背景
最終回である今回は「テーブル設計」についてまとめていこうと思います。
*本記事は私が学習コミュニティで書籍勉強会を企画したときの発表資料です。
企画概要概要は以下の通り。
・スッキリわかるSQL入門を読み、自分なりの解釈でまとめてみる
・メンバー四人で各1章ずつを担当して読み、Qiita等でまとめて発表
・全12章あるので3日程で1周。(今回はラスト第3回目!!)
・著作権/剽窃等は必ず配慮します。もし該当箇所あれば削除/修正しますのでお気軽にご指摘ください。
データベース設計
まずは結論から。
データベースの設計は以下の流れで実施します。
- 概念設計
- 論理設計
- 物理設計
それぞれについて見ていきましょう!!
概念設計
- 要件のヒアリング
SQLが書けるだけではデータベースは作れません。
クライアントがデータベースに求めるものをヒアリングしまとめましょう。
・データベースの目的 (何に使うのか、何を実現したいのか)
・最初に求める機能(基本機能+補助機能) (どういう機能か、あることで助かる機能はなにか)
・将来的に追加したい機能 (将来的に実現したいこと、欲しい機能)
→このヒアリングからエンティティ(情報の塊)を抽出する。
エンティティは複数の属性(attribute)を持っている。
*エンティティ:すごいざっくり言うとデータベースのこと。データの塊と表現される。
*属性:データベースのカラムのこと。
例)以下のようなDBが合ったとして、このテーブルのことをエンティティと捉える
| 日付 | 売上 | 原価 |
|---|---|---|
| 2021-05-04 | 10000 | 3000 |
| 2021-05-05 | 20000 | 6000 |
| 2021-05-06 | 15000 | 4500 |
このエンティティや属性、エンティティ同士のリレーションを俯瞰できるようにしたものがER図なのです!!こういうやつ↓↓
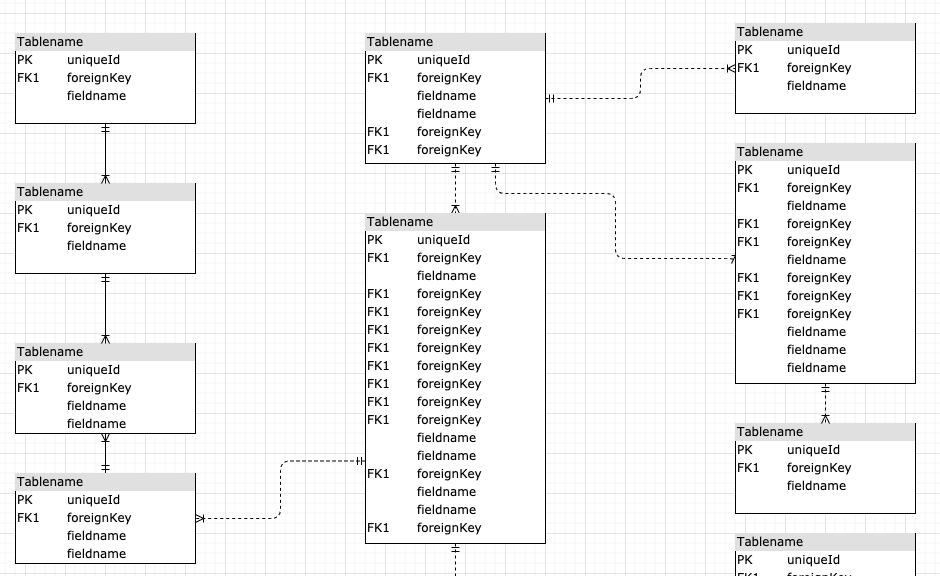
データの関連性とかわかりやすいですよね。
概念設計のまとめ
- クライアントの実現したいことをヒアリングしてまとめる
- まとめた内容からエンティティとして抽出する
- 俯瞰できるようにER図にまとめる
ということだと考えます。
論理設計
上記の概念設計はあくまでも理想の構造です。
RDBにそのまま適用できるとは限らないため、使うデータベースで扱いやすい構造にエンティティを加工する必要があります。
これが論理設計です。
やることはこんな感じ。
・多対多を解消するために1対多に分割する作業
・主キーを整理する。主キーを持たない場合は新たにカラム追加したり、不適切なキーが無いか確認したりします。
*主キーは非NULL性、一意性、不変性の3つの特性を持たせるべきです。
・正規化(データの不整合を排除するためにテーブルを分割する)
論理設計において中心となるものが正規化です。
これはデータが矛盾などの不整合/不都合を排除するために実施します。
手順はざっくりと以下の感じです。(詳しく知りたい場合は書籍を見るか、調べてみてください!)
-
非正規形
整合性が崩れやすい段階。 -
第1正規形
Excelでいうところの1セルに対して1値が必ず入っている状況
= セルの結合などがない状態 -
第2正規形
複合主キーを持つテーブルの場合、複合主キー全体に関数従属すべきである
引用スッキリわかるSQL入門 p.396
どういうことかというと、
日付というカラムと販路というカラムの2つが複合主キーとなっている場合、部分関数従属的に、主キーの片方だけでデータが呼び出せるような状態を排除すべきということです。
関数従属性:片方の値が決まれば関数的に(自ずと)もう片方の値が決まる関係。
片方と説明しているが、複数になる場合もあるので注意
部分関数従属:主キーが社員IDと部門IDである場合に、部門IDのみで部門名がわかること
| 社員ID | 部門ID | 部門名 | 氏名 |
|---|---|---|---|
| 1001 | 1 | 営業部 | Aさん |
| 1002 | 1 | 営業部 | Bさん |
| 2001 | 2 | 開発部 | Cさん |
4. 第3正規形
テーブルの非キー列は、主キーに直接、関数従属すべきである。
引用スッキリわかるSQL入門 p.399
これは推移関数従属いい、以下の表でいうと、社員IDがわかれば部門IDがわかり、部門IDがわかれば部門名がわかるというように、
推移的に関係性がわかるもののことをいう。
| 社員ID | 部門ID | 部門名 | 氏名 |
|---|---|---|---|
| 1001 | 1 | 営業部 | Aさん |
| 1002 | 1 | 営業部 | Bさん |
| 2001 | 2 | 開発部 | Cさん |
要はこれを排除しようぜってことです。
他にも第5正規形まであるらしいので、気になる方は調べてみてください!
物理設計
物理設計は最低限の知識として手順だけ。
本来はDBMS製品ごとのもっと深い知識が必要。
・論理設計後に、DBMS製品の選定する
・最終的なテーブル名/列名(物理名)の決定 (*基本アルファベットっで命名)
・制約、デフォルト値の設定
・インデックスの設定(メンバー記事のSQLのまとめ③(インデックスについて)を参照)
まとめ
・データベースの設計は主に3つのフェーズが存在する(概念/論理/物理)
・概念設計ではクライアントのヒアリング、エンティティ抽出、ER図を行う
・論理設計では主に正規化を行う
・正規化によってデータベースに望ましくないもの(1つのセルに複数データ、部分関数従属、推移関数従属)を排除していく
・最後に物理設計でDBMS製品に論理設計を落とし込む
参考
・スッキリわかるSQL入門
・データベーススペシャリスト試験 正規化を分かりやすく解説 第4回
・AT MARK IT 「関数従属性」を理解する
書籍勉強会の振り返り
今回書籍勉強会を立ち上げるきっかけである課題の「一人で本を読む非効率性」や「アウトプット機会をつくる」部分はクリアできたように思います。
また、他の人を巻き込む積極性/主体性は自分の武器だと再確認できましたし、勉強仲間を増やすことにも繋がったと感じています。
未経験の学習期間中はどうしてもRubyやPHP等の言語勉強に偏ってしまいますが、こういった勉強会を積極的に行って拾いきれないWEB知識を増やすのは有効だと考えたので、またやってみようと思います!!
参加していただいたメンバーに感謝です!!