この記事は「LLM・LLM活用 Advent Calendar 2025」 23日目の記事です。
少し毛色が違いますが、LLMを使っているということでご容赦ください。
コードの実装、記事の添削に生成AIを使用しています。
モチベーション
回帰問題をしていると、内挿とか外挿とか関係ない物理式で表せるといいよなーと思うことが多々ありますよね。僕はあります。その点に対してのソリューションとしてPINNsなども研究がされているのですが、本記事ではシンボリック回帰について実装して簡単な検証をしてみます。
シンプルなシンボリック回帰についてはすでに書いている方がいたので、ドメイン知識を注入できる可能性があるLLM×シンボリック回帰についてやってみます。
こちらの論文を参考にしています。
シンボリック回帰とは
シンボリック回帰とは、説明変数を四則演算・三角関数・log などの演算子で組み合わせ、目的変数を表す数式そのものを探索する手法です。
こちらの記事にあるように式を作るので外挿に強くなるというのがかなりうれしいメリットかなと思っています。
LLMをどう使うか
上述のLLM-Feynmanでは、LLMが持つ知識(エネルギー保存則とかの物理的な知識)を利用して、下記の作業をさせています。
- 特徴量エンジニアリング
- 公式の生成
- 生成した式の評価
- 生成した式の説明
これまで、人が考えていた部分を一部LLMが代替しています。
今回は、公式の生成のみをLLMにお願いしてみます。今回の流れは下記の通りです。
- 各説明変数の単位系と簡単な説明をLLMに渡す
- LLMによる公式の生成
- 生成された式を評価(RMSE)
- 生成された式とRMSEをセットにして、LLMに返す
- 1 ~ 4のループ
精度が上がっていくかどうかを見ていきます。
準備
LLM
- Gemini 2.5 flash
論文中ではFalcon-Mamba-7B、ChemLLM-20B、LLaMA3-8Bなど比較的小さめのモデルを使っていますが、今回は簡単のためGeminiを使ってしまいます。
(論文中ではChemLLM-20Bが最もよかったようです。このLLMは材料科学に特化してファインチューニングされているようなので、サイズが大きいのもありそうですが、LLMを使うにしてもドメイン知識が強力であることがわかります。)
プロンプト
プロンプトはイニシャルプロンプトとフィードバックプロンプトを作りました。
(APIの無料枠を使っていたらすぐにいっぱいになってしまうので注意が必要です。)
- イニシャルプロンプト:式生成のルールと各説明変数の単位系を含む
- フィードバックプロンプト:式生成のルールと各説明変数の単位系と生成された式、その式を使って評価したときのRMSE値
プロンプト
# イニシャルプロンプト
You are a scientific modeling assistant.
Your task is to propose candidate symbolic regression formulas
for predicting concrete compressive strength.
====================
Target variable
====================
Name: Strength
Meaning: Concrete compressive strength
Unit: MPa
====================
Input variables
====================
Cement : Cement content [kg/m^3]
Blast_Furnace_Slag : Blast furnace slag [kg/m^3]
Fly_Ash : Fly ash content [kg/m^3]
Water : Water content [kg/m^3]
Superplasticizer : Superplasticizer content [kg/m^3]
Coarse_Aggregate : Coarse aggregate content [kg/m^3]
Fine_Aggregate : Fine aggregate content [kg/m^3]
Age : Concrete age [day]
====================
Constraints
====================
1. The formula must be dimensionally consistent.
2. Use only the following operators:
+, -, *, /, ^, exp, log
3. All numerical constants must be symbolic parameters:
a, b, c, d, ...
4. The output must be a single scalar expression for strength.
5. Prefer physically interpretable structures:
- water-to-cement type ratios
- aging effects via log(age) or exp(-age)
6. Do NOT estimate parameter values.
====================
Output format (strict JSON)
====================
{
"expressions": [
"expression",
]
}
====================
Important notes
====================
- Do not include explanations.
- Do not include units in the expressions.
- Do not reuse identical expressions.
- Keep expressions relatively simple.
# フィードバックプロンプト
def generate_next_prompt(obses: list) -> str:
"""
Generate the next fixed English prompt for equation proposal.
This prompt MUST preserve all previous equations and their metrics.
"""
header = """
You are an equation discovery assistant for symbolic regression.
Your goal is to propose new candidate mathematical expressions
to predict Concrete Compressive Strength.
You MUST strictly follow all constraints and instructions below.
====================
Observed Equations and Performance
====================
The following equations have already been evaluated.
You must consider ALL of them as factual observations.
Do NOT discard or ignore any equation.
"""
obs_block = "\n### Previous Equations and Evaluation Results\n"
for obs in obses:
eid = obs["OBS"]["expression_id"]
expr = obs["OBS"]["expression_str"]
rmse = obs["metrics"]["rmse"]
obs_block += f"""
- Equation ID: {eid}
Expression: {expr}
RMSE: {rmse:.4f}
"""
descritption_blok = """
====================
Target variable
====================
Name: Strength
Meaning: Concrete compressive strength
Unit: MPa
====================
Input variables
====================
Cement : Cement content [kg/m^3]
Blast_Furnace_Slag : Blast furnace slag [kg/m^3]
Fly_Ash : Fly ash content [kg/m^3]
Water : Water content [kg/m^3]
Superplasticizer : Superplasticizer content [kg/m^3]
Coarse_Aggregate : Coarse aggregate content [kg/m^3]
Fine_Aggregate : Fine aggregate content [kg/m^3]
Age : Concrete age [day]
"""
instruction_block = """
====================
Constraints (STRICT)
====================
1. The formula must be dimensionally consistent.
2. Use ONLY the following operators:
+, -, *, /, ^, exp, log
3. All numerical constants MUST be symbolic parameters:
a, b, c, d, ...
4. The output must be a SINGLE scalar expression for strength.
5. Prefer physically interpretable structures, such as:
- water-to-cement type ratios
- binder-to-water ratios
- aging effects via log(Age) or exp(-Age)
6. Do NOT estimate or assign values to parameters.
7. You MAY use the constant 9.81 [m/s^2] only if physically justified.
8. Do NOT reuse or trivially reparameterize existing equations.
====================
Analysis Guidelines
====================
Internally analyze the observed equations with respect to:
- Structural differences and their performance impact
- Effects of ratios vs logarithmic transformations
- Missing interactions or nonlinearities
- Signs of underfitting or overfitting
This analysis is INTERNAL.
Do NOT output the analysis text.
====================
Task
====================
Based on the observations and constraints above:
- Propose NEW candidate expressions
- Each expression should be structurally distinct
- Prefer simplicity over complexity, unless justified
====================
Output Format (STRICT JSON)
====================
{"expressions": ["expression"]}
"""
return header + obs_block + instruction_block
結果
今回は10回ループを回して、式と誤差(RMSE)の変化を確認します。
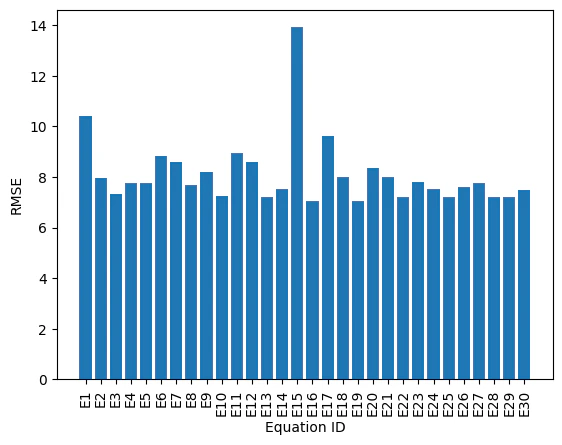
RMSEの遷移
RMSEは微妙に小さくなっていますが、大きな変化はありませんでした。最もRMSEが小さいE19と最も大きいE15の式を見てみようと思います。
式の評価
E19とE15の式は下のとおりです。思ったよりだいぶ複雑な式が出てきました。式中のa, b, c, d, ...は係数です。
例えばE19の一番初めの項
$$\frac{Cement}{Water - b \cdot Superplasticizer}$$
これは無次元の項になっています。Superplaticizerについているbも無次元です。
すべての項を確認するとどうやらすべて無次元になっていそうです。
係数のaとiが目的変数と同じMPaになると考えることができそうです。
E19
a \cdot \left(
\frac{Cement}{Water - b \cdot Superplasticizer}
+ c \cdot \frac{Blast\_Furnace\_Slag}{Water - b \cdot Superplasticizer}
+ d \cdot \frac{Fly\_Ash}{Water - b \cdot Superplasticizer}
\right)^{e}
\cdot \exp\left(
- f \cdot \frac{Coarse\_Aggregate + Fine\_Aggregate}{Cement + Blast\_Furnace\_Slag + Fly\_Ash}
\right)
\cdot \left(g + h \cdot \log(Age)\right)
+ i
E15
e \cdot \frac{Cement + a \cdot Blast\_Furnace\_Slag + b \cdot Fly\_Ash}{Water}
\cdot \left(1 + c \cdot \frac{Superplasticizer}{Water}\right)
\cdot \exp\left(-d \cdot \frac{Coarse\_Aggregate + Fine\_Aggregate}{Water}\right)
+ f \cdot \log(Age)
+ g
式の複雑さ
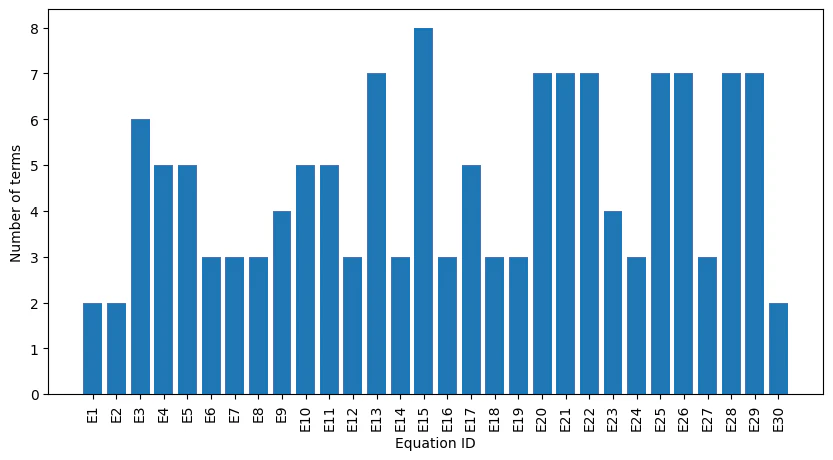
下記の観点で評価します。得られる式は簡単な方が良いという立場に立つことします。
つまり、項は少ないかつ、1つの項に使われている変数も少ない方が良いという立場をとります。
項の多さ
RMSEが小さかったE19は項も少なくていい感じですが、E15は項も多いし、RMSEも大きいしで散々な結果です。
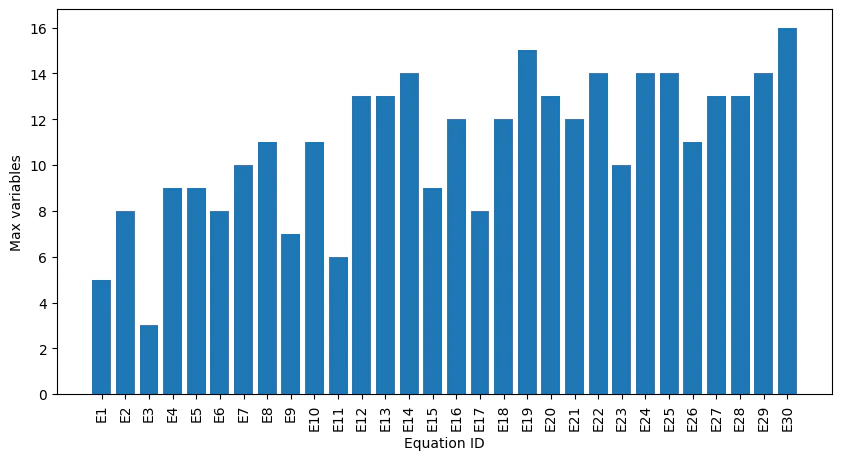
1つの項で使われている変数の数
こちらはE19>E15になりました。E19は項の数は少ないが1つの項がめちゃくちゃ長い、E15は項の数は多いが1つの項は短い、つまり1つの項に情報を詰め込むか詰め込まないかの違いが出ていそうです。
また、2つのグラフをみると、なんとなく3つ単位で項が多い/少ない、1つの項に入る変数が多い/少ないが混ざっていそうです。1回の出力で3式ずつ出力してくれたので、その3つの中で式の複雑さについても試行錯誤しようとしてくれた跡かもしれません。
まとめ
今回、LLMを使ったシンボリック回帰を試してみました。単位系を明示的に与えることができるというのは物理的にかなりメリットになってくると感じました。
また、今回フィードバックとしてRMSEしか渡しませんでしたが、
- 式の複雑さ
- 単位系が一致しているか
- どの項の感度が高いか
などいろいろ渡せる情報はいろいろ考えられるかなと思っています。その時、単純に増やしてしまうとプロンプトが長くなっていく一方なので、そこの渡し方というのも1つ工夫できる点かなと思います。
紹介していた論文はこの記事よりもっとちゃんとしていてGithubやWebアプリも公開していた(たぶん)と思うので興味がわいたら見てみてください。
全実装
# 関数
def llm_io(model, prompt):
response = model.generate_content(prompt)
return json.loads(response.text)
def build_expression_with_unit_check(
expression: str,
variable_units: Dict[str, Unit],
parameter_units: Dict[str, Unit],
target_unit: Unit,
):
tree = ast.parse(expression, mode="eval")
checker = UnitChecker(variable_units, parameter_units)
expr_unit = checker.visit(tree.body)
if expr_unit != target_unit:
raise ValueError(
f"Final unit mismatch: {expr_unit} != {target_unit}"
)
return tree
class CoefficientOptimizer:
def __init__(
self,
expression_func: Callable,
parameter_names: List[str],
):
self.expression_func = expression_func
self.parameter_names = parameter_names
def fit(
self,
X: Dict[str, np.ndarray],
y: np.ndarray,
initial_params: Dict[str, float] | None = None,
) -> Dict[str, float]:
"""
係数最適化
"""
if initial_params is None:
initial_params = {p: 1.0 for p in self.parameter_names}
x0 = np.array([initial_params[p] for p in self.parameter_names])
def residual(theta):
params = dict(zip(self.parameter_names, theta))
y_pred = self.expression_func(X, params)
return y_pred - y
result = least_squares(residual, x0)
return dict(zip(self.parameter_names, result.x))
def score(
self,
X: Dict[str, np.ndarray],
y: np.ndarray,
params: Dict[str, float],
metric: str = "mse",
) -> float:
y_pred = self.expression_func(X, params)
if metric == "mse":
return float(np.mean((y - y_pred) ** 2))
if metric == "rmse":
return float(np.sqrt(np.mean((y - y_pred) ** 2)))
raise ValueError(f"Unknown metric: {metric}")
def normalize_expression(expr: str) -> str:
return expr.replace("^", "**")
def evaluate_formula(df, data, valiable, i):
PARAMETER_PATTERN = re.compile(r"\b[a-z]\b") # a, b, c, ...
obses = []
for j, expr in enumerate(data["expressions"]):
parameters = PARAMETER_PATTERN.findall(expr)
expr = normalize_expression(expr)
f = build_expression(
expression=expr,
variable_names=valiable,
parameter_names=parameters,
)
optimizer = CoefficientOptimizer(
expression_func=f,
parameter_names=parameters
)
params = optimizer.fit(df[valiable], df["Strength"])
# 4. 評価
mse = optimizer.score(df[valiable], df["Strength"], params)
rmse = optimizer.score(df[valiable], df["Strength"], params, metric="rmse")
obs = {
"OBS": {
"expression_id": f"E{i*3+j+1}",
"expression_str": expr,
},
"metrics": {
"rmse": float(rmse),
"mse": float(mse),
}
}
obses.append(obs)
return obses
def generate_next_prompt(obses: list) -> str:
"""
Generate the next fixed English prompt for equation proposal.
This prompt MUST preserve all previous equations and their metrics.
"""
header = """
You are an equation discovery assistant for symbolic regression.
Your goal is to propose new candidate mathematical expressions
to predict Concrete Compressive Strength.
You MUST strictly follow all constraints and instructions below.
====================
Observed Equations and Performance
====================
The following equations have already been evaluated.
You must consider ALL of them as factual observations.
Do NOT discard or ignore any equation.
"""
obs_block = "\n### Previous Equations and Evaluation Results\n"
for obs in obses:
eid = obs["OBS"]["expression_id"]
expr = obs["OBS"]["expression_str"]
rmse = obs["metrics"]["rmse"]
obs_block += f"""
- Equation ID: {eid}
Expression: {expr}
RMSE: {rmse:.4f}
"""
descritption_blok = """
====================
Target variable
====================
Name: Strength
Meaning: Concrete compressive strength
Unit: MPa
====================
Input variables
====================
Cement : Cement content [kg/m^3]
Blast_Furnace_Slag : Blast furnace slag [kg/m^3]
Fly_Ash : Fly ash content [kg/m^3]
Water : Water content [kg/m^3]
Superplasticizer : Superplasticizer content [kg/m^3]
Coarse_Aggregate : Coarse aggregate content [kg/m^3]
Fine_Aggregate : Fine aggregate content [kg/m^3]
Age : Concrete age [day]
"""
instruction_block = """
====================
Constraints (STRICT)
====================
1. The formula must be dimensionally consistent.
2. Use ONLY the following operators:
+, -, *, /, ^, exp, log
3. All numerical constants MUST be symbolic parameters:
a, b, c, d, ...
4. The output must be a SINGLE scalar expression for strength.
5. Prefer physically interpretable structures, such as:
- water-to-cement type ratios
- binder-to-water ratios
- aging effects via log(Age) or exp(-Age)
6. Do NOT estimate or assign values to parameters.
7. You MAY use the constant 9.81 [m/s^2] only if physically justified.
8. Do NOT reuse or trivially reparameterize existing equations.
====================
Analysis Guidelines
====================
Internally analyze the observed equations with respect to:
- Structural differences and their performance impact
- Effects of ratios vs logarithmic transformations
- Missing interactions or nonlinearities
- Signs of underfitting or overfitting
This analysis is INTERNAL.
Do NOT output the analysis text.
====================
Task
====================
Based on the observations and constraints above:
- Propose NEW candidate expressions
- Each expression should be structurally distinct
- Prefer simplicity over complexity, unless justified
====================
Output Format (STRICT JSON)
====================
{"expressions": ["expression"]}
"""
return header + obs_block + instruction_block
def make_feedback(obses):
sorted_obs = sorted(obses, key=lambda o: o["metrics"]["rmse"])
best = sorted_obs[0]
others = sorted_obs[1:]
fb_prompt = generate_next_prompt(obses)
return fb_prompt
# モデルの準備
model = genai.GenerativeModel(
'gemini-2.5-flash',
generation_config={"response_mime_type": "application/json"}
)
file_path = "llm\\prompts\\initial_prompt.md"
with open(Path(path, file_path), "r", encoding="utf-8") as f:
init_prompt = f.read()
# データの読み込み
df = pd.read_csv(Path(path, "data", "raw", "concrete_data.csv"))
valiable = [c.replace(" ", "_") for c in df.columns if "Strength" not in c]
df.columns = valiable + ["Strength"]
variable_values = {c:df[c].values for c in valiable}
# ループ
limit = 10
obses = {}
for i in range(limit):
if i == 0:
init_data = llm_io(model, init_prompt)
obses = evaluate_formula(df, init_data, valiable, i)
else:
fb_data = llm_io(model, fb_prompt)
_obses = evaluate_formula(df, fb_data, valiable, i)
obses.extend(_obses)
fb_prompt = make_feedback(obses)
time.sleep(30)