みなさんSQL書いてますか?
今回は、私が遭遇したアクロバティックなSQLに関する話です。
人が書いたものであったり、若き日の私がこねくり回したりしたものを例にしています。
カウント
「ある条件に合致するレコード件数をカウントしたい」というのは、SQLで最初に習うことの一つかもしれません。
-- 部署が101の従業員を取得
select count(*) from emp where deptno = '101';
みたいなやつですね。
一方、このパターンがすすむと、「全体の件数と一緒に条件ごとの件数も表示したい」というケースがあったりします。
条件A,B,Cそれぞれの全体に対する割合を知りたいときなんかに使ったりします。
「部署101と102の従業員は、それぞれ全体の何%か」
みなさんはどのようなクエリを書くでしょうか。
私は普段こう書いています。
select
count(*) total,
sum(deptno = '101') c_101,
sum(deptno = '102') c_102
from emp;
sum の中身に条件を入れることで、条件に合致する場合は1、合致しない場合は0となり、それらの合計が条件にヒットするレコードの件数になる感じです。
ただ、他の流儀もあるらしく、以下はそれに該当する、私が最初に見た時にパッと見なぜこれで正しく取れるのか理解できなかったクエリです。
select
count(*) total,
count(deptno = '101' or null) c_101,
count(deptno = '102' or null) c_102
from emp;
count 自体は中身が1であろうが0であろうが数え上げてしまいますが、中身が null の時のみ、件数にカウントされません。で、中身を見てみると、条件に合致しないときは or null によって null が返ってくるため、意図したカウントができる、ということですね。
SQLの仕様と論理演算が分かっていないと、何故これで動くのか理解できないクエリでした。
連続判定
SQLでやるなよシリーズその1です。
はるか昔、SQLを扱い始めたばかりのアルバイト時代に、「連続してイベントが続く日数の分布をカウントしたい」ということがありました。
アクセスログみたいなものをサマリーした結果、
手元の環境にユーザ別・日別テーブル(user_id, access_date で unique key なテーブル)
みたいなものを作って格納していたのですが、
- ユーザーごとに、アクセスイベントがある日を、今日から一日ずつ遡っていった結果、連続して何日まで遡れるか
例えば、1週間連続でアクセスしている人は○人、2週間連続でアクセスしている人は○人、
みたいなことを、SQLで集計しようとしていました。
図にすると以下のようなものです。
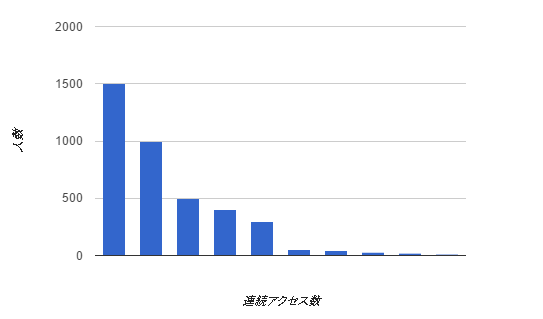
普通に考えるとSQLの select 句一発で、同一テーブル内のレコードが隣り合っているかどうか、
といったことを調べるのは明らかに間違った使い方なんですが、何とかこねくり回して実現しました。
select
datediff(current_date, last_c.last_c_date) c_day, -- 連続アクセス数別にグルーピング
count(*)
from
(
select
t1.user_id,
max(t1.access_date) last_c_date -- 1日差のアクセスがない直近日 = 今日まで連続したアクセスを始めた最初の日
from daily_access t1
inner join (select w.user_id from daily_access w where w.access_date = current_date) w1 -- 今日アクセスがある人だけに絞る
on w1.user_id = t1.user_id
left join daily_access t2 -- 1日差でjoin
on t1.user_id = t2.user_id
and t1.access_date = (t2.access_date + interval 1 day)
where t1.access_date >= (current_date - interval 30 day) -- そんなに長い期間見たいわけではないので1カ月で絞る
and t2.id is null -- これがミソ(連続したアクセスが「ない」日だけを取ってくる)
group by t1.user_id
) last_c
group by c_day
;
これで集計できた時はすごく気持ちよかったんですが、
実データではものすごくパフォーマンスが悪く、SQLでやるもんじゃないな、という結果に落ち着きました。
カレンダー推移
SQLでやるなよシリーズその2です。
これもその昔、私がある要件に対して、SQLのみを武器に果敢に立ち向かった案件です。
私が所属しているマネーフォワードの家計簿サービスでも、よく似た図が出てくるので、それを例にして説明します。
※もちろん、マネーフォワードでこのようなSQLが動いているわけではないです
- 現在の財布の残高がある
- 今月財布から出入りした入出金(「実績」)データが存在する
- 今月財布から出入りするであろう未来の入出金(「予定」)データが存在する
という状態で、
- 今月の毎日の財布残高を、過去・未来含めて一覧表示したい
図にすると以下のようなものです。
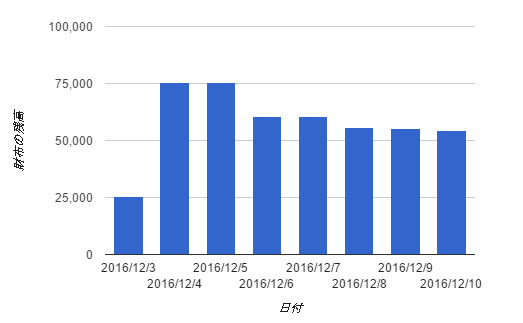
例えば、今日の財布残高が 50,000 円で、昨日の財布の入出金に + 30,000円と - 5,000円があったとすると、
昨日の(開始時点での)財布残高は 25,000円だったことになります。
またまた、どう考えても select 句でやるもんじゃなさそう感満載です。
しかもこいつの厄介なことは、「毎日」のデータが必要なんですが、入出金自体は毎日存在するとは限らない点で、
まずは、「なもない空間」から1カ月の連続レコードを生み出す必要があります。
select (current_date - interval concat(tot.c, too.c) day) calendar_date from
(select '0' c union all select '1' c union all select '2' c) tot,
(select '0' c union all select '1' c union all select '2' c union all select '3' c union all select '4' c union all
select '5' c union all select '6' c union all select '7' c union all select '8' c union all select '9' c ) too
having calendar_date > (current_date - interval 1 month)
order by calendar_date
;
10の位 3までの文字と、1の位 0~9 までの文字を cross join することで 0~39 の数字を生んでいます。
もうすでにツラいですね。
で、もうなんか思い出しているだけで説明する気力もなくなってきてしまったんですが、
このカレンダーテーブルに対して、実績のテーブルと予定のテーブルを、日付を条件(その日以前 or その日以降)にして join して、今日の残高も忘れないように足して、日別で集計して sum を取る(※符号に注意:実績の加算は逆符号です)ことで、欲しかった1カ月連続推移が出た、ような気が……
終わりに
どんな道具にも向き不向きというものがありますが、「SQL縛りのゲーム」みたいなものだと思えば、意外に楽しめたりもします。
しかし、それに囚われて目的を見失わないように、ご注意ください。