この記事はラクス Advent Calendar 2025の22日目の記事です
はじめに
最近PHPのRFCを読む機会がありました。特定のRFCに対して議論が進む様子や、採択が投票で決まる仕組みが面白く、これをコードレビューエージェントでも再現できたら質の高いAIコードレビューを自動化できるのでは?と思いました。
PHPのRFCの議論の様子

Anthropicが公式で提供しているコードレビューのプラグインにも並列実行で複数エージェントがレビューする機構は当然のようにあります。
ただ今回イメージしているのは観点の異なるエージェントを協働させるというより、一つのコードスメルに対して対立構造で議論してくれるものです。
やったこと
PRに対してレビュワーとして用意されたマルチエージェントが自律的に議論するGitHub Actionsを作りました。
仕組み
1. 処理の流れ
ざっくりと以下の流れで運用しています。
PRの作成・更新をトリガーにActionが起動し、マルチエージェントが議論形式で会話しながら、最終的に修正が必要かどうかまで自動で結論を出す構成を目指しました。
2. 実装の詳細
エントリーポイント
action.ymlに定義したbun run src/main.tsが実行されます。
main.tsではレビューフローを管理するReviewOrchestratorを呼び出しています。
差分の取得
ghコマンドで差分を取得しています。トークン節約のため、レビュー対象外ファイルもいくつか定義しました。
取得したdiffはReviewOrchestratorで呼び出され、以下のようにPRの概要と差分情報に整形されます。
Orchestratorはこれを各エージェントのプロンプトとしてClaude APIに送信し、レビューコメントを取得します。
## Pull Request: ログイン機能の追加
ユーザー認証機能を実装しました。
## Diff
## src/auth/login.ts (added)
+50 -0
```diff
@@ -0,0 +1,50 @@
+export async function login(email: string, password: string) {
+ const user = await findUser(email);
+ if (!user) throw new Error("User not found");
+ ...
+}
エージェントの定義
RFCのように活発な議論が起こるよう、役割や得意分野が異なる5つのエージェントを用意しました。いわゆるRole Promptingです。
RFCの議論を再現するなら、専門分野だけでなく立場や性格の違いも取り入れると面白かったかもしれません。とはいえ専門家のRole Promptingの方が一般的なので、今回は冒険せず以下の構成にしました。
| エージェント | 観点 |
|---|---|
| 🔒 Security Expert | 脆弱性、認証、入力検証 |
| ⚡ Performance Expert | パフォーマンス、N+1、非同期処理 |
| 📖 Readability Expert | 命名、構造、可読性 |
| 🏗️ Architecture Expert | 設計パターン、モジュール分離 |
| 🧪 Testing Expert | テストカバレッジ、エッジケース |
レビュー実行
自律的な議論を再現するため、各エージェントが1回目のレビューを行い、その結果をインプットにして2回目のレビューを行う流れにしています。2回目では他のエージェントの指摘に対して賛成か反対かを理由付きで表明させています。
はじめは初回レビューを並列で実行していましたが、APIのレートリミットに引っかかったためやむを得ず直列実行に変更しました。自分の環境だと1分間のinput tokenが30,000に制限されていたようです。GitHub Actionsの失敗履歴は以下↓
2周目のレビューでは1回目のレビュー結果をインプットとして受け取ります。
const initialReviews = await this.runInitialReviews(context, diffContent);
.
.
.
const discussions = await this.runDiscussionRound(initialReviews);
スキーマは以下のように定義しました。
export const DISCUSSION_SCHEMA = {
type: "object" as const,
properties: {
responses: {
type: "array",
items: {
type: "object",
properties: {
expert: { type: "string" },
stance: { type: "string", enum: ["agree", "disagree"] },
reason: { type: "string" },
},
required: ["expert", "stance", "reason"],
},
},
finalVote: { type: "string", enum: ["APPROVE", "REQUEST_CHANGES"] },
finalReasoning: { type: "string" },
},
required: ["responses", "finalVote", "finalReasoning"] as string[],
};
レビュー結果のまとめ
RFCのように多数決で修正可否を判定したかったので、レビュー終了後に指摘ごとの投票結果をまとめるようにしました。
出来上がったもの
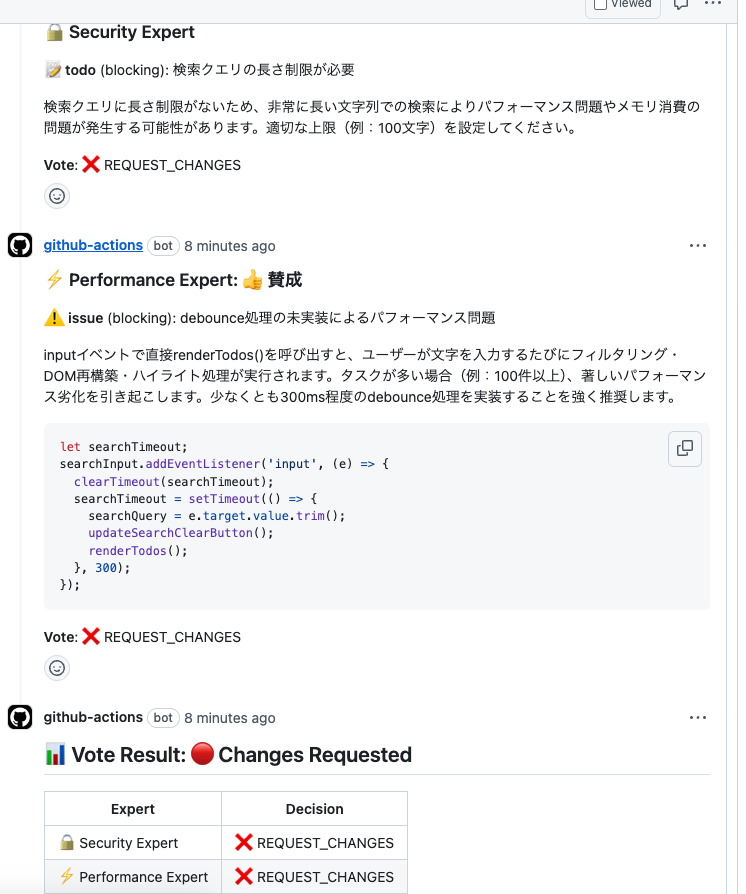
適当に作った別リポジトリのTODOアプリに対してActionを実行してみました。
以下のように一応スレッド形式でコメントを続けてくれています。ところどころ出力がバグっていてイマイチな部分はありますが、最低限の形にはなっていそうです。
ただ、議論しているように見えて期待したような議論にはなっていませんでした。指摘同士が点と点の関係になってしまっていて、結局何がどうなっているのかパッと見では分かりづらかったです。
数字の話
1回のアクション実行にかかるコスト
USD 0.3でした。思ったより安く済んだ印象です。
CIの実行時間
変更ファイル3つ、変更行数+179 −64のPRに対して約4分でした。正直かなり遅いですが、直列実行にしたことを考えると仕方ないかなと思います。
コメント総数
42個でした。議論形式でエージェントが自律的にレビューを完結する構成なので、当然多くなります。正直全部読むのは辛いですね...。
余談ですが、コメントの投稿自体は成功していたものの、CIがなぜかこけていました。was submitted too quicklyとある通り、短時間で大量のコメントが投稿されたため内部リミットに達したようです。
stdout: "{\"message\":\"Validation Failed\",\"errors\":[{\"resource\":\"PullRequestReviewComment\",\"code\":\"custom\",\"field\":\"pull_request_review_thread.base\",\"message\":\"was submitted too quickly\"}],\"documentation_url\":\"https://docs.github.com/rest/pulls/comments#create-a-review-comment-for-a-pull-request\",\"status\":\"422\"}",
stderr: "gh: Validation Failed (HTTP 422)\n",
コンテンツ作成制限レートなるものがあるらしいです。
感想と今後の展望
実行時間やコメントの質を考えると、あまり満足のいく結果にはなりませんでした。モデルにSonnet4を使ったのでその影響もありそうですが、なんとも言えない結果です。
エージェント同士が白熱した議論をしているところを見てみたかったので少し残念でした。
今後改善するなら、自前実装にこだわらずマルチエージェントフレームワークを使う、CodeRabbitやCodexなど複数ツールの併用を検討する、など色々案はありそうです。また気が向いたら遊んでみたいと思います。