はじめに
みなさん、Kubernetesはご存知でしょうか。
WEBサーバやゲームのAPIなどではどんどん採用されていますが、
実は、バッチ処理ともすごく相性が良いので紹介したいと思います。
ちなみに、とある案件で実際にビッグデータ分析基盤のバッチ処理として組み込まれ、
ビッグデータ分析基盤の一部として絶賛稼働中です。
KubenetesとDocker
Kubernetesを知る前にDockerについて理解しましょう。
基本的にKubernetesの環境はGoogle Kubernetes Engine (GKE)を元にして説明したいと思います。
Docker
Dockerとは一言で言えばソフトウエアのコンテナ技術で、アプリケーションを環境ごとパッケージングする技術の一つになります。
近年はパッケージに関してはパッケージマネージャで管理できることが多いですが、
pythonの2系と3系だったりなど、実行環境を分けたいバッチがあったり、
ローカルとバッチサーバの実行環境が異なってデータ破損につながるなどの問題が起こりがちだと思います。
また、別案件のバッチサーバの実行環境のバージョン違いなどによって、案件ごとに実行環境を切り替えなければならない人もいるかも知れません。
そんなときに便利なのがDockerで、実行環境ごと固めて共有することができます。
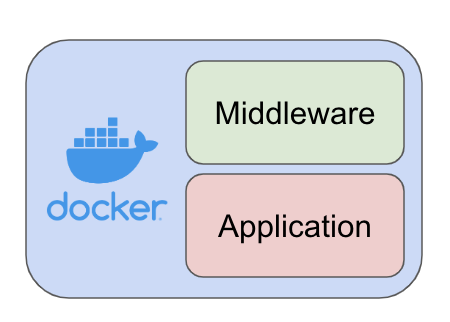
図1, Dockerでのカバー範囲
今回のバッチ処理で想定するDockerのカバー範囲の図。
この図のMiddlewareはPython3やGoogle Cloud SDKなどを指しています。
Applicationがバッチ処理本体になります。
Kubernetes
Dockerの実行をマネージメントするツールです。
単純に実行することもできますが、Kubernetesを使えばWEBサーバの負荷が大きい場合に、VMを3台から10台に増やすことや、逆に負荷が少なくなった場合に自動で3台まで減らすなど設定できます。
また、コンテナ技術はもちろん、Infrastructure as a CodeやImmutable Infrastructureなどの概念などがふんだんに取り入れられているツールとなっています。
この環境込でアプリケーションを固められるDockerとDockerのイメージを自在に実行できるKubernetesの組み合わせにより
アプリケーションの環境ごとまとめて、実行することが容易になります。
データエンジニアにとって便利なKubernetesの機能
Job
Kubernetes上でサーバを実行する場合にはPodというモードで実行する事が多いと思います。
JobはPodを管理するリソースで、Podと違って終了する事を前提にして管理されます。
KubernetesでJobを実行する場合にはJobのマニフェストで以下の項目を設定できます。
- 成功数
- 並列数
- 再実行の設定
- 再実行回数
の設定ができます。
また、Jobの実行履歴は正常終了などの情報がKubernetesで管理され、
一度実行したジョブと同名のジョブは再登録できなかったり。(削除して再登録する必要がある)
実行履歴から過去に失敗したジョブのログを調査できたりします。
 図2, JobとPodの関係
図2, JobとPodの関係
成功数: spec.completions
文字通り成功回数を設定できます。
1に設定することで成功するまでKubernetesが実行してくれます。
また、2以上に設定することで複数回成功するまで実行するなども設定することができます。
並列数: spec.parallelism
並列数はJobを何並列で動かすかという設定になります。
2以上に設定した場合、同一のバッチジョブを並列で動かすことができます。
例えば機械学習による判定処理を3並列で走らせて多数決を取るなんてときに有用かもしれません。
completions数以上の並列化は行われない点に注意が必要です。
例えば並列数3、成功回数3で1回正常終了している場合には、2並列までしか並列化されません。
再実行の設定: spec.template.spec.restartPolicy
常に再実行するAlwaysと再実行しないNeverと失敗時のみ再実行するOnFailureが設定できます。
OnFailureの場合バッチジョブが異常終了した場合にもう一度始めからJobを実行します。
これがとにかく便利です。
再実行回数: spec.backoffLimit
こちらは失敗時何度再実行を行うかの設定です。
5にすればジョブが失敗しても5回まで再実行されます。
オートスケール
Kubernetesを勉強するモチベーションの一つにオートスケールがあると思います。
これはJobでも利用できてノードプールにオートスケールを設定しておけば、
処理に合わせて利用するVMの数を自動で調整してくれます。
例えば、普段1台のVMでバッチ処理を実行しているクラスタで、
過去分のデータを転送するためのバッチジョブを一気に1000個実行したいと言うような場合に、
ノードプールにオートスケールがセットされていれば一時的にVMの数を200台にするというようなことも可能です。
GKEでは手動で設定することでオートスケールの上限を超えた数のVMを立ち上げることも可能で、
これを利用して、Jobがなくなると自動的にオートスケールの範囲内に収まるというような使い方もできます。
CronJob
Jobを定期的に実行するのがCronJobです。
Unix系のコマンドcrontabと同様に
spec.scheduleの項目に0 1 * * *というような設定をすることで、
その時間に自動でJobを実行するということができます。
また、同時実行を許すかの設定spec.concurrencyPolicyで、
実行時に前の処理が終わっていない場合の挙動を設定できます。
例えば、今回の実行をスキップするや、前のジョブを停止して新たに実行するなど。
CronJobはJobの実行を管理してくれます。
 図3, CronJobとJobとPodの関係
図3, CronJobとJobとPodの関係
wait
kubectl waitコマンドにてJobの終了や失敗などを検知することができます。
これにより、別のJobと組み合わせて、バッチジョブの並列実行と直列実行が実装できます。
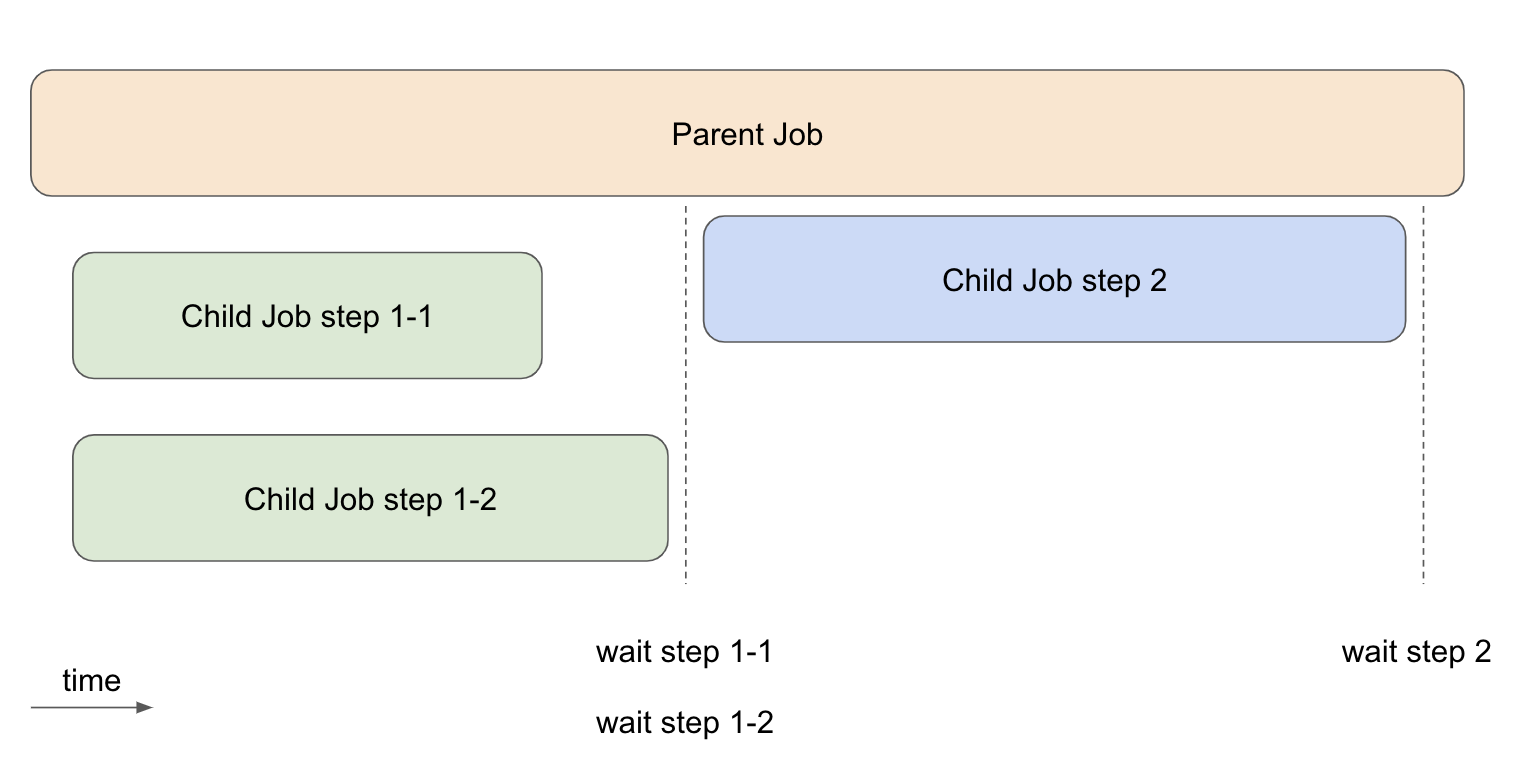
図4, waitを使ったJobの制御
図4はParent JobからChild JobをKubernetesに登録することを想定しています。
そのまま登録した場合にはstep 2のJobがstep 1-1, 1-2に続けて実行されますが、
waitコマンドを挟むことで完了を待って登録することができます。
BigQueryへloadしてからSQLを実行するなどの場合に非常に便利です。
Kubernetesを利用したバッチジョブの実行の注意点
エラー時に異常終了されるようにする
これはそもそもバッチ処理の作り方の問題ですが、
失敗したときに終了ステータスを正常終了の場合0、異常終了の場合それ以外を返すように作りましょう。
そうしなければKubernetes側に異常終了したことがわからないため、再実行されず成功扱いになってしまいます。
よく考えれば当たり前のことなのですが、普段自前でステータス管理を行っている場合は忘れがちなポイントです。
冪等性・原子性
こちらもデータ基盤やバッチ処理を書く上では改めて言う必要もないかも知れませんが、
コンテナレベルで冪等性と原子性を担保したバッチ処理を用意しましょう。
冪等性は同じ引数で実行した場合に同じ結果になるという意味です。
原子性はトランザクションのようにすべて成功するか失敗するかの二択になるようにすることです。
Kubernetesによって勝手に再実行される可能性があるため、何度実行しても同じ結果となるように作るのはほぼ必須だと思います。
原子性については、レジューム機能をもたせる方向でも良いと思います。
突然の死
コンテナを実行する上で一番怖いのがKubernetes自体のなんらかの障害により失敗を検知できないまま
コンテナが何のエラーも出さずに停止してしまうことです。(あまり有りませんが)
厳しい整合性を求められる場合では
- 成功した場合に成功したことをコンテナ外に通知・書き込む仕組み
- 外部での自動整合性チェック処理の実装
をおすすめします。
基本的にはコンテナ内のデータは基本的に揮発性として考えた設計・構築が必要になります。
自分がよく作成するバターン
Jobの設定
ワンショットのバッチ処理に関しては以下の設定でよく実行しています。
- 並列数:1
- 成功数:1
- 再実行回数:5
- 再実行の設定:OnFailure(失敗時のみ再実行)
この設定でJobを実行すれば並列実行せず、成功するまで、再実行してくれます。
また、リソースに空きができ次第実行されるという仕組みのおかげで
ワンショットのバッチ処理が大量に発生しても
Kubernetesに実行を管理してもらうことができ、非常に便利でした。
数千ジョブを登録したまま放っておけば勝手にVMが増え、実行され完了しているというような使い方ができます。
バッチ処理
バッチの作りに関してはKubernetesの処理に限らず、
日付を引数として受け、引数がない場合には昨日の日付として稼働するバッチ処理をよく用意しています。
日付を取得して前日分として稼働するのは冪等性としては微妙ですが、CronJobとJobで同じスクリプトが利用できておすすめです。
また、原子性の実装はファイルの上書きやテーブルの置き換えなどで完全ではないものの原子性に近い挙動にすることが多いです。
(この場合失敗した場合中途半端なファイルが残る事がある)
まとめ
成功回数を保証して実行してくれる仕組みのおかげでバッチ処理の管理が非常に楽になりました。
AirFlowなどのバッチ管理サーバを構築・運用せずとも気軽にワンショットのジョブを実行でき、
また、外的要因によるジョブの失敗時に失敗したジョブを抽出して再実行するなどの対応も不要になりました。
特に便利だと思うのが、並列で1000個のバッチを実行したいというような場合にバッチサーバで行う場合だと、
CPUリソースやネットワークリソース、他の担当者との調整など
何かとバッチ以外のタスクが発生しがちだったと思います。
Kubernetes上でJobを実行することで、バッチ処理の実行に注力できるのは
データ分析基盤開発などのタスクがオーバーフローしがちな案件に非常に有用だと思います。
この記事が誰かのモチベーションになって、Kubernetesで幸せになる人が出るといいなと思います。
参考資料
- 青山 真也(2018)『Kubernetes完全ガイド』(https://amzn.to/36k6qAZ)
- Kubernetes Documentation:
https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/ - Kubectl Reference Docs - Kubernetes:https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#wait