100という値を渡しています。これにより、Tは100を受け付ける型であることが分かり、number型が推論されます。
ポイントは、関数の型を推論するのに引数の型が使用されているということです。引数の100という式に対して先に型推論を行い、それによって型引数Tの値を決定することによって関数の型が判明するのです。
型引数の推論とcontextual typing
ところで、applyの第2引数num => String(num ** 2)は引数numの型註釈を書いていませんが、型情報を見るとnumの型はnumber型と正しく推論されています。これはもちろんcontextual typingのおかげです。
しかし、よく考えるとおかしいのではないでしょうか。今回の場合、numがnumber型であると推論されるためには先に型引数Tの型がnumberであると判明している必要があります。そのためには引数の型推論が既に終わっている必要があります。しかし、第2引数にはcontextual typeが必要であり、そのためには引数の型推論よりも先に型変数の推論ができていないといけません。引数の型推論と型引数の推論、一体どちらが先なのでしょうか。
この問題を解決するためにTypeScriptはひと工夫しています。それはcontextual typingが必要な引数だけ後回しにするというものです。つまり、apply(100, num => String(num ** 2))という式の場合TypeScriptは次のステップを踏んで型推論を行います。
- contextual typingが不要な引数を先に型推論する。ここでは、引数
100に対して型推論を行ってnumber型を得る。 - 得られた情報から型引数を推論する。型変数
Tがnumberに推論される。 - contextual typingが必要な引数を型推論する。引数
num => String(num ** 2)に対して型推論を行って(num: number) => string型を得る。このときcontextual typeは(arg: T) => R型だが、Tはすでに判明しているので(arg: number) => Rとなる。 - 再び型引数を推論する。型引数
Rがstringに推論される。
このようなステップで型引数の推論とcontextual typingによる引数の型推論を両立しています。型引数TとRの推論結果が決まるタイミングが異なることに注目してください。
より正確に言えば、型引数の推論結果は、その型引数が使われた時点で確定します。よって、Tが最終的に確定する瞬間は実はステップ3内です。上記のようにcontextual typeは(arg: T) => Rですが、これを使うと第2引数のnum => String(num ** 2)の部分でnumの引数がTと推論されます。この時点でTの型が具体的に何なのか知る必要が発生したため、Tの型が確定されます(これまでの情報からnumberになります)。
一方、第2引数の型推論において型引数Rの情報は使われていません。それどころか、Rは推論される側ですね。ここではnum => String(num ** 2)の返り値がstring型であることからRはstring型という情報が得られています。この情報は得られていますが、Rの型を具体的に確定させる必要はこのタイミングではまだ発生していません。
Rの型が確定するのは、apply(100, num => String(num ** 2)の返り値の型を決めるときです。宣言によればこの返り値の型はRですが、ここで初めてRの型を具体的に知る必要が発生し、やっとRがstringに決定するのです。
型引数の推論が失敗する場合
以上の説明のように引数の型推論は2段階に分けて行われることがあります。しかし、これが3段階以上になったりすることはありません。したがって、次のような場合は型引数の推論に失敗します。
function apply<T, U, R>(
value: T,
func1: (arg: U) => R,
func2: (arg: T) => U,
): R {
return func1(func2(value));
}
function id<T>(value: T): T {
return value;
}
// 意図はT = number, U = string, R = boolean だが、
// 実際の型引数の推論結果は T = number, U = unknown, R = boolean となる
// その結果、str が unknown 型扱いになり str.length でエラーが発生
const res = apply(100, str => str.length > 0, num => String(num ** 2));
この例ではapplyに渡す関数が2つに増えています。なぜ型推論が失敗するのか詳しく見てみましょう。なお、引数の型推論は前から順番に行われます。
- contextual typingが不要な引数を先に推論する。
100の型推論が行なわれてT = numberという情報が得られる。 - contextual typingが必要な引数を次に推論する。まず第2引数
str => str.length > 0が推論される。このときcontextual typeとして(arg: U) => Rが使われるのでstrの型はUとなる。まだUの情報が無い状態でUを具体化する必要が生じたので、Uはunknown型になる。よって、関数内部の型推論中にstr.lengthでエラーが発生(unknown型の値に対してプロパティアクセスはできないので)。なお、エラーが発生しても一応型推論が続けられてstr => str.length > 0の型は(str: unknown) => boolean型になる。これによりR = booleanという情報が得られる。 - 次に第3引数
num => String(num ** 2)の型推論が行なわれる。今回のcontextual typeは(arg: T) => Uであり、numの型はTとなる。ここでTが確定してnumberになる。
ポイントは、Uの正しい型が判明するのは第3引数の型推論を行った後なのに、それより前の段階でUが必要になったためやむなくunknown型に固定されているという点です。TypeScriptは原則としてワンパスで型推論を行うため、第3引数の推論で正しいUが判明したからといって第2引数の推論をやり直すとかそういう挙動をすることはありません。
ちなみに、引数の順番を入れ替えて次のようにすると型推論が成功します。TypeScriptの型推論結果は処理の順番に依存するということですね。型引数の推論がうまくいかない場合はこのあたりの挙動を頭に入れておくと役に立つでしょう。
function apply2<T, U, R>(
value: T,
func1: (arg: T) => U,
func2: (arg: U) => R,
): R {
return func2(func1(value));
}
function id<T>(value: T): T {
return value;
}
// res は boolean 型
const res = apply2(100, num => String(num ** 2), str => str.length > 0);
オーバーロードされた関数の型推論
引数の型の推論結果が関数の型に影響する場面はもうひとつあります。それは関数がオーバーロードされている場合です。TypeScriptでは関数のオーバーロードという機構があり、これはひとつの関数が複数の関数型を同時に持つという機能です。
function func(arg1: number, arg2: number): number;
function func(arg1: string): string;
function func(arg1: number | string, arg2?: number): number | string {
if (typeof arg1 === "number") {
return arg1 + arg2!;
} else {
return arg1;
}
}
// res1 は number 型
const res1 = func(123, 456);
// res2 は string 型
const res2 = func("foo");
この例ではfunction funcという宣言が3つも並んでいて気持ち悪いですが、よく見ると最初の2つは関数の中身が書いていません。これがオーバーロードシグネチャの宣言です。これが2つあるので、関数funcは2種類の関数型を持っているという意味になります。3つ目が関数の実体の宣言です。
このように宣言されたfuncを呼び出す側が今回のポイントです。2つの数値を引数に渡した場合はfuncの1つ目のシグネチャ((arg1: number, arg2: number) => number)が採用されて返り値がnumber型と推論される一方で、1つの文字列を引数に渡した場合はもう1つのシグネチャ(arg1: string) => stringが採用されて返り値はstring型になります。
これも型引数の場合と理屈は同じで、contextual typingが不要な引数の型を先に推論してfuncのどのシグネチャを採用するか決定、その後でcontextual typingが必要な引数の推論を行うというのが基本的な流れです。
オーバーロードの解決が失敗する例
これを踏まえると、やはり型推論が失敗する例を作ることができます。例えばこんな感じです。
function func(callback1: (arg: number) => number, callback2: (arg: number) => string): string;
function func(callback1: (arg: string) => string, callback2: (arg: string) => number): number;
function func(callback1: any, callback2: any): string | number {
return callback2(callback1(100));
}
// 返り値の x で Type 'number' is not assignable to type 'string'. というエラーが発生
func(x => x, str => Number(str));
この関数funcは、2つ目のオーバーロードを選択すれば正しく型が付けられるはずです。型註釈xもstrもstring型ということにすれば辻褄が合いますね。ところが、これらはどちらもcontextual typingが必要なのでfuncのオーバーロードの解決が失敗し、xとstrはnumber型に推論されます。ただその後のエラーを見ると、x => xの返り値がstring型であることが要求されており、どうやらオーバーロードの再解決が行われているようにも見えます。すみませんが、このあたりの挙動の詳細は筆者にもよくわかっておらず調査中です。
とにかく、実際にこんなオーバーロードがされた関数を書くことはあまり無いとは思いますが、オーバーロードと型引数を組み合わせたりしてややこしいことをすると実際のコードでもたまに型推論が失敗することがあります。基本的にはcontextual typingに頼っていることによる情報不足が原因ですので、適当に型註釈を増やしてやれば大丈夫なことが多いです。
まあ、筆者はそもそもオーバーロードがあまり好きではないのですが(関数定義の内部でだいたい敗北が発生するので)。
ジェネリクスとカリー化された関数に関する注意
関数型言語のバックグランドを持つ人は関数をカリー化したがることがあります。下の例のように、2つの引数を持つ関数をカリー化した場合は1引数関数を返す1引数関数になります。
// 元々の add 関数
const add_original = (left: number, right: number) => left + right;
// カリー化された add 関数
const add = (left: number) => (right: number) => left + right;
// add 関数の使い方
const eight = add(3)(5);
// 「3を足す関数」を作ったりできる
const add3 = add(3);
console.log(add3(10)); // 13
console.log(add3(10000)); // 10003
しかし、型引数を持つ関数をカリー化する場合は注意が必要です。次のようにするとうまくいきません。
// getは 配列 array の index 番目を返す関数
const get_original = <T>(index: number, array: T[]) => array[index];
const get = <T>(index: number) => (array: T[]) => array[index];
const numArr = [1, 2, 3];
// num1 は number 型
const num1 = get_original(1, numArr);
// num2 は number 型ではなく unknown 型になっている
const num2 = get(1)(numArr);
問題は、最後のnum2の型がunknown型になることです。これは、getの型引数Tの推論結果がnumberではなくunknown型になっているということを意味しています。つまり、Tの推論に失敗しているわけですね。
これは、型変数の推論はその関数が呼ばれた瞬間にのみ起こることを意味しています。関数getというのは型引数Tを持ち、indexというひとつの引数を受け取って何らかの関数を返すものでした。ということは、型引数Tの推論はindexというひとつの引数のみを使って行なわれます。端的に言えば、get_originalではindexとarrayという2つの引数を使ってTを推論できたのに、getでは<T>が直接ついている引数がindexだけなのでindexしか利用できないのです。
indexはTとは無関係の引数なのでTの情報は得られません。ということは、getの返り値の型((array: T[]) => T)を具体化する段階でTの情報がないため、ここでTがunknown型に確定します。よって、get(1)の型は(array: unknown[]) => unknownとなります。これがnum2、すなわちget(1)(numArr)の型がunknownとなった理由です。
今回の場合はgetを次のように変更すると意図した挙動に近くなるでしょう。型引数Tのつく位置をずらしてgetが型引数のある関数を返すように変更しました。これにより、Tの推論はarrayが渡されるまで遅延されます。
const get = (index: number) => <T>(array: T[]) => array[index];
// num2 に正しく number 型がつく
const num2 = get(1)(numArr);
その他の細かい挙動
ここまでで、TypeScriptの型推論のルール的なものはおおよそ説明し終わりました。実はまだいくつかの特殊ルールがあるので、ざっと解説していきます。
配列の型推論
配列を構築する場合、以下のようにまず[]を代入してからpushなどを使って要素を追加していくことがありますね。実はこのとき、変数の型が宣言時に決まるというルールを逸脱した挙動が発生します。
const arr = [];
for (let i=0; i<10; i++) {
arr.push(String(i));
}
// ここでは arr の型は string[] 型
arr.push(123);
// ここでは arr の型は (string | number)[] 型
このように、arrに対して行った操作に応じてarrの型が変わっていくという、letとかあの辺で見たような挙動をします。原理は同じです。
注意すべき点は、[]に大して何も要素を追加せずに使用しようとするとarrがany[]扱いになることです(--noImplicitAny下ではエラーとなります)。
const arr = [];
arr[0]; // ここでエラー
const arr2 = arr.slice(); //これもエラー
これが原因のエラーに遭遇することは滅多にありませんが、もしあったら「TypeScriptがバグった」などとは思わずに冷静にarrに型註釈を追加しましょう。
const arr: string[] = [];
arr[0]; // OK
const arr2 = arr.slice(); // OK
高階関数の返り値がジェネリクスになる場合(型引数の受け継ぎ)
TypeScriptの原則の一つとして「型註釈が尊重される」というものがあります。すでにそれが尊重されない例外も紹介していますが、ここではもう一つそんな例を紹介します。それは「関数を受け取って関数を返す」ような関数に対する型推論の場合です。
まずは普通の例です。
function twice<T>(func: (arg: T) => T): (arg: T) => T {
return arg => func(func(arg));
}
const add1 = (arg: number) => arg + 1;
// add2 の型は (arg: number) => number
const add2 = twice(add1);
関数twiceは、T型を受け取ってT型を返す関数funcを受け取って、funcを2回適用する新しい関数を返します。上の例では、受け取った値に1を足して返す関数add1をtwiceに渡すことで、受け取った値に2を足して返す関数add2を得ています。
このtwice呼び出しにおいて型推論はどのように行われているでしょうか。いきなり答えを言ってしまうと、Tがnumber型に推論されます。これは、add1に対して型推論が行われて(arg: number) => number型を得て、それをtwiceの引数(arg: T) => Tと比較することでTがnumberであると結論しています。
型引数の受け継ぎが発生する例
では本題です。上の例を踏まえて次の例を見てください。
function twice<T>(func: (arg: T) => T): (arg: T) => T {
return arg => func(func(arg));
}
const id = <V>(arg: V) => arg;
// idid の型は <V>(arg: V) => V
const idid = twice(id);
今度は関数idをtwiceに渡しています。先ほどとの違いはidが型引数を持つことです。これに対応してtwice(id)の型も<V>(arg: V) => Vとなっていますね。
実はこの**twice(id)の返り値の型こそが原則からの逸脱になっています**。というのも、twiceの関数宣言における返り値の型は(arg: T) => Tなのであって、型引数<V>なんてどこにも書いていませんね。それにも関わらずtwiceにidを渡したときの実際の返り値の型は<V>(arg: V) => Vになっています。
このような挙動は、特定条件下で引数として渡した関数が持つ型引数が返り値の関数に受け継がれるものとして説明できます。
その条件とは、その型引数の具体的な中身の推論が発生しなかったことです。また、他にも返り値の関数型がそれ自身ですでに型引数を持っている場合はだめです。
では詳細を見ていきましょう。twice(id)という関数呼び出しに対する型推論を考えます。idは関数なので、例によってcontextual typeありの型推論が行われます。今回のcontextual typeは(arg: T) => Tです。一方で、idの型は宣言の通り<V>(arg: V) => Vです。これの辻褄を合わせるにはV = Tとすれば良さそうですね。
ここがポイントです。渡された引数idが持っていた型引数Vは、T = Vという情報こそ得られたもののその具体的な型が何かは結局何も情報がないままです。これが「その型引数の具体的な中身の推論が発生しなかった」に相当します。
twice(id)の返り値の型については、宣言では(arg: T) => Tでしたね。型引数の推論からT = Vが分かっているのでこれは(arg: V) => Vになります。さらに、上記の条件を全て満たしているので型引数の受け継ぎが発生し、最終的にこれは<V>(arg: V) => V型となります。
ちなみに、この「型引数の受け継ぎ」はTypeScript 3.4で実装されました。TypeScript 3.3以前ではどうなっていたかというと、返り値の型が(arg: V) => Vとなるところまでは同じですが、最終的にVが具体化されます。Vについては情報が無かったのでVは{}に置き換えられて、twice(id)の返り値の型は(arg: {}) => {}となっていました。
他の例
型引数の受け継ぎが発生する例をもう一つ見ましょう。今度はより変な例です。
function makeDouble<T>(func: (arg: T) => T): (arg: number) => number {
return num => num * 2;
}
const id = <V>(arg: V) => arg;
// fn の型は <V>(arg: number) => number
const fn = makeDouble(id);
makeDoubleは、引数でもらった関数は使わずに(arg: number) => number型の変数を返すという謎の関数です。
これに対しても先ほどと同様の法則が適用された結果、Vが返り値の関数の型に受け継がれて<V>(arg: number) => number型になります。面白いですね。
関数にプロパティを生やす時の型推論
「変数の型は宣言時に決まる」という原則の例外となる挙動をさらにひとつ紹介します。それは関数に後からプロパティを追加できるという挙動です。ちょっと長いですが例を出します。
// 関数を宣言
const func = (num: number) => num ** 2;
// 関数にプロパティを追加できる
func.foo = 123;
// メソッドも追加できる
func.method = (arg: number) => func(arg * 10);
/* func の型は
{
(num: number): number;
foo: number;
method(arg: number): number;
}
*/
useObj(func);
// もちろん関数として使える
func(100);
type MyObj = { foo: number };
function useObj(obj: MyObj) {
console.log(obj.foo);
}
この例では、関数funcを作った後にfooとかmethodとかいうプロパティをfuncに追加しています。普通はオブジェクトの型に存在しないプロパティを勝手に追加するのは型エラーですから、これは関数に独特の挙動ですね。
何でこんな変な機能があるのかとお思いかもしれませんが、JavaScriptでは意外と「関数にプロパティを生やして拡張する」ということをするコードが多いのです(特にCommonJSで関数をエクスポートしたいけど他の機能も提供したい場合など)。そのようなコードに対して昔は問答無用でエラーを吐いていて簡単な解決策もありませんでしたが、頻出なので切り捨てるわけにもいかないという判断からこうなったと考えられます。
機能の危険性
ただ、この機能にはひとつとても残念な点があります。関数の型を変化させるにあたって、letとかとは違ってフロー情報を見ないのです。よって、実際にプロパティが追加される前から型上はプロパティが存在する扱いとなり、このようなプログラムをエラー無く書けてしまいます。
// 関数を宣言
const func = (num: number) => num ** 2;
// func にプロパティを追加する前に使用することができる!!!(危険)
useObj(func);
func.foo = 123;
func.method = (arg: number) => func(arg * 10);
type MyObj = { foo: number };
function useObj(obj: MyObj) {
console.log(obj.foo);
}
なので、安全性を気にする方はこの機能を使っているのを見たら黄色信号です。
安全な代替案
実は、型安全に同じことができる方法があります。それは次のようにObject.assignを使う方法です。
const func = Object.assign(
(num: number) => num ** 2,
{
foo: 123,
method: (arg: number) => func(arg * 10)
}
);
useObj(func);
type MyObj = { foo: number };
function useObj(obj: MyObj) {
console.log(obj.foo);
}
この場合はfuncは((num: number) => number) & { foo: number; method: (arg: number) => number }型となり、型の見た目が違いますがまあ同じ意味です。この方法を使う場合は中途半端な状態のfuncが露出しないので安全というわけです。
機能の有効化条件
この機能は「関数型なら何でもプロパティを追加できる」というものではありません。この機能が有効になるには一定の条件があります。
まず、この機能で拡張できる関数はfunction宣言で作られた関数か、constで変数に代入された関数でなければいけません。つまり、letとかはだめです。
let func = (num: number) => num * 2;
// これはエラー(funcがletで宣言されているので)
func.foo = 123;
const func2 = (num: number) => num * 2;
// これはOK(funcはconstで宣言されているので)
func2.foo = 1234;
// これもOK(func3はfunction宣言で宣言されているので)
func3.foo = 123;
function func3(num: number) { return num * 100; }
なお、constに関しては変数に“直に”代入された関数でなくてはいけません。つまり、const 変数 = 関数式;の形でないとだめだということです。次の例はfuncに入るのは確かに関数であるものの、直に関数式を入れるのではなく配列から取り出しているのでfuncは拡張不可能になります。この“直に”という概念は関数のnameプロパティの話を思い出しますね。
const funcArr = [(num: number) => num * 10];
const func = funcArr[0];
// これはエラー(変数funcに直に関数式が代入されていないので)
func.foo = 123;
また、関数をconstで宣言した場合でも、型註釈があるとだめです。次の例はfuncに型註釈が付いているので拡張不可となります。
type F = (num: number) => number;
const func: F = num => num * 2;
// これはエラー(funcに型註釈があるので)
func.foo = 123;
letの場合といい、変数に型註釈を付けないと特殊なフラグが立つのはちょっと気持ちが悪いような気がしないでもないですね。
型引数のwidening
ジェネリクスの説明に出てきたこの例を思い出してください。
function apply<T, R>(value: T, func: (arg: T) => R): R {
return func(value);
}
// res は string 型
const res = apply(100, num => String(num ** 2));
ここではT型の引数に100が渡されていたのでTがnumber型に推論されていました。よく考えると、ここでTの型に対してwideningが発生していますね。100という式の型は100型なのにいつのまにかnumber型にされています。
実は、型引数がいつでもwideningされるわけではありません。次の例ではTはnumber型ではなく100型になります。つまり、こっちの例では型引数がwideningされていないのです。
function id<T>(value: T): T {
return value;
}
// num は 100 型
const num = id(100);
では、型引数はいつwideningされていつwideningされないのでしょうか。Tという型変数がある場合を考えましょう。実は、以下の条件のどちらかを満たせば型引数Tはwideningされません6。
-
Tにextends stringのようなプリミティブ型による制約(またはextends 1 | 2 | 3のようなリテラル型による制約)がついている。 - 型推論中に
Tの具体的な型が確定しておらず、関数の返り値の型にTがトップレベルで出現する。
トップレベルで出現するというのは、関数の返り値の型がT自身である(T[]とかではない)か、またはTを含むunion型かintersection型であることを言います。
上記のid関数の場合、2を満たしていますね。id(100)という呼び出しではT = 100という情報が得られましたが、他の引数で特にTは使われていないため、戻り値の型を決めるときまでTは確定していません。また、idの返り値の型はTなのでTがトップレベルに出現しています。
試しに「型推論中にTの具体的な型が確定しておらず」という条件を壊してみましょう。
function id<T>(value: T, callback: (arg: T) => void) {
return value;
}
// n の型は number 型
const n = id(100, num => {})
idに特に使われない第2引数を追加しました。こうすると、Tは100ではなくnumber型に推論されるようになります。その理由はidの第2引数num => {}の型推論時にあります。この関数の型推論はcontextual typeがあり、それはidの定義に従えば(arg: T) => voidです。よって、numの型がTとなり、ここでTの具体的な型が必要となるためTが確定させられてしまいます。よって「Tの具体的な型が確定していない」の条件を満たさなくなったためTに対してwideningが発生し、Tはnumber型になるのです。
もうひとつの「関数の返り値の型にTがトップレベルで出現する」のほうを壊すのは簡単です。次のように返り値の型をT[]とかにするとTの推論結果がnumberに変わります。
function id<T>(value: T): T[] {
return [value];
}
// n の型は number[] 型
const n = id(100)
一方、T | nullとかはTがトップレベルに出現している判定になりセーフです。
function id<T>(value: T): T | null {
return value
}
// n の型は 100 | null 型
const n = id(100)
最後にwideningが抑制されるもうひとつの条件「Tにextends stringのようなプリミティブ型による制約(またはextends 1 | 2 | 3のようなリテラル型による制約)がついている」を試してみましょう。次の例はTにT extends numberという制約を付けました。
function id<T extends number>(value: T): T[] {
return [value]
}
// n の型は 100[] 型
const n = id(100)
これは返り値の型がT[]なので2つ目の条件は満たしていませんが、T extends numberがあることでTがwideningされずに100型に推論されています。この挙動の理由は、T extends numberと書いた時点でTとしてリテラル型を期待しているのは明らかであるということからでしょう。どんな数値を渡しても全部Tがnumber型にwideningされてしまうのでは、わざわざ型引数Tを作った意味がありません。
リテラル型が欲しくて型引数を作ったけどうまく推論してくれないという場面にこれから先出会うかもしれませんが、そのときはこの挙動を思い出しましょう。
まとめ
お疲れ様でした。長かった割に、TypeScriptを使いこなしている人にとっては当たり前の内容が多かったかもしれません。この記事で初めて知ったことが多かったという方は、きっとTypeScript力がついたことでしょう。
この記事全体を通して重要なことは、変数や関数の型は宣言された瞬間に決まるという原則です。これにより、TypeScriptの型推論は基本的にワンパスで、つまりプログラムを1度上から下、左から右に見ていくだけで行えるようになっています。これにより推論が失敗してしまう場合もありますが、これはTypeScriptの制限というよりはそういう言語デザインであると考えられます。この制限を克服するためには関数型言語などで採用されている類の本格的な型推論アルゴリズムを導入する必要がありますが、TypeScriptの複雑な型システムの上でそれをやるのは非常に難しいです。
関数の引数の型を(contextual typeにより推論できる場合を除いて)明示しないといけないというのも同じ原則から言えることです。宣言だけ見て関数の型が決まらないのはだめということですね。
ただ、例外もいくつか記事内で紹介しました。letで宣言された関数やフロー解析による絞り込みがそれにあたります。
TypeScriptが型をうまく推論してくれない場合、この記事を理解してTypeScriptの型推論器の気持ちになればその理由が分かるかもしれません。機会があればぜひじっくりと考えてみてください。
最後になりますが、「このよく分からん挙動も解説してほしい」という要望があればぜひコメント欄に書いてください。応えられるかもしれません。
あわせて読みたい
TypeScriptの型シリーズ
-
部分型というのは、ざっくり言えばある型よりさらに条件が厳しい型のことです。
string型は「文字列である」という条件を満たす値が許される型である一方、"abcde"型は「"abcde"である」という条件が必要です。"abcde"は文字列ですから、「"abcde"である」は「文字列である」の十分条件です。よって、"abcde"型の条件を満たす値は全て(といっても"abcde"だけですが)string型の条件を満たすことになります。つまり、"abcde"型の値はstring型の値であると言うことができます。このとき、"abcde"はstringの部分型であると言います。部分型関係に関しては、TypeScriptは構造的部分型を採用しているという点が特徴的です。 ↩ -
undefinedを忘れていると思う読者の方がいるかもしれませんが、実はundefinedはリテラルではなく変数です。undefined型自体はちゃんとあります。 ↩ -
一応JavaScriptにもクラスという概念はありますから、TypeScriptもクラスをサポートしています。実は
class Person {}のような定義を書いた場合、TypeScriptではクラスと同時にPerson型という型を定義したことになります。ただしこれは基本的には後述のような単なるオブジェクト型にPersonという名前を勝手に付けてくれるだけであり、それゆえnew Person()とする以外にもPerson型のオブジェクトを作る方法はあります。 ↩ -
関数宣言はJavaScriptの仕様でhoistingされるので先に処理されたりしますが。 ↩
-
これはTypeScriptコンパイラの
src/compiler/checker.ts内のgetCovariantInference関数のコメントに書いてあります。今回解説していない内容が関わってくる部分は省いていますが。 ↩